如何正確使用Redis Streams?
譯文【51CTO.com快譯】 Redis是一種內存中的多模式數據庫,適用于諸多使用場合,包括內容緩存、會話存儲、實時分析、消息代理和數據流。去年,我撰文介紹了如何使用Redis Pub/Sub、Lists和Sorted Sets用于實時數據流處理,詳見https://www.infoworld.com/article/3212768/database/how-to-use-redis-for-real-time-stream-processing.html。現在Redis 5.0已發布,Redis有了一種全新的數據結構來管理數據流。
有了Redis Streams數據結構,可以執行比Pub/Sub、Lists和Sorted Sets豐富得多的操作。Redis Streams有眾多優點,它讓你能夠執行下列操作:
- 收集大量高速傳來的數據(唯一的瓶頸是你的網絡I/O);
- 在許多生產者和許多消費者之間建立數據通道;
- 即使生產者和消費者運作的速度不一樣,也能高效地管理數據的消費;
- 你的消費者離線或斷開連接時確保數據持久化;
- 在生產者和消費者之間異步通信;
- 擴大消費者的數量;
- 消費者在消費數據過程中失效時,實現類似事務的數據安全性;
- 有效地使用主內存。
Redis Streams的最大優點是它內置于Redis中,因此部署或管理Redis Streams無需額外的步驟。我在本文中將逐步介紹使用Redis Streams的基本方面,包括如何將數據添加到數據流、如何讀取數據(一次性讀取、異步讀取和到達時讀取等),以滿足消費者的不同使用場合。
一、了解Redis Streams中的數據流
Redis Streams提供了一種“只允許追加”(append only)的數據結構,與日志類似。它提供了可以將數據源添加到數據流、使用數據流以及監控和管理如何消費數據的命令。 Streams數據結構很靈活,讓你可以以幾種方式來連接生產者和消費者。

圖1. Redis Streams的簡單應用,只有一個生產者和一個消費者
圖1表明了Redis Streams的基本用法。單單一個生產者充當數據源,消費者是將數據發送給相關接收者的消息傳遞應用程序。

圖2.多個消費者從Redis Streams讀取數據的應用
圖2中,一個公共數據流被多個消費者使用。使用Redis Streams,消費者可以按照自己的節奏來讀取和分析數據。
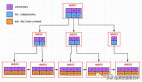
在下一個應用中,如圖3所示,情況變得復雜一點。該服務從多個生產者接收數據,并將所有數據存儲在Redis Streams數據結構中。該應用有多個消費者從Redis Streams讀取數據,讀取數據的還有消費者組(consumer group),消費者組支持無法與生產者保持同樣速度的消費者。

