踩坑實踐:如何消除微服務架構中的系統耦合?
原創【51CTO.com原創稿件】微服務架構實施后,不少通用數據訪問會拆分成服務,通用業務也會拆分成服務,站點與服務之間的依賴關系會變得復雜,服務與服務之間的調用關系也會變得復雜。
如果水平拆分/垂直拆分得不合理,系統之間會嚴重耦合,如何消除微服務架構中的系統耦合?
2018 年 5 月 18 - 19 日,由 51CTO 主辦的全球軟件與運維技術峰會在北京召開。
在“微服務架構設計”分會場,58 速運 CTO 沈劍帶來了《58 速運微服務架構解耦最佳實踐》的主題分享。
本文將按照如下幾個方面來展開分享:
- 微服務之前,系統中存在的耦合問題
- 微服務架構,存在什么問題?
- 58 速運的微服務實踐
- 總結
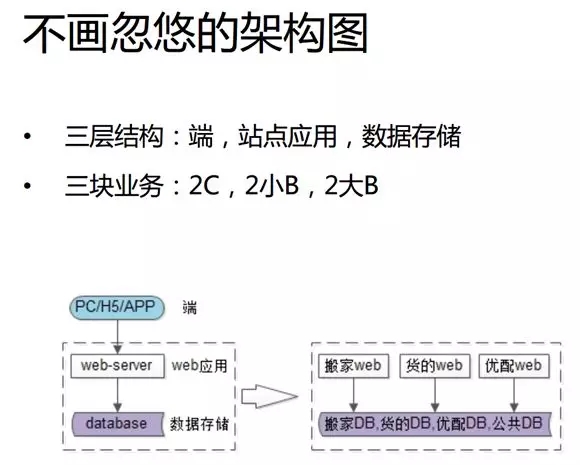
相對于 58 同城,58 速運屬于一家初創型公司。在早期,我們使用的是簡單的三層架構:
- 最上游是端,包括 PC、H5 和 App。
- 中間是 Web 應用。
- 下面是數據存儲。
這樣的架構能夠適應 58 速運早期“搶時間”這一特點的快速發展模式,同時也能夠支撐產品的快速迭代。
比如 58 速運能夠在接到請求之后的 5 分鐘內開車過來,將您的一個家具搬到某處。
在業務上,我們與滴滴的相同之處是:“同城、短途、及時性”;而區別則是:滴滴“帶人”、我們“拉貨”。
我們當前的業務主要分為三大塊:
- 2 C,如:幫助大家搬家,不過客頻次比較低,不屬于我們主要的訂單來源。
- 2 小 B,如:幫助賣五金、建材、衛浴等小商戶每天把貨物送到客戶家里,所以頻次比較高。
- 2 大 B,如:幫助 OFO 之類的企業客戶每天將共享單車從倉庫里運到各個地點。
所以總體來說,我們采用的是一般創業型公司最常見的架構,并將業務垂直地切分為三塊。
包括:搬家的站點(Web);為小 B 叫“貨的”的站點;為大 B“優配”的站點。在最底下則是統一的數據庫存儲。
隨著業務的持續發展,數據量的慢慢上升,我們在之后的兩、三年碰到了耦合的問題。
俗話說:歷史總是驚人的相似,大家可以結合我下面的介紹,看看是否也遇到過此類問題?
微服務之前,系統中存在的耦合問題
為啥代碼會 Copy 來 Copy 去?
