













科普 | 你應該知道的Java緩存進化史
背景
本文是上周去技術沙龍聽了一下愛奇藝的 Java 緩存之路有感寫出來的。先簡單介紹一下愛奇藝的 Java 緩存道路的發展吧。
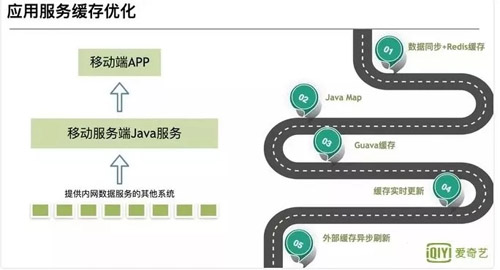
可以看見圖中分為幾個階段:
- 第一階段:數據同步加 Redis
通過消息隊列進行數據同步至 Redis,然后 Java 應用直接去取緩存。這個階段的優點是:由于是使用的分布式緩存,所以數據更新快。缺點也比較明顯:依賴 Redis 的穩定性,一旦 Redis 掛了,整個緩存系統不可用,造成緩存雪崩,所有請求打到 DB。
- 第二,三階段:JavaMap 到 Guava Cache
這個階段使用進程內緩存作為一級緩存,Redis 作為二級。優點:不受外部系統影響,其他系統掛了,依然能使用。缺點:進程內緩存無法像分布式緩存那樣做到實時更新。由于 Java 內存有限,必定緩存得設置大小,然后有些緩存會被淘汰,就會有命中率的問題。
- 第四階段: Guava Cache 刷新
為了解決上面的問題,利用 Guava Cache 可以設置寫后刷新時間,進行刷新。解決了一直不更新的問題,但是依然沒有解決實時刷新。
- 第五階段:外部緩存異步刷新
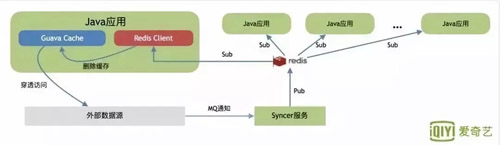
這個階段擴展了 Guava Cache,利用 Redis 作為消息隊列通知機制,通知其他 Java 應用程序進行刷新。
這里簡單介紹一下愛奇藝緩存發展的五個階段,當然還有一些其他的優化,比如 GC 調優,緩存穿透,緩存覆蓋的一些優化等等。
原始社會 - 查庫
上面說的是愛奇藝的一個進化線路,但是在大家的一般開發過程中,第一步一般都沒有 Redis,而是直接查庫。
在流量不大的時候,查數據庫或者讀取文件最為方便,也能完全滿足我們的業務要求。
古代社會 - HashMap
當我們應用有一定流量之后或者查詢數據庫特別頻繁,這個時候就可以祭出我們 Java 中自帶的 HashMap 或者 ConcurrentHashMap。我們可以在代碼中這么寫:
- public class CustomerService {
- private HashMap<String,String> hashMap = new HashMap<>();
- private CustomerMapper customerMapper;
- public String getCustomer(String name){
- String customer = hashMap.get(name);
- if ( customer == null){
- customer = customerMapper.get(name);
- hashMap.put(name,customer);
- }
- return customer;
- }
- }
但是這樣做就有個問題 HashMap 無法進行數據淘汰,內存會無限制的增長,所以 HashMap 很快也被淘汰了。
當然并不是說它完全就沒用,就像我們古代社會也不是所有的東西都是過時的,比如我們中華名族的傳統美德是永不過時的,就像這個 HashMap 一樣的可以在某些場景下作為緩存,當不需要淘汰機制的時候,比如我們利用反射,如果我們每次都通過反射去搜索 Method,field,性能必定低效,這時我們用 HashMap 將其緩存起來,性能能提升很多。
近代社會 - LRUHashMap
在古代社會中難住我們的問題是無法進行數據淘汰,這樣會導致我們內存無限膨脹,顯然我們是不可以接受的。
有人就說我把一些數據給淘汰掉唄,這樣不就對了,但是怎么淘汰呢?隨機淘汰嗎?當然不行,試想一下你剛把 A 裝載進緩存,下一次要訪問的時候就被淘汰了,那又會訪問我們的數據庫了,那我們要緩存干嘛呢?
