DBA的MySQL性能優(yōu)化及自動(dòng)化運(yùn)維實(shí)踐
本文作者將站在更加全面的角度分享他在這一年多 DBA 工作中的經(jīng)驗(yàn),希望可以給大家?guī)?lái)啟發(fā)和幫助。

DBA 的日常工作
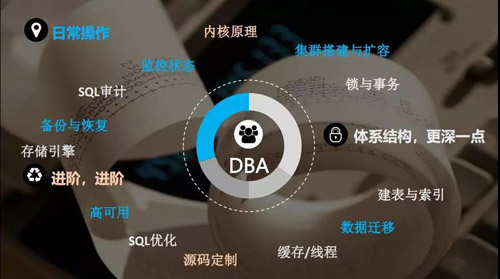
我覺(jué)得 DBA 真的很忙,我們來(lái)看看 DBA 的具體工作:備份和恢復(fù)、監(jiān)控狀態(tài)、集群搭建與擴(kuò)容、數(shù)據(jù)遷移和高可用。
上面這些是我們 DBA 的功能,了解這些功能以后要對(duì)體系結(jié)構(gòu)有更加深入的了解,你不知道怎么處理這些故障和投訴的事情。
所以我們要去了解緩存/線(xiàn)程、SQL 優(yōu)化、存儲(chǔ)引擎、SQL 審計(jì)以及鎖與實(shí)務(wù);體系結(jié)構(gòu)更深一點(diǎn),就去研究?jī)?nèi)核原理和源碼定制。
DBA 有這么多工作,它們就像一個(gè)小怪獸一樣等著我們?nèi)ソ鉀Q。
MySQL 的性能優(yōu)化

性能優(yōu)化讓我們的 MySQL 跑的更快、更順暢。在我們開(kāi)始 MySQL 性能優(yōu)化之前,我想提出 MySQL 性能優(yōu)化的三個(gè)關(guān)鍵點(diǎn):Why?What?How?
為什么我們要做性能優(yōu)化?我們的運(yùn)維來(lái)反映我們的數(shù)據(jù)庫(kù),正常情況下是 1 秒,后來(lái)變成 10 秒,我們就要啟動(dòng)優(yōu)化的動(dòng)作。原本他的訪(fǎng)問(wèn)時(shí)間是 1 秒,我們想優(yōu)化成 0.01 秒就要開(kāi)啟優(yōu)化。
第二就是 What?哪里是導(dǎo)致我們數(shù)據(jù)庫(kù)性能變差的原因,需要找到這個(gè)關(guān)鍵點(diǎn)。
當(dāng)我們找到這個(gè)問(wèn)題以后,我們就需要有的放矢地進(jìn)行優(yōu)化。MySQL 優(yōu)化之前我們要明確 3W 關(guān)鍵點(diǎn)。
MySQL 優(yōu)化基本流程
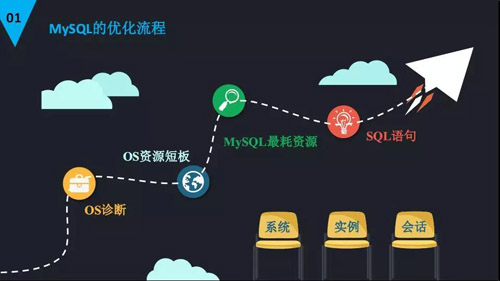
對(duì)于開(kāi)展 MySQL 優(yōu)化一個(gè)基本的流程如下:我們首先要登陸到操作系統(tǒng),通過(guò)操作系統(tǒng)的命令進(jìn)行優(yōu)化。
比如說(shuō)通過(guò)操作系統(tǒng)的基本命令,去看我們操作系統(tǒng)有什么資源的占用率比較高。
就是哪里出現(xiàn)了資源短板,短板的意思就是這個(gè)資源的占用率或者是使用率特別高,我們要密切關(guān)注。
比如說(shuō)像 CPU 的負(fù)載特別高,已經(jīng)超過(guò)了我們的核數(shù),或者是使用率特別高,已經(jīng)達(dá)到了 80% 以上,這就引起我們的關(guān)注了。
確定這個(gè)短板之后,我們就要確認(rèn)哪個(gè)進(jìn)程使用我們這個(gè)資源,使得它的使用率或者是占用率特別高。
一般情況下跟我們相關(guān)的就是 MySQL 這一層,比方說(shuō)使用 CPU 的 70% 以上,我們就要去檢查一下這個(gè) MySQL 出現(xiàn)了什么問(wèn)題。
再進(jìn)一步往里推進(jìn),如果我們發(fā)現(xiàn) MySQL 里面是執(zhí)行某一條大 MySQL 的時(shí)候,發(fā)現(xiàn)整個(gè)服務(wù)器或者是整個(gè)數(shù)據(jù)庫(kù)就在那里,可能就是語(yǔ)句問(wèn)題。
我們就要進(jìn)一步通過(guò) MySQL 的監(jiān)控或者是日志信息去排查 MySQL 的問(wèn)題,很重要的是發(fā)現(xiàn)哪個(gè)資源出現(xiàn)問(wèn)題進(jìn)行排查。
我們登陸系統(tǒng)發(fā)現(xiàn) CPU、IO、網(wǎng)絡(luò)等等都很正常,這種情況下怎么辦?