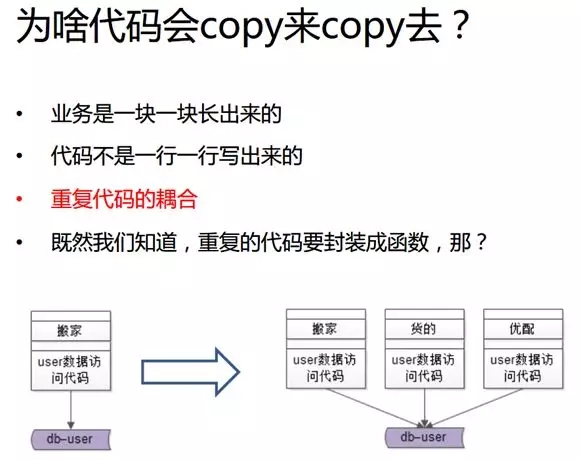
最早期我們并沒有小 B 類和大 B 類,而只有一個“貨的”的系統和站點。所有用戶都是統一的,并未做任何類型上的垂直切分,全部的請求也都通過“貨的”的數據訪問層,去訪問底層數據。
接著,我們發現 C 類的客頻次比較低,因此逐漸增加了“貨的”業務、“優配”業務、“貨的”的站點、“貨的”的數據訪問、“優配”的站點、“優配”的數據訪問等。
可見,業務就這么一塊、一塊長出來了。但是代碼可不是真正一行、一行寫出來的。
在早期組織架構中,我們只有 5 個人負責“貨的”的前端、后端,直至運維的全部。
后來我們增加了 3 個人負責“優配”業務,又增加了 10 個人從事“貨的”業務。
可見,早期為了提高效率,幾個人就這么粗獷地把研發到測試全干了。而后期就算有業務的新增,我們同樣需要用到之前業務中對于用戶數據的“增、刪、查、改”。
而此時,我們的團隊并不會從頭將代碼重寫一遍,而是從同事那里將以前現成的代碼復制、粘貼過來,再結合自己的業務特性稍作修改,并保持大部分代碼的一致。
眾所周知,代碼復制會存在許多潛在的問題。因此在同一個模塊、以及同一個工程里,我們不允許通過復制、粘貼而產生重復代碼的函數;而在跨工程、跨業務、跨系統時,代碼復制同樣是被禁止的。
因為,如果原來的那套代碼出現了問題,或是在用戶數據表需要升級的時候,我們會面臨許多地方需要修改的痛點。這正是跨系統、跨業務所帶來的耦合問題。
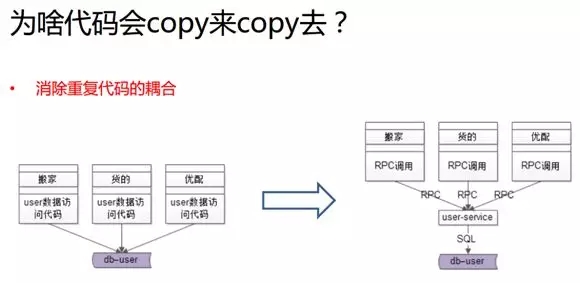
從架構層面來說,通過對服務層進行抽象,能夠緩解由于業務日趨復雜和重復代碼的日益增多所帶來的各種隱患。
因此,我們將用于訪問“搬家”、“貨的”、“優配”的用戶數據的那部分代碼抽象出來,變成一個通用的 user-service。
就像調用本地函數那樣,業務方通過一行代碼,傳遞一個 UID 過去,以獲得 UID 的實例。
而具體如何拼裝 SQL 語句,則被 DAO 層放到了 user-service 的微服務中,從而向上游屏蔽了底層的 SQL 拼裝過程。
在抽象 Service 的過程中,我們所遵循的原則是:公共的部分下沉,而個性化的部分則由每個業務線來承擔。
我們籍此減少了由于代碼的反復拷貝所導致的耦合問題。可見,微服務是一種對于創業性公司業務增長的潛在解決方案。
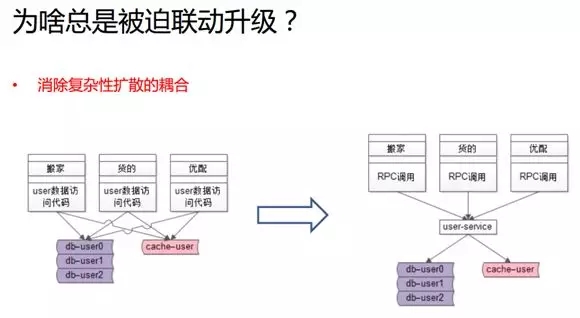
為啥總是被迫聯動升級?
