Netflix數據庫架構變革:縮放時間序列的數據存儲
2016年1月,Netflix在全球范圍內擴展,向130個國家開放服務,支持20種語言。2016年晚些時候,電視體驗逐漸演變為在瀏覽體驗期間包含視頻預覽。更多的成員,更多的語言和更多的視頻播放將時間序列數據存儲架構從***部分(https://medium.com/netflix-techblog/scaling-time-series-data-storage-part-i-ec2b6d44ba39)延伸至其突破點。在本文的第二部分中,我們將探討該架構的局限性,并描述如何在演化的下一階段重新構建。
突破點
***部分的架構將所有觀看數據視為相同,無論類型(完整標題播放與視頻預覽)或年齡(標題的查看時間)。隨著該功能推廣到更多設備,預覽與完整視圖的比例迅速增長。到2016年底,我們看到該數據存儲在一個季度內增長了30%; 由于對該數據存儲的潛在影響,視頻預覽的推出被推遲。簡單的解決方案是擴展底層的查看數據Cassandra(C *)集群以適應這種增長,但它已經是使用中***的集群,并且接近集群大小限制,很少有C *用戶成功通過。必須要做點什么,但那太早了。
重新思考我們的設計
我們挑戰自己,重新思考我們的方法,并設計出一種至少能實現5倍增長的方法。我們有可以從***部分的架構中重用的模式,但只有這些模式本身是不夠的,還需要新的模式和技術。
分析
我們首先分析了數據集的訪問模式,得到三種不同的數據類別:
• 完整標題播放
• 視頻預覽播放
• 語言偏好(即播放了哪些字幕/配音,表示成員在播放給定語言的字幕時的偏好是什么)
對于每個類別,我們發現了另一種模式——大多數訪問都是針對最近的數據。隨著數據年齡的增長,所需的詳細程度降低。將這些見解和我們與數據消費者的對話結合起來,我們討論了哪些數據需要詳細信息以及持續多長時間。
存儲效率低下
對于增長最快的數據集,視頻預覽和語言信息,我們的合作伙伴只需要最近的數據。我們的合作伙伴正在過濾非常短暫的視頻預覽視圖,因為它們不是會員對內容意圖的正面或負面信號。此外,我們發現大多數會員為他們觀看的大多數標題選擇相同的subs / dubs語言。在每個查看記錄中存儲相同的語言***項會導致大量數據重復。
客戶端復雜性
我們研究的另一個限制因素是查看數據服務的客戶端庫如何滿足調用者對特定時間段內特定數據的特殊需求。調用者可以通過指定來檢索查看數據:
• 視頻類型——完整標題或視頻預覽
• 時間范圍——***X天/月/年,X對于各種用例不同
• 詳細程度——完整或摘要
• 是否包含subs / dubs信息
對于大多數用例,在從后端服務獲取完整數據后,這些過濾器應用于客戶端。正如您可能想象的那樣,這導致了大量不必要的數據傳輸。此外,對于較大的觀看數據集,性能會迅速下降,導致第99個百分點的讀取延遲發生巨大變化。
重新設計
我們的目標是設計一個可以擴展到5倍增長的解決方案,具有合理的成本效率和改進以及更容易預測的延遲。通過對上述問題的分析和理解,我們進行了這次重大的重新設計。以下是我們的設計指南:
數據類別
• 按數據類型分片
• 將數據字段簡化為基本元素
數據時代
• 按數據年齡劃分的碎片。對于最近的數據,在設置TTL后過期
• 對于歷史數據,匯總并旋轉到歸檔群集中
性能
• 并行化讀取以提供跨最近和歷史數據的統一抽象
群集分片
