面試大殺器:為什么一定要用MQ中間件?
這篇文章我們會把消息中間件這塊高頻的面試問題來給大家說一下,也會涵蓋一些 MQ 中間件常見的技術問題。
假如說面試官看你簡歷里寫了 MQ 中間件的使用經驗,很可能會有如下的問題:
- 你們公司生產環境用的是什么消息中間件?
- 為什么要在系統架構中引入消息中間件?
- 引入消息中間件之后會有什么好處以及壞處?
好,下面我們一個個的來分析!
你們公司生產環境用的是什么消息中間件?
這個首先你可以說下你們公司選用的是什么消息中間件,比如用的是 RabbitMQ,然后可以初步給一些你對不同 MQ 中間件技術的選型分析。
舉個例子:比如說 ActiveMQ 是老牌的消息中間件,國內很多公司過去運用的還是非常廣泛的,功能很強大。
但是問題在于沒法確認 ActiveMQ 可以支撐互聯網公司的高并發、高負載以及高吞吐的復雜場景,在國內互聯網公司落地較少。而且使用較多的是一些傳統企業,用 ActiveMQ 做異步調用和系統解耦。
然后你可以說說 RabbitMQ,他的好處在于可以支撐高并發、高吞吐、性能很高,同時有非常完善便捷的后臺管理界面可以使用。
另外,他還支持集群化、高可用部署架構、消息高可靠支持,功能較為完善。
而且經過調研,國內各大互聯網公司落地大規模 RabbitMQ 集群支撐自身業務的 case 較多,國內各種中小型互聯網公司使用 RabbitMQ 的實踐也比較多。
除此之外,RabbitMQ 的開源社區很活躍,較高頻率的迭代版本,來修復發現的 Bug 以及進行各種優化,因此綜合考慮過后,公司采取了 RabbitMQ。
但是 RabbitMQ 也有一點缺陷,就是他自身是基于 Erlang 語言開發的,所以導致較為難以分析里面的源碼,也較難進行深層次的源碼定制和改造,畢竟需要較為扎實的 Erlang 語言功底才可以。
然后可以聊聊 RocketMQ,是阿里開源的,經過阿里的生產環境的超高并發、高吞吐的考驗,性能卓越,同時還支持分布式事務等特殊場景。
而且 RocketMQ 是基于 Java 語言開發的,適合深入閱讀源碼,有需要可以站在源碼層面解決線上生產問題,包括源碼的二次開發和改造。
另外就是 Kafka。Kafka 提供的消息中間件的功能明顯較少一些,相對上述幾款 MQ 中間件要少很多。
但是 Kafka 的優勢在于專為超高吞吐量的實時日志采集、實時數據同步、實時數據計算等場景來設計。
因此 Kafka 在大數據領域中配合實時計算技術(比如 Spark Streaming、Storm、Flink)使用的較多。但是在傳統的 MQ 中間件使用場景中較少采用。
PS:如果大家對上述一些 MQ 技術還沒在自己電腦部署過,沒寫幾個 helloworld 體驗一下的話,建議先上各個技術的官網找到 helloworld demo,自己跑一遍玩玩。
為什么在你們系統架構中要引入消息中間件?
