為你的回歸問題選擇最佳機器學習算法
在處理任何類型的機器學習(ML)問題時,我們有許多不同的算法可供選擇。而機器學習領域有一個得到大家共識的觀點,大概就是:沒有一個ML算法能夠***地適用于解決所有問題。不同ML算法的性能在很大程度上取決于數據的大小和結構。因此,如何選擇正確的算法往往是一個大難題,除非我們直接通過大量的試驗和錯誤來測試我們的算法。
但是,每個ML算法都有一些優點和缺點,我們可以將它們用作指導。雖然一種算法并不總是比另一種更好,但是我們可以使用每種算法的一些屬性作為快速選擇正確算法和調優超參數的指南。我們將介紹一些用于回歸問題的著名ML算法,并根據它們的優缺點設置使用它們的指導方針。這篇文章將幫助您為回歸問題選擇***的ML算法!
線性和多項式回歸
線性回歸
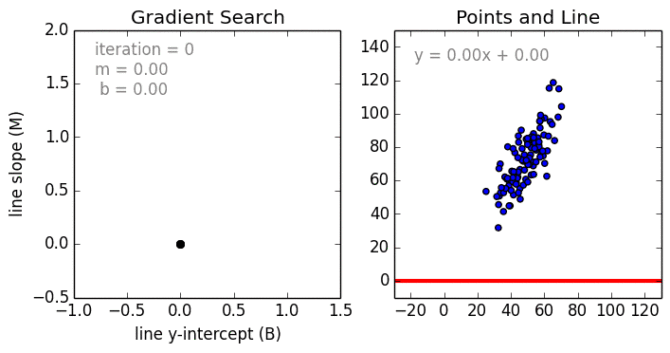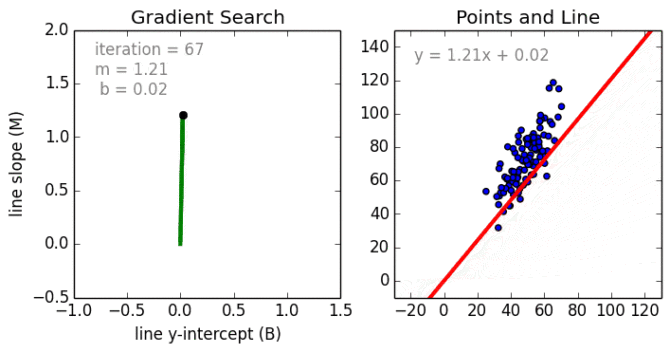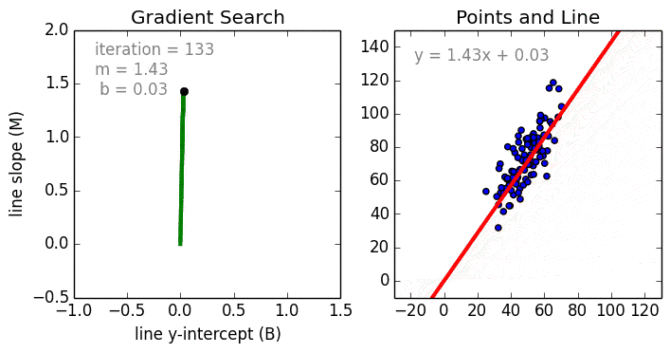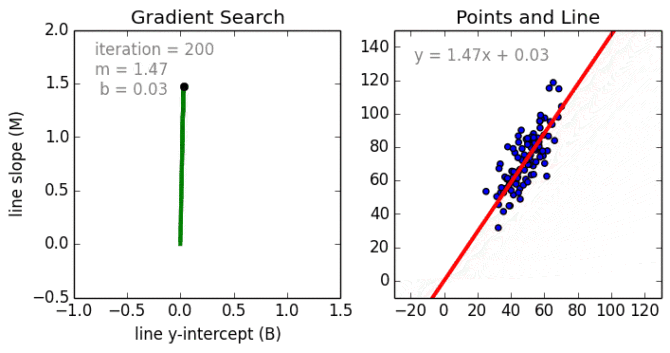
從簡單的情況開始。單變量線性回歸是一種用于使用線性模型例如一條線對單個輸入自變量(特征變量)和輸出因變量之間的關系進行建模的技術。更普遍的情況是多變量線性累加,其中為多個獨立輸入變量(特征變量)和輸出因變量之間的關系創建了一個模型。模型保持線性,因為輸出是輸入變量的線性組合。
第三種最普遍的情況叫做多項式回歸模型現在變成了特征變量的非線性組合,例如可以是指數變量,和余弦等,但這需要知道數據與輸出的關系。回歸模型可以使用隨機梯度下降(SGD)進行訓練。
優點:
- 快速建模,當要建模的關系不是非常復雜,而且你沒有很多數據時,這是非常有用的。
- 線性回歸很容易理解哪些對業務決策非常有用。
缺點:
- 對于非線性數據,多項式回歸的設計是非常具有挑戰性的,因為必須有一些關于數據結構和特征變量之間關系的信息。
- 因此,當涉及到高度復雜的數據時,這些模型并不像其他模型那樣好。
神經網絡
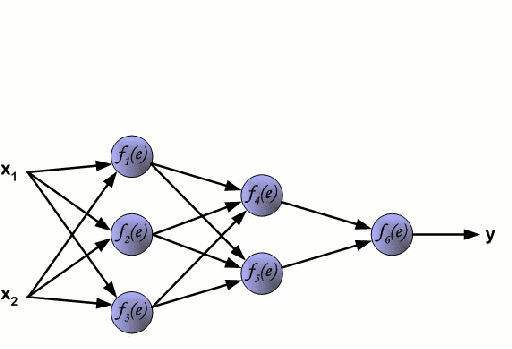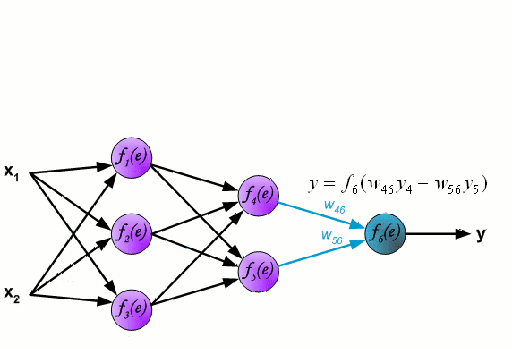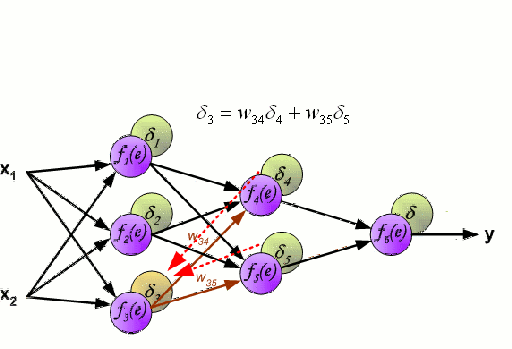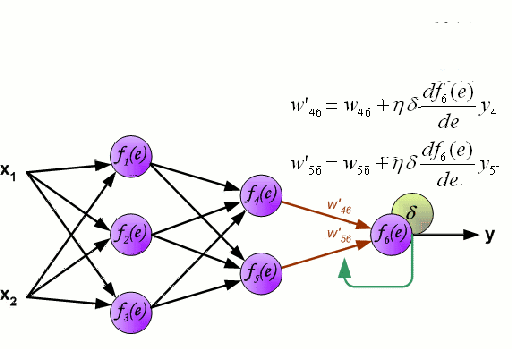
