













事務系統實現模式很簡單?你確定沒忽視這些差異?
本文試圖討論這幾個問題:
- MySQL的redo log和binlog為什么要用XA?
- MongoDB的oplog是按照什么順序復制?
- Raft真的只能串行Apply嗎?
- 數據庫的復制和事務是完全獨立的兩回事?
- 為什么MySQL不早點做一個Raft插件,直接用Raft實現高可用?
本文旨在闡述Fault-Tolerant Transaction的幾種實現模式。雖然乍一看它們可能都是Raft+KVEngine +Concurrency Control,容易被認為是同一類方法,但實際上的差異很大,在討論時不應該忽視它們之間的差異。
一、基本概念
討論的Fault-Tolerance,指的是通過網絡通信的多個計算機節點,在部分節點發生Stop Failure的情況下,仍然盡力保證可用性;
不討論具體的Fault-Tolerance方法,默認讀者對Raft等算法有基本理解;
也不討論具體的Concurrency Control方法,默認讀者對其有基本的理解;
會涉及到Spanner、TiKV、MongoDB等具體的數據庫。
1、基于RSM的Fault-Tolerant KV
Replicated State Machine最早應該是在『Implementing fault-tolerant services using the state machine approach』提出。它是一種很簡單實用的實現容錯的方法,核心思想是:幾個狀態機具有相同的初始狀態,并且按照同樣的順序執行了同樣的命令序列,那么它們的最終狀態也是一樣的。由于狀態一樣,那么任意一個狀態機宕機,都可以被其他的代替,因此實現了Fault Tolerant。
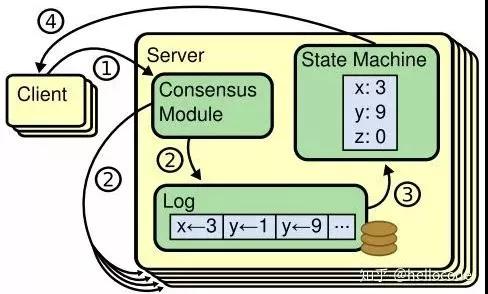
這里提到了幾個概念,命令、執行順序、狀態機,它們都是抽象概念,對應到具體的應用場景才有實際意義。在KVEngine的場景下,命令就是Put/Get等操作,狀態機就是KVEngine本身,而執行序列,則由Replication Log決定。
既然提到了RSM和KV,那么基于RSM的KV也就呼之欲出了。把發到KVEngine的操作先用Raft復制一遍,在Apply的時候扔回到KVEngine執行,于是我們就得到了一個Fault-Tolerant的KVEngine。
看起來很簡單,但我在這里顯然忽略了很多細節:
- 串行還是并行Apply:Raft被人詬病的一點是串行Commit、串行Apply,但這并不是Raft的鍋;
- 兩條Log:Raft復制需要一個Log,KVEngine也會有一個WAL,會帶來IO放大,能不能合并成一個呢?
- Checkpoint:為了加速Recovery,需要做Checkpoint;
- 只讀操作需要復制嗎?
- 命令可以是復合操作嗎:單行的CAS操作可以嗎,多行的事務操作可以作為一個命令嗎?
2、基于RSM的事務
我們來考慮***一個問題,RSM中的命令,可以直接是一個事務嗎?
