面試必備指南:你的系統(tǒng)如何支撐高并發(fā)?
這篇文章,我們聊聊大量同學問我的一個問題,面試的時候被問到一個讓人特別手足無措的問題:你的系統(tǒng)如何支撐高并發(fā)?
一道面試題的背景引入
大多數(shù)同學被問到這個問題壓根兒沒什么思路去回答,不知道從什么地方說起,其實本質就是沒經歷過一些真正有高并發(fā)系統(tǒng)的錘煉罷了。
因為沒有過相關的項目經歷,所以就沒法從真實的自身體會和經驗中提煉出一套回答,然后系統(tǒng)的闡述出來自己負責過的系統(tǒng)如何支撐高并發(fā)的。
所以,這篇文章就從這個角度切入來簡單說說這個問題,用一個最簡單的思路來回答,大致如何應對。
當然這里首先說清楚一個前提:高并發(fā)系統(tǒng)各不相同。比如每秒百萬并發(fā)的中間件系統(tǒng)、每日百億請求的網關系統(tǒng)、瞬時每秒幾十萬請求的秒殺大促系統(tǒng)。
他們在應對高并發(fā)的時候,因為系統(tǒng)各自特點的不同,所以應對架構都是不一樣的。
另外,比如電商平臺中的訂單系統(tǒng)、商品系統(tǒng)、庫存系統(tǒng),在高并發(fā)場景下的架構設計也是不同的,因為背后的業(yè)務場景什么的都不一樣。
所以,這篇文章主要是給大家提供一個回答這類問題的思路,不涉及任何復雜架構設計,讓你不至于在面試中被問到這個問題時,跟面試官大眼瞪小眼。
具體要真能在面試的時候回答好這個問題,建議各位參考一下本文思路,然后對你自己手頭負責的系統(tǒng)多去思考一下,***做一些相關的架構實踐。
先考慮一個最簡單的系統(tǒng)架構
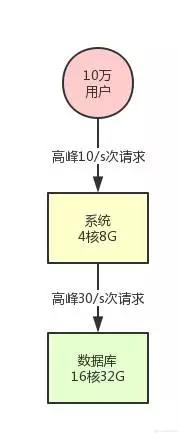
假設剛剛開始你的系統(tǒng)就部署在一臺機器上,背后就連接了一臺數(shù)據(jù)庫,數(shù)據(jù)庫部署在一臺服務器上。
我們甚至可以再現(xiàn)實點,給個例子,你的系統(tǒng)部署的機器是 4 核 8G,數(shù)據(jù)庫服務器是 16 核 32G。
此時假設你的系統(tǒng)用戶量總共就 10 萬,用戶量很少,日活用戶按照不同系統(tǒng)的場景有區(qū)別,我們取一個較為客觀的比例,10% 吧,每天活躍的用戶就 1 萬。
按照 28 法則,每天高峰期算它 4 個小時,高峰期活躍的用戶占比達到 80%,就是 8000 人活躍在 4 小時內。
然后每個人對你的系統(tǒng)發(fā)起的請求,我們算他每天是 20 次吧。那么高峰期 8000 人發(fā)起的請求也才 16 萬次,平均到 4 小時內的每秒(14400 秒),每秒也就 10 次請求。
好吧!完全跟高并發(fā)搭不上邊,對不對?
然后系統(tǒng)層面每秒是 10 次請求,對數(shù)據(jù)庫的調用每次請求都會有好幾次數(shù)據(jù)庫操作的,比如做做 crud 之類的。
那么我們取一個一次請求對應 3 次數(shù)據(jù)庫請求吧,那這樣的話,數(shù)據(jù)庫層每秒也就 30 次請求,對不對?
按照這臺數(shù)據(jù)庫服務器的配置,支撐是絕對沒問題的。上述描述的系統(tǒng),用一張圖表示,就是下面這樣:
系統(tǒng)集群化部署
假設此時你的用戶數(shù)開始快速增長,比如注冊用戶量增長了 50 倍,上升到了 500 萬。
此時日活用戶是 50 萬,高峰期對系統(tǒng)每秒請求是 500/s。然后對數(shù)據(jù)庫的每秒請求數(shù)量是 1500/s,這個時候會怎么樣呢?