隨著我們數據量和訪問量的上漲,系統的不同部分難免會出現不同的問題,最明顯的就是:讀取吞吐量的增大。
對于創業性公司的絕大部分業務場景來說,最先出現的都是由于讀多寫少所帶來的數據庫瓶頸問題。
所以一般來說我們不用去修改代碼,而直接將數據庫做出集群,以主從同步、和從多個服務器上讀取數據的方式來提升讀的性能。
同時我們也可以增加緩存,以降低數據庫和磁盤 I/O 的壓力。這都是常見的優化手段。
在增加了緩存之后,你會發現讀取數據的流程和訪問數據的代碼也會相繼發生了變化。
即:從直接訪問數據庫變成了先訪問緩存,如果在緩存里命中、則直接返回;如果未命中、再訪問讀庫、將數據取出后放入緩存中。
與此同時,數據的寫入也會發生類似的變化。即:從直接操作寫入數據庫變成了需要考慮緩存的一致性,你必須得把緩存淘汰掉,才能修改數據庫內容。
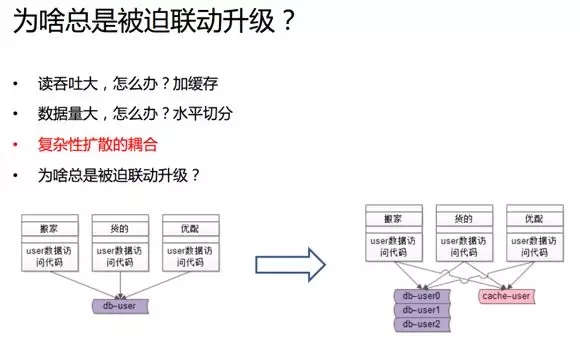
由于速運有著多塊垂直的業務和不同的用戶分類,因此引入緩存的復雜性會擴散到整個業務線上。
例如:由于用戶的訪問量巨大,我們增加了緩存,那么各個產品系統,包括“搬家”、“貨的”、“優配”等流程就需要做相應的升級。
而其中“優配”的負責人會覺得:“是因為底層的復雜性擴散到我這里,我是被迫進行技術改進和升級的。”
那么隨著數據量的增大,我們通過綜合運用上述方法,采取了水平切分的方式來優化整體架構的性能。
例如:我們會將單個用戶庫或用戶表轉化為多個實例、多個庫、多個表,以降低單實例、單庫、單表的數據量,從而提升整體的容量。這也是互聯網架構中十分常見的技術優化手段。
在過去單庫的模式下,你只需要將 SQL 語句發往該數據庫便可;而變成多個庫之后,則會涉及到集函數、求最大/最小、Join 等方面。
由于數據庫被水平切分,業務側的代碼需要做相應的改動。而當你有多個上游的時候,你會發現底層的復雜性會迅速擴散到所有的上游業務方那里。
上述提到的上游業務方所必須關注的緩存復雜性和切分復雜性,只是兩個最典型的例子。
我們 58 同城還曾出現過:底層的存儲引擎由 MySQL 變更為 MongoDB 的情況。
這些底層資源的耦合和復雜性的變化,都值得上游的所有業務方予以關注。
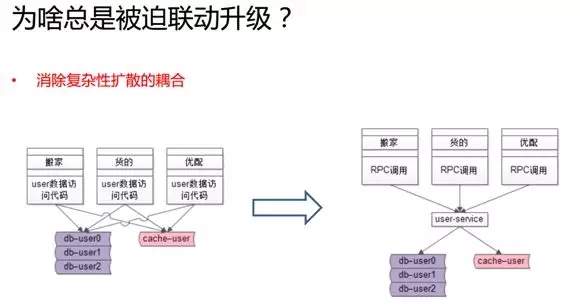
由此可見,服務化可以讓上述問題得到緩解。因為,它只需要一個團隊去關注底層的復雜性。
如上圖所示在升級之后,所有的業務側通過 RPC 就像調用本地函數一樣去獲取遠端的數據,只要傳一個 UID 過去便能獲取一個用戶的實體。
具體這些數據是放在哪個分庫中(是放在緩存中、MySQL 中、還是 MongoDB 中),只需被服務層所關注。
而當底層需要升級的時候,所有的調用方,乃至所有的業務線都不會被牽動,我們只需對服務進行升級。可見,通過服務化,我們很好地解決了底層復雜性的耦合問題。
兄弟部分上線,為啥我們掛了?
