













MySQL索引設計不可忽視的知識點
本文主要討論MySQL索引的部分知識。將會從MySQL索引基礎、索引優化實戰和數據庫索引背后的數據結構三部分相關內容,下面一一展開。
一、MySQL——索引基礎
首先,我們將從索引基礎開始介紹一下什么是索引,分析索引的幾種類型,并探討一下如何創建索引以及索引設計的基本原則。
此部分用于測試索引創建的user表的結構如下:
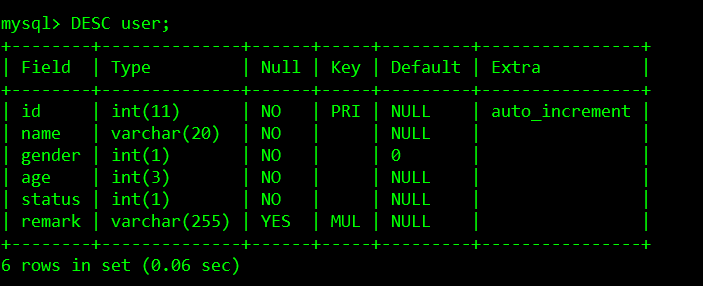
1、什么是索引
“索引(在MySQL中也叫“鍵key”)是存儲引擎快速找到記錄的一種數據結構。”
——《高性能MySQL》
我們需要知道索引其實是一種數據結構,其功能是幫助我們快速匹配查找到需要的數據行,是數據庫性能優化最常用的工具之一。其作用相當于超市里的導購員、書本里的目錄。
2、索引類型
可以使用SHOW INDEX FROM table_name;查看索引詳情:
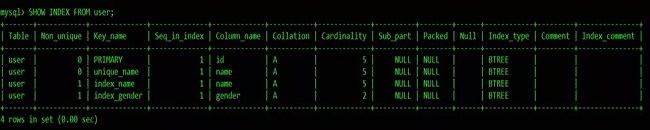
主鍵索引 PRIMARY KEY
它是一種特殊的唯一索引,不允許有空值。一般是在建表的時候同時創建主鍵索引。注意:一個表只能有一個主鍵。

唯一索引 UNIQUE
唯一索引列的值必須唯一,但允許有空值。如果是組合索引,則列值的組合必須唯一。
可以通過ALTER TABLE table_name ADD UNIQUE (column);創建唯一索引:

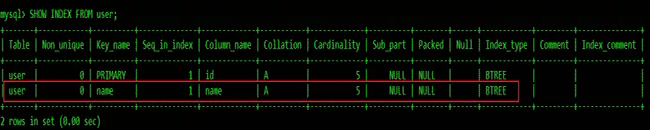
可以通過ALTER TABLE table_name ADD UNIQUE (column1,column2);創建唯一組合索引:


普通索引 INDEX
這是最基本的索引,它沒有任何限制。
可以通過ALTER TABLE table_name ADD INDEX index_name (column);創建普通索引:

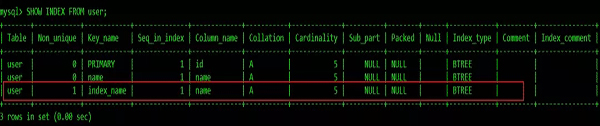
組合索引 INDEX
即一個索引包含多個列,多用于避免回表查詢。
可以通過ALTER TABLE table_name ADD INDEX index_name(column1,column2, column3);創建組合索引:

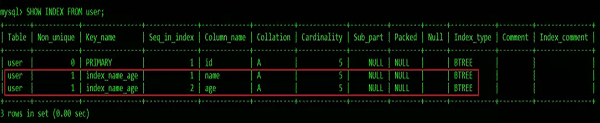
全文索引 FULLTEXT
也稱全文檢索,是目前搜索引擎使用的一種關鍵技術。
可以通過ALTER TABLE table_name ADD FULLTEXT (column);創建全文索引:

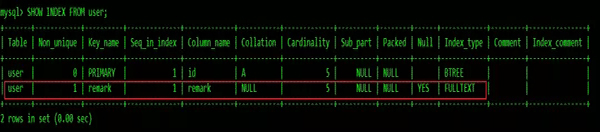
索引一經創建不能修改,如果要修改索引,只能刪除重建。可以使用DROP INDEX index_name ON table_name;刪除索引。
3、索引設計的原則
- 適合索引的列是出現在where子句中的列,或者連接子句中指定的列;
- 基數較小的類,索引效果較差,沒有必要在此列建立索引;
- 使用短索引,如果對長字符串列進行索引,應該指定一個前綴長度,這樣能夠節省大量索引空間;
- 不要過度索引。索引需要額外的磁盤空間,并降低寫操作的性能。在修改表內容的時候,索引會進行更新甚至重構,索引列越多,這個時間就會越長。所以只保持需要的索引有利于查詢即可。
二、MySQL——索引優化實戰
上面我們介紹了索引的基本內容,這部分我們介紹索引優化實戰。在介紹索引優化實戰之前,首先要介紹兩個與索引相關的重要概念,這兩個概念對于索引優化至關重要。
此部分用于測試的user表結構:
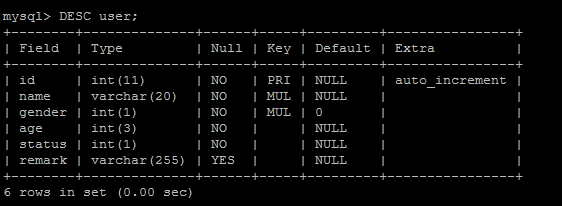
1、索引相關的重要概念
基數
單個列唯一鍵(distict_keys)的數量叫做基數。
- SELECT COUNT(DISTINCT name),COUNT(DISTINCT gender) FROM user;
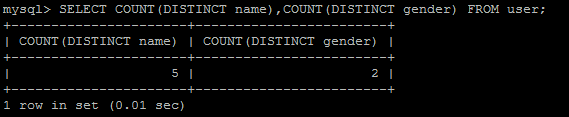
user表的總行數是5,gender列的基數是2,說明gender列里面有大量重復值,name列的基數等于總行數,說明name列沒有重復值,相當于主鍵。
返回數據的比例:
user表中共有5條數據:
- SELECT * FROM user;
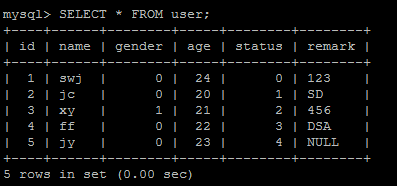
查詢滿足性別為0(男)的記錄數:
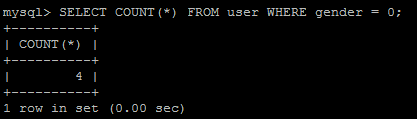
那么返回記錄的比例數是:
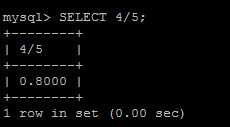
同理,查詢name為'swj'的記錄數:
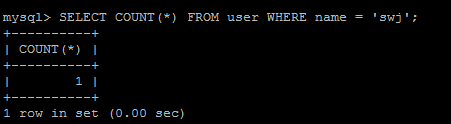
返回記錄的比例數是:
現在問題來了,假設name、gender列都有索引,那么SELECT * FROM user WHERE gender = 0; SELECT * FROM user WHERE name = 'swj';都能命中索引嗎?
user表的索引詳情:

SELECT * FROM user WHERE gender = 0;沒有命中索引,注意filtered的值就是上面我們計算的返回記錄的比例數。

SELECT * FROM user WHERE name = 'swj';命中了索引index_name,因為走索引直接就能找到要查詢的記錄,所以filtered的值為100。

因此,返回表中30%內的數據會走索引,返回超過30%數據就使用全表掃描。當然這個結論太絕對了,也并不是絕對的30%,只是一個大概的范圍。
回表
當對一個列創建索引之后,索引會包含該列的鍵值及鍵值對應行所在的rowid。通過索引中記錄的rowid訪問表中的數據就叫回表。回表次數太多會嚴重影響SQL性能,如果回表次數太多,就不應該走索引掃描,應該直接走全表掃描。
EXPLAIN命令結果中的Using Index意味著不會回表,通過索引就可以獲得主要的數據。Using Where則意味著需要回表取數據。
2、索引優化實戰
有些時候雖然數據庫有索引,但是并不被優化器選擇使用。
我們可以通過SHOW STATUS LIKE 'Handler_read%';查看索引的使用情況:
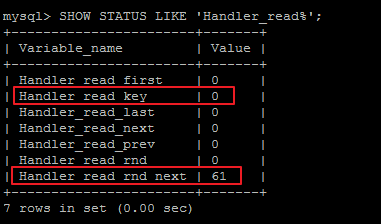
- Handler_read_key:如果索引正在工作,Handler_read_key的值將很高。
- Handler_read_rnd_next:數據文件中讀取下一行的請求數,如果正在進行大量的表掃描,值將較高,則說明索引利用不理想。
索引優化規則:
- 如果MySQL估計使用索引比全表掃描還慢,則不會使用索引。
返回數據的比例是重要的指標,比例越低越容易命中索引。記住這個范圍值——30%,后面所講的內容都是建立在返回數據的比例在30%以內的基礎上。
前導模糊查詢不能命中索引。
name列創建普通索引:

前導模糊查詢不能命中索引:
- EXPLAIN SELECT * FROM user WHERE name LIKE '%s%';

非前導模糊查詢則可以使用索引,可優化為使用非前導模糊查詢:
- EXPLAIN SELECT * FROM user WHERE name LIKE 's%';

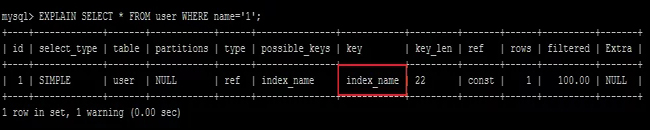
- 數據類型出現隱式轉換的時候不會命中索引,特別是當列類型是字符串,一定要將字符常量值用引號引起來。
- EXPLAIN SELECT * FROM user WHERE name=1;

- EXPLAIN SELECT * FROM user WHERE name='1';
- 復合索引的情況下,查詢條件不包含索引列最左邊部分(不滿足最左原則),不會命中符合索引。
name,age,status列創建復合索引:
- ALTER TABLE user ADD INDEX index_name (name,age,status);

user表索引詳情:
- SHOW INDEX FROM user;

根據最左原則,可以命中復合索引index_name:
- EXPLAIN SELECT * FROM user WHERE name='swj' AND status=1;

注意,最左原則并不是說是查詢條件的順序:
- EXPLAIN SELECT * FROM user WHERE status=1 AND name='swj';

而是查詢條件中是否包含索引最左列字段:
- EXPLAIN SELECT * FROM user WHERE status=2 ;

- union、in、or都能夠命中索引,建議使用in。
union:
- EXPLAIN SELECT*FROM user WHERE status=1
- UNION ALL
- SELECT*FROM user WHERE status = 2;

in:
- EXPLAIN SELECT * FROM user WHERE status IN (1,2);

or:
EXPLAIN SELECT*FROM user WHERE status=1OR status=2;

查詢的CPU消耗:or>in>union
- 用or分割開的條件,如果or前的條件中列有索引,而后面的列中沒有索引,那么涉及到的索引都不會被用到。
- EXPLAIN SELECT * FROM payment WHERE customer_id = 203 OR amount = 3.96;

因為or后面的條件列中沒有索引,那么后面的查詢肯定要走全表掃描,在存在全表掃描的情況下,就沒有必要多一次索引掃描增加IO訪問。
- 負向條件查詢不能使用索引,可以優化為in查詢。
負向條件有:!=、<>、not in、not exists、not like等。
status列創建索引:
- ALTER TABLE user ADD INDEX index_status (status);

user表索引詳情:
- SHOW INDEX FROM user;

負向條件不能命中緩存:
- EXPLAIN SELECT * FROM user WHERE status !=1 AND status != 2;

可以優化為in查詢,但是前提是區分度要高,返回數據的比例在30%以內:
- EXPLAIN SELECT * FROM user WHERE status IN (0,3,4);

- 范圍條件查詢可以命中索引。范圍條件有:<、<=、>、>=、between等。
status,age列分別創建索引:
- ALTER TABLE user ADD INDEX index_status (status);

- ALTER TABLE user ADD INDEX index_age (age);

user表索引詳情:
- SHOW INDEX FROM user;

范圍條件查詢可以命中索引:
- EXPLAIN SELECT * FROM user WHERE status>5;

范圍列可以用到索引(聯合索引必須是最左前綴),但是范圍列后面的列無法用到索引,索引最多用于一個范圍列,如果查詢條件中有兩個范圍列則無法全用到索引:
- EXPLAIN SELECT * FROM user WHERE status>5 AND age<24;