回答這個問題,其實就是讓你先說說消息中間件的常見使用場景。然后結合你們自身系統對應的使用場景,說一下在你們系統中引入消息中間件解決了什么問題。
系統解耦
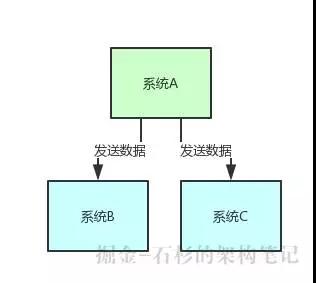
假設你有個系統 A,這個系統 A 會產出一個核心數據,現在下游有系統 B 和系統 C 需要這個數據。那簡單,系統 A 就是直接調用系統 B 和系統 C 的接口發送數據給他們就好了。
整個過程,如下圖所示:
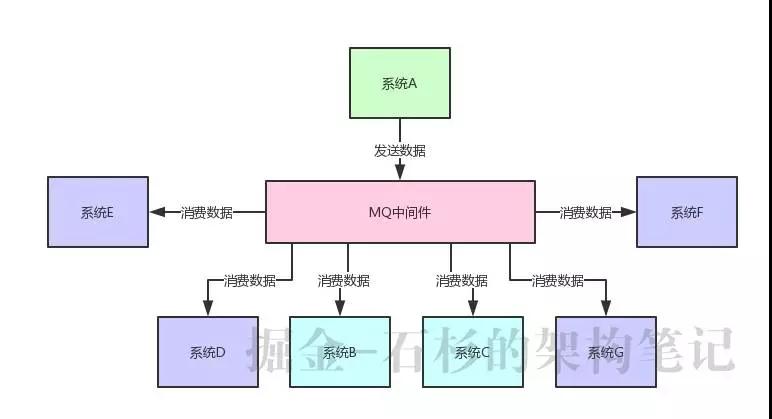
但是現在要是來了系統 D、系統 E、系統 F、系統 G,等等,十來個其他系統慢慢的都需要這份核心數據呢?如下圖所示:
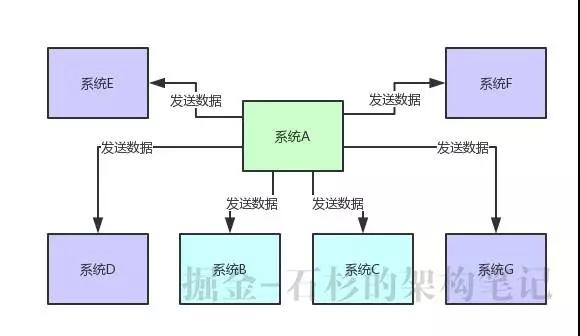
大家可別以為這是開玩笑,一個大規模系統,往往會拆分為幾十個甚至上百個子系統,每個子系統又對應 N 多個服務,這些系統與系統之間有著錯綜復雜的關系網絡。
如果某個系統產出一份核心數據,可能下游無數的其他系統都需要這份數據來實現各種業務邏輯。
此時如果你要是采取上面那種模式來設計系統架構,那么絕對你負責系統 A 的同學要被煩死了。
先是來一個人找他要求發送數據給一個新的系統 H,系統 A 的同學要修改代碼,然后在那個代碼里加入調用新系統 H 的流程。
一會那個系統 B 是個陳舊老系統要下線了,告訴系統 A 的同學:別給我發送數據了,接著系統 A 再次修改代碼不再給這個系統 B。
然后如果要是某個下游系統突然宕機了呢?系統 A 的調用代碼里是不是會拋異常?