這種情況下我們可以分三種情況判斷:
- 操作系統(tǒng)的問(wèn)題,可能我們登陸 MySQL 的時(shí)候整個(gè)系統(tǒng)就在那里了,我們需要通過(guò)操作系統(tǒng)去查是哪個(gè)資源的問(wèn)題。
- 數(shù)據(jù)庫(kù)實(shí)例問(wèn)題,數(shù)據(jù)庫(kù)實(shí)例問(wèn)題跟數(shù)據(jù)庫(kù)配置參數(shù)相關(guān),也就是說(shuō)我們配置參數(shù)可能存在一些不合理的設(shè)置需要我們?nèi)?yōu)化。
- 會(huì)話(huà)問(wèn)題,我們登陸到 MySQL 里面,一開(kāi)始很正常,后來(lái)我們發(fā)現(xiàn)這個(gè)實(shí)例慢下來(lái)了,可能就是 MySQL 語(yǔ)句有問(wèn)題,我們需要看 MySQL 的執(zhí)行計(jì)劃到具體哪一步比較慢,拖慢了整個(gè)流程。
我們發(fā)現(xiàn)數(shù)據(jù)庫(kù)性能出現(xiàn)問(wèn)題,都可以沿著這個(gè)流程走下去,從而定位出問(wèn)題。
MySQL 優(yōu)化的幾個(gè)關(guān)鍵點(diǎn)
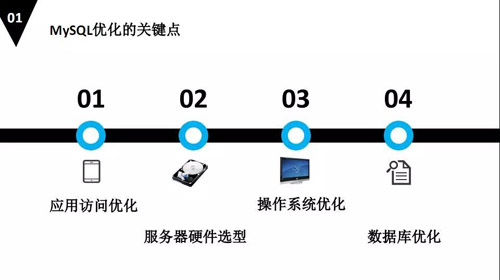
我們通過(guò)剛才的基本流程,可以確定出 MySQL 需要優(yōu)化的幾個(gè)關(guān)鍵點(diǎn)如下:
- 應(yīng)用訪(fǎng)問(wèn)的優(yōu)化,因?yàn)橛袘?yīng)用需要訪(fǎng)問(wèn)我們的數(shù)據(jù)庫(kù),有請(qǐng)求的發(fā)送、數(shù)據(jù)的存儲(chǔ)和網(wǎng)絡(luò)的交互等等,會(huì)導(dǎo)致數(shù)據(jù)庫(kù)性能發(fā)生比較慢的地方。
- 服務(wù)器硬件選型,不知道大家 DBA 對(duì)服務(wù)器有沒(méi)有自主權(quán),如果有自主權(quán)的情況下,我覺(jué)得我們應(yīng)該按照 MySQL 的特性來(lái)選擇服務(wù)器的硬件。
比方說(shuō)我們可能要考慮到數(shù)據(jù)和日志的存儲(chǔ)機(jī)理不同,要選擇不同的類(lèi)型去優(yōu)化它。
- 操作系統(tǒng)的優(yōu)化,就是我們部署配置數(shù)據(jù)庫(kù)之前,要對(duì)操作系統(tǒng)有什么優(yōu)化?能夠讓我們的數(shù)據(jù)庫(kù)有優(yōu)化。
- 數(shù)據(jù)庫(kù)優(yōu)化,數(shù)據(jù)庫(kù)優(yōu)化過(guò)程是一個(gè)全局角度優(yōu)化的過(guò)程,不僅僅是是針對(duì)數(shù)據(jù)庫(kù)本身優(yōu)化的流程。
應(yīng)用訪(fǎng)問(wèn)優(yōu)化
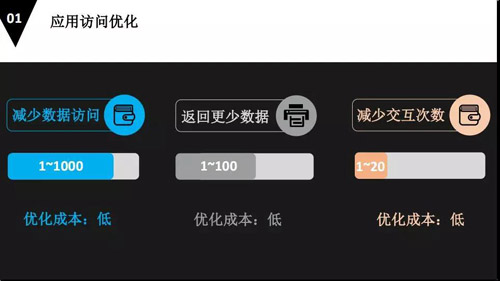
我們根據(jù)每個(gè)關(guān)鍵點(diǎn)稍微開(kāi)展一下,比方說(shuō)應(yīng)用訪(fǎng)問(wèn)的優(yōu)化。
首先***步就是減少數(shù)據(jù)的訪(fǎng)問(wèn)。因?yàn)闇p少數(shù)據(jù)的訪(fǎng)問(wèn)其實(shí)就是減少磁盤(pán)的訪(fǎng)問(wèn)。
