50種常用的matplotlib可視化,再也不用擔心模型背著我亂跑了
數據分析與機器學習中常需要大量的可視化,因此才能直觀了解模型背地里都干了些什么。而在可視化中,matplotlib 算得上是最常用的工具,不論是對數據有個預先的整體了解,還是可視化預測效果,matplotlib 都是不可缺失的模塊。最近 Machine Learning Plus 的作者介紹了 50 種最常用的 matplotlib 可視化圖表,而本文簡要介紹了這篇文章,詳細的 50 種可視化需要查閱原文。
50 種可視化圖原地址:https://www.machinelearningplus.com/plots/top-50-matplotlib-visualizations-the-master-plots-python
介紹
該表格主要介紹了 7 種不同的 matplotlib 可視化類別,讀者可根據目的選擇不同的圖。例如,如果你想要繪制兩個變量之間的關系,查看下面 Correlation 部分;或者如果你想展示某個變量的動態變化,查看下面的 Change 部分。
- 一個美麗的圖表應該:
- 提供準確、有需求的信息,不歪曲事實;
- 設計簡單,獲取時不會太費力;
- 美感是為了支持這些信息,而不是為了掩蓋這些信息;
- 不要提供太過豐富的信息與太過復雜的結構。
如下所示為 7 種不同類型的可視化圖表:協相關性主要描述的是不同變量之間的相互關系;偏差主要展現出不同變量之間的差別;排序主要是一些有序的條形圖、散點圖或斜線圖等;分布就是繪制概率與統計中的分布圖,包括離散型的直方圖和連續型的概率密度分布圖等。后面還有變量的時序變化圖和類別圖等常見的可視化制圖類別。


配置
在繪制這 50 種可視化圖之前,我們需要配置一下依賴項以及通用設定,當然后面有一些獨立的美圖會修改通用設定。如果讀者看中了某種可視化圖,那么用這些配置再加上對應的可視化代碼就能嵌入到我們自己的項目中。
如下所示 pandas 與 numpy 主要用于讀取和處理數據,matplotlib 與 seaborn 主要用于可視化數據。其中 seaborn 其實是 matplotlib 上的一個高級 API 封裝,在大多數情況下使用 seaborn 就能做出很有吸引力的圖,而使用 matplotlib 能制作更具特色的圖。
- # !pip install brewer2mpl
- import numpy as np
- import pandas as pd
- import matplotlib as mpl
- import matplotlib.pyplot as plt
- import seaborn as sns
- import warnings; warnings.filterwarnings(action='once')
- large = 22; med = 16; small = 12
- params = {'axes.titlesize': large,
- 'legend.fontsize': med,
- 'figure.figsize': (16, 10),
- 'axes.labelsize': med,
- 'axes.titlesize': med,
- 'xtick.labelsize': med,
- 'ytick.labelsize': med,
- 'figure.titlesize': large}
- plt.rcParams.update(params)
- plt.style.use('seaborn-whitegrid')
- sns.set_style("white")
- %matplotlib inline
- # Version
- print(mpl.__version__) #> 3.0.0
- print(sns.__version__) #> 0.9.0
制圖示意
前面列出了 7 大類共 50 種不同的可視化圖,但我們無法一一介紹,因此我們從協相關性、偏差、分布、時序變化和群組圖中各選擇了一個示例,它們能展示不同數據在不同情況下的可視化需求。
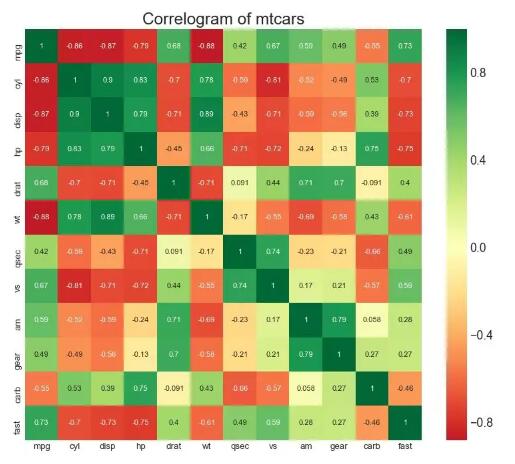
1. 相關圖(Correllogram)
若有兩種變量,且它們的值為離散的,那么二維相關圖可以表示兩個變量所有可能組合之間的相關性。當然如果是單變量,那么自身所有可能的組合也可以組成一個相關圖:
- # Import Dataset
- df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
- # Plot
- plt.figure(figsize=(12,10), dpi= 80)