圖3. Redis Streams支持多個生產者和消費者
二、用Redis Streams將數據添加到數據流
圖3中的圖表只顯示了向Redis Stream添加數據的一種方法。雖然一個或多個生產者可以向數據結構添加數據,但任何新數據始終追加到數據流的末尾。
1.添加數據的默認方法
這是向Redis Streams添加數據的最簡單方法:
- XADD mystream * name Anna
- XADD mystream * name Bert
- XADD mystream * name Cathy
在上述命令中,XADD是Redis命令,mystream是數據流的名稱,Anna、Bert和Cathy是每一行添加的名稱,而*操作符告訴Redis為每一行自動生成識別符。這個命令得出三個mystream條目:
- 1518951481323-0 name Cathy
- 1518951480723-0 name Bert
- 1518951480106-0 name Anna
2.針對每個條目,為數據添加用戶管理的ID
Redis讓你可以為每個條目維護你自己的識別符(見下面)。雖然這在一些情況下很有用,但依賴自動生成的ID通常來得更簡單:
- XADD mystream 10000000 name Anna
- XADD mystream 10000001 name Bert
- XADD mystream 10000002 name Cathy
這得出下列的mystream條目:
- 10000002-0 name Cathy
- 10000001-0 name Bert
- 10000000-0 name Anna
3.為數據添加最大限制
你可以為數據流設置條目最大數:
- XADD mystream MAXLEN 1000000 * name Anna
- XADD mystream MAXLEN 1000000 * name Bert
- XADD mystream MAXLEN 1000000 * name Cathy
數據流達到1000000個左右條目的長度時,該命令驅逐舊條目。
一個小貼士:Redis Streams將數據存儲在基樹(radix tree)的宏節點中。每個宏節點有幾個數據項(通常在幾十個左右)。如果添加一個近似的MAXLEN值(如下所示),就沒必要為每次插入處理宏節點。如果幾十個數(比如1000000或1000050)對你來說關系不大,可以用近似字符(~)來調用命令,從而優化性能。
- XADD mystream MAXLEN ~ 1000000 * name Anna
- XADD mystream MAXLEN ~ 1000000 * name Bert
- XADD mystream MAXLEN ~ 1000000 * name Cathy
三、用Redis Streams消費來自數據流的數據
Redis Streams結構提供了一套豐富的命令和功能,以便以多種方式消費數據。
1.從數據流的開頭讀取所有內容
場景:數據流已含有你需要處理的數據,而且你想從開頭開始處理數據。
為此你要使用的命令是XREAD,它讓你可以從數據的開頭讀取所有或前N個條目。一條最佳實踐是,逐頁讀取數據始終是好主意。想從數據流的開頭讀取多達100個條目,命令是:
- XREAD COUNT 100 STREAMS mystream 0
假設1518951481323-0是你在上一個命令中收到的數據項的最后一個ID,你可以運行該命令,檢索下100個條目:
- XREAD COUNT 100 STREAMS mystream 1518951481323-1
2.異步消費數據(通過阻塞調用)
場景:你的消費者消費和處理數據的速度比數據添加到數據流的速度還快。
在許多使用場合下,消費者讀取的速度比生產者向數據流添加數據的速度還快。這種情況下,你希望消費者等待、新數據到達時接到通知。BLOCK選項讓你可以指定等待新數據的時長:
- XREAD BLOCK 60000 STREAMS mystream 1518951123456-1
在這里,XREAD返回1518951123456-1之后的所有數據。如果之后沒有數據,查詢將等待N= 60秒,直至新數據到達,然后超時中斷。如果你想要無限期地阻止該命令,按如下方式調用XREAD:
- XREAD BLOCK 0 STREAMS mystream 1518951123456-1
注意:在該示例中,你還可以使用XRANGE命令來逐頁檢索數據。
3.只讀取剛到達的新數據
場景:你只對處理從當前時間點開始的新數據集有興趣。
你反復讀取數據時,從上次停下來的地方重新開始始終是個好主意。比如在前一個示例中,你進行了阻塞調用以讀取大于1518951123456-1的數據。然而,你可能不知道最新的ID。在這種情況下,可以用$符號開始讀取數據流,該符號告訴XREAD命令只檢索新數據。由于該調用使用的BLOCK選項是60秒,它將等到數據流中有一些數據。
- XREAD BLOCK 60000 STREAMS mystream $
這種情況下,你將開始用$選項讀取新數據。然而,不該用$選項進行后續調用。比如說,如果1518951123456-0是之前調用中檢索的數據的ID,你的下一個調用應該是:
- XREAD BLOCK 60000 STREAMS mystream 1518951123456-1
4.迭代數據流以讀取過去的數據
場景:你的數據流已有足夠的數據,你想查詢它已分析到目前為止收集的數據。
可以分別使用XRANGE和XREVRANGE,以向前或向后的方向讀取兩個條目之間的數據。在該示例中,命令讀取1518951123450-0和1518951123460-0之間的數據:
- XRANGE mystream 1518951123450-0 1518951123460-0
XRANGE還讓你可以借助COUNT選項,限制返回的數據項數量。比如說,下列查詢返回兩個間隔之間的前10個數據項。使用該選項,你可以像使用SCAN命令一樣迭代數據流:
- XRANGE mystream 1518951123450-0 1518951123460-0 COUNT 10
如果你不知道查詢的上限或下限,可以將下限換成-、將上限換成+。比如說,下列查詢返回從數據開頭的前10個數據項:
- XRANGE mystream - + COUNT 10
XREVRANGE的語法類似XRANGE,只是下限和上限的順序倒過來。比如說,下列查詢以相反的順序返回數據流末尾的前10個數據項:
- XREVRANGE mystream + - COUNT 10
5.在多個消費者之間劃分數據
場景:消費者消費數據的速度遠低于生產者生成數據的速度。
在某些情況下,包括圖像處理、深度學習和情感分析,消費者與生產者相比可能很慢。這種情況下,可以通過分散消費者并劃分每個消費者消耗的數據的做法,來匹配到達數據的速度與消耗數據的速度。
使用Redis Streams,你可以利用消費者組來完成此任務。多個消費者是消費者組的一部分時,Redis Streams將確保每個消費者都收到一組獨有的數據。
- XREADGROUP GROUP mygroup consumer1 COUNT 2 STREAMS mystream >
當然,關于消費者組如何運作還有更多的東西要了解。Redis Streams消費者組旨在劃分數據、實現災難恢復并提供事務數據安全性。
如你所見,Redis Streams很容易上手。只需下載并安裝Redis 5.0,然后鉆研該項目網站上的Redis Streams教程。
原文標題:How to use Redis Streams,作者:Roshan Kumar
作者簡介:Roshan Kumar是Redis Labs的資深產品經理。他在軟件開發和技術營銷方面有著豐富的從業經驗。Roshan曾供職于惠普和多家成功的硅谷初創公司,包括ZillionTV、 Salorix、Alopa和ActiveVideo。
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】