所以聰明的人們就發明了幾種淘汰算法,下面列舉下常見的三種 FIFO,LRU,LFU(還有一些 ARC,MRU 感興趣的可以自行搜索):
- FIFO:先進先出,在這種淘汰算法中,先進入緩存的會先被淘汰。
這種可謂是最簡單的了,但是會導致我們命中率很低。試想一下我們如果有個訪問頻率很高的數據是所有數據第一個訪問的,而那些不是很高的是后面再訪問的,那這樣就會把我們的首個數據但是他的訪問頻率很高給擠出。
- LRU:最近最少使用算法。
在這種算法中避免了上面的問題,每次訪問數據都會將其放在我們的隊尾,如果需要淘汰數據,就只需要淘汰隊首即可。
但是這個依然有個問題,如果有個數據在 1 個小時的前 59 分鐘訪問了 1 萬次(可見這是個熱點數據),再后 1 分鐘沒有訪問這個數據,但是有其他的數據訪問,就導致了我們這個熱點數據被淘汰。
- LFU:最近最少頻率使用。
在這種算法中又對上面進行了優化,利用額外的空間記錄每個數據的使用頻率,然后選出頻率最低進行淘汰。這樣就避免了 LRU 不能處理時間段的問題。
上面列舉了三種淘汰策略,對于這三種,實現成本是一個比一個高,同樣的命中率也是一個比一個好。
而我們一般來說選擇的方案居中即可,即實現成本不是太高,而命中率也還行的 LRU,如何實現一個 LRUMap 呢?我們可以通過繼承 LinkedHashMap,重寫 removeEldestEntry 方法,即可完成一個簡單的 LRUMap。
- class LRUMap extends LinkedHashMap {
- private final int max;
- private Object lock;
- public LRUMap(int max, Object lock) {
- //無需擴容
- super((int) (max * 1.4f), 0.75f, true);
- this.max = max;
- this.lock = lock;
- }
- /**
- * 重寫LinkedHashMap的removeEldestEntry方法即可
- * 在Put的時候判斷,如果為true,就會刪除最老的
- * @param eldest
- * @return
- */
- @Override
- protected boolean removeEldestEntry(Map.Entry eldest) {
- return size() > max;
- }
- public Object getValue(Object key) {
- synchronized (lock) {
- return get(key);
- }
- }
- public void putValue(Object key, Object value) {
- synchronized (lock) {
- put(key, value);
- }
- }
- public boolean removeValue(Object key) {
- synchronized (lock) {
- return remove(key) != null;
- }
- }
- public boolean removeAll(){
- clear();
- return true;
- }
- }
在 LinkedHashMap 中維護了一個 entry(用來放 key 和 value 的對象)鏈表。在每一次 get 或者 put 的時候都會把插入的新 entry,或查詢到的老 entry 放在我們鏈表末尾。
可以注意到我們在構造方法中,設置的大小特意設置到 max*1.4,在下面的 removeEldestEntry 方法中只需要 size>max 就淘汰,這樣我們這個 map 永遠也走不到擴容的邏輯了,通過重寫 LinkedHashMap,幾個簡單的方法我們實現了我們的 LruMap。
現代社會 - Guava Cache
在近代社會中已經發明出來了 LRUMap,用來進行緩存數據的淘汰,但是有幾個問題:
- 鎖競爭嚴重,可以看見我的代碼中,Lock 是全局鎖,在方法級別上面的,當調用量較大時,性能必然會比較低。
- 不支持過期時間
- 不支持自動刷新
所以谷歌的大佬們對于這些問題,按捺不住了,發明了 Guava Cache,在 Guava Cache 中你可以如下面的代碼一樣,輕松使用:
- public static void main(String[] args) throws ExecutionException {
- LoadingCache<String, String> cache = CacheBuilder.newBuilder()
- .maximumSize(100)
- //寫之后30ms過期
- .expireAfterWrite(30L, TimeUnit.MILLISECONDS)
- //訪問之后30ms過期
