換個姿勢入門大數據
這篇文章是我近期準備在公司做大數據分享的內容。因為習慣了全英文的 keynote,所以本來標題叫《Introduction to bigdata》,但微信的英文標題字體總覺得有些別扭,所以還是取了這么個中文名。
這篇文章的目的是帶那些對大數據不了解又有興趣的人入門。如果你是老手可以忽略,或者想看看有沒有不一樣的東西也行。
我們學習一個新知識,***步應該是給它個明確的定義。這樣才能知道你學的是什么,哪些該學,哪些又可以先不用管。
然而,大數據雖然很火,但其實是個概念沒那么清晰的東西,不同的人可能有不同的理解。
這次我們不去糾結具體的定義,也忽略那些 4 個 V、6 個 C 之類傳統說教的東西,甚至不想聊架構演進以及各種調優的方法,這些東西講了大家也不一定懂,懂了也記不住,記住了也用不起來。
我們也不去關注 AI、Machine Learning 那些炫酷的應用層面的東西,而是去看看大數據這棟房子的地基是什么模樣。限于篇幅,很多技術細節點到即止,有興趣的同學可以再按需了解,這也正是入門的含義所在。
一
首先***個問題,大數據,大數據,多大叫大?或者換一個角度,什么時候需要用到大數據相關的技術?
這依然是個沒有標準答案的問題,有些人可能覺得幾十 G 就夠大了,也有人覺得幾十 T 也還好。當你不知道多大叫大,或者當你不知道該不該用大數據技術的時候,通常你就還不需要它。
而當你的數據多到單機或者幾臺機器存不下,即使存得下也不好管理和使用的時候;當你發現用傳統的編程方式,哪怕多進程多線程協程全用上,數據處理速度依然很不理想的時候;當你碰到其他由于數據量太大導致的實際問題的時候,可能你需要考慮下是不是該嘗試下大數據相關的技術。
二
從剛才的例子很容易能抽象出大數據的兩類典型應用場景:
- 大量數據的存儲,解決裝不下的問題。
- 大量數據的計算,解決算得慢的問題。
因此,大數據的地基也就由存儲和計算兩部分組成。
三
我們在單機,或者說數據量沒那么大的時候,對于存儲有兩種需求:
- 文件形式的存儲
- 數據庫形式的存儲
文件形式的存儲是最基本的需求,比如各個服務產生的日志、爬蟲爬來的數據、圖片音頻等多媒體文件等等。對應的是最原始的數據。
數據庫形式的存儲則通常是處理之后可以直接供業務程序化使用的數據,比如從訪問日志文件里處理得到訪問者 ip、ua 等信息保存到關系數據庫,這樣就能直接由一個 web 程序展示在頁面上。對應的是處理后方便使用的數據。
大數據也只是數據量大而已,這兩種需求也一樣。雖然不一定嚴謹,但前者我們可以叫做離線(offline)存儲,后者可以叫做在線(online)存儲。
四
離線存儲這塊 HDFS(Hadoop Distributed File System) 基本上是事實上的標準。從名字可以看出,這是個分布式的文件系統。實際上,「分布式」也是解決大數據問題的通用方法,只有支持***橫向擴展的分布式系統才能在理論上有解決***增長的數據量帶來的問題的可能性。當然這里的***要打個引號。
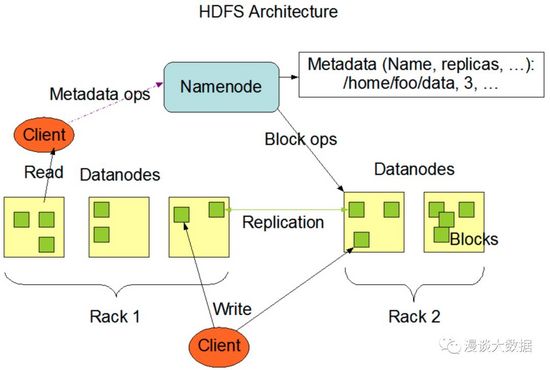
這是 HDFS 的簡易架構圖,看起來仍然不太直觀,其實要點只有幾句話:
- 文件被以 block 為單位拆分后存放在不同的服務器上,每個 block 都在不同機器上做了多份冗余。
- 有 NameNode 和 DataNode 兩種角色,前者存放元數據也就是每個 block 保存在哪里,后者負責存放實際數據。