- sns.heatmap(df.corr(), xticklabels=df.corr().columns, yticklabels=df.corr().columns, cmap='RdYlGn', center=0, annot=True)
- # Decorations
- plt.title('Correlogram of mtcars', fontsize=22)
- plt.xticks(fontsize=12)
- plt.yticks(fontsize=12)
- plt.show()
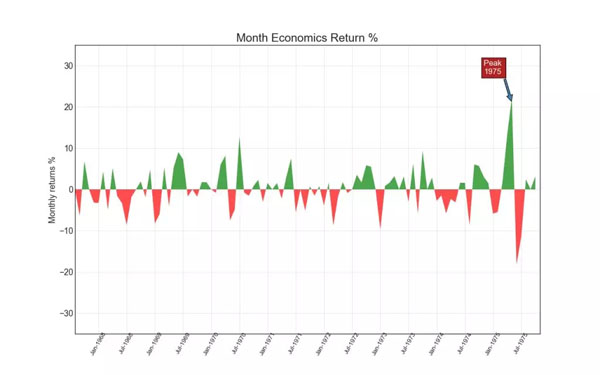
2. 面積圖(Area Chart)
通過使用不同的顏色表示水平軸和線之間的區域,面積圖不僅強調峰值和低谷值,同時還強調它們持續的時間:即峰值持續時間越長,面積越大。
- import numpy as np
- import pandas as pd
- # Prepare Data
- df = pd.read_csv("https://github.com/selva86/datasets/raw/master/economics.csv", parse_dates=['date']).head(100)
- x = np.arange(df.shape[0])
- y_returns = (df.psavert.diff().fillna(0)/df.psavert.shift(1)).fillna(0) * 100
- # Plot
- plt.figure(figsize=(16,10), dpi= 80)
- plt.fill_between(x[1:], y_returns[1:], 0, where=y_returns[1:] >= 0, facecolor='green', interpolate=True, alpha=0.7)
- plt.fill_between(x[1:], y_returns[1:], 0, where=y_returns[1:] <= 0, facecolor='red', interpolate=True, alpha=0.7)
- # Annotate
- plt.annotate('Peak \n1975', xy=(94.0, 21.0), xytext=(88.0, 28),
- bbox=dict(boxstyle='square', fc='firebrick'),
- arrowprops=dict(facecolor='steelblue', shrink=0.05), fontsize=15, color='white')
- # Decorations
- xtickvals = [str(m)[:3].upper()+"-"+str(y) for y,m in zip(df.date.dt.year, df.date.dt.month_name())]
- plt.gca().set_xticks(x[::6])
- plt.gca().set_xticklabels(xtickvals[::6], rotation=90, fontdict={'horizontalalignment': 'center', 'verticalalignment': 'center_baseline'})
- plt.ylim(-35,35)
- plt.xlim(1,100)
- plt.title("Month Economics Return %", fontsize=22)
- plt.ylabel('Monthly returns %')
- plt.grid(alpha=0.5)
- plt.show()
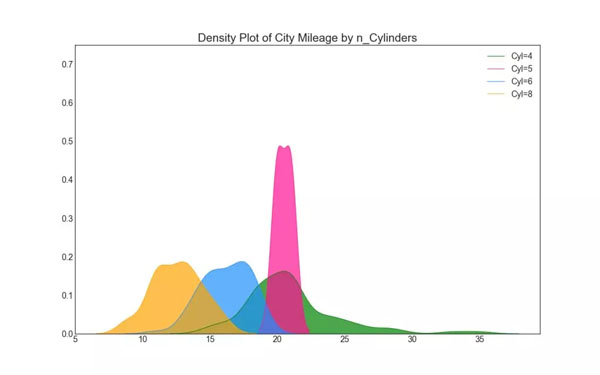
3. 密度圖(Density Plot)
在概率論與統計學習方法中,可視化概率密度就變得非常重要了。這種密度圖正是可視化連續型隨機變量分布的利器,分布曲線上的每一個點都是概率密度,分布曲線下的每一段面積都是特定情況的概率。如下所示,通過將它們按「response」變量分組,我們可以了解 X 軸和 Y 軸之間的關系。
- # Import Data
- df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
- # Draw Plot
- plt.figure(figsize=(16,10), dpi= 80)
- sns.kdeplot(df.loc[df['cyl'] == 4, "cty"], shade=True, color="g", label="Cyl=4", alpha=.7)
- sns.kdeplot(df.loc[df['cyl'] == 5, "cty"], shade=True, color="deeppink", label="Cyl=5", alpha=.7)