我們知道數(shù)據(jù)訪(fǎng)問(wèn)磁盤(pán)獲得數(shù)據(jù)的速度很慢,如果我們是器械磁盤(pán),因?yàn)槠餍荡疟P(pán)是通過(guò)器械旋轉(zhuǎn)來(lái)獲得數(shù)據(jù)。
我們應(yīng)該把活躍數(shù)據(jù)和內(nèi)存數(shù)據(jù)放在內(nèi)存里面,這樣可以使我們的數(shù)據(jù)庫(kù)性能提升 1-1000 倍,它的優(yōu)化成本很低。
第二步是減少返回更多的數(shù)據(jù),減少返回更多的數(shù)據(jù)終結(jié)就是減少了網(wǎng)絡(luò)的傳輸,有很多大的系統(tǒng),網(wǎng)絡(luò)傳輸是一個(gè)很重要的瓶頸。
假設(shè)我們的數(shù)據(jù)庫(kù)服務(wù)器跟我們應(yīng)用服務(wù)器的距離是 20 公里的話(huà),因?yàn)楣饩€(xiàn)數(shù)據(jù)庫(kù)是 20 公里,一個(gè)光的請(qǐng)求是 0.2 毫秒。如果我們減少更少的數(shù)據(jù)請(qǐng)求的話(huà),那這個(gè)時(shí)間就會(huì)變短很多。
所以說(shuō)如果我們發(fā)現(xiàn)數(shù)據(jù)庫(kù)的性能有問(wèn)題,我們可以去看是否網(wǎng)絡(luò)上存在問(wèn)題或者是通過(guò) P 命令看時(shí)間是否會(huì)變得長(zhǎng)。
第三是減少交互次數(shù),每個(gè)交互假設(shè)還是按照 20 公里來(lái)說(shuō),一個(gè)交互的時(shí)間就是 0.2 毫秒,2 個(gè)交互就是 0.4 毫秒。如果有 1 萬(wàn)個(gè)操作的話(huà),就是 1 萬(wàn)乘 0.4 毫秒,那就變得整個(gè)交互時(shí)間變短了很多。
但是也有它的復(fù)雜性或者是不宜擴(kuò)展的局面。從應(yīng)用層就降低了優(yōu)化。這個(gè)成本也是很低的。

我們公司的 DBA 對(duì)于服務(wù)器的應(yīng)用選型沒(méi)有太多的話(huà)語(yǔ)權(quán),移動(dòng)公司都是集團(tuán)公司通過(guò)集采來(lái)選擇的。
在采集的時(shí)候我們不可能規(guī)定這幾臺(tái)服務(wù)器是用在哪個(gè)數(shù)據(jù)庫(kù),這幾個(gè)數(shù)據(jù)庫(kù)用在什么服務(wù)系統(tǒng)。所以我們?cè)诜?wù)器選型時(shí)候 DBA 是沒(méi)有辦法參與進(jìn)去的。
這是我們移動(dòng)云的一些服務(wù)器的選型:采用的服務(wù)器是惠普的 DL360G9,CPU是 2 核×e5-2650V4,內(nèi)存是 8×32G,硬盤(pán)是 6×1.2TSAS,網(wǎng)卡是 4×10GE+4×1GE+1IPMI。
這里特別說(shuō)一下,如果我們 DBA 對(duì)于服務(wù)器有自主權(quán)的話(huà),我們可以把數(shù)據(jù)放到 SSD 盤(pán),把日志放到 SAS 上,這就是服務(wù)器硬件選型需要主要的地方。
操作系統(tǒng)層面的優(yōu)化