- 讀和寫數據都要先向 NameNode 拿到對應文件的元數據,然后再找對應的 DataNode 拿實際的數據。
可以看到,HDFS 通過集中記錄元數據的方式實現了分布式的效果,數據量增長只需要添加一些新的 DataNode 就可以了,單機容量不再是限制。
而為了保證數據的高可用,比如某臺服務器突然壞了再也起不來了,HDFS 通過冗余的方式(通常是 3 副本)來解決這個問題。這也是分布式系統里最常用的高可用方式,雖然成本可能很高。
系統級別的高可用才有意義,所以除了數據的高可用,元數據的高可用也至關重要。思路一樣 -- 備份。HDFS 提供了 Secondary NameNode 來提供元數據的冗余。當然更好的方式是使用 NameNode HA 的方式,通過 active/standby 一組 NameNode 來保證不間斷的元數據讀寫服務。
同樣,擴展性剛才也只考慮到數據的橫向擴展,元數據呢?當數據量大到一定程度,元數據也會非常大,類似我們在傳統關系數據庫里碰到的索引膨脹的問題。解決的思路是 NameNode Federation。簡單講就是把原來的一組 active/standy NameNode 拆分成多組,每組只管理一部分元數據。拆分后以類似我們在 Linux 系統里掛載(mount)硬盤的方法對外作為整體提供服務。這些 NameNode 組之間相互獨立,2.x 版本的 HDFS 通過 ViewFS 這個抽象在客戶端通過配置的方式實現對多組 NameNode 的透明訪問,3.x 版本的 HDFS 則實現了全新的 Router Federation 來在服務端保證對多組 NameNode 的透明訪問。
可以看到,元數據的橫向擴展和實際數據的橫向擴展思路完全一樣,都是拆分然后做成分布式。
五
和離線存儲對應的是在線存儲,可以參照傳統的 MySQL、Oracle 等數據庫來理解。在大數據領域最常用的是 HBase。
數據分類的標準很多,HBase 可能被歸類為 NoSQL 數據庫、列式數據庫、分布式數據庫等等。
說它是 NoSQL 數據庫,是因為 HBase 沒有提供傳統關系型數據庫的很多特性。比如不支持通過 SQL 的形式讀寫數據,雖然可以集成 Apache Phoenix 等第三方方案,但畢竟原生不支持;不支持二級索引(Secondary Index),只有順序排列的 rowkey 作為主鍵,雖然通過內置的 Coprocessor 能實現,第三方的 Apache Phoenix 也提供了 SQL 語句創建二級索引的功能,但畢竟原生不支持;Schema 不那么結構化和確定,只提供了列族來對列分類管理,每個列族內的列的數量、類型都沒有限制,完全在數據寫入時確定,甚至只能通過全表掃描確定一共有哪些列。從這些角度看,HBase 甚至都不像是個 DataBase,而更像是個 DataStore。
說它是列式數據庫,是因為底層存儲以列族為單位組織。不同行的相同列族放在一起,同一行的不同列族反而不在一起。這也就使得基于列(族)的過濾等變得更加容易。
說它是分布式數據庫,是因為它提供了強大的橫向擴展的能力。這也是 HBase 能成為大數據在線存儲領域主流方案的主要原因。
HBase 能提供超大數據量存儲和訪問的根本在于,它是基于 HDFS 的,所有的數據都以文件的形式保存在 HDFS 上。這樣就天然擁有了橫向擴展的能力,以及高可用等特性。
解決了數據存儲的問題,剩下就需要在這個基礎上提供一套類似數據庫的 API 服務,并保證這套 API 服務也是可以很容易橫向擴展的。