按照上述的機器配置來說,如果你的系統(tǒng)內處理的是較為復雜的一些業(yè)務邏輯,是那種重業(yè)務邏輯的系統(tǒng)的話,是比較耗費 CPU 的。
此時,4 核 8G 的機器每秒請求達到 500/s 的時候,很可能你會發(fā)現(xiàn)你的機器 CPU 負載較高了。
然后數(shù)據(jù)庫層面,以上述的配置而言,其實基本上 1500/s 的高峰請求壓力的話,還算可以接受。
這個主要是要觀察數(shù)據(jù)庫所在機器的磁盤負載、網絡負載、CPU 負載、內存負載,按照我們的線上經驗而言,那個配置的數(shù)據(jù)庫在 1500/s 請求壓力下是沒問題的。
所以此時你需要做的一個事情,首先就是要支持你的系統(tǒng)集群化部署。
你可以在前面掛一個負載均衡層,把請求均勻打到系統(tǒng)層面,讓系統(tǒng)可以用多臺機器集群化支撐更高的并發(fā)壓力。
比如說這里假設給系統(tǒng)增加部署一臺機器,那么每臺機器就只有 250/s 的請求了。
這樣一來,兩臺機器的 CPU 負載都會明顯降低,這個初步的“高并發(fā)”不就先 cover 住了嗎?
要是連這個都不做,那單臺機器負載越來越高的時候,極端情況下是可能出現(xiàn)機器上部署的系統(tǒng)無法有足夠的資源響應請求了,然后出現(xiàn)請求卡死,甚至系統(tǒng)宕機之類的問題。
所以,簡單小結,***步要做的:
- 添加負載均衡層,將請求均勻打到系統(tǒng)層。
- 系統(tǒng)層采用集群化部署多臺機器,扛住初步的并發(fā)壓力。
此時的架構圖變成下面的樣子:

數(shù)據(jù)庫分庫分表 + 讀寫分離
假設此時用戶量繼續(xù)增長,達到了 1000 萬注冊用戶,然后每天日活用戶是 100 萬。
那么此時對系統(tǒng)層面的請求量會達到每秒 1000/s,系統(tǒng)層面,你可以繼續(xù)通過集群化的方式來擴容,反正前面的負載均衡層會均勻分散流量過去的。
但是,這時數(shù)據(jù)庫層面接受的請求量會達到 3000/s,這個就有點問題了。
此時數(shù)據(jù)庫層面的并發(fā)請求翻了一倍,你一定會發(fā)現(xiàn)線上的數(shù)據(jù)庫負載越來越高。
每次到了高峰期,磁盤 IO、網絡 IO、內存消耗、CPU 負載的壓力都會很高,大家很擔心數(shù)據(jù)庫服務器能否抗住。
沒錯,一般來說,對那種普通配置的線上數(shù)據(jù)庫,建議就是讀寫并發(fā)加起來,按照上述我們舉例的那個配置,不要超過 3000/s。
因為數(shù)據(jù)庫壓力過大,首先一個問題就是高峰期系統(tǒng)性能可能會降低,因為數(shù)據(jù)庫負載過高對性能會有影響。
另外一個,壓力過大把你的數(shù)據(jù)庫給搞掛了怎么辦?