- .expireAfterAccess(30L, TimeUnit.MILLISECONDS)
- //20ms之后刷新
- .refreshAfterWrite(20L, TimeUnit.MILLISECONDS)
- //開啟weakKey key 當啟動垃圾回收時,該緩存也被回收
- .weakKeys()
- .build(createCacheLoader());
- System.out.println(cache.get("hello"));
- cache.put("hello1", "我是hello1");
- System.out.println(cache.get("hello1"));
- cache.put("hello1", "我是hello2");
- System.out.println(cache.get("hello1"));
- }
- public static com.google.common.cache.CacheLoader<String, String> createCacheLoader() {
- return new com.google.common.cache.CacheLoader<String, String>() {
- @Override
- public String load(String key) throws Exception {
- return key;
- }
- };
- }
我將會從 Guava Cache 原理中,解釋 Guava Cache 是如何解決 LRUMap 的幾個問題的。
鎖競爭
Guava Cache 采用了類似 ConcurrentHashMap 的思想,分段加鎖,在每個段里面各自負責自己的淘汰的事情。
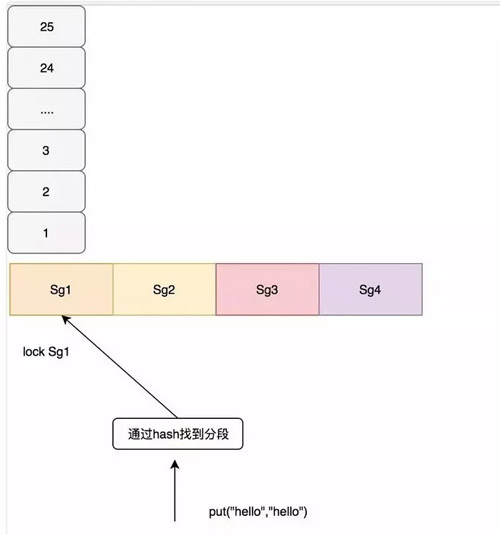
在 Guava 根據一定的算法進行分段,這里要說明的是,如果段太少那競爭依然很嚴重,如果段太多容易出現隨機淘汰,比如大小為 100 的,給他分 100 個段,那也就是讓每個數據都獨占一個段,而每個段會自己處理淘汰的過程,所以會出現隨機淘汰。在 Guava Cache 中通過如下代碼,計算出應該如何分段。
- int segmentShift = 0;
- int segmentCount = 1;
- while (segmentCount < concurrencyLevel && (!evictsBySize() || segmentCount * 20 <= maxWeight)) {
- ++segmentShift;
- segmentCount <<= 1;
- }
上面 segmentCount 就是我們最后的分段數,其保證了每個段至少 10 個 entry。如果沒有設置 concurrencyLevel 這個參數,那么默認就會是 4,最后分段數也最多為 4,例如我們 size 為 100,會分為 4 段,每段最大的 size 是 25。
在 Guava Cache 中對于寫操作直接加鎖,對于讀操作,如果讀取的數據沒有過期,且已經加載就緒,不需要進行加鎖,如果沒有讀到會再次加鎖進行二次讀,如果還沒有需要進行緩存加載,也就是通過我們配置的 CacheLoader,我這里配置的是直接返回 Key,在業務中通常配置從數據庫中查詢。 如下圖所示:
過期時間
相比于 LRUMap 多了兩種過期時間,一個是寫后多久過期 expireAfterWrite,一個是讀后多久過期 expireAfterAccess。
很有意思的事情是,在 Guava Cache 中對于過期的 entry 并沒有馬上過期(也就是并沒有后臺線程一直在掃),而是通過進行讀寫操作的時候進行過期處理,這樣做的好處是避免后臺線程掃描的時候進行全局加鎖。看下面的代碼:
- public static void main(String[] args) throws ExecutionException, InterruptedException {
- Cache<String, String> cache = CacheBuilder.newBuilder()
- .maximumSize(100)
- //寫之后5s過期
- .expireAfterWrite(5, TimeUnit.MILLISECONDS)
- .concurrencyLevel(1)
- .build();
- cache.put("hello1", "我是hello1");
- cache.put("hello2", "我是hello2");
- cache.put("hello3", "我是hello3");
- cache.put("hello4", "我是hello4");
- //至少睡眠5ms
- Thread.sleep(5);
- System.out.println(cache.size());
