













操作系統之CPU知識掃盲
前言
CPU的英文全稱是(Central Processing Unit),中文意思翻譯中央處理器,是計算機的主要設備之一,功能主要是解釋計算機指令以及處理計算機軟件中的數據。計算機的可編程性主要是指對中央處理器的編程。
關于馮·諾依曼結構
馮·諾依曼結構(Von Neumann architecture)是一種將程序指令存儲器和數據存儲器合并在一起的計算機設計概念結構。馮·諾依曼結構隱約指導了將存儲設備與中央處理器分開ß的概念,因此依本結構設計出的計算機又稱存儲程序計算機,這也是目前大多數計算機設計的主要參考原則。
最早的計算機器僅內含固定用途的程序。現代的某些計算機依然維持這樣的設計方式,通常是為了簡化或教育目的。例如一個計算器僅有固定的數學計算程序,它不能拿來當作文字處理軟件,更不能拿來玩游戲。若想要改變此機器的程序,你必須更改線路、更改結構甚至重新設計此機器。當然最早的計算機并沒有設計的那么可編程。當時所謂的“重寫程序”很可能指的是紙筆設計程序步驟,接著制訂工程細節,再施工將機器的電路配線或結構改變。
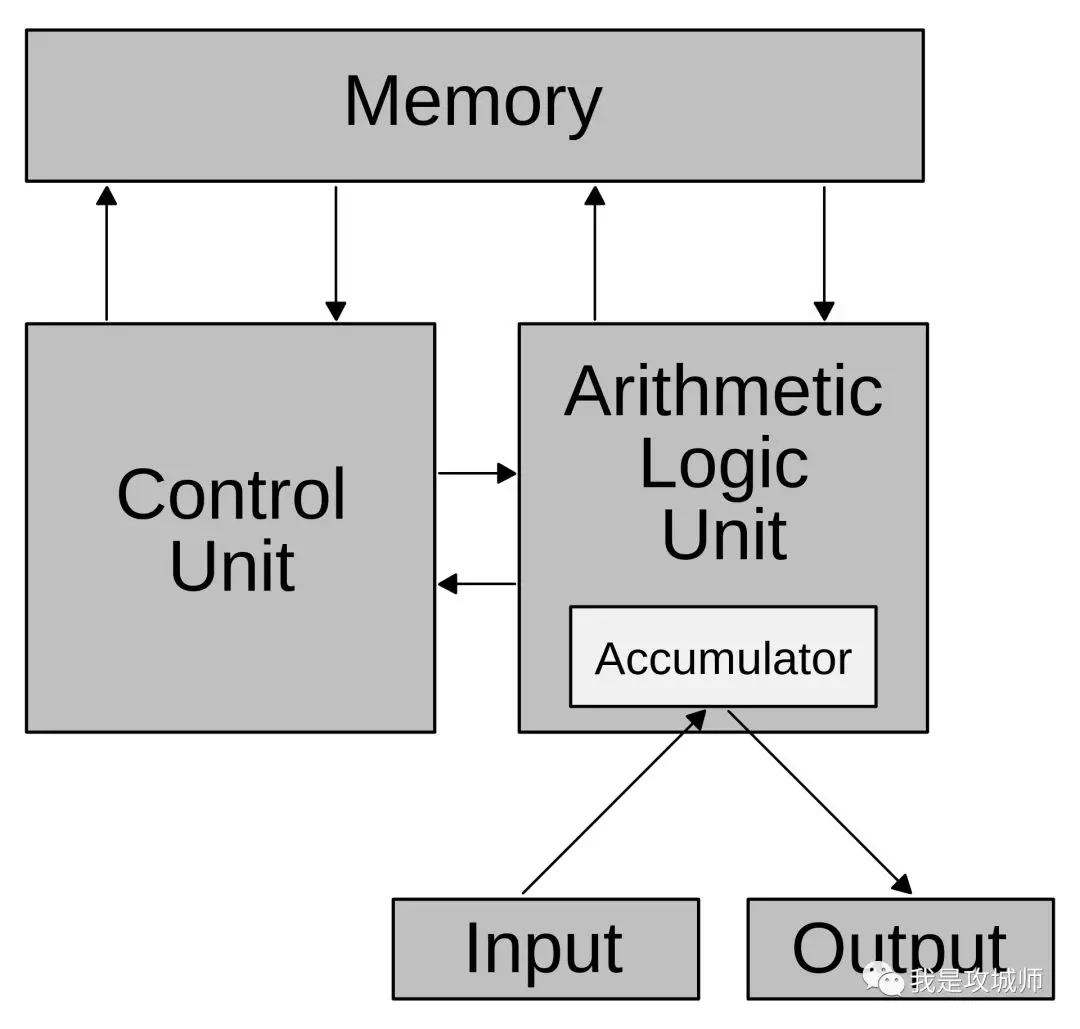
而存儲程序型計算機的概念改變了這一切。借由創造一組指令集結構,并將所謂的運算轉化成一串程序指令的運行細節,可讓程序運行時自我修改程序的運算內容,讓此機器更有彈性。借著將指令當成一種特別類型的靜態數據,一臺存儲程序型計算機可輕易改變其程序,并在程控下改變其運算內容。 馮·諾伊曼結構與存儲程序型計算機是互相通用的名詞。而哈佛結構則是一種將程序數據與普通數據分開存儲的設計概念,但是它并未完全突破馮.諾伊曼架構。
CPU執行原理
CPU的主要運作原理,不論其外觀,都是執行儲存于被稱為程序里的一系列指令。在此討論的是遵循普遍的馮·諾伊曼結構(von Neumann architecture)設計的裝置。程序以一系列數字儲存在計算機存儲器中。差不多所有的馮·諾伊曼CPU的運作原理可分為四個階段:提取、解碼、執行和寫回。
(1)提取
從程序內存中檢索指令(為數值或一系列數值)。由程序計數器指定程序存儲器的位置,程序計數器保存供識別目前程序位置的數值。換言之,程序計數器記錄了CPU在目前程序里的蹤跡。提取指令之后,PC根據指令式長度增加存儲器單元[iwordlength]。指令的提取常常必須從相對較慢的存儲器查找,導致CPU等候指令的送入。這個問題主要被論及在現代處理器的緩存和管線化架構。
(2)解碼
CPU根據從存儲器提取到的指令來決定其執行行為。在解碼階段,指令被拆解為有意義的片斷。根據CPU的指令集架構(ISA)定義將數值解譯為指令[isa]。一部分的指令數值為運算碼,其指示要進行哪些運算。其它的數值通常供給指令必要的信息
(3)執行
在提取和解碼階段之后,接著進入執行階段。該階段中,連接到各種能夠進行所需運算的CPU部件。例如,要求一個加法運算,算術邏輯單元將會連接到一組輸入和一組輸出。輸入提供了要相加的數值,而且在輸出將含有總和結果。ALU內含電路系統,以于輸出端完成簡單的普通運算和邏輯運算(比如加法和比特運算)。如果加法運算產生一個對該CPU處理而言過大的結果,在標志寄存器里,溢出標志可能會被設置
(4)寫回
最終階段,寫回,以一定格式將執行階段的結果簡單的寫回。運算結果經常被寫進CPU內部的寄存器,以供隨后指令快速訪問。在其它案例中,運算結果可能寫進速度較慢,如容量較大且較便宜的主存
