Hadoop中Hive原理及安裝
Hive是什么(官網概念)
Apache Hive™數據倉庫軟件有助于使用SQL讀取,寫入和管理駐留在分布式存儲中的大型數據集。可以將結構投影到已存儲的數據上。提供命令行工具和JDBC驅動程序,用于將用戶連接到Hive。
- Hive是建立在Hadoop (HDFS/MR)上的用于管理和查詢結果化/非結構化的數據倉庫;
- 一種可以存儲、查詢和分析存儲在Hadoop 中的大規模數據的機制;
- Hive 定義了簡單的類SQL 查詢語言,稱為HQL,它允許熟悉SQL 的用戶查詢數據;
- 允許用Java開發自定義的函數UDF來處理內置無法完成的復雜的分析工作;
- Hive沒有專門的數據格式(分隔符等可以自己靈活的設定);
適用場景
- Hive不適用于在線事務處理。 它最適用于傳統的數據倉庫任務
- Hive的執行延遲比較高,因為hive常用于數據分析的,對實時性要求不高;
- Hive優勢在于處理大數據,對于處理小數據沒有優勢,因為hive的執行延遲比較高。
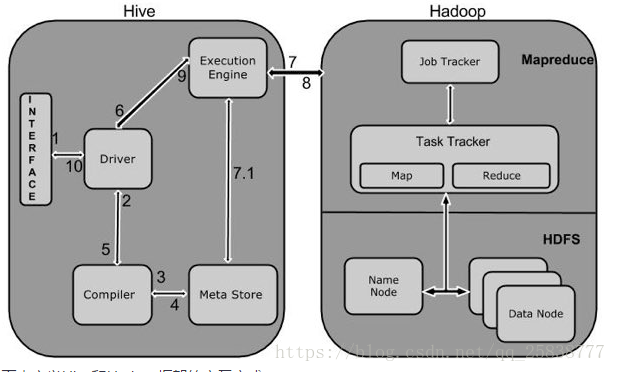
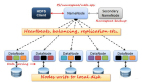
1 Execute Query
Hive接口,如命令行或Web UI發送查詢驅動程序(任何數據庫驅動程序,如JDBC,ODBC等)來執行。
2 Get Plan
在驅動程序幫助下查詢編譯器,分析查詢檢查語法和查詢計劃或查詢的要求。
3 Get Metadata
編譯器發送元數據請求到Metastore(任何數據庫)。
4 Send Metadata
Metastore發送元數據,以編譯器的響應。
5 Send Plan
編譯器檢查要求,并重新發送計劃給驅動程序。到此為止,查詢解析和編譯完成。
6 Execute Plan
驅動程序發送的執行計劃到執行引擎。
7 Execute Job
在內部,執行作業的過程是一個MapReduce工作。執行引擎發送作業給JobTracker,在名稱節點并把它分配作業到TaskTracker,這是在數據節點。在這里,查詢執行MapReduce工作。
7.1 Metadata Ops
與此同時,在執行時,執行引擎可以通過Metastore執行元數據操作。
8 Fetch Result
執行引擎接收來自數據節點的結果。
9 Send Results
執行引擎發送這些結果值給驅動程序。
10 Send Results
驅動程序將結果發送給Hive接口。
Hadoop中實際應用
通過上面流程解釋,要想在hadoop中使用hive,至少需要安裝hive和Metastore(任何數據庫)本文安裝mysql 。
1 , 安裝mysql
下載linux環境下的mysql安裝包,需要兩個,一個是server端的,一個是client端的。
查詢linux機器上默認安裝的mysql或者你以前安裝的mysql, 暴力卸載之 。
- rpm -e mysql-libs-5.xxxxxx_i686 --nodeps
執行安裝命令
- rpm -ivh Mysql-server-xxx.i386.rpm
- rpm -ivh Mysql-client-xxx.i386.rpm
執行命令初始化設置mysql
- /usr/bin/mysql_secure_installation

使用客戶端登陸
- mysql -uroot -proot
登陸成功后輸入命令:(授予mysql遠程用戶連接的權限)
- GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
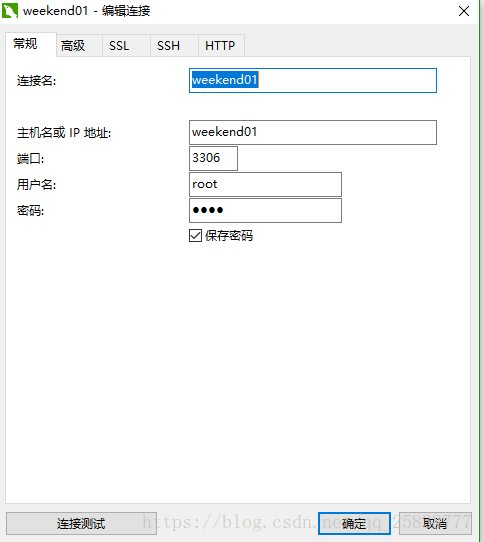
使用遠程客戶端連接(navicat 或Advanced Query Tools等等工具 )我用的navicat, 如圖自行領悟。
到這里hive就安裝搭建完成了!