- cache.put("hello5", "我是hello5");
- System.out.println(cache.size());
- }
- 輸出:
- 4
- 1
從這個結果中我們知道,在 put 的時候才進行的過期處理。特別注意的是我上面 concurrencyLevel(1)這里將分段最大設置為 1,不然不會出現這個實驗效果的,在上面一節中已經說過,我們是以段位單位進行過期處理。在每個 Segment 中維護了兩個隊列:
- final Queue<ReferenceEntry<K, V>> writeQueue;
- final Queue<ReferenceEntry<K, V>> accessQueue;
writeQueue 維護了寫隊列,隊頭代表著寫得早的數據,隊尾代表寫得晚的數據。accessQueue 維護了訪問隊列,和 LRU 一樣,用來進行訪問時間的淘汰。如果當這個 Segment 超過最大容量,比如我們上面所說的 25,超過之后,就會把 accessQueue 這個隊列的第一個元素進行淘汰。
- void expireEntries(long now) {
- drainRecencyQueue();
- ReferenceEntry<K, V> e;
- while ((e = writeQueue.peek()) != null && map.isExpired(e, now)) {
- if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
- throw new AssertionError();
- }
- }
- while ((e = accessQueue.peek()) != null && map.isExpired(e, now)) {
- if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
- throw new AssertionError();
- }
- }
- }
上面就是 Guava Cache 處理過期 entries 的過程,會對兩個隊列一次進行 peek 操作,如果過期就進行刪除。
一般處理過期 entries 可以在我們的 put 操作的前后,或者讀取數據時發現過期了,然后進行整個 segment 的過期處理,又或者進行二次讀 lockedGetOrLoad 操作的時候調用。
- void evictEntries(ReferenceEntry<K, V> newest) {
- ///... 省略無用代碼
- while (totalWeight > maxSegmentWeight) {
- ReferenceEntry<K, V> e = getNextEvictable();
- if (!removeEntry(e, e.getHash(), RemovalCause.SIZE)) {
- throw new AssertionError();
- }
- }
- }
- /**
- **返回accessQueue的entry
- **/
- ReferenceEntry<K, V> getNextEvictable() {
- for (ReferenceEntry<K, V> e : accessQueue) {
- int weight = e.getValueReference().getWeight();
- if (weight > 0) {
- return e;
- }
- }
- throw new AssertionError();
- }
上面是我們驅逐 entry 的時候的代碼,可以看見訪問的是 accessQueue 對其隊頭進行驅逐。而驅逐策略一般是在對 segment 中的元素發生變化時進行調用,比如插入操作,更新操作,加載數據操作。
自動刷新
自動刷新操作,在 Guava Cache 中實現相對比較簡單,直接通過查詢,判斷其是否滿足刷新條件,進行刷新。
其他特性
在 Guava Cache 中還有一些其他特性:
虛引用
在 Guava Cache 中,key 和 value 都能進行虛引用的設定,在 segment 中有兩個引用隊列:
- final @Nullable ReferenceQueue<K> keyReferenceQueue;
- final @Nullable ReferenceQueue<V> valueReferenceQueue;
這兩個隊列用來記錄被回收的引用,其中每個隊列記錄了每個被回收的 entry 的 hash,這樣回收了之后通過這個隊列中的 hash 值就能把以前的 entry 進行刪除。
刪除監聽器
在 Guava Cache 中,當有數據被淘汰時,但是你不知道他到底是過期,還是被驅逐,還是因為虛引用的對象被回收?