既然Raft都是串行Apply了,那么看起來把事務的所有操作作為一個命令扔到狀態機執行并沒有什么問題。
但問題在于,實際中的事務是交互式的,也就是包含了if-else等邏輯的,并且邏輯還可能依賴了數據庫系統外部的狀態,所以不能簡單地用Write Batch + Snapshot來實現一個事務,還是要有Concurrency Control的邏輯。
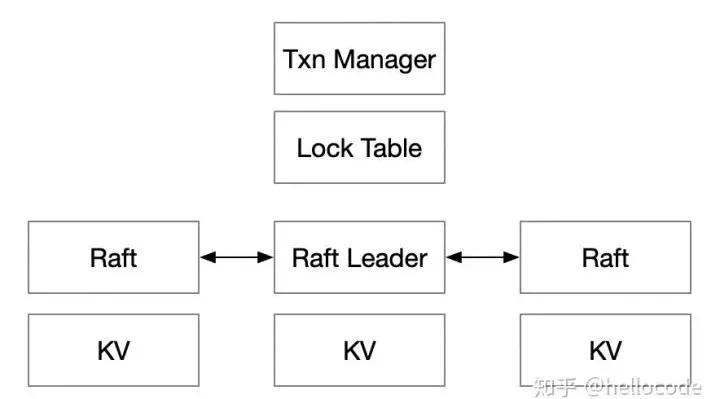
為了解決Concurrency Control的問題,我們在Raft Leader上,實現一個Lock Table和Transaction Manager。拿S2PL方法舉例:
- 讀數據之前加讀鎖,寫數據之前加寫鎖;讀操作通過Raft讀數據,寫操作Buffer在本地;
- 在用戶決定事務提交時,即可釋放讀鎖;通過Raft寫一條事務日志,包含所有寫操作;
- 在Raft Apply事務日志時,把寫操作應用到KVEngine,并且釋放寫鎖。
這里舉的例子是S2PL,但對于其他的并發控制方法也基本通用。例如Snapshot Isolation,事務開始時獲得KV的Snapshot,讀操作都走Snapshot,寫操作獲得寫鎖,數據Buffer在本地,事務提交時檢查[begin, end]之間有沒有寫沖突,沒有的話則通過Raft寫事務日志,在Apply事務日志之后,把寫操作應用到KVEngine,***釋放寫鎖。
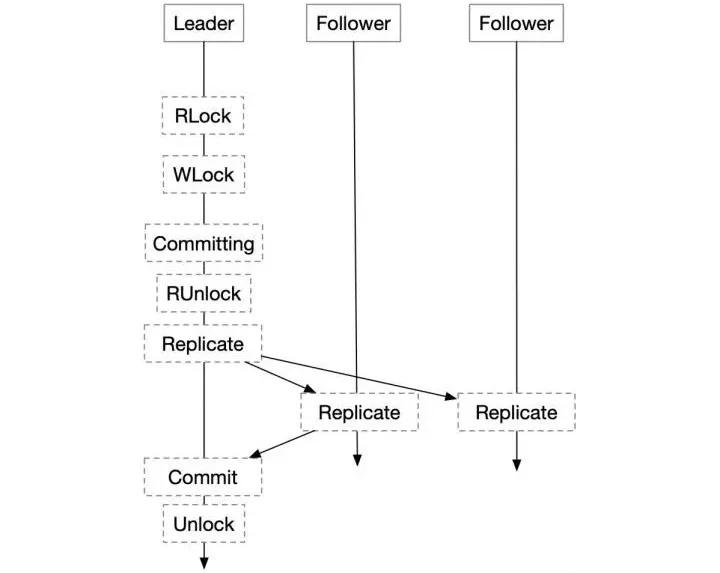
這種方法接近Spanner的做法,它具有幾個特點:
- 只有Leader需要維護Lock Table、Transaction Manager,事務并發控制基本在Leader節點完成;
- 從RSM的角度來看,這里的Lock Table起到了命令定序的作用,保證所有State Machine按照同樣的順序執行命令;
- 加鎖操作不走復制協議,解鎖操作在復制協議Apply之后完成,鎖會在復制的開始到Commit一直持有:也就意味著,復制協議的Commit即是事務的Commit,在Commit之前發生Failover,事務都會Abort;
- Raft所復制的,即是事務的REDO。
3、基于共享存儲的事務
重新看一下上面這個模型,復制協議所做的事情非常簡單,和其他模塊的耦合也很小,僅僅是維護一個有序的Log,因此,我們可以把它從share-nothing推廣到share-storage的模型中。
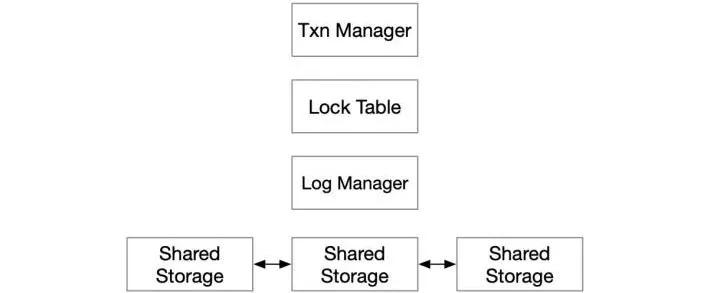
也就是說,我們把普通的單機事務引擎,放到一個高可用的存儲上,就得到了基本可用的Fault-Tolerant 事務引擎了,連復制協議也不需要實現的。
不過事情顯然不會這么簡單:
- 如何實現只讀節點,提供讀擴展的能力;
- 計算節點如何更快地Failover;
- 如何把更多的操作下推到存儲節點。
4、基于高可用KV的事務
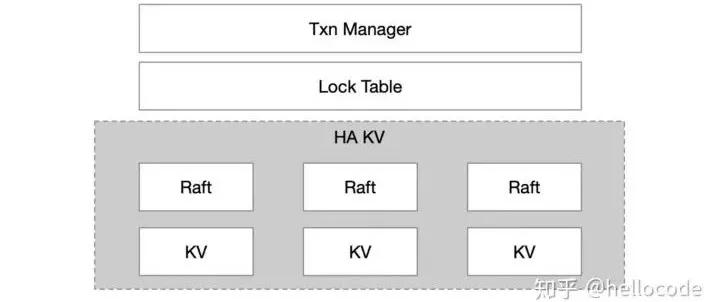