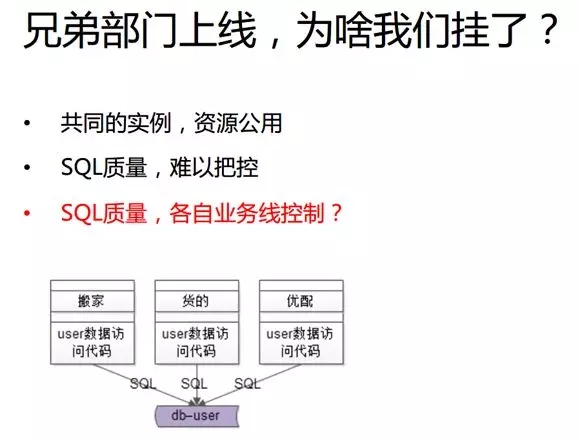
在服務化之前,多個業務線會同時訪問同一份數據,以前面的用戶數據為例。
雖然我們的每個業務線都能夠通過由 DAO 拼裝的 SQL 語句去訪問同一個數據層(當然也有些公司甚至都沒有 DAO 層,而直接拼裝 SQL 語句去訪問數據庫),但是每個業務線上工程師的能力是不一樣的。
較資深的工程師在拼裝 SQL 的過程中,會考慮到索引以及優化等問題;但是一些經驗欠佳的工程師在寫下一行 DAO 代碼的時候,可能不曾想到它所被轉化的 SQL 語句。
還可能因為沒有命中索引,而導致數據庫的全盤掃描,進而出現 CPU 的利用率達到百分之百的問題。
過去,我們“搬家”的業務線曾寫了一個非常低效的 SQL 語句并發布到了線上。
它直接導致了整個數據庫實例的 CPU 利用率高達百分之百,進而影響到了“貨的”和“優配”。
而由于“搬家”的訂單量遠小于“貨的”和“優配”的訂單量,那么“貨的”一旦訪問訂單的時候,就會發現系統是訪問不了的。
這就造成了:“搬家”的上線卻導致“貨的”“掛掉”了的局面。究其原因,正是因為該架構中 SQL 語句的質量沒有得到很好的控制。
另外,我們也需要遵從 SQL、Java 等方面的編程規范。我在負責 DBA 部門的時候,就曾要求:無論什么規范,都必須限定在十條以內,以合適一張 A4 紙單面打印出來。
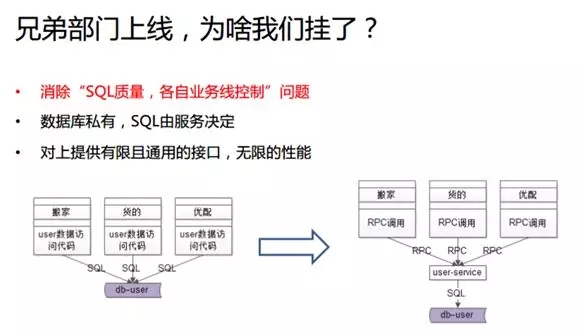
在做了服務化之后,服務層應能夠向上游業務提供一些相對比較通用的 RPC 訪問,我們籍此可以通過服務層來控制 SQL 的質量。
這里同樣以用戶數據的“增、刪、查、改”為例,在用戶側訪問時,如果你傳來用戶名/密碼,我就回傳 UID;如果你傳來一個 UID,我就給你一個用戶的實例。
可見,這些接口都是非常有限且通用的。它們對于數據庫的訪問,都被控制在 Service 上,而非用戶層面。所以我總結出來服務化具有如下原則:
數據庫私有
任何上游不得繞過 Service 去訪問底層數據庫。業務層只能調用接口,即 SQL 由服務所決定,這一點很重要。
對上游提供有限且通用的接口
許多公司雖然做了服務化,但是服務層仍然有許多個性化的、與業務緊密相關的接口,這就沒有達到服務化的目的。
例如:我們曾經在 user-service 里,有著大量與“搬家”、“貨的”、“優配”相關的業務代碼,一旦上游出現新的需求,他就提交給服務層去修改。
這樣的話,user-service 實際上實現的是各種個性化的需求,由于這些接口的復用性低,因此不但會導致其代碼的混亂,還會造成研發的瓶頸。可見,服務化只應該提供有限的通用接口。
服務側要保證無限的性能
我們通過水平擴展、加緩存、分表等方式去解決各種并發量、吞吐量、和數據量的問題,從而保證了上游側不必關心各種操作的實現細節。這就是服務維護者對外的一種服務承諾。