這個時候你可以調用這個方法 removalListener(RemovalListener listener)添加監聽器進行數據淘汰的監聽,可以打日志或者一些其他處理,可以用來進行數據淘汰分析。
在 RemovalCause 記錄了所有被淘汰的原因:被用戶刪除,被用戶替代,過期,驅逐收集,由于大小淘汰。
Guava Cache 的總結
細細品讀 Guava Cache 的源碼總結下來,其實就是一個性能不錯的,api 豐富的 LRU Map。愛奇藝的緩存的發展也是基于此之上,通過對 Guava Cache 的二次開發,讓其可以進行 Java 應用服務之間的緩存更新。
走向未來-caffeine
Guava Cache 的功能的確是很強大,滿足了絕大多數人的需求,但是其本質上還是 LRU 的一層封裝,所以在眾多其他較為優良的淘汰算法中就相形見絀了。而 Caffeine Cache 實現了 W-TinyLFU(LFU+LRU 算法的變種)。下面是不同算法的命中率的比較:
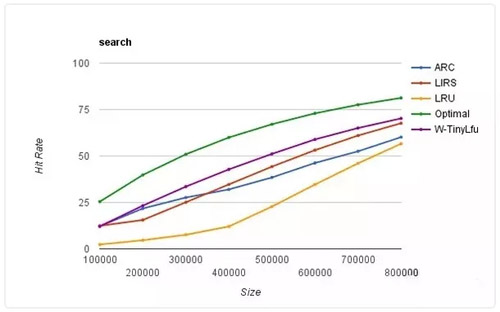
其中 Optimal 是最理想的命中率,LRU 和其他算法相比的確是個弟弟。而我們的 W-TinyLFU 是最接近理想命中率的。當然不僅僅是命中率 Caffeine 優于了 Guava Cache,在讀寫吞吐量上面也是完爆 Guava Cache。
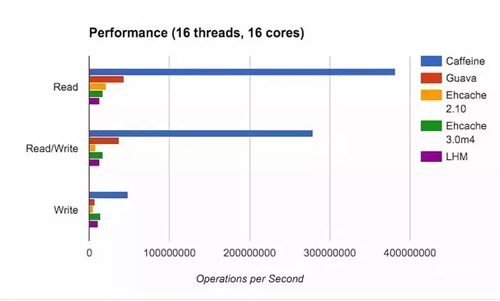
這個時候你肯定會好奇為啥 Caffeine 這么牛逼呢?別著急下面慢慢給你道來。
W-TinyLFU
上面已經說過了傳統的 LFU 是怎么一回事。在 LFU 中只要數據訪問模式的概率分布隨時間保持不變時,其命中率就能變得非常高。
這里我還是拿愛奇藝舉例,比如有部新劇出來了,我們使用 LFU 給他緩存下來,這部新劇在這幾天大概訪問了幾億次,這個訪問頻率也在我們的 LFU 中記錄了幾億次。
但是新劇總會過氣的,比如一個月之后這個新劇的前幾集其實已經過氣了,但是他的訪問量的確是太高了,其他的電視劇根本無法淘汰這個新劇,所以在這種模式下是有局限性。
所以各種 LFU 的變種出現了,基于時間周期進行衰減,或者在最近某個時間段內的頻率。同樣的 LFU 也會使用額外空間記錄每一個數據訪問的頻率,即使數據沒有在緩存中也需要記錄,所以需要維護的額外空間很大。
可以試想我們對這個維護空間建立一個 HashMap,每個數據項都會存在這個 HashMap 中,當數據量特別大的時候,這個 HashMap 也會特別大。
再回到 LRU,我們的 LRU 也不是那么一無是處,LRU 可以很好的應對突發流量的情況,因為他不需要累計數據頻率。
所以 W-TinyLFU 結合了 LRU 和 LFU,以及其他的算法的一些特點。
頻率記錄
首先要說到的就是頻率記錄的問題,我們要實現的目標是利用有限的空間可以記錄隨時間變化的訪問頻率。在 W-TinyLFU 中使用 Count-Min Sketch 記錄我們的訪問頻率,而這個也是布隆過濾器的一種變種。如下圖所示::
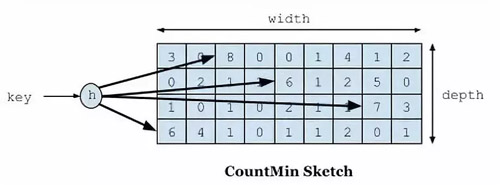
如果需要記錄一個值,那我們需要通過多種 hash 算法對其進行處理hash,然后在對應的 hash 算法的記錄中+1,為什么需要多種 hash 算法呢?