回到一開始的***種方案,在一個節點實現了KV、Raft、Lock Table、Transaction Manager,看起來耦合度比較大了,我們能不能對其進行分層,進一步簡化呢?例如Google的經典做法,基于GFS實現Bigtable,基于Bigtable實現Percolator,Layered設計易于迭代、易于開發、易于調試。
因此我們可以考慮把KV層單獨抽離出來,基于KV去實現Lock Table、Txn Manager:
- Lock Table:在原本的KV中增加一列,變成Key => {Value, Lock};
- Txn Manager: 從事務修改的所有Key中選出一個Primary Key,用來記錄事務狀態,因此KV進一步變成 Key => {Value, Lock, TxnStatus};
- MVCC:甚至我們不甘心于Single Version,還想用Multi Version的并發控制,那么KV就變成{Key, Version} => {Value, Lock, TxnStatus}。
看過Percolator、TiKV設計的應該會比較熟悉,它們就是基于一個高可用的KV,把事務的狀態都下沉到KV中。這種設計很容易拓展到分布式事務的場景,如果KV能夠scale,那么上層的事務也能夠scale了。
5、基于單機事務引擎實現高可用事務
上面的方案看起來都比較簡單,不過有一個細節不容忽視:鎖基本都是在復制協議提交之后才會釋放,換句話說事務持有的鎖會從事務開始直到多個節點寫完日志,經歷多次網絡延遲、IO延遲,并且在擁塞情況下會面臨排隊延遲的風險。而鎖意味著互斥,互斥意味著事務吞吐降低。
翻譯一下:
- 并發且有沖突的事務,其提交順序由Lock Table決定,并且和復制協議的Log順序一致;
- 事務的Serialization Order,和RSM 中的Order一致。
不過這里存在一個問題:
- 鎖一定要在復制協議提交之后才能釋放嗎?
- 提前釋放會破壞Order的一致性嗎?
- RSM的Order一定要和事務的Serialization Order一致嗎?
暫且不做回答,我們再看***一種方案,基于單機事務引擎的高可用事務。
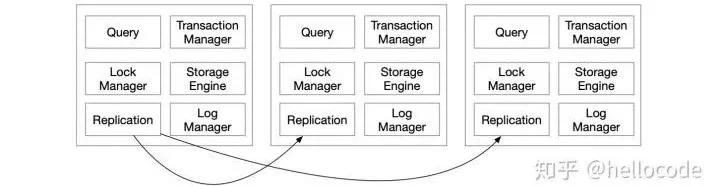
在正常的單機事務流程中,增加一個復制的環節:本地事務提交之后不是立即返回用戶,而是寫binlog,等待binlog復制到其他節點之后再返回用戶。
這種方式的事務延遲,看起來還是本地事務的延遲,加上復制日志的延遲;但相比于之前的方案,本地事務可以先提交,鎖可以提交釋放,總體的事務吞吐相比之下會有所提升。
看起來甚至比之前的方案更加簡單,事務和復制模塊得到了***的分離,但這里忽略了一個復雜的問題:
- 基于哪個日志來復制,基于數據庫的Journal,還是再寫一個binlog?
- 基于什么順序進行復制,如果是基于Journal復制可以用Journal順序,如果基于binlog,順序又是什么?
- 如果有兩個日志,兩個日志其實意味著Transaction Serialization Order和RSM的State Machine Order不一樣,會不會產生事務的并發異常,或者導致State Machine不一致?