那系統A的同學會收到報警說異常了,結果他還要去 care 是下游哪個系統宕機了。
所以在實際的系統架構設計中,如果全部采取這種系統耦合的方式,在某些場景下絕對是不合適的,系統耦合度太嚴重。
并且互相耦合起來并不是核心鏈路的調用,而是一些非核心的場景(比如上述的數據消費)導致了系統耦合,這樣會嚴重的影響上下游系統的開發和維護效率。
因此在上述系統架構中,就可以采用 MQ 中間件來實現系統解耦。系統 A 就把自己的一份核心數據發到 MQ 里,下游哪個系統感興趣自己去消費即可,不需要了就取消數據的消費,如下圖所示:
異步調用
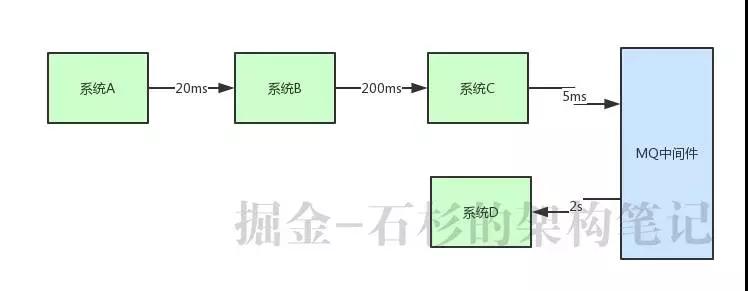
假設你有一個系統調用鏈路,是系統 A 調用系統 B,一般耗時 20ms;系統 B 調用系統 C,一般耗時 200ms;系統 C 調用系統 D,一般耗時 2s,如下圖所示:

現在***的問題就是:用戶一個請求過來巨慢無比,因為走完一個鏈路,需要耗費 20ms + 200ms + 2000ms(2s) = 2220ms,也就是 2 秒多的時間。
但是實際上,鏈路中的系統 A 調用系統 B,系統 B 調用系統 C,這兩個步驟起來也就 220ms。
就因為引入了系統 C 調用系統 D 這個步驟,導致最終鏈路執行時間是 2 秒多,直接將鏈路調用性能降低了 10 倍,這就是導致鏈路執行過慢的罪魁禍首。
那此時我們可以思考一下,是不是可以將系統 D 從鏈路中抽離出去做成異步調用呢?其實很多的業務場景是可以允許異步調用的。
舉個例子,你平時點個外賣,咔嚓一下子下訂單然后付款了,此時賬戶扣款、創建訂單、通知商家給你準備菜品。
接著,是不是需要找個騎手給你送餐?那這個找騎手的過程,是需要一套復雜算法來實現調度的,比較耗時。
但是其實稍微晚個幾十秒完成騎手的調度都是 ok 的,因為實際并不需要在你支付的一瞬間立馬給你找好騎手,也沒那個必要。
那么我們是不是就可以把找騎手給你送餐的這個步驟從鏈路中抽離出去,做成異步化的,哪怕延遲個幾十秒,但是只要在一定時間范圍內給你找到一個騎手去送餐就可以了。
這樣是不是就可以讓你下訂單點外賣的速度變得超快?支付成功之后,直接創建好訂單、賬戶扣款、通知商家立馬給你準備做菜就 ok 了,這個過程可能就幾百毫秒。
然后后臺異步化的耗費可能幾十秒通過調度算法給你找到一個騎手去送餐,但是這個步驟不影響我們快速下訂單。
當然我們不是說那些大家熟悉的外賣平臺的技術架構就一定是這么實現的,只不過是用一個生活中常見的例子給大家舉例說明而已。
所以上面的鏈路也是同理,如果業務流程支持異步化的話,是不是就可以考慮把系統 C 對系統 D 的調用抽離出去做成異步化的,不要放在鏈路中同步依次調用。
這樣,實現思路就是系統 A→系統 B→系統 C,直接就耗費 220ms 后直接成功了。
然后系統 C 就是發送個消息到 MQ 中間件里,由系統 D 消費到消息之后慢慢的異步來執行這個耗時 2s 的業務處理。通過這種方式直接將核心鏈路的執行性能提升了 10 倍。
整個過程,如下圖所示:
流量削峰
假設你有一個系統,平時正常的時候每秒可能就幾百個請求,系統部署在 8 核 16G 的機器的上,正常處理都是 ok 的,每秒幾百請求是可以輕松抗住的。
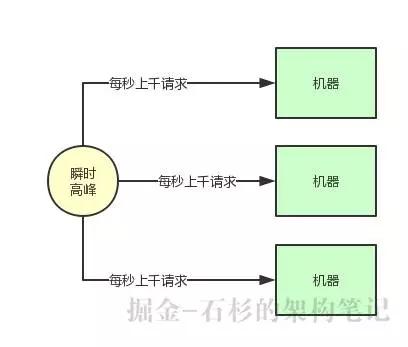
但是如下圖所示,在高峰期一下子來了每秒鐘幾千請求,瞬時出現了流量高峰,此時你的選擇是要搞 10 臺機器,抗住每秒幾千請求的瞬時高峰嗎?