我們推薦使用 Linux 操作系統(tǒng),一些開(kāi)源主流的是我們做的。像一些商業(yè)版 Linux 這些就是我們?cè)谟玫摹?/p>
如果要使用這個(gè) SWAP 值,我們盡量不去使用虛擬內(nèi)存,而使用物理內(nèi)存。因?yàn)槲锢韮?nèi)存的訪(fǎng)問(wèn)速度肯定比去訪(fǎng)問(wèn)磁盤(pán)要快得多。
所以我們把這個(gè)值設(shè)成了 10。有的同學(xué)可能就會(huì)說(shuō)為什么不把這個(gè)值設(shè)成 0,就直接全部訪(fǎng)問(wèn)物理內(nèi)存就好了。
如果把它設(shè)為 0 的話(huà),可能就會(huì)出現(xiàn)內(nèi)存溢出的現(xiàn)象,就是 OOM。這不是我們 DBA 想看到的情況,所以我們一般把這個(gè)值設(shè)成 10。
關(guān)閉 NUMA 特性:我們公司一般是單實(shí)例的情況,所以這個(gè)時(shí)候 NUMA 的特性要關(guān)注。
NUMA 特性就是假設(shè)我們一個(gè)服務(wù)器上有兩個(gè) CPU,分布在服務(wù)器左右兩邊,同時(shí)有四塊內(nèi)存,把同一側(cè) CPU 作為一個(gè) NUMA 節(jié)點(diǎn),就是在物理位置分布同一側(cè) CPU 訪(fǎng)問(wèn)同一側(cè)內(nèi)存,距離比較近,速度更快。
我們盡量同一側(cè) CPU 訪(fǎng)問(wèn)同一側(cè)內(nèi)存,這跟我們數(shù)據(jù)庫(kù)的特性是相違背的。因?yàn)槲覀償?shù)據(jù)庫(kù)希望它一般部署了數(shù)據(jù)庫(kù)的服務(wù)器就不會(huì)布其他的應(yīng)用系統(tǒng)資源了。
所以我們希望數(shù)據(jù)庫(kù)是獨(dú)占數(shù)據(jù)庫(kù)資源,在這種情況下我們要盡量關(guān)閉這個(gè) NUMA 特性。
網(wǎng)卡優(yōu)化:我們采用多個(gè)物理網(wǎng)卡通過(guò)做 Bond 綁定成虛擬網(wǎng)卡,就是一些雙網(wǎng)卡做成 Bond 或者調(diào)整網(wǎng)絡(luò)參數(shù)。
磁盤(pán)調(diào)度設(shè)置:一般會(huì)有幾個(gè)算法,如 NOOP 算法、CFQ 或者是 Deadline 算法。
比如說(shuō)這 NOOP 算法用在我們數(shù)據(jù)庫(kù)上有什么問(wèn)題?就會(huì)有餓死讀操作的方式存在,如果兩個(gè)寫(xiě)操作,***個(gè)寫(xiě)操作進(jìn)來(lái)不需要等這個(gè)結(jié)束以后第二個(gè)寫(xiě)操作就可以開(kāi)展了。
如果是讀操作的話(huà),第二個(gè)讀操作就一定要在在前一個(gè)完成。如果有幾毫秒的時(shí)間里面,進(jìn)來(lái)一堆寫(xiě)操作,后面的讀操作就會(huì)餓死的,這個(gè)不符合我們數(shù)據(jù)庫(kù)算法調(diào)動(dòng)的方式。
另外就是 CFQ 算法,CFQ 算法不適合我們的數(shù)據(jù)庫(kù)服務(wù)器,MySQL 是單操作服務(wù)器。所以我們這個(gè)算法也不適合我們使用。
