沒有完美的數(shù)據(jù)插補(bǔ)法,只有最適合的
大數(shù)據(jù)文摘出品
編譯:張秋玥、胡笳、夏雅薇
數(shù)據(jù)缺失是數(shù)據(jù)科學(xué)家在處理數(shù)據(jù)時(shí)經(jīng)常遇到的問題,本文作者基于不同的情境提供了相應(yīng)的數(shù)據(jù)插補(bǔ)解決辦法。沒有完美的數(shù)據(jù)插補(bǔ)法,但總有一款更適合當(dāng)下情況。
我在數(shù)據(jù)清理與探索性分析中遇到的最常見問題之一就是處理缺失數(shù)據(jù)。首先我們需要明白的是,沒有任何方法能夠完美解決這個(gè)問題。不同問題有不同的數(shù)據(jù)插補(bǔ)方法——時(shí)間序列分析,機(jī)器學(xué)習(xí),回歸模型等等,很難提供通用解決方案。在這篇文章中,我將試著總結(jié)最常用的方法,并尋找一個(gè)結(jié)構(gòu)化的解決方法。
一、插補(bǔ)數(shù)據(jù)vs刪除數(shù)據(jù)
在討論數(shù)據(jù)插補(bǔ)方法之前,我們必須了解數(shù)據(jù)丟失的原因。
- 隨機(jī)丟失(MAR,Missing at Random):隨機(jī)丟失意味著數(shù)據(jù)丟失的概率與丟失的數(shù)據(jù)本身無關(guān),而僅與部分已觀測到的數(shù)據(jù)有關(guān)。
- 完全隨機(jī)丟失(MCAR,Missing Completely at Random):數(shù)據(jù)丟失的概率與其假設(shè)值以及其他變量值都完全無關(guān)。
- 非隨機(jī)丟失(MNAR,Missing not at Random):有兩種可能的情況。缺失值取決于其假設(shè)值(例如,高收入人群通常不希望在調(diào)查中透露他們的收入);或者,缺失值取決于其他變量值(假設(shè)女性通常不想透露她們的年齡,則這里年齡變量缺失值受性別變量的影響)。
在前兩種情況下可以根據(jù)其出現(xiàn)情況刪除缺失值的數(shù)據(jù),而在第三種情況下,刪除包含缺失值的數(shù)據(jù)可能會(huì)導(dǎo)致模型出現(xiàn)偏差。因此我們需要對(duì)刪除數(shù)據(jù)非常謹(jǐn)慎。請(qǐng)注意,插補(bǔ)數(shù)據(jù)并不一定能提供更好的結(jié)果。
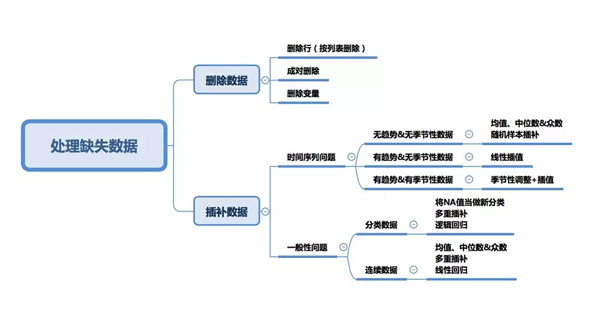
二、刪除
1. 列表刪除
按列表刪除(完整案例分析)會(huì)刪除一行觀測值,只要其包含至少一個(gè)缺失數(shù)據(jù)。你可能只需要直接刪除這些觀測值,分析就會(huì)很好做,尤其是當(dāng)缺失數(shù)據(jù)只占總數(shù)據(jù)很小一部分的時(shí)候。然而在大多數(shù)情況下,這種刪除方法并不好用。因?yàn)橥耆S機(jī)缺失(MCAR)的假設(shè)通常很難被滿足。因此本刪除方法會(huì)造成有偏差的參數(shù)與估計(jì)。
- newdata <- na.omit(mydata)
- # In python
- mydata.dropna(inplace=True)
2. 成對(duì)刪除
在重要變量存在的情況下,成對(duì)刪除只會(huì)刪除相對(duì)不重要的變量行。這樣可以盡可能保證充足的數(shù)據(jù)。該方法的優(yōu)勢(shì)在于它能夠幫助增強(qiáng)分析效果,但是它也有許多不足。它假設(shè)缺失數(shù)據(jù)服從完全隨機(jī)丟失(MCAR)。如果你使用此方法,最終模型的不同部分就會(huì)得到不同數(shù)量的觀測值,從而使得模型解釋非常困難。

觀測行3與4將被用于計(jì)算ageNa與DV1的協(xié)方差;觀測行2、3與4將被用于計(jì)算DV1與DV2的協(xié)方差。
- #Pairwise Deletion
- ncovMatrix <- cov(mydata, use="pairwise.complete.obs")
- #Listwise Deletion
- ncovMatrix <- cov(mydata, use="complete.obs")
3. 刪除變量
在我看來,保留數(shù)據(jù)總是比拋棄數(shù)據(jù)更好。有時(shí),如果超過60%的觀測數(shù)據(jù)缺失,直接刪除該變量也可以,但前提是該變量無關(guān)緊要。話雖如此,插補(bǔ)數(shù)據(jù)總是比直接丟棄變量好一些。
- df <- subset(mydata, select = -c(x,z) )
- df <- mydata[ -c(1,3:4) ]
- In python
- del mydata.column_name
- mydata.drop('column_name', axis=1, inplace=True)
- Time-Series Specific Methods