如果是范圍查詢和等值查詢同時存在,優先匹配等值查詢列的索引:
- EXPLAIN SELECT * FROM user WHERE status>5 AND age=24;

- 數據庫執行計算不會命中索引。
- EXPLAIN SELECT * FROM user WHERE age>24;

- EXPLAIN SELECT * FROM user WHERE age+1>24;

計算邏輯應該盡量放到業務層處理,節省數據庫的CPU的同時最大限度的命中索引。
- 利用覆蓋索引進行查詢,避免回表。
被查詢的列,數據能從索引中取得,而不用通過行定位符row-locator再到row上獲取,即“被查詢列要被所建的索引覆蓋”,這能夠加速查詢速度。
user表的索引詳情:

因為status字段是索引列,所以直接從索引中就可以獲取值,不必回表查詢:
Using Index代表從索引中查詢:
- EXPLAIN SELECT status FROM user where status=1;

當查詢其他列時,就需要回表查詢,這也是為什么要避免SELECT*的原因之一:
- EXPLAIN SELECT * FROM user where status=1;

- 建立索引的列,不允許為null。
單列索引不存null值,復合索引不存全為null的值,如果列允許為null,可能會得到“不符合預期”的結果集,所以,請使用not null約束以及默認值。
remark列建立索引:
- ALTER TABLE user ADD INDEX index_remark (remark);

IS NULL可以命中索引:
- EXPLAIN SELECT * FROM user WHERE remark IS NULL;

IS NOT NULL不能命中索引:
- EXPLAIN SELECT * FROM user WHERE remark IS NOT NULL;