注意,這上面的4個階段與我們編寫程序是非常相關的,但編程語言里面可能會簡化,并把2和3階段合并,分為:加載,處理,寫回。在多線程編程里面,了解這幾個概念至關重要,由此可以延伸,數據從哪里加載,在哪里執行,***結果又寫回了哪里。指令數據一般從內存里面加載,但是內存的訪問時間,相比cpu慢了n多倍,所以為了加速處理,cpu一般把指令給加載到離cpu更近的寄存器里面,或者是L1,L2,L3的cache來提速,最終計算出來的結果,還要寫回內存。正是因為cpu執行指令復雜,所以這里面其實牽扯到很多問題,比如多個線程如何協作處理任務,以及如何保證程序數據的原子性,有序性,可見性。而這正是Java的內存模型出現的意義。在其他不同的編程語言里面其實都有在操作系統之上抽象的內存模型來應對不同的cpu架構的的差異,這一點需要注意。
多個單核CPU vs 單個多核CPU
多個單核CPU:
成本更高,因為每個CPU都需要一定的線路電路支持,這樣對主板上布局布線極為不便。并且當運行多線程任務時,多線程間通信協同合作也是一個問題。依賴總線的傳輸,速度較慢,且每一個線程因為運行在不同的CPU上。導致不同線程間各開一個Cache,會造成資源的浪費,同時如果線程間協作就會有冗余數據的產生,更加大了內存的開銷。
單個多核CPU:
可以很好地規避基本上多個單核CPU提到的所有缺點。他不需要考慮硬件上的開銷以及復雜性問題,同時也可以很好地解決多線程間協同工作的問題,減少內存的開銷,因為多線程程序在多核CPU中運行是共用一塊內存區的,數據的傳輸速度比總線來的要快同時不會有冗余數據的產生。單個多核CPU的問題也是顯而易見的,假設倆大程序,每一個程序都好多線程還幾乎用滿cache,它們分時使用CPU,那在程序間切換的時候,光指令和數據的替換就是個問題。
單個多核cpu已經成為個人計算機的主流配置,多個多核的cpu在一些大型的服務器里面也很常見。
超線程
“超線程”(Hyperthreading Technology)技術就是通過采用特殊的硬件指令,可以把兩個邏輯內核模擬成兩個物理超線程芯片,在單處理器中實現線程級的并行計算,同時在相應的軟硬 件的支持下大幅度的提高運行效能,從而使單處理器上模擬雙處理器的效能。其實,從實質上說,超線程是一種可以將CPU內部暫時閑置處理資源充分“調動”起來的技術。
每個單位時間內,CPU只能處理一個線程,以這樣的單位進行,如果想要在單位時間內處理超過一個的線程,是不可能的,除非是有兩個核心處理單元,英特爾的HT技術便是以單個核心處理單元,去整合兩個邏輯處理單元,也就是一個實體核心,兩個邏輯核心,在單位時間內處理兩個線程,模擬雙核心運作。
簡單的說,超線程就是在單個core中,模擬出兩個邏輯處理單元,以此能夠提高程序執行的并發能力,提高系統cpu資源的利用率。
至此,關于CPU的個數,核數,邏輯CPU的個數計算關系如下:
(1)總核數 = 物理CPU個數 X 每顆物理CPU的核數
(2)總邏輯CPU數 = 物理CPU個數 X 每顆物理CPU的核數 X 超線程數
一些概念解釋如下:
- ① 物理CPU
- 實際Server中插槽上的CPU個數
- 物理cpu數量,可以數不重復的 physical id 有幾個
- ② 邏輯CPU
- Linux用戶對 /proc/cpuinfo 這個文件肯定不陌生. 它是用來存儲cpu硬件信息的
- 信息內容分別列出了processor 0 – n 的規格。這里需要注意,如果你認為n就是真實的cpu數的話, 就大錯特錯了