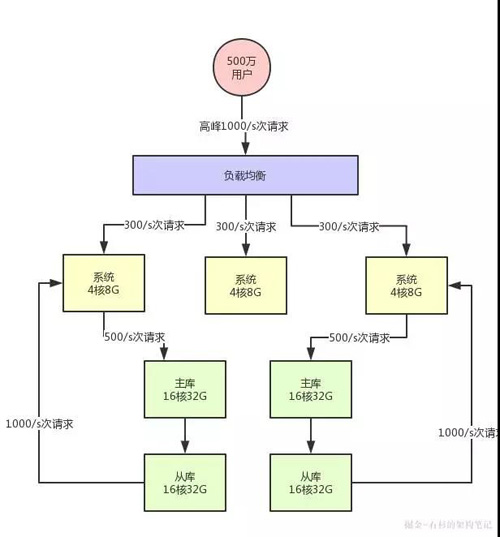
所以此時你必須得對系統(tǒng)做分庫分表 + 讀寫分離,也就是把一個庫拆分為多個庫,部署在多個數(shù)據(jù)庫服務上,這是作為主庫承載寫入請求的。
然后每個主庫都掛載至少一個從庫,由從庫來承載讀請求。
此時假設對數(shù)據(jù)庫層面的讀寫并發(fā)是 3000/s,其中寫并發(fā)占到了 1000/s,讀并發(fā)占到了 2000/s。
那么一旦分庫分表之后,采用兩臺數(shù)據(jù)庫服務器上部署主庫來支撐寫請求,每臺服務器承載的寫并發(fā)就是 500/s。
每臺主庫掛載一個服務器部署從庫,那么 2 個從庫每個從庫支撐的讀并發(fā)就是 1000/s。
簡單總結,并發(fā)量繼續(xù)增長時,我們就需要 focus 在數(shù)據(jù)庫層面:分庫分表、讀寫分離。
此時的架構圖如下所示:
緩存集群引入
接著就好辦了,如果你的注冊用戶量越來越大,此時你可以不停的加機器,比如說系統(tǒng)層面不停加機器,就可以承載更高的并發(fā)請求。
然后數(shù)據(jù)庫層面如果寫入并發(fā)越來越高,就擴容加數(shù)據(jù)庫服務器,通過分庫分表是可以支持擴容機器的,如果數(shù)據(jù)庫層面的讀并發(fā)越來越高,就擴容加更多的從庫。
但是這里有一個很大的問題:數(shù)據(jù)庫其實本身不是用來承載高并發(fā)請求的,所以通常來說,數(shù)據(jù)庫單機每秒承載的并發(fā)就在幾千的數(shù)量級,而且數(shù)據(jù)庫使用的機器都是比較高配置,比較昂貴的機器,成本很高。
如果你就是簡單的不停的加機器,其實是不對的。
所以在高并發(fā)架構里通常都有緩存這個環(huán)節(jié),緩存系統(tǒng)的設計就是為了承載高并發(fā)而生。
所以單機承載的并發(fā)量都在每秒幾萬,甚至每秒數(shù)十萬,對高并發(fā)的承載能力比數(shù)據(jù)庫系統(tǒng)要高出一到兩個數(shù)量級。
所以你完全可以根據(jù)系統(tǒng)的業(yè)務特性,對那種寫少讀多的請求,引入緩存集群。
具體來說,就是在寫數(shù)據(jù)庫的時候同時寫一份數(shù)據(jù)到緩存集群里,然后用緩存集群來承載大部分的讀請求。
這樣的話,通過緩存集群,就可以用更少的機器資源承載更高的并發(fā)。
比如說上面那個圖里,讀請求目前是每秒 2000/s,兩個從庫各自抗了 1000/s 讀請求,但是其中可能每秒 1800 次的讀請求都是可以直接讀緩存里的不怎么變化的數(shù)據(jù)的。
那么此時你一旦引入緩存集群,就可以抗下來這 1800/s 讀請求,落到數(shù)據(jù)庫層面的讀請求就 200/s。
同樣,給大家來一張架構圖,一起來感受一下:

按照上述架構,它的好處是什么呢?
可能未來你的系統(tǒng)讀請求每秒都幾萬次了,但是可能 80%~90% 都是通過緩存集群來讀的,而緩存集群里的機器可能單機每秒都可以支撐幾萬讀請求,所以耗費機器資源很少,可能就兩三臺機器就夠了。
你要是換成是數(shù)據(jù)庫來試一下,可能就要不停的加從庫到 10 臺、20 臺機器才能抗住每秒幾萬的讀并發(fā),那個成本是極高的。
好了,我們再來簡單小結,承載高并發(fā)需要考慮的第三個點:
- 不要盲目進行數(shù)據(jù)庫擴容,數(shù)據(jù)庫服務器成本昂貴,且本身就不是用來承載高并發(fā)的。
- 針對寫少讀多的請求,引入緩存集群,用緩存集群抗住大量的讀請求。
引入消息中間件集群
接著再來看看數(shù)據(jù)庫寫這塊的壓力,其實是跟讀類似的。
假如說你所有寫請求全部都落地數(shù)據(jù)庫的主庫層,當然是沒問題的,但是寫壓力要是越來越大了呢?
比如每秒要寫幾萬條數(shù)據(jù),此時難道也是不停的給主庫加機器嗎?
