三行Python代碼,讓數據預處理速度提高2到6倍
Python 是機器學習領域內的***編程語言,它易于使用,也有很多出色的庫來幫助你更快處理數據。但當我們面臨大量數據時,一些問題就會顯現……
目前,大數據(Big Data)這個術語通常用于表示包含數十萬數據點的數據集。在這樣的尺度上,工作進程中加入任何額外的計算都需要時刻注意保持效率。在設計機器學習系統時,數據預處理非常重要——在這里,我們必須對所有數據點使用某種操作。
在默認情況下,Python 程序是單個進程,使用單 CPU 核心執行。而大多數當代機器學習硬件都至少搭載了雙核處理器。這意味著如果沒有進行優化,在數據預處理的時候會出現「一核有難九核圍觀」的情況——超過 50% 的算力都會被浪費。在當前四核處理器(英特爾酷睿 i5)和 6 核處理器(英特爾酷睿 i7)大行其道的時候,這種情況會變得更加明顯。
幸運的是,Python 庫中內建了一些隱藏的特性,可以讓我們充分利用所有 CPU 核心的能力。通過使用 Python 的 concurrent.futures 模塊,我們只需要 3 行代碼就可以讓一個普通的程序轉換成適用于多核處理器并行處理的程序。
標準方法
讓我們舉一個簡單的例子,在單個文件夾中有一個圖片數據集,其中有數萬張圖片。在這里,我們決定使用 1000 張。我們希望在所有圖片被傳遞到深度神經網絡之前將其調整為 600×600 像素分辨率的形式。以下是你經常會在 GitHub 上看到的標準 Python 代碼:
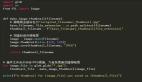
- import glob
- import os
- import cv2
- ### Loop through all jpg files in the current folder
- ### Resize each one to size 600x600
- for image_filename in glob.glob("*.jpg"):
- ### Read in the image data
- img = cv2.imread(image_filename)
- ### Resize the image
- img = cv2.resize(img, (600, 600))
上面的程序遵循你在處理數據腳本時經常看到的簡單模式:
- 首先從需要處理內容的文件(或其他數據)列表開始。
- 使用 for 循環逐個處理每個數據,然后在每個循環迭代上運行預處理。
讓我們在一個包含 1000 個 jpeg 文件的文件夾上測試這個程序,看看運行它需要多久:
- time python standard_res_conversion.py
在我的酷睿 i7-8700k 6 核 CPU 上,運行時間為 7.9864 秒!在這樣的高端 CPU 上,這種速度看起來是難以讓人接受的,看看我們能做點什么。
更快的方法
為了便于理解并行化的提升,假設我們需要執行相同的任務,比如將 1000 個釘子釘入木頭,假如釘入一個需要一秒,一個人就需要 1000 秒來完成任務。四個人組隊就只需要 250 秒。
在我們這個包含 1000 個圖像的例子中,可以讓 Python 做類似的工作:
- 將 jpeg 文件列表分成 4 個小組;
- 運行 Python 解釋器中的 4 個獨立實例;
- 讓 Python 的每個實例處理 4 個數據小組中的一個;
- 結合四個處理過程得到的結果得出最終結果列表。
這一方法的重點在于,Python 幫我們處理了所有棘手的工作。我們只需告訴它我們想要運行哪個函數,要用多少 Python 實例,剩下的就交給它了!只需改變三行代碼。實例:
- import glob
- import os
- import cv2
- import concurrent.futures
- def load_and_resize(image_filename):
- ### Read in the image data
- img = cv2.imread(image_filename)
- ### Resize the image
- img = cv2.resize(img, (600, 600))
- ### Create a pool of processes. By default, one is created for each CPU in your machine.
- with concurrent.futures.ProcessPoolExecutor() as executor:
- ### Get a list of files to process
- image_files = glob.glob("*.jpg")
- ### Process the list of files, but split the work across the process pool to use all CPUs
- ### Loop through all jpg files in the current folder
- ### Resize each one to size 600x600
- executor.map(load_and_resize, image_files)
從以上代碼中摘出一行:
- with concurrent.futures.ProcessPoolExecutor() as executor:
你的 CPU 核越多,啟動的 Python 進程越多,我的 CPU 有 6 個核。實際處理代碼如下:
- executor.map(load_and_resize, image_files)
「executor.map()」將你想要運行的函數和列表作為輸入,列表中的每個元素都是我們函數的單個輸入。由于我們有 6 個核,我們將同時處理該列表中的 6 個項目!
如果再次用以下代碼運行我們的程序:
- time python fast_res_conversion.py
我們可以將運行時間降到 1.14265 秒,速度提升了近 6 倍!
注意:在生成更多 Python 進程及在它們之間整理數據時會有一些開銷,所以速度提升并不總是這么明顯。但是總的來說,速度提升還是非常可觀的。
它總是那么快嗎?
如果你有一個數據列表要處理,而且在每個數據點上執行相似的運算,那么使用 Python 并行池是一個很好的選擇。但有時這不是***解決方案。并行池處理的數據不會在任何可預測的順序中進行處理。如果你對處理后的結果有特殊順序要求,那么這個方法可能不適合你。
你處理的數據也必須是 Python 可以「炮制」的類型。所幸這些指定類別都很常見。以下來自 Python 官方文件:
- None, True, 及 False
- 整數、浮點數、復數
- 字符串、字節、字節數組
- 只包含可挑選對象的元組、列表、集合和字典
- 在模塊頂層定義的函數(使用 def ,而不是 lambda )
- 在模塊頂層定義的內置函數
- 在模塊頂層定義的類
- 這種類的實例,其 __dict__ 或調用__getstate__() 的結果是可選擇的(參見「Pickling Class Instances」一節)。
原文鏈接:
https://towardsdatascience.com/heres-how-you-can-get-a-2-6x-speed-up-on-your-data-pre-processing-with-python-847887e63be5
【本文是51CTO專欄機構“機器之心”的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】