以前,我們將所有數據合并到一個集群中,客戶端庫根據類型/年齡/詳細程度過濾數據。我們顛倒了這種方法,現在根據類型/年齡/細節水平對聚類進行分片。這樣可以將每個數據集的不同增長率彼此分離,簡化了客戶端,并改善了讀取延遲。
存儲效率
對于增長最快的數據集、視頻預覽和語言信息,我們能夠與合作伙伴保持一致,僅保留***的數據。我們不會存儲非常短暫的預覽視頻,因為它們不是會員對內容感興趣的良好信號。此外,我們現在存儲初始語言***項,然后僅存儲后續播放的增量。對于絕大多數會員而言,這意味著只存儲一條語言偏好記錄,從而節省大量存儲空間。對于預覽播放和語言偏好數據,我們也有較低的TTL,因此比完整標題播放的數據更容易過期。
如果需要,我們應用***部分中的實時和壓縮技術,其中可配置數量的最近記錄以未壓縮的形式存儲,其余記錄以壓縮形式存儲在單獨的表中。對于存儲較舊數據的集群,我們將數據完全以壓縮形式存儲,在訪問時以較低的存儲成本換取較高的計算成本。
***,我們不是存儲歷史完整標題播放的所有細節,而是在單獨的表中存儲具有較少列的匯總視圖。此摘要視圖也經過壓縮,可進一步優化存儲成本。
總的來說,我們的新架構如下所示:
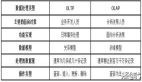
查看數據存儲架構
如上所示,查看數據存儲是按類型分片的——有完整標題播放、預覽標題播放和語言***項的單獨集群。在完整的標題播放中,存儲按年齡分類。對于最近查看數據(最近幾天)、過去查看數據(幾天到幾年)和歷史查看數據都有單獨的集群。***,歷史查看數據只有一個摘要視圖,沒有詳細的記錄
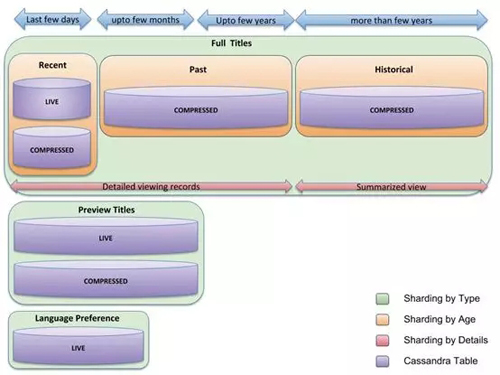
數據流
寫入
將數據寫入到最近的集群中。在輸入之前應用過濾器,例如不存儲非常短的視頻預覽播放或將播放的字幕/配音與以前的***項進行比較,并且僅在與先前行為發生變化時存儲。
讀取
對***數據的請求直接轉到***的集群。當請求更多數據時,并行讀取可以實現高效檢索。
查看數據的***幾天:對于絕大多數需要幾天完整標題播放的用例,信息僅從“最近”集群中讀取。執行對集群中LIVE和COMPRESSED表的并行讀取。繼續本博文系列***部分詳細介紹的實時和壓縮數據集的模式,如果記錄數超出可配置的閾值,則在從LIVE讀取期間,將記錄匯總,壓縮并寫入COMPRESSED表作為具有相同行鍵的新版本。
另外,如果需要語言偏好信息,則對“語言偏好”集群進行并行讀取。同樣,如果需要預覽播放信息,則會對“預覽標題”集群中的LIVE和COMPRESSED表進行并行讀取。與完整標題查看數據類似,如果LIVE表中的記錄數超過可配置閾值,則記錄將被匯總,壓縮并作為具有相同行鍵的新版本寫入COMPRESSED表。
通過對“最近”和“過去”群集的并行讀取,可以啟用最近幾個月的完整標題播放。
匯總的查看數據通過并行讀取 “最近”,“過去”和“歷史”集群返回。然后將數據拼接在一起以獲得完整的匯總視圖。為了減少存儲大小和成本,“歷史”集群中的匯總視圖不包含成員查看的***幾年的更新,因此需要通過匯總來自“最近”和“過去”集群的查看數據來進行擴充。
數據輪換
對于完整的標題播放,不同年齡組之間的記錄移動是異步發生的。在從“最近”集群中讀取會員的查看數據時,如果確定存在超過配置天數的記錄,則任務排隊以將該會員的相關記錄從“最近”移動到“過去”集群。在任務執行時,相關記錄與“過去”集群中COMPRESSED表的現有記錄組合在一起。然后壓縮組合的記錄集并將其存儲在具有新版本的COMPRESSED表中。新版本寫入成功后,將刪除先前的版本記錄。
