從DevOps到AIOps,阿里如何實現智能化運維?
背景
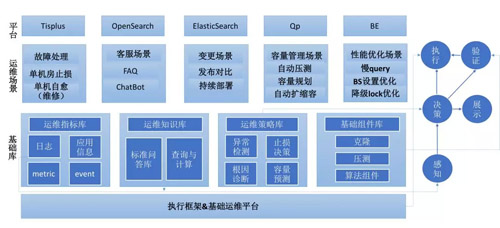
隨著搜索業務的快速發展,搜索系統都在走向平臺化,運維方式在經歷人肉運維,腳本自動化運維后最終演變成DevOps。但隨著大數據及人工智能的快速發展,傳統的運維方式及解決方案已不能滿足需求。
基于如何提升平臺效率和穩定性及降低資源,我們實現了在線服務優化大師hawkeye及容量規劃平臺torch。經過幾年的沉淀后,我們在配置合理性、資源合理性設置、性能瓶頸、部署合理性等4個方面做了比較好的實踐。下面具體介紹下hawkeye和torch系統架構及實現。
AIOps實踐及實現
hawkeye——智能診斷及優化
系統簡介

hawkeye是一個智能診斷及優化系統,平臺大體分為三部分:
1.分析層,包括兩部分:
1) 底層分析工程hawkeye-blink:基于Blink完成數據處理的工作,重點是訪問日志分析、全量數據分析等,該工程側重底層的數據分析,借助Blink強大的數據處理能力,每天對于搜索平臺所有Ha3應用的訪問日志以及全量數據進行分析。
2) 一鍵診斷工程hawkeye-experience:基于hawkeye-blink的分析結果進行更加貼近用戶的分析,比如字段信息監測,包括字段類型合理性,字段值單調性監測等,除此之外還包括但不限于kmon無效報警、冒煙case錄入情況、引擎降級配置、內存相關配置、推薦行列數配置以及切換時最小服務行比例等檢測。
hawkeye-experience工程的定位是做一個引擎診斷規則中臺,將平時運維人員優化維護引擎的寶貴經驗沉淀到系統中來,讓每一個新接入的應用可以快速享受這樣的寶貴經驗,而不是通過一次次的踩坑之后獲得,讓每位用戶擁有一個類似智能診斷專家的角色來優化自己的引擎是我們的目標,也是我們持續奮斗的動力,其中hawkeye-experience的數據處理流程圖如下所示:
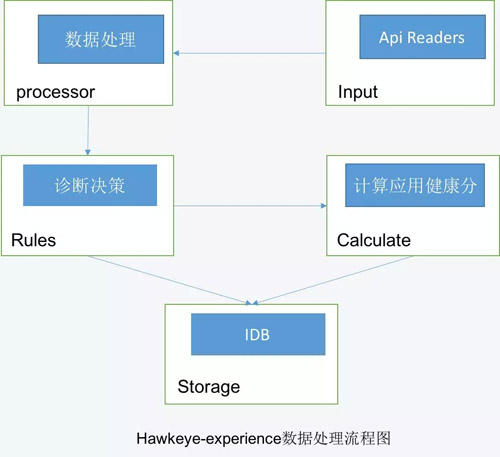
2.web層:提供hawkeye分析結果的各種api以及可視化的監控圖表輸出。
3.service層:提供hawkeye分析與優化api的輸出。
基于上述架構我們落地的診斷及優化功能有:
- 資源優化:引擎Lock內存優化(無效字段分析)、實時內存優化等;
- 性能優化:TopN慢query優化、buildservice資源設置優化等;
- 智能診斷:日常化巡檢、智能問答等。
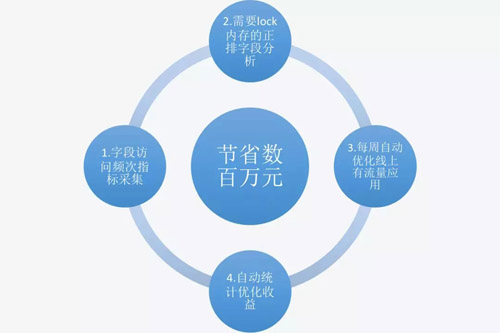
引擎Lock內存優化
對于Ha3引擎,引擎字段是分為倒排(index)索引、正排(attribute)索引和摘要(summary)索引的。引擎的Lock策略可以針對這三類索引進行Lock或者不Lock內存的設置,Lock內存好處不言而喻,加速訪問,降低rt,但是試想100個字段中,如果兩個月只有50個訪問到了,其他字段在索引中壓根沒訪問,這樣會帶來寶貴內存的較大浪費,為此hawkeye進行了如下分析與優化,針對頭部應用進行了針對性的索引瘦身。下圖為Lock內存優化的過程,累計節省約數百萬元。
慢query分析