可以當然也可以,但是同理,你耗費的機器資源是很大的,這個就是數(shù)據(jù)庫系統(tǒng)的特點所決定的。
相同的資源下,數(shù)據(jù)庫系統(tǒng)太重太復雜,所以并發(fā)承載能力就在幾千/s的量級,所以此時你需要引入別的一些技術。
比如說消息中間件技術,也就是 MQ 集群,它可以非常好的做寫請求異步化處理,實現(xiàn)削峰填谷的效果。
假如說,你現(xiàn)在每秒是 1000/s 次寫請求,其中比如 500 次請求是必須請求過來立馬寫入數(shù)據(jù)庫中的,但是另外 500 次寫請求是可以允許異步化等待個幾十秒,甚至幾分鐘后才落入數(shù)據(jù)庫內的。
那么此時你完全可以引入消息中間件集群,把允許異步化的每秒 500 次請求寫入 MQ,然后基于 MQ 做一個削峰填谷。
比如就以平穩(wěn)的 100/s 的速度消費出來,然后落入數(shù)據(jù)庫中即可,此時就會大幅度降低數(shù)據(jù)庫的寫入壓力。
此時,架構圖變成了下面這樣:
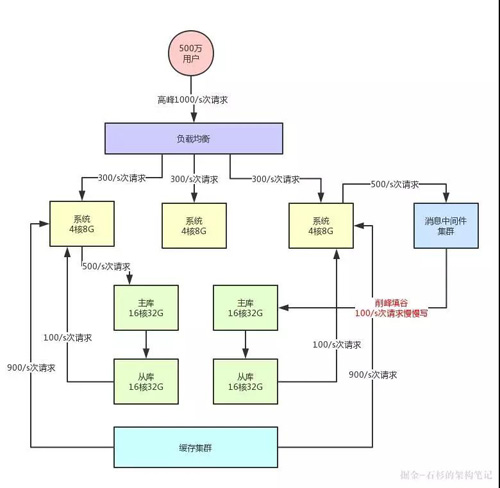
大家看上面的架構圖,首先消息中間件系統(tǒng)本身也是為高并發(fā)而生,所以通常單機都是支撐幾萬甚至十萬級的并發(fā)請求的。
所以,它本身也跟緩存系統(tǒng)一樣,可以用很少的資源支撐很高的并發(fā)請求,用它來支撐部分允許異步化的高并發(fā)寫入是沒問題的,比使用數(shù)據(jù)庫直接支撐那部分高并發(fā)請求要減少很多的機器使用量。
而且經過消息中間件的削峰填谷之后,比如就用穩(wěn)定的 100/s 的速度寫數(shù)據(jù)庫,那么數(shù)據(jù)庫層面接收的寫請求壓力,不就成了 500/s + 100/s = 600/s 了么?
大家看看,是不是發(fā)現(xiàn)減輕了數(shù)據(jù)庫的壓力?到目前為止,通過下面的手段,我們已經可以讓系統(tǒng)架構盡可能用最小的機器資源抗住了***的請求壓力,減輕了數(shù)據(jù)庫的負擔:
- 系統(tǒng)集群化。
- 數(shù)據(jù)庫層面的分庫分表+讀寫分離。
- 針對讀多寫少的請求,引入緩存集群。
- 針對高寫入的壓力,引入消息中間件集群。
初步來說,簡單的一個高并發(fā)系統(tǒng)的闡述是說完了。但是,故事到這里還遠遠沒有結束。
現(xiàn)在能 Hold 住高并發(fā)面試題了嗎?
看完了這篇文章,你覺得自己能回答好面試里的高并發(fā)問題了嗎?