- sns.kdeplot(df.loc[df['cyl'] == 6, "cty"], shade=True, color="dodgerblue", label="Cyl=6", alpha=.7)
- sns.kdeplot(df.loc[df['cyl'] == 8, "cty"], shade=True, color="orange", label="Cyl=8", alpha=.7)
- # Decoration
- plt.title('Density Plot of City Mileage by n_Cylinders', fontsize=22)
- plt.legend()
- plt.show()
此外值得注意的是,深度學習,尤其是深度生成模型中的分布極其復雜,它們是不能直接可視化的,我們一般會通過 T-SNE 等降維方法可視化。
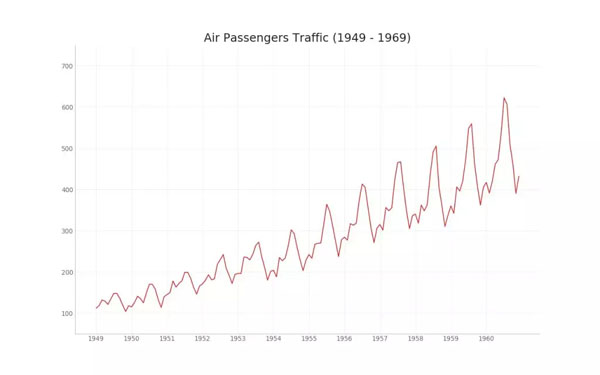
4. 時序變化圖(Time Series Plot)
時序變化圖也是機器學習中最常見的一種可視化圖表,不論是可視化損失函數還是準確率,都需要這種時序變化圖的幫助。這種圖主要關注某個變量怎樣隨時間變化而變化,以下展示了從 1949 到 1969 航空客運量的變化:
- # Import Data
- df = pd.read_csv('https://github.com/selva86/datasets/raw/master/AirPassengers.csv')
- # Draw Plot
- plt.figure(figsize=(16,10), dpi= 80)
- plt.plot('date', 'traffic', data=df, color='tab:red')
- # Decoration
- plt.ylim(50, 750)
- xtick_location = df.index.tolist()[::12]
- xtick_labels = [x[-4:] for x in df.date.tolist()[::12]]
- plt.xticks(ticks=xtick_location, labels=xtick_labels, rotation=0, fontsize=12, horizontalalignment='center', alpha=.7)
- plt.yticks(fontsize=12, alpha=.7)
- plt.title("Air Passengers Traffic (1949 - 1969)", fontsize=22)
- plt.grid(axis='both', alpha=.3)
- # Remove borders
- plt.gca().spines["top"].set_alpha(0.0)
- plt.gca().spines["bottom"].set_alpha(0.3)
- plt.gca().spines["right"].set_alpha(0.0)
- plt.gca().spines["left"].set_alpha(0.3)
- plt.show()
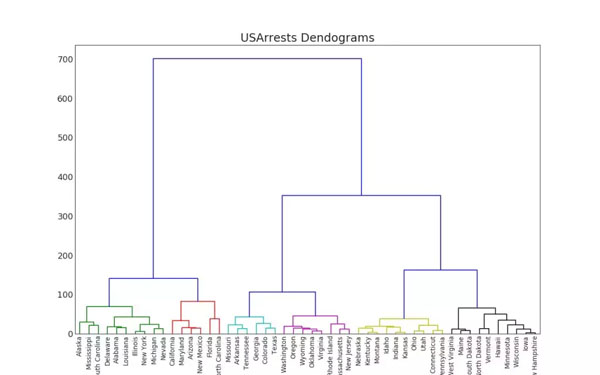
5. 樹狀圖(Dendrogram)
樹狀圖是另一個比較有用的圖表,層次聚類或決策樹等算法可以使用它完成優美的可視化。樹形圖是以樹的圖形表示數據或模型結構,以父層和子層的結構來組織對象,是枚舉法的一種表達方式。下圖展示了一種神似層次聚類算法的圖表:
- import scipy.cluster.hierarchy as shc
- # Import Data
- df = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/USArrests.csv')
- # Plot
- plt.figure(figsize=(16, 10), dpi= 80)
- plt.title("USArrests Dendograms", fontsize=22)
- dend = shc.dendrogram(shc.linkage(df[['Murder', 'Assault', 'UrbanPop', 'Rape']], method='ward'), labels=df.State.values, color_threshold=100)
- plt.xticks(fontsize=12)
- plt.show()
【本文是51CTO專欄機構“機器之心”的原創文章,微信公眾號“機器之心( id: almosthuman2014)”】