慢query數據來自應用的訪問日志,query數量和應用的訪問量有關,通常在千萬甚至億級別。從海量日志中獲取TopN慢query屬于大數據分析范疇。我們借助Blink的大數據分析能力,采用分治+hash+小頂堆的方式進行獲取,即先將query格式進行解析,獲取其查詢時間,將解析后的k-v數據取md5值,然后根據md5值做分片,在每一個分片中計算TopN慢query,***在所有的TopN中求出最終的TopN。對于分析出的TopN慢query提供個性化的優化建議給用戶,從而幫助用戶提升引擎查詢性能,間接提高引擎容量。
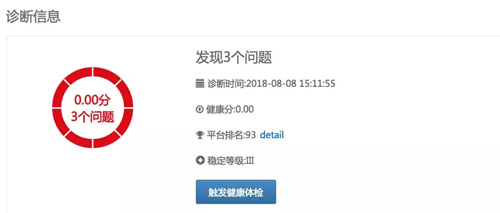
一鍵診斷
我們通過健康分衡量引擎健康狀態,用戶通過健康分可以明確知道自己的服務健康情況,診斷報告給出診斷時間,配置不合理的簡要描述以及詳情,優化的收益,診斷邏輯及一鍵診斷之后有問題的結果頁面如下圖所示,其中診斷詳情頁面因篇幅問題暫未列出。

智能問答
隨著應用的增多,平臺遇到的答疑問題也在不斷攀升,但在答疑的過程中不難發現很多重復性的問題,類似增量停止、常見資源報警的咨詢,對于這些有固定處理方式的問題實際上是可以提供chatOps的能力,借助答疑機器人處理。目前hawkeye結合kmon的指標和可定制的告警消息模板,通過在報警正文中添加診斷的方式進行這類問題的智能問答,用戶在答疑群粘貼診斷正文,at機器人即可獲取此次報警的原因。
torch-容量治理優化
hawkeye主要從智能診斷和優化的視角來提升效率增強穩定性,torch專注從容量治理的視角來降低成本,隨著搜索平臺應用的增多面臨諸如以下問題,極易造成資源使用率低下,機器資源的嚴重浪費。
1)業務方申請容器資源隨意,造成資源成本浪費嚴重,需要基于容器成本耗費最小化明確指導業務方應該合理申請多少資源(包括cpu,內存及磁盤)或者資源管理對用戶屏蔽。
2)業務變更不斷,線上真實容量(到底能扛多少qps)大家都不得而知,當業務需要增大流量(譬如各種大促)時是否需要擴容?如果擴容是擴行還是增大單個容器cpu規格?當業務需要增大數據量時是拆列合適還是擴大單個容器的內存大小合適? 如此多的問號隨便一個都會讓業務方蒙圈。
解決方案
如下圖所示,做容量評估擁有的現有資源,是kmon數據,線上系統的狀態匯報到kmon,那直接拿kmon數據來分析進行容量評估可不可以呢?
實際實驗發現是不夠的,因為線上有很多應用水位都比較低,擬合出來高水位情況下的容量也是不夠客觀的,所以需要個壓測服務來真實摸底性能容量,有了壓測接下來需要解決的問題是壓哪?壓線上風險比較大,壓預發預發的資源有限機器配置差沒法真實摸底線上,所以需要克隆仿真,真實克隆線上的一個單例然后進行壓測,這樣既能精準又安全。有了壓測數據,接下來就是要通過算法分析找到***成本下的資源配置,有了上面的幾個核心支撐,通過任務管理模塊將每個任務管理起來進行自動化的容量評估。

以上是我們的解決方案,接下來會優先介紹下整體架構,然后再介紹各核心模塊的具體實現。
系統架構
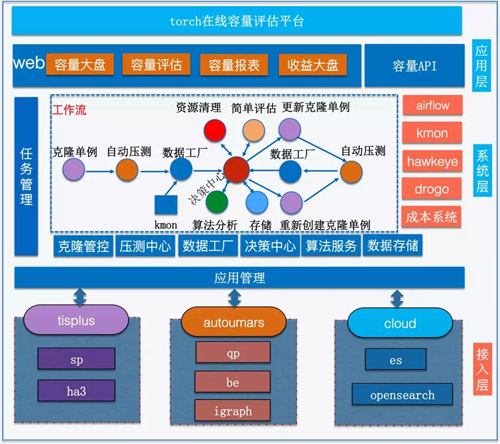
如圖,從下往上看,首先是接入層。平臺要接入只需要提供平臺下各應用的應用信息及機群信息(目前接入的有tisplus下的ha3和sp),應用管理模塊會對應用信息進行整合,接下來任務管理模塊會對每個應用抽象成一個個的容量評估任務。
一次完整的容量評估任務的大概流程是:首先克隆一個單例,然后對克隆單例進行自動化壓測壓到極限容量,壓測數據和日常數據經過數據工廠加工將格式化后的數據交由決策中心,決策中心會先用壓測數據和日常數據通過算法服務進行容量評估,然后判斷收益,如果收益高會結合算法容量優化建議進行克隆壓測驗證,驗證通過將結果持久化保存,驗證失敗會進行簡單的容量評估(結合壓測出的極限性能簡單評估容量),容量評估完成以及失敗決策中心都會將克隆及壓測申請的臨時資源清理不至于造成資源浪費。