由于直接復制Journal會引起一系列復雜的耦合問題,大部分數據庫都選擇單獨寫一個binlog/oplog來實現復制,不過在實現時可以做優化,因為如果真的寫兩個log會有原子性的問題(一個寫成功了另一個沒寫成功)以及IO放大的問題。
這里的設計空間比較龐大,不做詳細討論,僅僅考慮在簡化的模型下復制順序的問題。
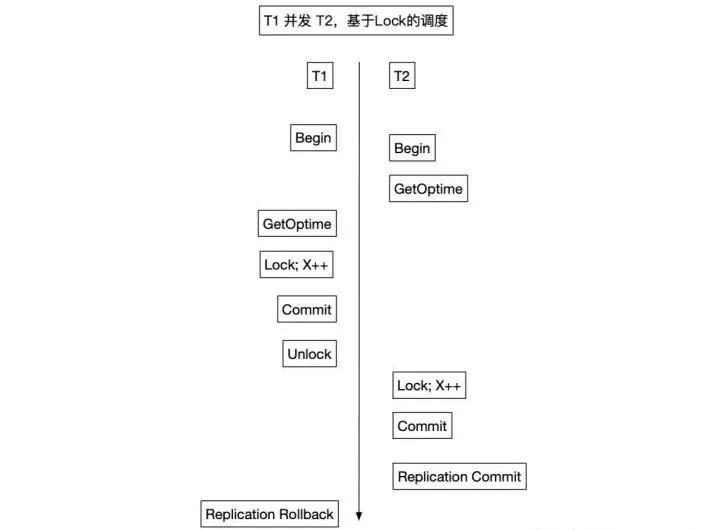
對于并發執行的事務,為了確定復制順序,這里維護一個稱之為OpTime的自增ID。后續的復制會按照OpTime的順序,OpTime小的先復制。如果OpTime僅僅是在事務的開始和結束之間分配,會帶來問題:
- 有沖突且并發的事務T1先Commit,具有較大的OpTime,也就意味會被后復制;
- 后Commit的事務T2先Replication Commit,而先Commit的事務T1可能因為復制失敗而Rollback;
- 對于事務來說,這種場景下出現的異常類似Read-Uncommitted,事務T2讀到了未Commit的數據。
因此,OpTime的分配需要有更強的限制:對于并發且有沖突的事務,OpTime的順序要和事務的Serialization Order一樣:
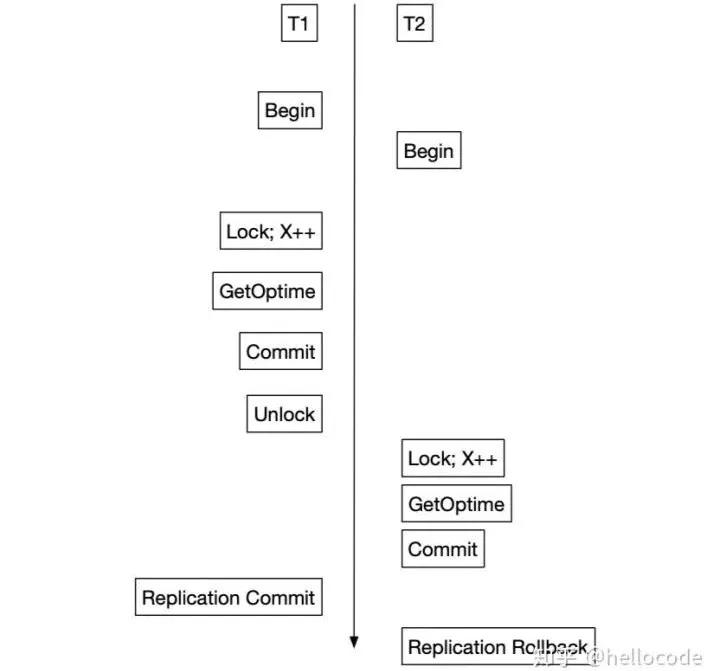
在S2PL的場景中,我們把OpTime分配放到Lock之后Commit之前,即可滿足這個要求。因為按照S2PL的調度,事務的Commit-Point就是Lock完成和Unlock之間。對照上面的例子,事務T2的OpTime被推遲到T1之后,復制的順序也會相應改變,不會發生先前的異常了。
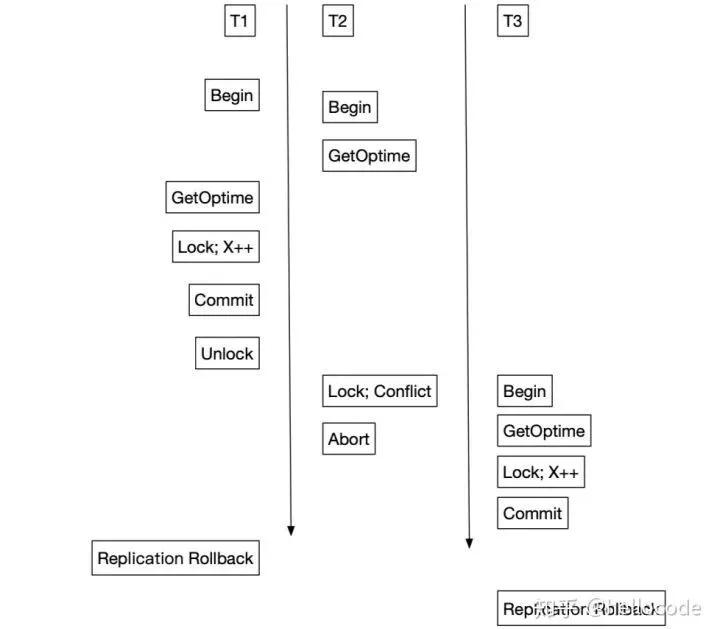
推廣到其他的并發控制方法也是類似,例如上面的Snapshot Isolation。提交之前會檢查[begin, end]是否有沖突,有沖突直接重啟事務。相當于在[begin, end]區間內分配OpTime即可。
這種方法通過OpTime,保留了Transaction Serialization Order和RSM的Order之間的關系:
- 并發且有沖突的事務,其OpTime的順序和事務Serialization Order一樣;
- 并發但沒有沖突的事務,其OpTime順序不確定,因為誰先提交都不會影響正確性;
- 有先于關系的事務,OpTime也一定滿足這個先于關系。
不過這里留下了一個問題,留待讀者思考:
如何按照OpTime復制,因為有事務Abort的情況,OpTime做不到連續自增,僅僅是單調自增。
二、對比