神經網絡由一組相互連接的被稱作神經元的節點組成。數據中的輸入特征變量作為多變量線性組合傳遞給這些神經元,其中每個特征變量乘以的值稱為權重。然后將非線性應用于這種線性組合,使神經網絡能夠建立復雜的非線性關系。神經網絡可以有多個層,其中一層的輸出以同樣的方式傳遞給下一層。在輸出端,通常不應用非線性。神經網絡的訓練使用隨機梯度下降(SGD)和反向傳播算法(兩者都顯示在上面的GIF中)。
優點:
- 由于神經網絡可以有許多具有非線性的層(和參數),因此它們在建模高度復雜的非線性關系時非常有效。
- 我們通常不需要擔心,神經網絡的數據結構在學習任何類型的特征變量關系時都很靈活。
- 研究表明,簡單地向網絡提供更多的訓練數據,無論是全新的,還是增加原始數據集,都有利于網絡性能。
缺點:
- 由于這些模型的復雜性,它們并不容易解釋和理解。
- 對于訓練而言,它們可能具有相當的挑戰性和計算密集性,需要仔細進行超參數調整,設定學習進度計劃。
- 它們需要大量的數據才能獲得高性能,在“小數據”情況下,它們往往會被其他ML算法超越。
回歸樹和隨機森林
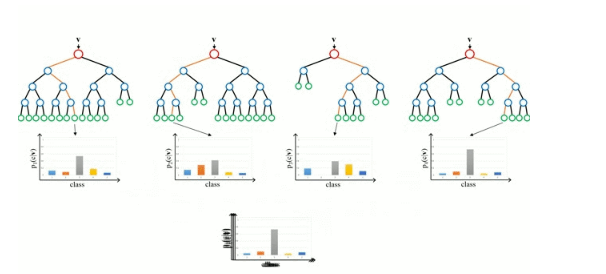
隨機森林
從基本情況開始。決策樹是一種直觀的模型,通過一個遍歷樹的分支,并根據節點上的決策選擇下一個分支。樹誘導是將一組訓練實例作為輸入的任務,決定哪些屬性最適合拆分,分割數據集,并在產生的拆分數據集上重復出現,直到所有的訓練實例都被分類為止。構建樹時,目標是對創建可能的***純度子節點的屬性進行分割,這將使對數據集中的所有實例進行分類時,需要進行的分割數量保持***。純度是由信息增益的概念來衡量的,這一概念涉及為了對其進行適當的分類,需要對一個以前不可見的實例了解多少。在實踐中,通過比較熵,或對當前數據集分區的單個實例進行分類所需的信息量,對單個實例進行分類,如果當前的數據集分區要在給定的屬性上進一步分區的話。
隨機森林只是一組決策樹。輸入向量在多個決策樹中運行。對于回歸,取所有樹的輸出值的平均值;對于分類,使用投票方案來決定最終的類。
優點:
- 擅長學習復雜的、高度非線性的關系。它們通常可以達到相當高的性能,比多項式回歸更好,而且通常與神經網絡相當。
- 很容易解釋和理解。雖然最終的訓練模型可以學習復雜的關系,但是在訓練過程中建立的決策邊界是很容易理解和實用的。
缺點:
- 由于訓練決策樹的性質,它們可能傾向于主要的過度擬合。一個完整的決策樹模型可能過于復雜,包含不必要的結構。雖然這有時可以通過適當的樹木修剪和更大的隨機森林組合來緩解。
- 使用更大的隨機森林組合來實現更高的性能帶來了速度慢和需要更多內存的缺點。
***
希望你喜歡這篇文章,并學到一些新的和有用的東西。