一般情況下數(shù)據(jù)服務(wù)器會(huì)使用 Deadline 的算法,程序會(huì)調(diào)用這個(gè)時(shí)候的 IO 請(qǐng)求去解決這個(gè)請(qǐng)求。
這種 Deadline 算法更加適合數(shù)據(jù)庫(kù),因?yàn)檫@個(gè) Deadline 的算法更加適合。
***一個(gè)是文件系統(tǒng)的推薦,我們移動(dòng)云的數(shù)據(jù)庫(kù)系統(tǒng)就是 Xfs 或者是 Ext4 或者是 Noatime 或者是 nobarrier,這些都會(huì)有影響。這是數(shù)據(jù)庫(kù)系統(tǒng)的優(yōu)化。
數(shù)據(jù)庫(kù)實(shí)例的優(yōu)化

我列了幾個(gè)我們?cè)跇?biāo)準(zhǔn)化的時(shí)候需要規(guī)范和配置的參數(shù),這里不一一揭示了。
這些參數(shù)很重要,因?yàn)樗鼪Q定了我們實(shí)例的性能。某一些參數(shù)配置不合理,我們實(shí)例的性能就會(huì)受到很大的影響。
SQL 語(yǔ)句的優(yōu)化

這里有編寫(xiě)高效 SQL 語(yǔ)句的原則,這個(gè)原則我們 DBA 要知道,同時(shí)要通知業(yè)務(wù)方的研發(fā),讓他們也知道。
有很多業(yè)務(wù)側(cè)進(jìn)來(lái)都是業(yè)務(wù)寫(xiě)的,他沒(méi)有經(jīng)驗(yàn)的話(huà),就會(huì)寫(xiě)出一些有問(wèn)題的語(yǔ)句,所以***就變成我們 DBA 要去嚴(yán)查。
所以最開(kāi)始要把這些思想貫徹給業(yè)務(wù)研發(fā),讓他們按照這個(gè)流程去編寫(xiě) SQL 的設(shè)計(jì)。
索引的設(shè)計(jì)

這里說(shuō)的是覆蓋索引,比如說(shuō)有了這個(gè)覆蓋索引我們的查詢(xún),查詢(xún)的字段都是在這個(gè)索引內(nèi)。
還有我們查詢(xún)的后面的字段也是索引,然后還有我們一些排序位置也是覆蓋索引,就是這一系列全部都是中了索引的情況所以就叫覆蓋索引。
這里我也列舉了一些不能使用索引的情況:比如說(shuō)不要給選擇率低的字段選擇索引,如果通過(guò)索引掃描記錄數(shù)超過(guò) 30% 就變成全表掃描了。
還有 Like 額查詢(xún)條件列最左以通配符 % 開(kāi)始,兩個(gè)獨(dú)立索引,其中一個(gè)用于索引一個(gè)用于排序。以上就是對(duì)于 MySQL 性能優(yōu)化的步驟。
自動(dòng)化運(yùn)維實(shí)踐
所謂自動(dòng)化運(yùn)維實(shí)踐就相當(dāng)于是給我們 DBA 提供小工具或者是小幫手,幫助我們打開(kāi),而不是糾纏著我們。
我們移動(dòng)云的體量就是幾百上千臺(tái)數(shù)據(jù)庫(kù)的體量,如果我們面對(duì)幾臺(tái)或者是十幾臺(tái)的數(shù)據(jù)庫(kù)的時(shí)候,有沒(méi)有這個(gè)自動(dòng)化其實(shí)無(wú)所謂,因?yàn)槟阕鲎詣?dòng)化反而更加麻煩。
如果你已經(jīng)有大的量的時(shí)候就要平臺(tái)化,在自動(dòng)化的數(shù)據(jù)庫(kù)上進(jìn)行拓展。以下是我們?cè)谧詣?dòng)化運(yùn)維的實(shí)踐經(jīng)驗(yàn)。