雖然IS NULL可以命中索引,但是NULL本身就不是一種好的數據庫設計,應該使用NOT NULL約束以及默認值。
- 更新十分頻繁的字段上不宜建立索引:因為更新操作會變更B+樹,重建索引。這個過程是十分消耗數據庫性能的。
- 區分度不大的字段上不宜建立索引:類似于性別這種區分度不大的字段,建立索引的意義不大。因為不能有效過濾數據,性能和全表掃描相當。另外返回數據的比例在30%以外的情況下,優化器不會選擇使用索引。
- 業務上具有唯一特性的字段,即使是多個字段的組合,也必須建成唯一索引。雖然唯一索引會影響insert速度,但是對于查詢的速度提升是非常明顯的。另外,即使在應用層做了非常完善的校驗控制,只要沒有唯一索引,在并發的情況下,依然有臟數據產生。
- 多表關聯時,要保證關聯字段上一定有索引。
- 創建索引時避免以下錯誤觀念:索引越多越好,認為一個查詢就需要建一個索引;寧缺勿濫,認為索引會消耗空間、嚴重拖慢更新和新增速度;抵制唯一索引,認為業務的唯一性一律需要在應用層通過“先查后插”方式解決;過早優化,在不了解系統的情況下就開始優化。
3、小結
對于自己編寫的SQL查詢語句,要盡量使用EXPLAIN命令分析一下,做一個對SQL性能有追求的程序員。衡量一個程序員是否靠譜,SQL能力是一個重要的指標。作為后端程序員,深以為然。
三、數據庫索引背后的數據結構
第一部分開頭我們簡單提到,索引是存儲引擎快速找到記錄的一種數據結構。進一步說,在數據庫系統里,這種數據結構要滿足特定查找算法,即這些數據結構以某種方式引用(指向)數據,這樣就可以在這些數據結構上實現高級查找算法。
1、B-Tree
B-Tree是一種平衡的多路查找(又稱排序)樹,在文件系統中和數據庫系統中有所應用,主要用作文件的索引。其中的B就表示平衡(Balance) 。
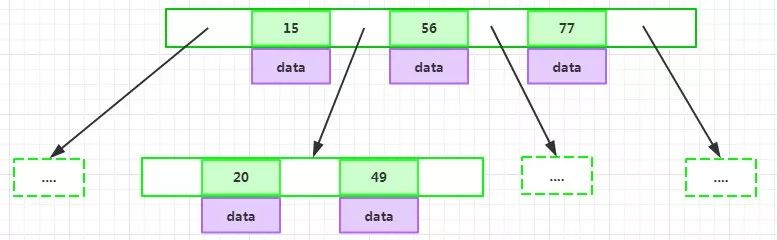
B-Tree的特性
為了描述B-Tree,首先定義一條數據記錄為一個二元組[key, data],key為記錄的鍵值,對于不同數據記錄,key是互不相同的;data為數據記錄除key外的數據。那么B-Tree是滿足下列條件的數據結構:
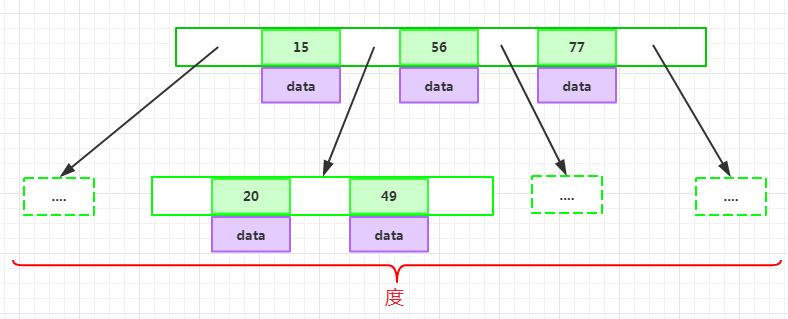
d為大于1的一個正整數,稱為B-Tree的度:
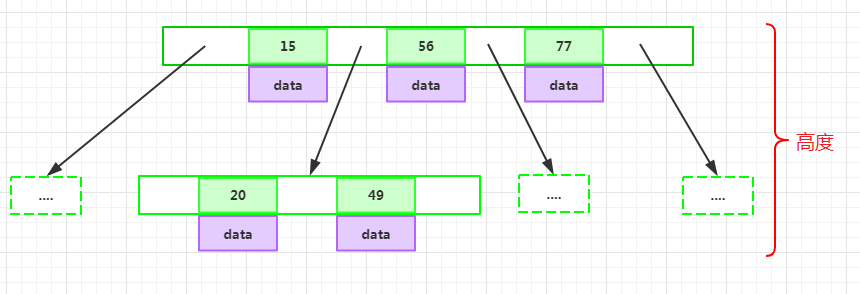
h為一個正整數,稱為B-Tree的高度:
key和指針互相間隔,節點兩端是指針:
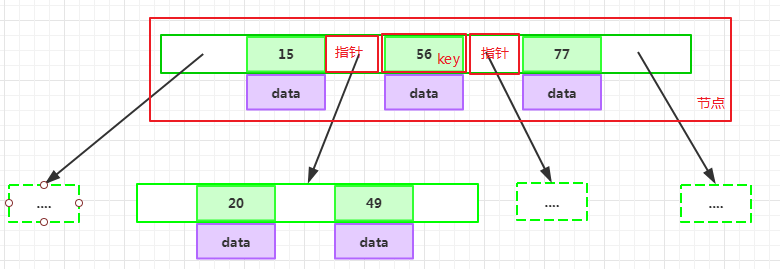
一個節點中的key從左到右非遞減排列:
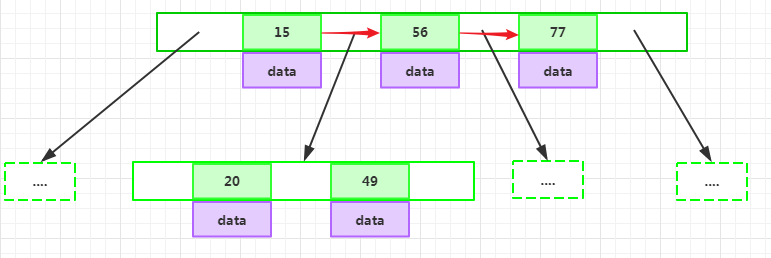
所有節點組成樹結構。
每個指針要么為null,要么指向另外一個節點;每個非葉子節點由n-1個key和n個指針組成,其中d<=n<=2d:
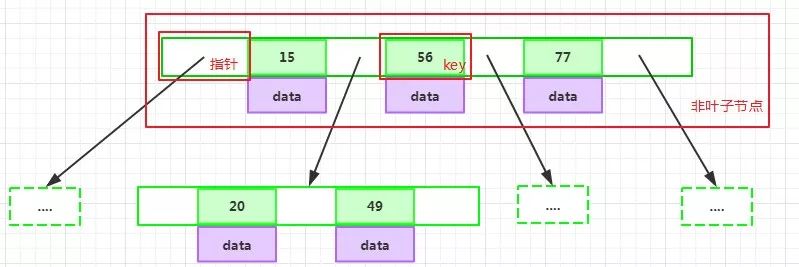
每個葉子節點最少包含一個key和兩個指針,最多包含2d-1個key和2d個指針,葉節點的指針均為null:
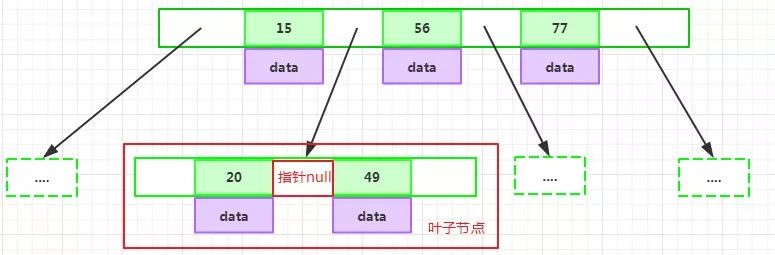
所有葉節點具有相同的深度,等于樹高h。
如果某個指針在節點node最左邊且不為null,則其指向節點的所有key小于key1,其中key1為node的第一個key的值:
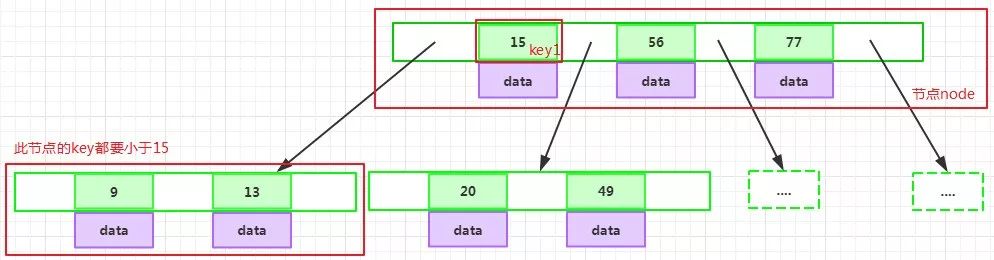
如果某個指針在節點node最右邊且不為null,則其指向節點的所有key大于keym,其中keym為node的最后一個key的值:
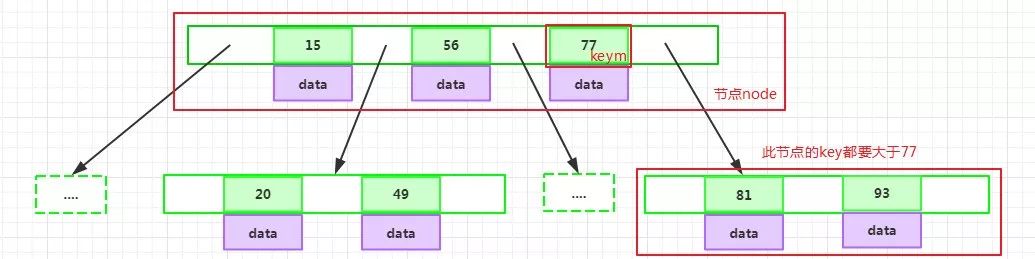
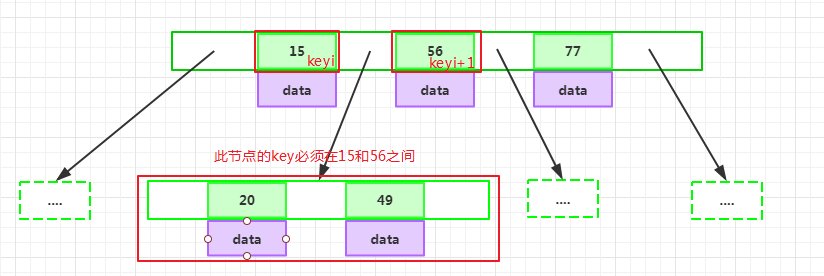
如果某個指針在節點node的左右相鄰key分別是keyi和keyi+1且不為null,則其指向節點的所有key小于keyi+1且大于keyi:
B-Tree查找數據