很遺憾,答案是不能。而且我覺得單單憑借幾篇文章是絕對不可能真的讓你完全回答好這個問題的,這里有很多原因在里面。
首先,高并發(fā)這個話題本身是非常復雜的,遠遠不是一些文章可以說的清楚的,它的本質就在于,真實的支撐復雜業(yè)務場景的高并發(fā)系統(tǒng)架構其實是非常復雜的。
比如說每秒百萬并發(fā)的中間件系統(tǒng)、每日百億請求的網關系統(tǒng)、瞬時每秒幾十萬請求的秒殺大促系統(tǒng)、支撐幾億用戶的大規(guī)模高并發(fā)電商平臺架構,等等。
為了支撐高并發(fā)請求,在系統(tǒng)架構的設計時,會結合具體的業(yè)務場景和特點,設計出各種復雜的架構,這需要大量底層技術支撐,需要精妙的架構和機制設計的能力。
最終,各種復雜系統(tǒng)呈現(xiàn)出來的架構復雜度會遠遠超出大部分沒接觸過的同學的想象。
但是那么復雜的系統(tǒng)架構,通過一些文章是很難說的清楚里面的各種細節(jié)以及落地生產的過程的。
其次,高并發(fā)這話題本身包含的內容也遠遠不止本文說的這么幾個 topic:分庫分表、緩存、消息。
一個完整而復雜的高并發(fā)系統(tǒng)架構中,一定會包含:
- 各種復雜的自研基礎架構系統(tǒng)。
- 各種精妙的架構設計(比如熱點緩存架構設計、多優(yōu)先級高吞吐 MQ 架構設計、系統(tǒng)全鏈路并發(fā)性能優(yōu)化設計,等等)。
- 還有各種復雜系統(tǒng)組合而成的高并發(fā)架構整體技術方案。
- 還有 NoSQL(Elasticsearch 等)/負載均衡/Web 服務器等相關技術。
所以大家切記要對技術保持敬畏之心,這些東西都很難通過一些文章來表述清楚。
***,真正在生產落地的時候,高并發(fā)場景下你的系統(tǒng)會出現(xiàn)大量的技術問題。
比如說消息中間件吞吐量上不去需要優(yōu)化、磁盤寫壓力過大性能太差、內存消耗過大容易撐爆、分庫分表中間件不知道為什么丟了數(shù)據(jù),等等吧。
諸如此類的問題非常多,這些也不可能通過文章給全部說清楚。
本文能帶給你什么啟發(fā)?
其實本文的定位,就是對高并發(fā)這個面試 topic 做一個掃盲,因為我發(fā)現(xiàn)大部分來問我這個問題的同學,連本文闡述的最最基本的高并發(fā)架構演進思路可能都沒理解。
當然,也是因為畢竟沒真的做過高并發(fā)系統(tǒng),沒相關經驗,確實很難理解好這個問題。
所以本文就是讓很多沒接觸過的同學有一個初步的感知,這個高并發(fā)到底是怎么回事兒,到底對系統(tǒng)哪里有壓力,要在系統(tǒng)架構里引入什么東西,才可以比較好的支撐住較高的并發(fā)壓力。
而且你可以順著本文的思路繼續(xù)思考下去,結合你自己熟悉和知道的一些技術繼續(xù)思考。
比如說,你熟悉 Elasticsearch 技術,那么你就可以思考,在高并發(fā)的架構之下,是不是可以通過分布式架構的 ES 技術支撐高并發(fā)的搜索?
上面所說,權當拋磚引玉。大家自己平時一定要多思考,多畫圖,盤點自己手頭系統(tǒng)的請求壓力。
計算一下分散到各個中間件層面的請求壓力,到底應該如何利用最少的機器資源***的支撐更高的并發(fā)請求。
這才是一個好的高并發(fā)架構設計思路。
如果起到這個效果,本文就成功了。剩下的,還是建議各位同學,對高并發(fā)這個話題,結合自己手頭負責的系統(tǒng)多做思考。
比如當前業(yè)務場景下,你的系統(tǒng)有多大的請求壓力?如果請求壓力增長 10 倍,你的架構如何支撐?如果請求壓力增長 100 倍,你的架構如何支撐?如果請求壓力增長 1000 倍,你的架構如何支撐?
平時一定多給自己設置一些技術挑戰(zhàn),敦促自己去思考自己的系統(tǒng),***多做寫架構上的演練、落地和實踐,實際操作一下,才有更好的感知。
然后在面試的時候,起碼自己做過一定深度的思考,結合自己負責的系統(tǒng)做過一些實踐,可以跟面試官有一個較為清晰和系統(tǒng)的闡述。
雖然大部分同學可能沒機會經歷那種真正大規(guī)模超高并發(fā)的系統(tǒng)架構的設計,但是本文如果能讓大家平時對自己的項目多一些思考。在面試的時候,有一些系統(tǒng)性的思路和闡述,那么也就達到本文的目的了。
作者:中華石杉
中華石杉:十余年 BAT 架構經驗,一線互聯(lián)網公司技術總監(jiān)。帶領上百人團隊開發(fā)過多個億級流量高并發(fā)系統(tǒng)。現(xiàn)將多年工作中積累下的研究手稿、經驗總結整理成文,傾囊相授。微信公眾號:石杉的架構筆記(ID:shishan100)。