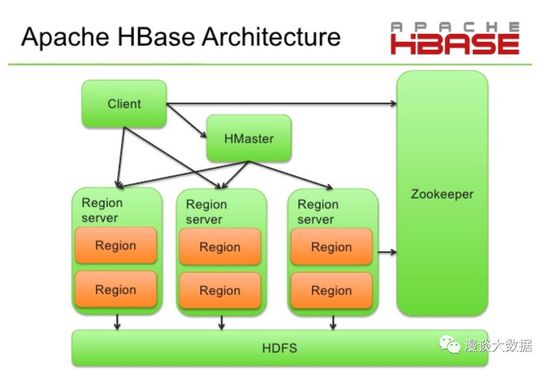
上線這個架構圖已經足夠簡單,我們羅列幾個關鍵點:
- 每個節點上都有一個叫 RegionServer 的程序來提供對數據的讀寫服務
- 每個表被拆分成很多個 Region,然后均衡地分散在各個 RegionServer 上
另外有個 HMaster 的服務,負責對表的創建、修改、刪除已經 Region 相關的各種管理操作。
很容易看出,HBase 的分布式和 HDFS 非常像,RegionServer 類似于 DataNode,HMaster 類似于 NameNode,Region 類似于 Block。
只要在 HDFS 層擴容 DataNode,在 HBase 層擴容 RegionServer,就很容易實現 HBase 的橫向擴展,來滿足更多數據的讀寫需求。
細心的人應該發現了,圖里沒有體現元數據。在 HDFS 里元數據是由 NameNode 掌控的,類似的,HBase 里的元數據由 HMaster 來掌控。HBase 里的元數據保存的是一張表有哪些 Region,又各由哪個 RegionServer 提供服務。
這些元數據,HBase 采用了很巧妙的方法保存 -- 像應用數據那些以 HBase table 的形式保存,這樣就能像操作一張普通表一樣操作元數據了,實現上無疑簡單了很多。
而由于 HBase 的元數據以 Region 為粒度,遠遠比 HDFS 里的 block 粒度大多了,因此元數據的數據量一般也就不會成為性能瓶頸,也就不太需要再考慮元數據的橫向擴展了。
至于高可用,存儲層面已經有 HDFS 保障,服務層面只要提供多個 HMaster 做主備就行了。
六
存儲的話題聊到這里。下面來看看計算這塊。
和存儲類似,無論數據大小,我們可以把計算分為兩種類型:
- 離線(offline)計算,或者叫批量(batch)計算/處理
- 在線(online)計算,或者叫實時(realtime)計算、流(stream)計算/處理
區分批處理和流處理的另一個角度是處理數據的邊界。批處理對應 bounded 數據,數據量的大小有限且確定,而流處理的數據是 unbounded 的,數據量沒有邊界,程序永遠執行下去不會停止。
在大數據領域,批量計算一般用于用于對響應時間和延遲不敏感的場景。有些是業務邏輯本身就不敏感,比如天級別的報表,有些則是由于數據量特別大等原因而被迫犧牲了響應時間和延遲。而相反,流計算則用于對響應時間和延遲敏感的場景,如實時的 PV 計算等。
批量計算的延遲一般較大,在分鐘、小時甚至天級。流處理則一般要求在毫秒或秒級完成數據處理。值得一提的是,介于兩者之間,還有準實時計算的說法,延遲通常在數秒到數十秒。準實時計算很自然能想到是為了在延遲和處理數據量之間達到一個可以接受的平衡。
七
批量計算在大數據領域最老資歷的就是 MapReduce。MapReduce 和前面提到的 HDFS 合在一起就組成了 Hadoop。而 Hadoop 多年來一直是大數據領域事實上的標準基礎設施。從這一點也可以看出,我們按存儲和計算來對大數據技術做分類也是最基本的一種辦法。
MapReduce 作為一個分布式的計算框架(回想下前面說的分布式是解決大數據問題的默認思路),編程模型起源于函數式編程語言里的 map 和 reduce 函數。
得益于 HDFS 已經將數據以 block 為單位切割,MapReduce 框架也就可以很輕松地將數據的初步處理以多個 map 函數的形式分發到不同的服務器上并行執行。map 階段處理的結果又以同樣的思路分布到不同的服務器上并行做第二階段的 reduce 操作,以得到想要的結果。