業務一旦出了問題只會影響到自己;如果服務出現了故障,那么就會有深遠的影響,甚至會導致用戶無法登錄。
可見,諸如用戶 Service、訂單 Service、支付 Service、商家 Service,都必須具有良好的穩定性。
我們曾經在“同城”做過的一個實踐是:將公司最基礎的 Service 放置在架構部,由資深的工程師去做維護。
數據庫拆分真的容易?
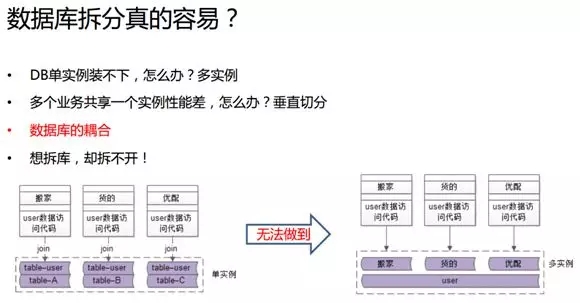
在最早期,由于 58 速運的數據量較小,我們只用一個庫將所有表格包含其中。
這些表中既有如用戶表這樣的公共表格,也有一些業務個性化的表格,例如與“搬家”相關的一些用戶信息。
公共表以 UID 為 Key 放置用戶公布的屬性;個性化表同樣以 UID 為 Key,包括“搬家”用戶個性化屬性。那么,“搬家”的某些業務場景可能會同時提取公共的和個性化的數據。
由于只有一個庫、一個實例,我們通過簡單代碼直接根據相同的 UID、運用 Join 去操作兩張表,便可取出所有需要的數據。即使用到對于 UID 的索引,也不會有多次的交互,或出現性能的問題。
當然,這些都是基于兩張表必須在同一個實例中的前提條件。同理,我們的“貨的”、“優配”也是這么各自構建的。
另外,除了 Join,還有各種子查詢、自制定函數、視圖、觸發器,都可能出現耦合在一個實例的情況。因此,我們很難將這種結構拆成多個實例。
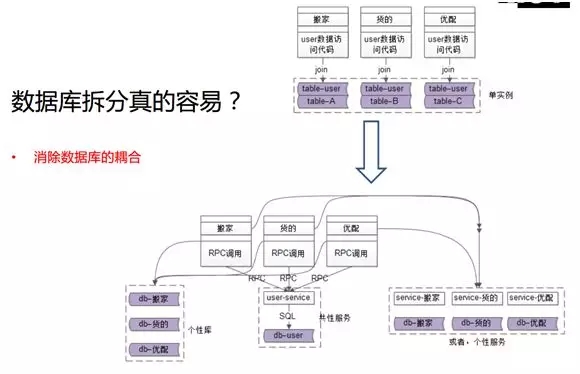
那么當業務越來越復雜、數據量越來越大、數據庫里的數據表越來越多時,我們勢必要消除數據庫的耦合,通過微服務架構的改造來拆分出多個實例。
如圖所示,最上方是原始的耦合,我們在下面抽象出來共性的數據,包括 user-service 和 db-user(一個單獨的實例)。
對于個性化的數據,我們也要拆到個性化的庫里。如果你要進一步拆分的話,我們還能對共性的數據以及個性的數據分別抽象成 Service。
如圖所示,“搬家”、“貨的”、“優配”都分別有自己的 Service,和各自的數據庫,從而實現了將業務整體數據拆到了多個單實例中。
我們的拆分目標是:實現數據請求需要根據 UID 訪問 RPC 接口,并基于 user-service 先拿到共性數據。
如果你只是抽象了數據庫,那么需要用 UID 去拼裝 SQL 以拿個性的數據;如果你也抽象了業務 Service,那么就通過 UID 自己做邏輯拼裝,產生完整的 SQL 語句,去訪問業務 Service 的接口,從而得到業務個性化的數據。
這是一個循序漸進的過程,我們耗時三個季度,對站點應用層的代碼做了大量的修改工作。
完成之后,我們實現了:根據 DBA 新增的設備臺數和新的實例,將數據拆出來并遷移過去。
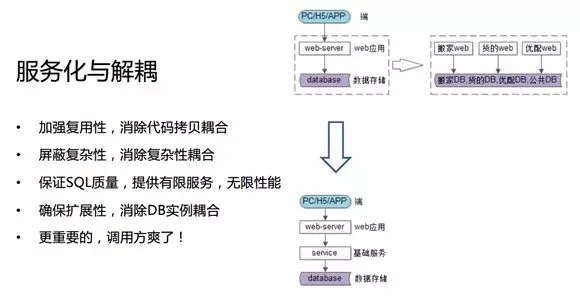