最上面是應用層,考慮到torch容量治理不僅僅是為tisplus定制的,應用層提供容量大盤,容量評估,容量報表及收益大盤,以便其它平臺接入嵌用,另外還提供容量API供其它系統調用。
容量評估也依賴了搜索很多其它系統,maat, kmon, hawkeye,drogo,成本系統等整個形成了一道閉環。
架構實現
克隆仿真
克隆仿真簡單地理解就是克隆線上應用的一個單例,ha3應用就是克隆完整一行,sp就是克隆出一個獨立服務。隨著搜索hippo這大利器的誕生,資源都以容器的方式使用,再加上suez ops及sophon這些DevOps的發展,使得快速克隆一個應用成為可能,下面給出克隆管控模塊的具體實現:
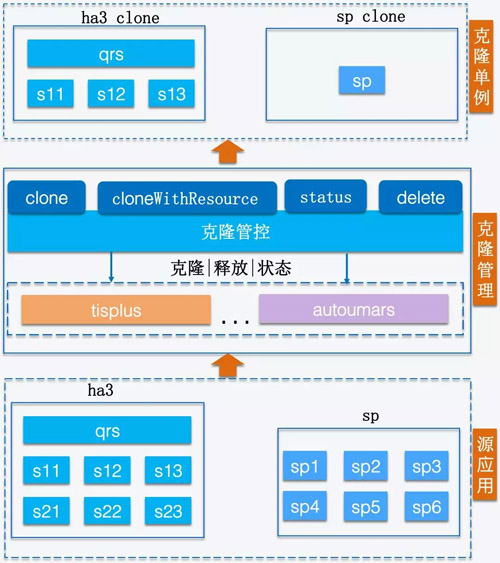
克隆目前分為淺克隆和深度克隆,淺克隆主要針對ha3應用通過影子表的方式直接拉取主應用的索引,省掉build環節加快克隆速度,深度克隆就是克隆出來的應用需要進行離線build。
克隆的優勢明顯:
服務隔離,通過壓測克隆環境可以間接摸底線上的真實容量。
資源優化建議可以直接在克隆環境上進行壓測驗證。
克隆環境使用完,直接自動釋放,不會對線上資源造成浪費。
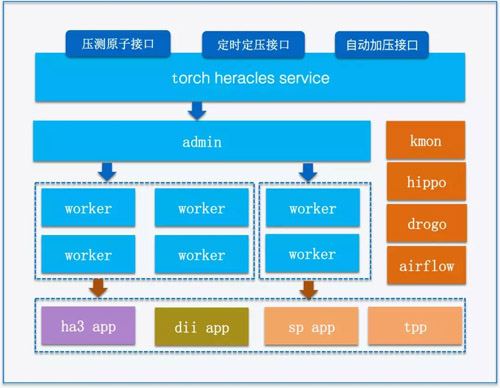
壓測服務
考慮到日常的kmon數據大部分應用缺少高水位的metrics指標,并且引擎的真實容量也只有通過實際壓測才能獲得,因此需要壓測服務,前期調研了公司的亞馬遜壓測平臺及阿里媽媽壓測平臺,發現不能滿足自動壓測的需求,于是基于hippo我們開發了自適應增加施壓woker的分布式壓測服務。
算法服務
容量評估的目標就最小化資源成本提高資源利用率,所以有個先決條件,資源得可被成本量化,成本也是搜索走向平臺化衡量平臺價值的一個重要維度,于是我們搜索這邊跟財務制定了價格公式,也就擁有了這個先決條件,和算法同學經過大量的實驗分析發現這個問題可以轉換成帶約束條件的規劃問題,優化的目標函數就是價格公式(里面有內存 cpu磁盤幾個變量)約束條件就是提供的容器規格和容器數一定要滿足***的qps 內存和磁盤的需要。
AIOps展望
通過hawkeye診斷優化和torch容量治理在tisplus搜索平臺上的落地大大降低了成本提高了效率和穩定性,為將AIOps應用到其它在線系統樹立了信心,因此下一步目標就是將hawkeye和torch整合進行AIOps平臺化建設,讓其它在線服務也都能享受到AIOps帶來的福利。因此,開放性,易用性是平臺設計首要考慮的兩個問題。
為此,接下來會重點進行四大基礎庫的建設:
運維指標庫:將在線系統的日志,監控指標,event和應用信息進行規范整合,讓策略實現過程中方便獲取各種運維指標。
運維知識庫:通過ES沉淀日常答疑積累的問題集及經驗,提供檢索及計算功能,便于對線上類似問題進行自動診斷及自愈。
運維組件庫:將克隆仿真 壓測 及算法模型組件化,便于用戶靈活選擇算法進行策略實現,并輕松使用克隆仿真及壓測對優化建議進行有效驗證。
運維策略庫:通過畫布讓用戶拖拽及寫UDP來快速實現自己系統的運維策略,運維指標庫,運維知識庫及運維組 件庫提供了豐富多樣的數據及組件,使得運維策略的實現變得足夠簡單。
基于上述基礎設施的建設結合策略便可產出各種運維場景下的數據,全面進行故障處理,智能問答,容量管理及性能優化各種場景的應用。