以大數據領域的「Hello World」-- 「Word Count」為例,要計算 100 個文件共 10 T 數據里每個單詞出現的次數,在 map 階段可能就會有 100 個 mapper 并行去對自己分配到的數據做分詞,然后把同樣的單詞「shuffle」到同樣的 reducer 做聚合求和的操作,這些 reducer 同樣也是并行執行,***獨立輸出各自的執行結果,合在一起就是最終完整的結果。
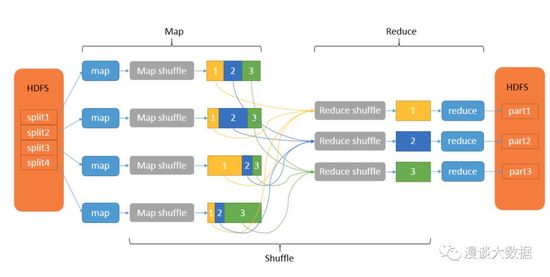
從上圖可以看到,shuffle 操作處理 map 階段的輸出以作為 reduce 階段的輸入,是個承上啟下的關鍵過程。這個過程雖然是 MapReduce 框架自動完成的,但由于涉及非常多的 IO 操作,而 IO 往往是數據處理流程中最消耗性能的部分,因此 shuffle 也就成了性能調優的重點。
可以看到,正是采用了分布式計算的思想,利用了多臺服務器多核并行處理的方法,才使得我們能以足夠快的速度完成對海量數據的處理。
八
MapReduce 框架作為一個分布式計算框架,提供了基礎的大數據計算能力。但隨著使用場景越來越豐富,也慢慢暴露出一些問題。
資源協調
前面我們講分布式存儲的時候提到了 NameNode 這么一個統一管理的角色,類似的,分布式計算也需要有這么一個統一管理和協調的角色。更具體的說,這個角色需要承擔計算資源的協調、計算任務的分配、任務進度和狀態的監控、失敗任務的重跑等職責。
早期 MapReduce -- 即 MR1 -- 完整地實現了這些功能,居中統一協調的角色叫做 JobTracker,另外每個節點上會有一個 TaskTracker 負責收集本機資源使用情況并匯報給 JobTracker 作為分配資源的依據。
這個架構的主要問題是 JobTracker 的職責太多了,在集群達到一定規模,任務多到一定地步后,很容易成為整個系統的瓶頸。
于是有了重構之后的第二代 MapReduce -- MR2,并給它取了個新名字 YARN(Yet-Another-Resource-Negotiator)。
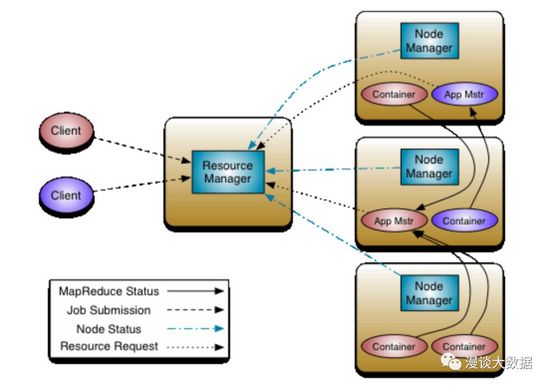
JobTracker 的兩個核心功能 -- 資源管理和任務的調度/監控被拆分開,分別由 ResourceManager 和 ApplicationMaster 來承擔。ResouerceManager 主要負責分配計算資源(其實還包括初始化和監控 ApplicationMaster),工作變的很簡單,不再容易成為瓶頸,部署多個實例后也很容易實現高可用。而 ApplicationMaster 則是每個 App 各分配一個,所有 Job 的資源申請、調度執行、狀態監控、重跑等都由它來組織。這樣,負擔最重的工作分散到了各個 AM 中去了,瓶頸也就不存在了。
開發成本
為了使用 MapReduce 框架,你需要寫一個 Mapper 類,這個類要繼承一些父類,然后再寫一個 map 方法來做具體的數據處理。reduce 也類似。可以看到這個開發和調試成本還是不低的,尤其對于數據分析師等編程能力不那么突出的職位來說。
很自然的思路就是 SQL 化,要實現基本的數據處理,恐怕沒有比 SQL 更通用的語言了。