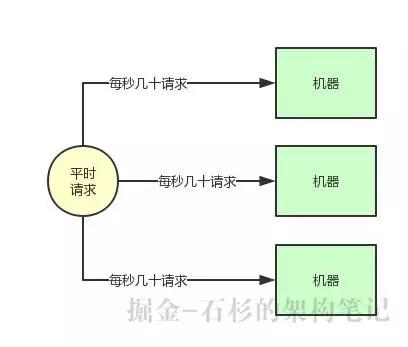
那如果瞬時高峰每天就那么半個小時,接著直接就降低為了每秒就幾百請求,如果你線上部署了很多臺機器,那么每臺機器就處理每秒幾十個請求就可以了,這不是有點浪費機器資源嗎?
大部分時候,每秒幾百請求,一臺機器就足夠了,但是為了抗那每天瞬時的高峰,硬是部署了 10 臺機器,每天就那半個小時有用,別的時候都是浪費資源的。
但是如果你就部署一臺機器,那會導致瞬時高峰時,一下子壓垮你的系統,因為絕對無法抗住每秒幾千的請求高峰。
此時我們就可以用 MQ 中間件來進行流量削峰。所有機器前面部署一層 MQ,平時每秒幾百請求大家都可以輕松接收消息。
一旦到了瞬時高峰期,一下涌入每秒幾千的請求,就可以積壓在 MQ 里面,然后那一臺機器慢慢的處理和消費。
等高峰期過了,再消費一段時間,MQ 里積壓的數據就消費完畢了。

這個就是很典型的一個 MQ 的用法,用有限的機器資源承載高并發請求。
如果業務場景允許異步削峰,高峰期積壓一些請求在 MQ 里,然后高峰期過了,后臺系統在一定時間內消費完畢不再積壓的話,那就很適合用這種技術方案。
引入消息中間件之后會有什么好處以及壞處?
如果你在系統架構里引入了消息中間件之后,會有哪些缺點?
系統可用性降低
首先是你的系統整體可用性絕對會降低,給你舉個例子,我們就拿之前的一幅圖來說明。
比如說一個核心鏈路里面,系統 A→系統 B→系統 C,然后系統 C 是通過 MQ 異步調用系統 D 的。
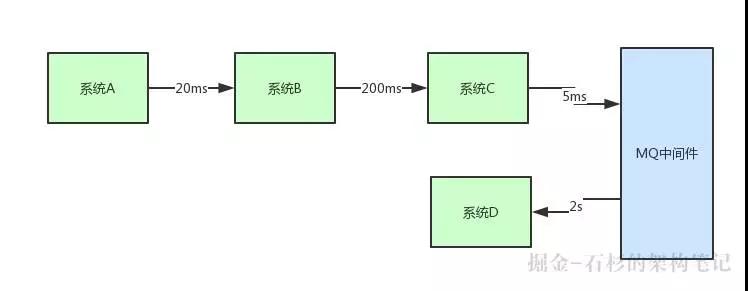
看起來很好,你用這個 MQ 異步化的手段解決了一個核心鏈路執行性能過差的問題。
但是你有沒有考慮另外一個問題,就是萬一你依賴的那個 MQ 中間件突然掛掉了怎么辦?