由于這是一個壓縮算法必定會出現沖突,比如我們建立一個 Long 的數組,通過計算出每個數據的 hash 的位置。比如張三和李四,他們倆有可能 hash 值都是相同,比如都是 1 那 Long[1] 這個位置就會增加相應的頻率,張三訪問 1 萬次,李四訪問 1 次那 Long[1] 這個位置就是 1 萬零 1。
如果取李四的訪問評率的時候就會取出是 1 萬零 1,但是李四命名只訪問了 1 次啊,為了解決這個問題,所以用了多個 hash 算法可以理解為 Long[][] 二維數組的一個概念,比如在第一個算法張三和李四沖突了,但是在第二個,第三個中很大的概率不沖突,比如一個算法大概有 1% 的概率沖突,那四個算法一起沖突的概率是 1% 的四次方。
通過這個模式,我們取李四的訪問率的時候取所有算法中,李四訪問最低頻率的次數。所以他的名字叫 Count-Min Sketch。
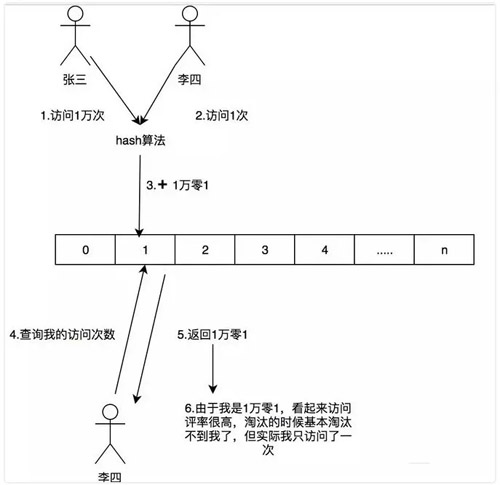
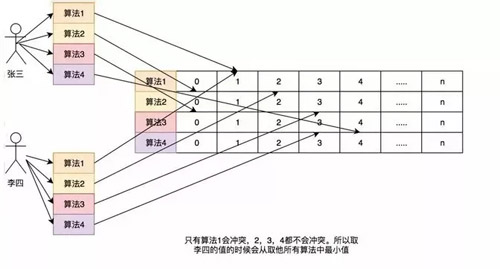
這里和以前的做個對比,簡單的舉個例子:如果一個 HashMap 來記錄這個頻率,如果我有 100 個數據,那這個 HashMap 就得存儲 100 個這個數據的訪問頻率。
哪怕我這個緩存的容量是 1,因為 LFU 的規則我必須全部記錄這 100 個數據的訪問頻率。如果有更多的數據我就有記錄更多的。
在 Count-Min Sketch 中,我這里直接說 Caffeine 中的實現吧(在 FrequencySketch 這個類中),如果你的緩存大小是 100,他會生成一個 Long 數組大小是和 100 最接近的 2 的冪的數,也就是 128。
而這個數組將會記錄我們的訪問頻率。在 Caffeine 中它規則頻率最大為 15,15 的二進制位 1111,總共是 4 位,而 Long 型是 64 位。所以每個 Long 型可以放 16 種算法,但是 Caffeine 并沒有這么做,只用了四種 hash 算法,每個 Long 型被分為四段,每段里面保存的是四個算法的頻率。
這樣做的好處是可以進一步減少 hash 沖突,原先 128 大小的 hash,就變成了 128X4。
一個Long的結構如下:
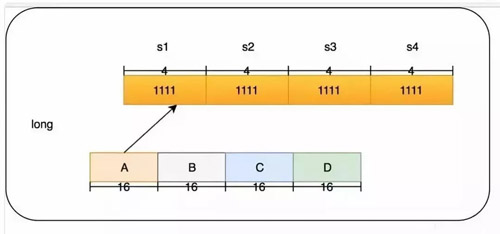
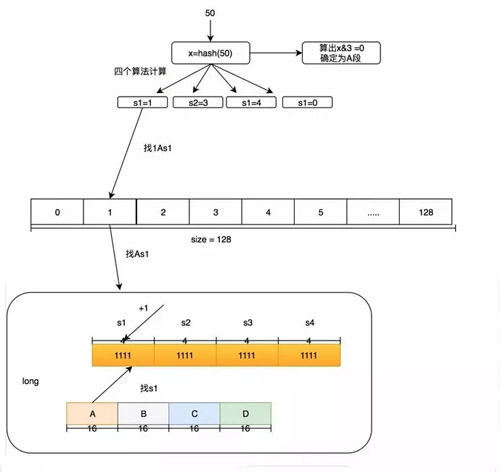
我們的 4 個段分為 A,B,C,D,在后面我也會這么叫它們。而每個段里面的四個算法我叫他 s1,s2,s3,s4。下面舉個例子,如果要添加一個訪問 50 的數字頻率應該怎么做?我們這里用 size=100 來舉例。
- 首先確定 50 這個 hash 是在哪個段里面,通過 hash & 3 必定能獲得小于 4 的數字,假設 hash & 3=0,那就在 A 段。