由上可見,兩層變三層的架構給我們帶來了四點好處:
- 加強了復用性
- 屏蔽了復雜性
- 保證了 SQL 質量
- 確保了擴展性
而且調用方不再需要關注 JDBC、DAO 和緩存,只需傳送 UID 便可。
微服務架構,存在什么問題?

眾所周知,各種技術大會一般都只講服務化和微服務的好處,幾乎不會提及坑點。
而大家也不要盲目地評判諸如 Dubbo 等微服務框架的優劣,更不要以為引入了 RPC 框架,就實現了服務化。
我們通過親自實踐,在經歷了改造、消除了耦合、演進了架構的過程中,也遇到過如下的問題:
微服務會帶來系統復雜性的上升
即:原來由數據庫單點做緩存,改造后會增加多個服務層。
層次依賴關系會變得非常復雜
即:原來是 Nginx/站點/數據庫的模式,改造后引入了多個相互依賴的服務,包括數據庫與緩存。
而且服務還可能會再次調用其他的服務,例如:我們的“同城”,它在業務上就像一個包含了各種帖子的論壇,一般由商業置頂推薦部分、付費部分、中間自然搜索部分、下面人工部分、以及右側的個人中心所組成。
這些數據的展示,需要先訪問商業服務進行搜索、獲得搜索數據后,再推薦服務,以及調用個性化的數據,最后拼裝成一個列表頁面。
這些代碼在各個業務線上都有重復。而如果商業的結構需要升級,則所有的業務線接口都予以跟進;如果推薦部分出現了 Bug,那么所有都要跟著修改。
因此我們把相同的公共部分抽象為通用列表的服務,由它來統一調用底層的商業服務、自然搜索服務、推進服務和個人服務。
隨著業務邏輯的日趨復雜,我們的服務層次也會增多,而服務的抽象和相互之間的依賴關系也勢必日漸復雜。
監控和運維部署也會變得復雜
例如:在一個站點上集群了三個節點的時候,我們在早期并沒有專門地去做運維,而是首先 SSH 到第一臺→wget 一個 war 包→解壓→restart。然后同法炮制第二臺、第三臺。
那么當站點有十個以上時,運維就不能這么做了。因此從長遠來看,我們需要開發自動化的運維腳本和運維平臺。
那么在引入服務化之后,隨著服務與集群數量的增加,運維部署與監控的工作量也勢必會有所增加。
定位問題更麻煩
例如:當用戶反饋登錄緩慢時,負責 Web 登錄的人員通過排查發現是列表服務的問題,就轉給其列表服務人員。
列表服務的人員經查發現是調用不出用戶中心了→則由負責用戶中心的工程師進一步調查→他們上升到 DBA 那里→DBA 通過運維人員才發現是阿里云上的某個節點出了問題。
最終認定問題不大,只需重啟或摘除掉該節點,以及修改網絡配置便可恢復。可見這樣的定位過程是極其復雜的。
綜上所述,微服務也會給我們帶來一些潛在問題,因此大家要事先考慮周全。
58 速運的微服務實踐

我們通過實踐形成了一套技術體系,從而更快、更好地支持了自己的微服務架構:
統一的服務框架
我的建議是:要在一開始就定下整體統一的基礎體系,通過統一語言、統一框架,來減少重復開發。