三、時(shí)間序列分析專屬方法
前推法(LOCF,Last Observation Carried Forward,將每個(gè)缺失值替換為缺失之前的最后一次觀測值)與后推法(NOCB,Next Observation Carried Backward,與LOCF方向相反——使用缺失值后面的觀測值進(jìn)行填補(bǔ))
這是分析可能缺少后續(xù)觀測值的縱向重復(fù)測量數(shù)據(jù)的常用方法。縱向數(shù)據(jù)在不同時(shí)間點(diǎn)跟蹤同一樣本。當(dāng)數(shù)據(jù)具有明顯的趨勢(shì)時(shí),這兩種方法都可能在分析中引入偏差,表現(xiàn)不佳。
線性插值。此方法適用于具有某些趨勢(shì)但并非季節(jié)性數(shù)據(jù)的時(shí)間序列。
季節(jié)性調(diào)整+線性插值。此方法適用于具有趨勢(shì)與季節(jié)性的數(shù)據(jù)。
性+插值法")
季節(jié)性+插值法

線性插值法
法")
LOCF插補(bǔ)法
法")
均值插補(bǔ)法
注:以上數(shù)據(jù)來自imputeTS庫的tsAirgap;插補(bǔ)數(shù)據(jù)被標(biāo)紅。
- library(imputeTS)
- na.random(mydata) # Random Imputation
- na.locf(mydata, option = "locf") # Last Obs. Carried Forward
- na.locf(mydata, option = "nocb") # Next Obs. Carried Backward
- na.interpolation(mydata) # Linear Interpolation
- na.seadec(mydata, algorithm = "interpolation") # Seasonal Adjustment then Linear Interpolation
四、均值,中位數(shù)與眾數(shù)
計(jì)算整體均值、中位數(shù)或眾數(shù)是一種非常基本的插補(bǔ)方法,它是唯一沒有利用時(shí)間序列特征或變量關(guān)系的測試函數(shù)。該方法計(jì)算起來非常快速,但它也有明顯的缺點(diǎn)。其中一個(gè)缺點(diǎn)就是,均值插補(bǔ)會(huì)減少數(shù)據(jù)的變化差異(方差)。
- library(imputeTS)
- na.mean(mydata, option = "mean") # Mean Imputation
- na.mean(mydata, option = "median") # Median Imputation
- na.mean(mydata, option = "mode") # Mode Imputation
- In Python
- from sklearn.preprocessing import Imputer
- values = mydata.values
- imputer = Imputer(missing_values=’NaN’, strategy=’mean’)
- transformed_values = imputer.fit_transform(values)
- # strategy can be changed to "median" and “most_frequent”
五、線性回歸
首先,使用相關(guān)系數(shù)矩陣能夠選出一些缺失數(shù)據(jù)變量的預(yù)測變量。從中選擇最靠譜的預(yù)測變量,并將其用于回歸方程中的自變量。缺失數(shù)據(jù)的變量則被用于因變量。自變量數(shù)據(jù)完整的那些觀測行被用于生成回歸方程;其后,該方程則被用于預(yù)測缺失的數(shù)據(jù)點(diǎn)。在迭代過程中,我們插入缺失數(shù)據(jù)變量的值,再使用所有數(shù)據(jù)行來預(yù)測因變量。重復(fù)這些步驟,直到上一步與這一步的預(yù)測值幾乎沒有什么差別,也即收斂。
該方法“理論上”提供了缺失數(shù)據(jù)的良好估計(jì)。然而,它有幾個(gè)缺點(diǎn)可能比優(yōu)點(diǎn)還值得關(guān)注。首先,因?yàn)樘鎿Q值是根據(jù)其他變量預(yù)測的,他們傾向于“過好”地組合在一起,因此標(biāo)準(zhǔn)差會(huì)被縮小。我們還必須假設(shè)回歸用到的變量之間存在線性關(guān)系——而實(shí)際上他們之間可能并不存在這樣的關(guān)系。
六、多重插補(bǔ)
- 插補(bǔ):將不完整數(shù)據(jù)集缺失的觀測行估算填充m次(圖中m=3)。請(qǐng)注意,填充值是從某種分布中提取的。模擬隨機(jī)抽取并不包含模型參數(shù)的不確定性。更好的方法是采用馬爾科夫鏈蒙特卡洛模擬(MCMC,Markov Chain Monte Carlo Simulation)。這一步驟將生成m個(gè)完整的數(shù)據(jù)集。