***種其實是Spanner,第二種是TiKV、Percolator,第三種是MySQL、MongoDB。
它們在復制上的區別:
- ***種方案,復制了事務的REDO,事務的提交順序由Raft Log的順序確定,Failover等機制完全按照RSM的模型來即可;
- 第二種方案,Raft僅僅用于復制KV,事務的順序和Raft Log的順序沒有關系,KV層的Failover和事務的Recovery完全獨立;
- 第三種方案,已經區別于傳統的RSM模型,因為它其實是先Apply,再Replication、Commit,可以實現并發Apply。
從復雜度來看:
- 第二種最簡單清晰,從Raft,到Raft KV,再到Transactional KV,分層良好;
- 其次是***種,在Leader節點會額外實現Lock Table、Transaction Manager,這個和Raft是緊密結合的,但是事務提交的順序就是Raft Log的提交順序,不會造成混淆;
- 最復雜的是第三種,由于事務提交順序和Optime順序不一致,對復制、讀寫等各種流程都會造成影響,看似簡單但實則耦合。
從事務并發的角度來看:
- 第三種方案可以***支持并發,且持有鎖的時間較短,僅僅是寫一次本地日志;
- ***二種方案持有鎖的時間更長,***在Apply時理論上可以做到并發,如果沒有其他約束。
從讀寫開銷的角度來看:
- ***種***,Replication Log和Engine Log可以合并,每條事務只要復制一次Raft Log;
- 其次是第二種,通常會把binlog和存儲引擎的journal獨立,需要寫兩遍;不過oplog可以寫到存儲引擎里,一次IO即可提交(MongoDB的做法);
- ***是第二種,在KV中增加了更多的數據,放大較多。
不過這僅僅是理論上的分析,實際的復雜度、性能,很大程度上取決于實現而非理論。
三、總結
如果我們從很粗的層面來看,會覺得這些系統不過都是幾個技術點的組合,而每一個技術點看起來都很簡單,進而覺得事務系統不過是如此。
但實際上事務系統絕非簡單的KV+Raft+Snapshot Isolation,它們之間不同的組合方式,會最終造就不同的系統。
本文留下了很多問題,RSM的Order往往認為是全序的,而Transaction 的Serialization Order是偏序的(偏序關系由事務沖突定義),它們之間如何統一?
RSM的Checkpoint和Transaction Checkpoint的統一?RSM的Recovery和Transaction Recovery的關系?寫兩條日志的系統(journal和binlog)兩條日志之間的關系是什么?