- 對 50 的 hash 再用其他 hash 算法再做一次 hash,得到 Long 數組的位置。假設用 s1 算法得到 1,s2 算法得到 3,s3 算法得到 4,s4 算法得到 0。
- 然后在 Long[1] 的 A 段里面的 s1 位置進行+1,簡稱 1As1 加 1,然后在 3As2 加 1,在 4As3 加 1,在 0As4 加 1。
這個時候有人會質疑頻率最大為 15 的這個是否太小?沒關系在這個算法中,比如 size 等于 100,如果他全局提升了 1000 次就會全局除以 2 衰減,衰減之后也可以繼續增加,這個算法再 W-TinyLFU 的論文中證明了其可以較好的適應時間段的訪問頻率。
讀寫性能
在 Guava Cache 中我們說過其讀寫操作中夾雜著過期時間的處理,也就是你在一次 put 操作中有可能還會做淘汰操作,所以其讀寫性能會受到一定影響。
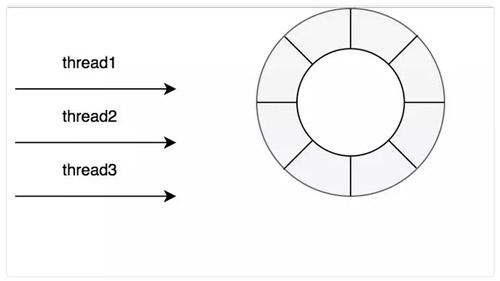
可以看上面的圖中,Caffeine 的確在讀寫操作上面完爆 Guava Cache。主要是因為在 Caffeine,對這些事件的操作是通過異步操作,它將事件提交至隊列,這里的隊列的數據結構是 RingBuffer。
然后會通過默認的 ForkJoinPool.commonPool(),或者自己配置線程池,進行取隊列操作,然后在進行后續的淘汰,過期操作。
當然讀寫也是有不同的隊列,在 Caffeine 中認為緩存讀比寫多很多,所以對于寫操作是所有線程共享一個 Ringbuffer。
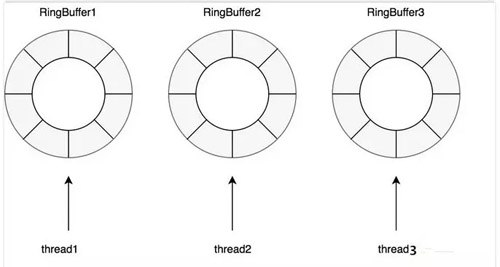
對于讀操作比寫操作更加頻繁,進一步減少競爭,其為每個線程配備了一個 RingBuffer:
數據淘汰策略
在 Caffeine 所有的數據都在 ConcurrentHashMap 中,這個和 Guava Cache 不同,Guava Cache 是自己實現了個類似 ConcurrentHashMap 的結構。在 Caffeine 中有三個記錄引用的 LRU 隊列:
- Eden 隊列:在 Caffeine 中規定只能為緩存容量的 %1,如果 size=100,那這個隊列的有效大小就等于 1。這個隊列中記錄的是新到的數據,防止突發流量由于之前沒有訪問頻率,而導致被淘汰。
比如有一部新劇上線,在最開始其實是沒有訪問頻率的,防止上線之后被其他緩存淘汰出去,而加入這個區域。伊甸區,最舒服最安逸的區域,在這里很難被其他數據淘汰。
- Probation 隊列:叫做緩刑隊列,在這個隊列就代表你的數據相對比較冷,馬上就要被淘汰了。這個有效大小為 size 減去 eden 減去 protected。
- Protected 隊列:在這個隊列中,可以稍微放心一下了,你暫時不會被淘汰,但是別急,如果 Probation 隊列沒有數據了或者 Protected 數據滿了,你也將會面臨淘汰的尷尬局面。