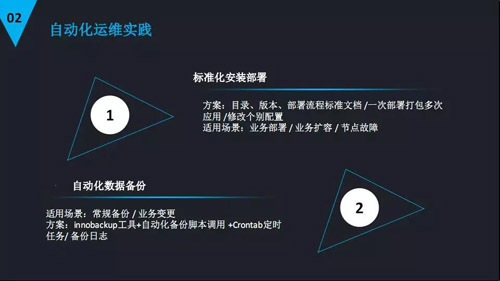
標(biāo)準(zhǔn)化安裝部署
我們的目錄方案,版本以及部署流程有標(biāo)準(zhǔn)文檔去遵循。比如說(shuō)一次部署打包多次應(yīng)用,我們需要在一個(gè)節(jié)點(diǎn)上把標(biāo)準(zhǔn)包打包起來(lái)就一步完成了,那這個(gè)標(biāo)準(zhǔn)化的安裝部署就給后面自動(dòng)化的安裝部署打了一定的基礎(chǔ)。
自動(dòng)化數(shù)據(jù)備份
數(shù)據(jù)備份是我們 DBA 非常重要的一個(gè)工作。所以我們公司也是建立合理有效以及規(guī)范的自動(dòng)化備份的規(guī)范。
比方說(shuō)我們的常規(guī)備份,我們是每周一次全備,變更前后,有一個(gè)業(yè)務(wù)變更了,在這之前要做一個(gè)全備,萬(wàn)一業(yè)務(wù)變更哪里出現(xiàn)問(wèn)題我就可以及時(shí)回退。
這個(gè)是自動(dòng)化使用的場(chǎng)景:我們使用的是 innobackup 工具+自動(dòng)化備份腳本調(diào)用+Crontab 定時(shí)來(lái)做。
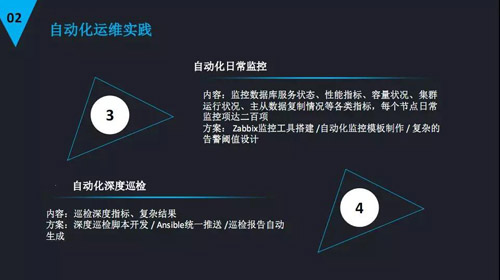
自動(dòng)化日常監(jiān)控
監(jiān)控是 DBA 的第三只眼睛,如果建立實(shí)時(shí)有效的監(jiān)控非常有效。我們的監(jiān)控是采用 Zabbix 監(jiān)控工具。
像確定一些告警閾值這種,一旦超過(guò)了這個(gè)閾值就可以給我們 DBA 發(fā)送短信和郵件,這就是自動(dòng)化的日常監(jiān)控。
自動(dòng)化深度巡檢
這個(gè)就是補(bǔ)充了監(jiān)控所不能達(dá)到的地方。比方說(shuō)如果我們需要掃描或者是看一些大表的情況或者是看一些沒(méi)有建索引表的情況,它的輸出很復(fù)雜,是一張表或者是幾張表,所以我們就需要深度的巡檢來(lái)完成。
深度的巡檢我們公司也是采用開(kāi)發(fā)巡檢腳本,通過(guò) Ansible 統(tǒng)一推送,巡檢報(bào)告自動(dòng)生成。也就是說(shuō)可以很明確的呈現(xiàn)出這個(gè)巡檢的結(jié)果供 DBA 去看和去檢查。
自動(dòng)化故障切換
自動(dòng)化故障切換是發(fā)生在單節(jié)點(diǎn)發(fā)生故障。比如說(shuō)變更操作,一些 Keepalive 部署配置,切換腳本,VRRP 協(xié)議來(lái)實(shí)現(xiàn)的。
也是通過(guò)編寫(xiě)一些腳本,那這個(gè)腳本可能會(huì)定期去檢查我們的數(shù)據(jù)庫(kù)節(jié)點(diǎn)的運(yùn)行狀況。
比如說(shuō)這個(gè) VIP 有沒(méi)有在這個(gè)節(jié)點(diǎn)或者是進(jìn)程在不在?一旦發(fā)生異常就會(huì)自動(dòng)切換這個(gè)節(jié)點(diǎn)。
自動(dòng)化節(jié)點(diǎn)擴(kuò)容