例如 58 同城很早就統一了自研的框架,盡管初期并不太好用,但是隨著時間的推移,它被慢慢地改善且好用起來。
統一數據訪問層
如果有的團隊用 JDBC,有的用 DAO,這樣重復的成本會很高,因此一定要事先達成共識。
配置中心
早期各個 user-service 的 IP 地址都被寫在配置文件里,那么一旦服務需要擴容出一個節點,就需要找到所有調用它的上游調用方,告知 IP 地址的變更,調用方再各自經歷復雜的修改,并配以必要的重啟。
而如果我們使用的是配置中心的話,則可以通過簡單配置,以平臺發通知的方式,告知 IP 的變更,進而所有調用方的流量都會被遷移到新的節點之上。
服務治理
包括:服務發現與限流等一系列的問題。例如:某個上游的調用方寫了一個帶有 Bug 的死循環,導致將下游所有的調用次數都占滿了。
那么我們可以運用服務質量的治理,根據調用方的峰值來進行配額和限流。
如此,就算出現了死循環,它只會把自己的配額用光,而不影響到其他的業務線。
可見服務質量的管理對于服務本身的快速擴/縮容,以及遇到問題時的降級,都是非常有用的。
統一監控
為了實現統一的服務框架和數據訪問層,我們可以在框架層的請求出入口、在 DAO 的層面上、訪問數據庫的前/后、訪問緩存、以及訪問 Redis 的 MemoryCacheClient 時簡單包裝一層。
從而 hook 這些節點,快速地監控到所有的接口、數據庫的訪問、緩存訪問的時間。可見在框架層面上,所有的接口都能夠被統一監控到。
統一調用鏈分析
由于微服務化之后,層次關系變得復雜,因此我們需要具有一個調用關系的視圖。
如果出現某個請求的超時,我們就能迅速定位到是網絡、是數據庫、還是節點的問題。
自動化運維平臺
通過調節服務的上限與擴容等操作,讓服務化給技術體系帶來更大的便利。
總結

微服務解決了:代碼拷貝的耦合,底層復雜性擴散的耦合,SQL 質量不可控,以及 DB 實例無法擴容的耦合問題。
同時,微服務帶來的問題有:系統復雜性的上升,層次間依賴關系變得復雜,運維、部署更麻煩,監控變得更復雜,定位問題也更麻煩等。
因此服務化并不是簡單引入一個RPC框架,而是需要一系列的技術體系來做支撐。
我們需要通過建立該技術體系,以解決如下可能面對的問題:
- 統一服務框架和數據訪問層(包括:數據庫的統一訪問、緩存、Redis 的 MemoryCache 等)
- 配置中心和服務治理
- 統一的監控
- 調用鏈
- 自動化運維平臺
互聯網架構技術專家,“架構師之路”公眾號作者。曾任百度高級工程師,58同城高級架構師,58 同城技術委員會主席。2015 年調至 58 到家任高級總監,技術委員會主席,負責基礎架構,技術平臺,運維安全,信息系統等后端技術體系搭建。2017 年調至 58 速運任 CTO,負責 58 速運技術體系的搭建。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】