- 分析:分別對(duì)(m個(gè))每一個(gè)完整數(shù)據(jù)集進(jìn)行分析。
- 合并:將m個(gè)分析結(jié)果整合為最終結(jié)果。
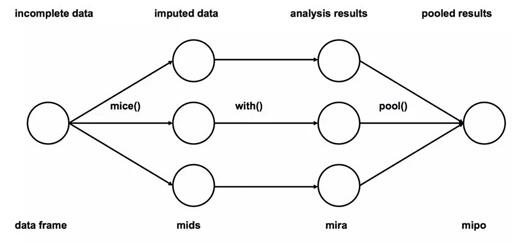
來源:http://www.stefvanbuuren.nl/publications/mice%20in%20r%20-%20draft.pdf
- # We will be using mice library in r
- library(mice)
- # Deterministic regression imputation via mice
- imp <- mice(mydata, method = "norm.predict", m = 1)
- # Store data
- data_imp <- complete(imp)
- # Multiple Imputation
- imp <- mice(mydata, m = 5)
- #build predictive model
- fit <- with(data = imp, lm(y ~ x + z))
- #combine results of all 5 models
- combine <- pool(fit)
這是迄今為止最優(yōu)選的插補(bǔ)方法,因?yàn)樗浅R子谑褂茫⑶以诓逖a(bǔ)模型正確的情況下它不會(huì)引入偏差。
七、分類變量插補(bǔ)
- 眾數(shù)插補(bǔ)法算是一個(gè)法子,但它肯定會(huì)引入偏差。
- 缺失值可以被視為一個(gè)單獨(dú)的分類類別。我們可以為它們創(chuàng)建一個(gè)新類別并使用它們。這是最簡單的方法了。
- 預(yù)測模型:這里我們創(chuàng)建一個(gè)預(yù)測模型來估算用來替代缺失數(shù)據(jù)位置的值。這種情況下,我們將數(shù)據(jù)集分為兩組:一組剔除缺少數(shù)據(jù)的變量(訓(xùn)練組),而另一組則包括缺失變量(測試組)。我們可以用邏輯回歸和ANOVA等方法來進(jìn)行預(yù)測。
- 多重插補(bǔ)法。
八、KNN(K近鄰)
能夠用于數(shù)據(jù)插補(bǔ)的機(jī)器學(xué)習(xí)方法有很多,比如XGBoost與Random Forest,但在這里我們討論KNN方法,因?yàn)樗粡V泛應(yīng)用。在本方法中,我們根據(jù)某種距離度量選擇出k個(gè)“鄰居”,他們的均值就被用于插補(bǔ)缺失數(shù)據(jù)。這個(gè)方法要求我們選擇k的值(最近鄰居的數(shù)量),以及距離度量。KNN既可以預(yù)測離散屬性(k近鄰中最常見的值)也可以預(yù)測連續(xù)屬性(k近鄰的均值)。
根據(jù)數(shù)據(jù)類型的不同,距離度量也不盡相同:
- 連續(xù)數(shù)據(jù):最常用的距離度量有歐氏距離,曼哈頓距離以及余弦距離。
- 分類數(shù)據(jù):漢明(Hamming)距離在這種情況比較常用。對(duì)于所有分類屬性的取值,如果兩個(gè)數(shù)據(jù)點(diǎn)的值不同,則距離加一。漢明距離實(shí)際上與屬性間不同取值的數(shù)量一致。
KNN算法最吸引人的特點(diǎn)之一在于,它易于理解也易于實(shí)現(xiàn)。其非參數(shù)的特性在某些數(shù)據(jù)非常“不尋常”的情況下非常有優(yōu)勢(shì)。
KNN算法的一個(gè)明顯缺點(diǎn)是,在分析大型數(shù)據(jù)集時(shí)會(huì)變得非常耗時(shí),因?yàn)樗鼤?huì)在整個(gè)數(shù)據(jù)集中搜索相似數(shù)據(jù)點(diǎn)。此外,在高維數(shù)據(jù)集中,最近與最遠(yuǎn)鄰居之間的差別非常小,因此KNN的準(zhǔn)確性會(huì)降低。
- library(DMwR)
- knnOutput <- knnImputation(mydata)
- In python
- from fancyimpute import KNN
- # Use 5 nearest rows which have a feature to fill in each row's missing features
- knnOutput = KNN(k=5).complete(mydata)
在上述方法中,多重插補(bǔ)與KNN最為廣泛使用,而由于前者更為簡單,因此其通常更受青睞。
相關(guān)報(bào)道:https://towardsdatascience.com/how-to-handle-missing-data-8646b18db0d4
【本文是51CTO專欄機(jī)構(gòu)大數(shù)據(jù)文摘的原創(chuàng)文章,微信公眾號(hào)“大數(shù)據(jù)文摘( id: BigDataDigest)”】