早期對 MapReduce 的 SQL 化主要有兩個框架實現。一個是 Apache Pig,一個是 Apache Hive。前者相對小眾,后者是絕大部分公司的選擇。
Hive 實現的基本功能就是把你的 SQL 語句解釋成一個個 MapReduce 任務去執行。
比如我們現在創建這么一張測試表:
- create table test2018(id int, name string, province string);
然后通過 explain 命令來查看下面這條 select 語句的執行計劃:
- explain select province, count(*) from test2018 group by province;
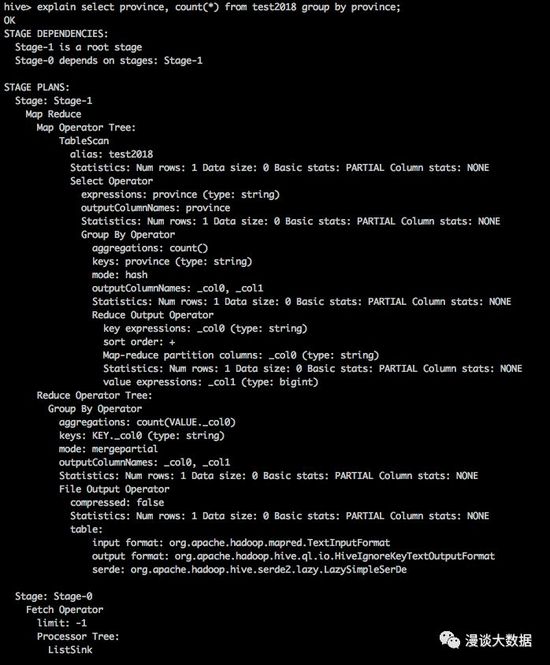
可以看到,Hive 把剛才的 SQL 語句解析成了 MapReduce 任務。這條 SQL 很簡單,如果是復雜的 SQL,可能會被解析成很多個連續依賴執行的 MapReduce 任務。
另外,既然是 SQL,很自然的,Hive 還提供了庫、表這類抽象,讓你來更好的組織你的數據。甚至傳統的數據倉庫技術也能很好地以 Hive 為基礎開展。這又是另一個很大的話題,這里不再展開。
計算速度
MapReduce 每個階段的結果都需要落磁盤,然后再讀出來給下一階段處理。由于是分布式系統,所以也有很多需要網絡傳輸數據的情況。而磁盤 IO 和網絡 IO 都是非常消耗時間的操作。后者可以通過數據本地性(locality)解決 -- 把任務分配到數據所在的機器上執行,前者就很大程度地拖慢了程序執行的速度。
在這個問題上解決的比較好的是 Apache Spark。 Spark 號稱基于內存的分布式計算框架,所有計算都在內存中進行,只要當內存不夠時才會 spill 到磁盤。因此能盡可能地減少磁盤操作。
同時,Spark 基于 DAG(Directed Acyclic Graph)來組織執行過程,知道了整個執行步驟的先后依賴關系,也就有了優化物理執行計劃的可能,很多無謂和重復的 IO 操作也就被省略了。
另外一個不得不提的點是,MapReduce 編程模型太過簡單,導致很多情況下一些并不復雜的運算卻需要好幾個 MapReduce 任務才能完成,這也嚴重拖累了性能。而 Spark 提供了類型非常豐富的操作,也很大程度上提升了性能。
編程模型
上一段提到 Spark 類型豐富的操作提升了性能,另一個好處就是開發復雜度也變低了很多。相比較之下,MapReduce 編程模型的表達能力就顯得非常羸弱了,畢竟很多操作硬要去套用先 map 再 reduce 會非常麻煩。
以分組求平均值為例,在 MapReduce 框架下,需要像前面說的那樣寫兩個類,甚至有人會寫成兩個 MapReduce 任務。
而在 Spark 里面,只要一句 ds.groupby(key).avg() 就搞定了。 真的是沒有對比就沒有傷害。
九
毫無疑問,每個人都希望數據越早算出來越好,所以實時計算或者叫流計算一直是研究和使用的熱點。
前面提到,Hadoop 是大數據領域的標準基礎設施,提供了 HDFS 作為存儲系統,以及 MapReduce 作為計算引擎,但卻并沒有提供對流處理的支持。因此,流處理這個領域也就出現了很多競爭者,沒有形成早些年 MapReduce 那樣一統江湖的局面。
這里我們簡單看下目前流行度***的三個流處理框架:Spark Streaming、Storm 和 Flink。
既然能各自鼎立天下,這些框架肯定也都各有優缺點。篇幅有限,這里我們挑選幾個典型的維度來做對比。