如果壓縮后的新版本記錄集的大小大于可配置的閾值,則將記錄集分塊并且多個塊被并行寫入。這些記錄從一個集群到另一個集群的后臺傳輸是批處理的,因此每次讀取時都不會觸發它們。所有這些都類似于***部分中詳述的實時壓縮存儲方法中的數據移動。
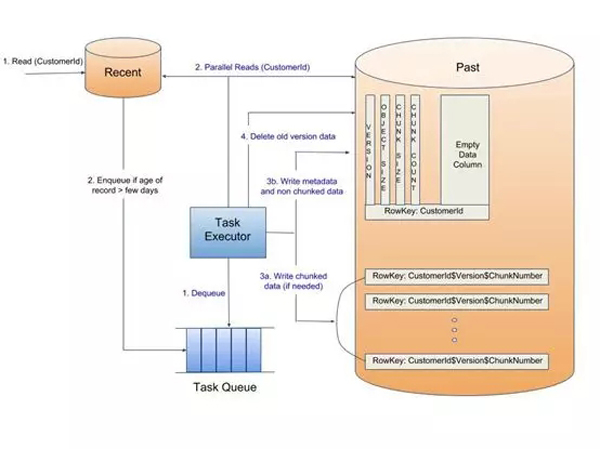
群集之間的數據輪換
類似的記錄到“歷史”集群的移動是在讀取“過去”集群時完成的。使用現有摘要記錄重新處理相關記錄以創建新的摘要記錄。然后將它們壓縮并寫入具有新版本的“歷史”集群中的COMPRESSED表。成功寫入新版本后,將刪除以前的版本記錄。
性能調優
與之前的體系結構一樣,LIVE和COMPRESSED記錄存儲在不同的表中,并進行不同的調整以獲得更好的性能。由于LIVE表具有頻繁的更新和少量的查看記錄,因此壓縮會頻繁運行,并且gc_grace_seconds很小,以減少SSTable的數量和數據大小。經常運行讀取修復和全列族修復以提高數據一致性。由于對COMPRESSED表的更新很少,因此手動和不頻繁的完全壓縮足以減少SSTable的數量。在罕見的更新期間檢查數據的一致性。這樣就不需要進行讀取修復以及全列修復。
緩存層更改
由于我們對來自Cassandra的大數據塊進行了大量并行讀取,因此擁有緩存層有很大的好處。EVCache緩存層架構也進行了更改,以模擬后端存儲架構,如下圖所示。所有緩存都有接近99%的***率,并且在最小化對Cassandra層的讀取請求數量方面非常有效。
緩存層架構
緩存和存儲體系結構之間的一個區別是“摘要”緩存集群存儲整個查看數據的壓縮摘要以進行完整標題播放。緩存***率約為99%,只有一小部分請求被發送到Cassandra層,在該層中,需要并行讀取3個表,并將記錄拼接在一起,以便跨整個查看數據創建摘要。
遷移:初步結果
團隊已經完成了一半以上的更改。已經遷移了利用按數據類型分片的用例。因此,雖然我們沒有完整的結果可以分享,但初步的結果和經驗教訓如下:
• Cassandra的操作特性(壓縮,GC壓力和延遲)的大幅改進僅基于按數據類型分割群集。
• 完整標題的巨大空間,查看數據Cassandra集群,使團隊能夠擴展至少5倍的增長。
• 由于更積極的數據壓縮和數據TTL,大幅節省了成本。
• 重新架構是向后兼容的。現有的API將繼續有效工作,并且預計會有更好和更可預測的延遲。為訪問數據子集而創建的新API將帶來顯著的額外延遲優勢,但需要更改客戶端。這使得在獨立于客戶端更改的情況下推出服務器端更改變得更加容易,并且可以根據客戶端的業務帶寬在不同的時間遷移不同的客戶端。
結論
在過去幾年中,查看數據存儲架構已經取得了很大的進步。我們逐步發展到使用實時數據和壓縮數據并行讀取的模式來查看數據存儲,并將該模式用于團隊中的其它時間序列數據存儲需求。最近,我們對存儲集群進行了分片,以滿足不同用例的獨特需求,并為一些集群使用了實時和壓縮數據模式。我們擴展了實時和壓縮數據移動模式,以便在年齡分片群集之間移動數據。
設計這些可擴展的構建塊以一種簡單而有效的方式擴展我們的存儲層。雖然我們重新設計了5倍于當前用例增長的產品,但我們知道Netflix的產品體驗在不斷變化和改進。我們也正密切關注可能需要進一步進化的變化。