當(dāng)發(fā)生單節(jié)點(diǎn)故障的時(shí)候,我們需要部署一個(gè)新的節(jié)點(diǎn)的時(shí)候就需要啟動(dòng)自動(dòng)化的節(jié)點(diǎn)擴(kuò)容,編寫(xiě)腳本來(lái)做。
自動(dòng)化安全審計(jì)
這就是異常訪(fǎng)問(wèn),異常操作可審計(jì)追溯。部署安全審計(jì)插件,這個(gè)安全審計(jì)的插件+啟用安全審計(jì)日志+日志自動(dòng)化或者是分析提煉。
所以要不要開(kāi)啟這個(gè)插件根據(jù)各位公司對(duì)于安全審計(jì)方面的要求以及對(duì)于性能的要求從兩者取一個(gè)平衡。
因?yàn)槲覀冞€是很看中這個(gè)安全事件,所以我們開(kāi)啟了這個(gè)安全審計(jì)插件,開(kāi)啟這個(gè)插件以后還需要配置文件做一個(gè)配置。
以什么樣的方式存或者是多大?這些參數(shù)都可以在配置文件里面進(jìn)行配置。
自動(dòng)化密碼審計(jì)
這個(gè)自動(dòng)化密碼審計(jì)也是一個(gè)插件,就是我們安裝了強(qiáng)密碼審查的日志,這個(gè)插件的工作原理就是設(shè)置了規(guī)則,我們需要日志要多少位或者是多少位的大小寫(xiě)或者是特殊字符的要求。
我們?cè)O(shè)置密碼的時(shí)候必須符合這個(gè)強(qiáng)密碼驗(yàn)證的要求。這個(gè)也是進(jìn)行實(shí)時(shí)校驗(yàn)的。
也就是說(shuō)我們當(dāng)設(shè)一個(gè)數(shù)據(jù)庫(kù)用戶(hù)的密碼,如果不符合這個(gè)強(qiáng)密碼的需求就不會(huì)給他通過(guò),防止一些比較容易破解的弱密碼。
自動(dòng)化日志分析
我們的日志分析挺重要的,如果出現(xiàn)問(wèn)題就需要這個(gè)日志分析,沒(méi)有問(wèn)題正常的時(shí)候也需要日志分析工具的。
因?yàn)樗軌虬l(fā)生潛在的優(yōu)化建議,我們采用一個(gè) Percona 為工具 Pt-query-digest,我們只需要看 DBA 的慢日志又可以發(fā)現(xiàn)哪些內(nèi)容存在問(wèn)題。
自動(dòng)化數(shù)據(jù)校驗(yàn)
我們通過(guò)自動(dòng)化驗(yàn)校修復(fù)工具來(lái)做,也是設(shè)了 Crontab 的任務(wù)讓它定期執(zhí)行。
自動(dòng)化數(shù)據(jù)清理
因?yàn)閿?shù)據(jù)庫(kù)每天每周都在備份,我們就需要機(jī)制定期清理備份文件。
我們也是采用腳本去開(kāi)發(fā)和定時(shí)看,如果超過(guò)兩個(gè)月的備份文件我們就把它刪掉。如果文件都在兩個(gè)月就不用管它。超過(guò)兩個(gè)月就清除它。
自動(dòng)化日志切分
如果數(shù)據(jù)庫(kù)跑的時(shí)間比較長(zhǎng),慢日志或者是錯(cuò)誤日志比較大,就需要定時(shí)檢測(cè)日志文件,大于某值則自動(dòng)切分,否則不處理。
以上就是我們?cè)跀?shù)據(jù)庫(kù)運(yùn)維的沉淀和積累。雖然不像騰訊或者是阿里那么大的體量和經(jīng)驗(yàn),但是以上是我們探索出來(lái)的一些經(jīng)驗(yàn),希望可以給各位帶來(lái)啟發(fā)或者是幫助。