編程范式
常規來說,可以把編程范式或者通俗點說程序的寫法分為兩類:命令式(Imperative)和聲明式(Declarative)。前者需要一步步寫清楚「怎么做」,更接近機器,后者只用寫需要「做什么」,更接近人。前文提到 WordCount 的例子,MapReduce 的版本就屬于命令式,Spark 的版本就屬于聲明式。
不難看出,命令式更繁瑣但也賦予了程序員更強的控制力,聲明式更簡潔但也可能會失去一定的控制力。
延遲(latency)
延遲的概念很簡單,就是一條數據從產生到被處理完經歷的時間。注意這里的時間是實際經歷的時間,而不一定是真正處理的時間。
吞吐量(throughput)
吞吐量就是單位時間內處理數據的數量。和上面的延遲一起通常被認為是流處理系統在性能上最為重要的兩個指標。
下面我們就從這幾個維度來看看這三個流處理框架。
Spark Streaming
Spark Streaming 和我們前面提到的用于離線批處理的 Spark 基于同樣的計算引擎,本質上是所謂的 mirco-batch,只是這個 batch 可以設置的很小,也就有了近似實時的效果。
編程范式
和離線批處理的 Spark 一樣,屬于聲明式,提供了非常豐富的操作,代碼非常簡潔。
延遲
由于是 micro-batch,延遲相對來一條處理一條的實時處理引擎會差一些,通常在秒級。當然可以把 batch 設的更小以減小延遲,但代價是吞吐量會降低。
由于是基于批處理做的流處理,所以就決定了 Spark Streaming 延遲再怎么調優也達不到有些場景的要求。為了解決這個問題,目前尚未正式發布的 Spark 2.3 將會支持 continuous processing,提供不遜于 native streaming 的延遲。continuous processing 顧名思義摒棄了 mirco-batch 的偽流處理,使用和 native streaming 一樣的 long-running task 來處理數據。到時候將以配置的方式讓用戶自己選擇 micro-batch 還是 continuous processing 來做流式處理。
吞吐量
由于是 micro-batch,吞吐量比嚴格意義上的實時處理引擎高不少。從這里也可以看到,micro-batch 是個有利有弊的選擇。
Storm
Storm 的編程模型某種程度上說和 MapReduce 很像,定義了 Spout 用來處理輸入,Bolt 用來做處理邏輯。多個 Spout 和 Bolt 互相連接、依賴組成 Topology。Spout 和 Bolt 都需要像 MR 那樣定義一些類再實現一些具體的方法。
編程范式
很顯然屬于命令式。
延遲
Storm 是嚴格意義上的實時處理系統(native streaming),來一條數據處理一條,所以延遲很低,一般在毫秒級別。
吞吐量
同樣,由于來一條數據處理一條,為了保證容錯(falt tolerance) 采用了逐條消息 ACK 的方式,吞吐量相對 Spark Streaming 這樣的 mirco-batch 引擎就差了不少。
需要補充說明的是,Storm 的升級版 Trident 做了非常大的改動,采用了類似 Spark Streaming 的 mirco-batch 模式,因此延遲比 Storm 高(變差了),吞吐量比 Storm 高(變好了),而編程范式也變成了開發成本更低的聲明式。
Flink