- 一般情況,我們認為一顆cpu可以有多核,加上intel的超線程技術(HT), 可以在邏輯上再分一倍數量的cpu core出來
- 邏輯CPU數量=物理cpu數量 x cpu cores 這個規格值 x 2(如果支持并開啟ht)
- 備注一下:Linux下top查看的CPU也是邏輯CPU個數
- ③ CPU核數
- 一塊CPU上面能處理數據的芯片組的數量、比如現在的i5 760,是雙核心四線程的CPU、而 i5 2250 是四核心四線程的CPU
- 一般來說,物理CPU個數×每顆核數就應該等于邏輯CPU的個數,如果不相等的話,則表示服務器的CPU支持超線程技術
(描述信息可滑動)
在linux上查看這些信息命令如下:
- # 查看物理CPU個數
- cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
- # 查看每個物理CPU中core的個數(即核數)
- cat /proc/cpuinfo| grep "cpu cores"| uniq
- # 查看邏輯CPU的個數
- cat /proc/cpuinfo| grep "processor"| wc -l
舉例,在一個Mac Pro的機器上,可以通過關于本機,系統報告選項中,看到當前系統的基本配置情況,如下:
- 型號名稱:MacBook Pro
- 型號標識符:MacBookPro11,4
- 處理器名稱:IntelCore i7
- 處理器速度:2.2GHz
- 處理器數目:1
- 核總數:4
- L2 緩存(每個核):256KB
- L3 緩存:6MB
- 內存:16GB
- Boot ROM 版本:187.0.0.0.0
- SMC 版本(系統):2.29f24
- 序列號(系統):C02SK27CG8WN
- 硬件 UUID:652D3965-1BF1-5614-AA0D-63DC5B6DD347
比如上面的信息中,顯示了當前的系統物理上只擁有一個cpu,但是這個cpu有4個核。然后,我們查詢其邏輯cpu的個數,會發現顯示是8個:(在Mac上打開活動監視器,然后雙擊最下面的中間的cpu負載的地方,就可以看到)

這就是因為每個核又有2個超線程,所以8個邏輯cpu個數=1物理cpu個數 * 4核 * 2個超線程,最終也就是說如果我要編寫一個多線程計算密集型的程序任務,起的線程數可以以邏輯cpu的個數作為參照。當然如果是io密集型的任務,可以開的更多一點。
CPU性能參數
計算機的性能在很大程度上由CPU的性能決定,而CPU的性能主要體現在其運行程序的速度上。影響運行速度的性能指標包括CPU的工作頻率、Cache容量、指令系統和邏輯結構等參數。
大多數情況下,我們主要關注的是CPU的主頻,也稱時鐘頻率,是指同步電路中時鐘的基礎頻率,它以“每秒時鐘周期”(clock cycles per second)來度量,單位是兆赫(MHz)或千兆赫(GHz)用來表示CPU的運算、處理數據的速度。通常,主頻越高,CPU處理數據的速度就越快。
在上面的mac的參數里面,我們能夠看到在Intel Core i7處理器下,主頻是2.2 GHz,當前主頻高的處理器也在4 GHz之內,其主要原因主要在于散熱,提高主頻超過一定范圍后熱密度急速提高,很不經濟,也造成散熱困難。
總結
本文主要介紹了計算機操作系統中CPU有關的知識,計算機的核心就在于CPU,了解CPU相關的知識,可以讓我們更清楚我們的程序底層執行的過程,從而寫出更健壯的代碼及調優相關的程序。