這個還真的不是異想天開,MQ、Redis、MySQL 這些組件都有可能會掛掉。一旦你的 MQ 掛了,就導致你的系統的核心業務流程中斷了。
本來你要是不引入 MQ 中間件,那其實就是一些系統之間的調用,但是現在你引入了 MQ,就導致你多了一個依賴。一旦多了一個依賴,就會導致你的可用性降低。
因此,一旦引入了 MQ 中間件,你就必須去考慮這個 MQ 是如何部署的,如何保證高可用性。
甚至在復雜的高可用的場景下,你還要考慮如果 MQ 一旦掛了以后,你的系統有沒有備用兜底的技術方案,可以保證系統繼續運行下去。
系統穩定性降低
還是上面那張圖,大家再來看一下:
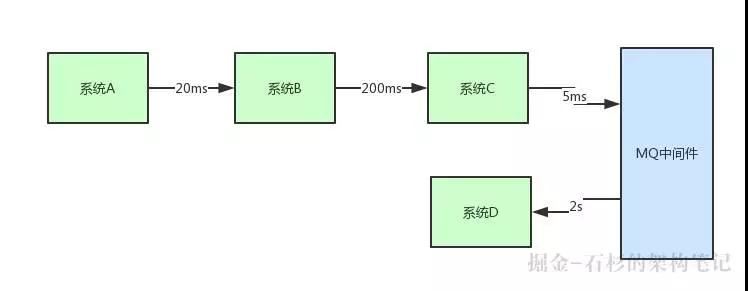
不知道大家有沒有發現一個問題,這個鏈路除了 MQ 中間件掛掉這個可能存在的隱患之外,可能還有一些其他的技術問題。
比如說,莫名其妙的,系統 C 發了一個消息到 MQ,結果那個消息因為網絡故障等問題,就丟失了。這就導致系統 D 沒有收到那條消息。
這可就慘了,這樣會導致系統 D 沒完成自己該做的任務,此時可能整個系統會出現業務錯亂,數據丟失,嚴重的 Bug,用戶體驗很差等各種問題。
這還只是其中之一,萬一說系統 C 給 MQ 發送消息,不小心一抽風重復發了一條一模一樣的,導致消息重復了,這個時候該怎么辦?
可能會導致系統 D 一下子把一條數據插入了兩次,導致數據錯誤,臟數據的產生,***一樣會導致各種問題。
或者說如果系統 D 突然宕機了幾個小時,導致無法消費消息,結果大量的消息在 MQ 中間件里積壓了很久,這個時候怎么辦?
即使系統 D 恢復了,也需要慢慢的消費數據來進行處理。所以這就是引入 MQ 中間件的第二個大問題,系統穩定性可能會下降,故障會增多,各種各樣亂七八糟的問題都可能產生。
而且一旦產生了一個問題,就會導致系統整體出問題。你就需要為了解決各種 MQ 引發的技術問題,采取很多的技術方案。
關于這個,我們后面會用專門的文章聊聊 MQ 中間件的這些問題的解決方案,包括:
- 消息高可靠傳遞(0 丟失)
- 消息冪等性傳遞(絕對不重復)
- 百萬消息積壓的線上故障處理
分布式一致性問題
引入消息中間件,還有分布式一致性的問題。舉個例子,比如說系統 C 現在處理自己本地數據庫成功了,然后發送了一個消息給 MQ,系統 D 也確實是消費到了。
但是結果不幸的是,系統 D 操作自己本地數據庫失敗了,那這個時候咋辦?
系統 C 成功了,系統 D 失敗了,會導致系統整體數據不一致了啊。所以此時又需要使用可靠消息最終一致性的分布式事務方案來保障。
關于這個,可以參考之前的一篇文章:最終一致性分布式事務如何保障實際生產中 99.99% 高可用?
我們在里面詳細闡述了系統之間異步調用場景下,如何采用分布式事務方案保證其數據一致性。
總結
最后,我們來做一個簡單的小結。在面試中要答好這個問題,首先一定要熟悉 MQ 這個技術的優缺點。了解清楚把他引入系統是為了解決哪些問題的,但是他自身又會帶來哪些問題。
此外,對于引入 MQ 以后,是否對他自身可能引發的問題有一些方案的設計,來保證你的系統高可用、高可靠的運行,保證數據的一致性。這個也要做好相應的準備。
中華石杉:十余年 BAT 架構經驗,一線互聯網公司技術總監。帶領上百人團隊開發過多個億級流量高并發系統。現將多年工作中積累下的研究手稿、經驗總結整理成文,傾囊相授。微信公眾號:石杉的架構筆記(ID:shishan100)。