B-Tree是一個非常有效率的索引數據結構。這主要得益于B-Tree的度可以非常大,高度會變的非常小,只需要二分幾次就可以找到數據。例如一個度為d的B-Tree,設其索引N個key,則其樹高h的上限為logd((N+1)/2)),檢索一個key,其查找節點個數的漸進復雜度為O(logdN)。
在B-Tree中按key檢索數據的算法非常直觀:
- 首先從根節點進行二分查找,如果找到則返回對應節點的data;
- 否則對相應區間的指針指向的節點遞歸進行查找,如果找到則返回對應節點的data;
- 如果找不到,則重復上述“對相應區間的指針指向的節點遞歸進行查找”,直到找到節點或找到null指針,前者查找成功,后者查找失敗。
2、B+Tree
B+Tree是B-Tree的一種變種。一般來說,B+Tree比B-Tree更適合實現外存儲索引結構,具體原因與外存儲器原理及計算機存取原理有關,將在以后討論。
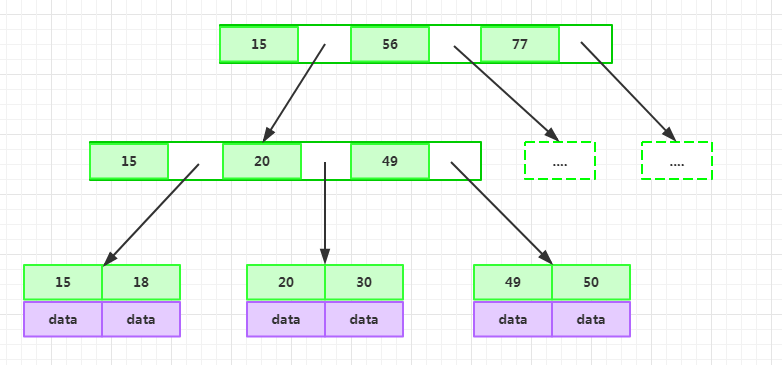
B+Tree的特性
區別于B-Tree:
- 每個節點的指針上限為2d而不是2d+1;
- 內節點不存儲data,只存儲key;葉子節點不存儲指針。
3、帶有順序訪問指針的B+Tree
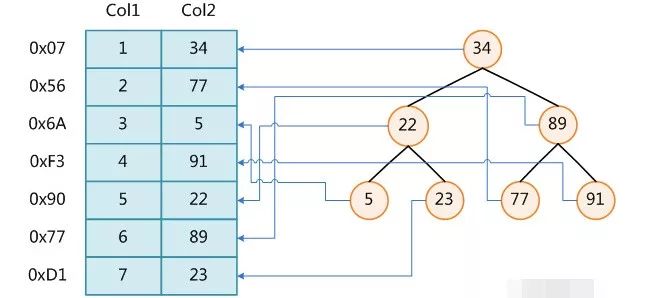
一般在數據庫系統或者文件系統中,并不是直接使用B+Tree作為索引數據結構的,而是在B+Tree的基礎上做了優化,增加了順序訪問指針,提升了區間查詢的性能。
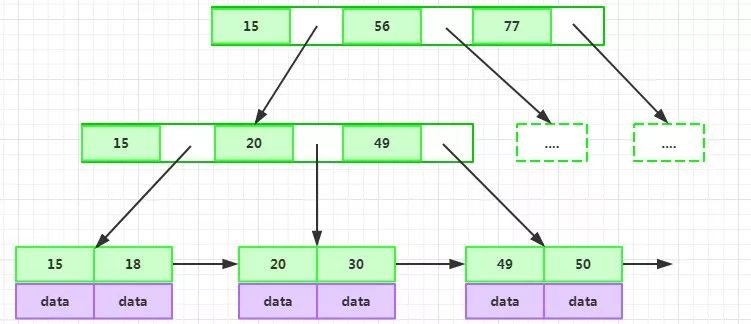
如上圖所示,在B+Tree的每個葉子節點增加一個指向相鄰葉子節點的指針,就形成了帶有順序訪問指針的B+Tree。
例如要查詢18到30之間的數據記錄,只要先找到18,然后順著順序訪問指針就可以訪問到所有的數據節點。這樣就提升了區間查詢的性能。數據庫的索引全掃描index和索引范圍掃描range就是基于此實現的。
四、總結
索引能夠提高系統的性能,設計有效的索引是十分重要的。希望看完的小伙伴能夠有所收獲,如有更多建議,也歡迎留言與我交流!
