Flink 其實和 Spark 一樣都想做通用的計算引擎,這點上比 Storm 的野心要大。但 Flink 采用了和 Spark 完全相反的方式來支持自己本來不擅長的領域。Flink 作為 native streaming 框架,把批處理看做流處理的特殊情況來達到邏輯抽象上的統一。
- 編程范式
典型的聲明式。
- 延遲
和 Storm 一樣,Flink 也是來一條處理一條,保證了很低的延遲。
- 吞吐量
實時處理系統中,往往低延遲帶來的就是低吞吐量(Storm),高吞吐量又會導致高延遲(Spark Streaming)。這兩個性能指標也是常見的 trade-off 了,通常都需要做取舍。
但 Flink 卻做到了低延遲和高吞吐兼得。關鍵就在于相比 Storm 每條消息都 ACK 的方式,Flink 采取了 checkpoint 的方式來容錯,這樣也就盡可能地減小了對吞吐量的影響。
十
到此為止,批處理和流處理我們都有了大致的了解。不同的應用場景總能二選一找到適合的方案。
然而,卻也有些情況使得我們不得不在同一個業務中同時實現批處理和流處理兩套方案:
- 流處理程序故障,恢復時間超過了流數據的保存時間,導致數據丟失。
- 類似多維度月活計算,精確計算需要保存所有用戶 id 來做去重,由此帶來的存儲開銷太大,因此只能使用 hyperloglog 等近似算法。
- ...
這些場景下,往往會采用流處理保證實時性,再加批處理校正來保證數據正確性。由此還專門產生了一個叫 Lambda Architecture 的架構。
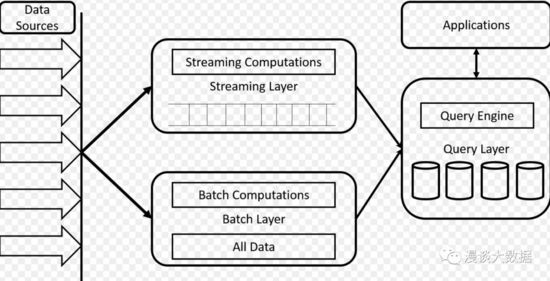
流處理層和批處理層各自獨立運行輸出結果,查詢層根據時間選擇用哪份結果展示給用戶。比如最近一天用流處理的實時但不一定精確的結果,超過一天就用批處理不實時但精確的結果。
Lambda Architecture 確實能解決問題,但流處理和批處理兩套程序,再加上頂在前面的查詢服務,帶來的開發和維護成本也不小。
因此,近年來也有人提出了 Kappa Architecture,帶來了另一種統一的思路,但也有明顯的缺點。限于篇幅這里不再贅述。
十一
計算框架是大數據領域競爭最激烈的方向之一,除了前面提到的方案,還有 Impla、Tez、 Presto、Samza 等等。很多公司都喜歡造輪子,并且都聲稱自己的輪子比別人的好。而從各個框架的發展歷程來看,又有很明顯的互相借鑒的意思。
在眾多選擇中,Spark 作為通用型分布式計算框架的野心和能力已經得到充分的展示和證實,并且仍然在快速地進化: Spark SQL 支持了類 Hive 的純 SQL 數據處理,Spark Streaming 支持了實時計算,Spark MLlib 支持了機器學習,Spark GraphX 支持了圖計算。而流處理和批處理底層執行引擎的統一,也讓 Spark 在 Lambda Architecture 下的開發和維護成本低到可以接受。
所以,出于技術風險、使用和維護成本的考慮,Spark 是我們做大數據計算的***。當然,如果有些實際應用場景 Spark 不能很好的滿足,也可以選擇其他計算框架作為補充。比如如果對延遲(latency) 非常敏感,那 Storm 和 Flink 就值得考慮了。
十二
如開篇所說,大數據是個非常廣的領域,初學者很容易迷失。希望通過這篇文章,能讓大家對大數據的基礎有個大概的了解。限于篇幅,很多概念和技術都點到即止,有興趣的同學可以再擴展去學習。相信,打好了這個基礎,再去學大數據領域的其他技術也會輕松一些。