當然想要變成這個隊列,需要把 Probation 訪問一次之后,就會提升為 Protected 隊列。這個有效大小為(size 減去 eden) X 80% 如果 size =100,就會是 79。
這三個隊列關系如下:
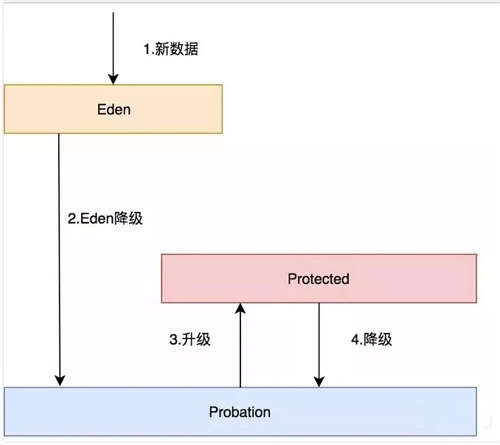
- 所有的新數據都會進入 Eden。
- Eden 滿了,淘汰進入 Probation。
- 如果在 Probation 中訪問了其中某個數據,則這個數據升級為 Protected。
- 如果 Protected 滿了又會繼續降級為 Probation。
對于發生數據淘汰的時候,會從 Probation 中進行淘汰,會把這個隊列中的數據隊頭稱為受害者,這個隊頭肯定是最早進入的,按照 LRU 隊列的算法的話那它就應該被淘汰,但是在這里只能叫它受害者,這個隊列是緩刑隊列,代表馬上要給它行刑了。
這里會取出隊尾叫候選者,也叫攻擊者。這里受害者會和攻擊者做 PK,通過我們的 Count-Min Sketch 中的記錄的頻率數據有以下幾個判斷:
- 如果攻擊者大于受害者,那么受害者就直接被淘汰。
- 如果攻擊者<=5,那么直接淘汰攻擊者。這個邏輯在他的注釋中有解釋: 他認為設置一個預熱的門檻會讓整體命中率更高。
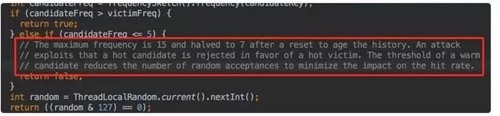
- 其他情況,隨機淘汰。
如何使用
對于熟悉 Guava 的玩家來說,如果擔心有切換成本,那么你就多慮了, Caffeine 的 api 借鑒了 Guava 的 api,可以發現其基本一模一樣。
- public static void main(String[] args) {
- Cache<String, String> cache = Caffeine.newBuilder()
- .expireAfterWrite(1, TimeUnit.SECONDS)
- .expireAfterAccess(1,TimeUnit.SECONDS)
- .maximumSize(10)
- .build();
- cache.put("hello","hello");
- }
順便一提的是,越來越多的開源框架都放棄了 Guava Cache,比如 Spring5。在業務上我也曾經比較過 Guava Cache 和 Caffeine,最終選擇了 Caffeine,在線上也有不錯的效果。所以不用擔心 Caffeine 不成熟,沒人使用。
最后
本文主要講述愛奇藝的緩存之路和本地緩存的一個發展歷史(從古至今到未來),以及每一種緩存的實現基本原理。
當然要使用好緩存光是這些遠遠不夠,比如本地緩存如何在其他地方更改了之后同步更新,分布式緩存,多級緩存等等。后面也會專門寫一節介紹這個如何用好緩存。
對于 Guava Cache 和 Caffeine 的原理后面也會專門抽出時間寫這兩個的源碼分析,如果感興趣的朋友可以關注公眾號第一時間查閱更新文章。


















