前端遇上Go: 靜態(tài)資源增量更新的新實踐
為什么要做增量更新
美團金融的業(yè)務在過去的一段時間里發(fā)展非常快速。在業(yè)務增長的同時,我們也注意到,很多用戶的支付環(huán)境,其實是在弱網環(huán)境中的。
大家知道,前端能夠服務用戶的前提是 JavaScript 和 CSS 等靜態(tài)資源能夠正確加載。如果網絡環(huán)境惡劣,那么我們的靜態(tài)資源尺寸越大,用戶下載失敗的概率就越高。
根據我們的數據統(tǒng)計,我們的業(yè)務中有2%的用戶流失與資源加載有關。因此每次更新的代價越小、加載成功率越高,用戶流失率也就會越低,從而就能夠變相提高訂單的轉化率。
作為一個發(fā)版頻繁的業(yè)務,要降低發(fā)版的影響,可以做兩方面優(yōu)化:
更高效地使用緩存,減少靜態(tài)資源的重復下載。
使用增量更新,降低單次發(fā)版時下發(fā)的內容尺寸。
針對***點,我們有自己的模塊加載器來做,這里先按下不表,我們來重點聊聊增量更新的問題。
增量更新是怎么一個過程
看圖說話。
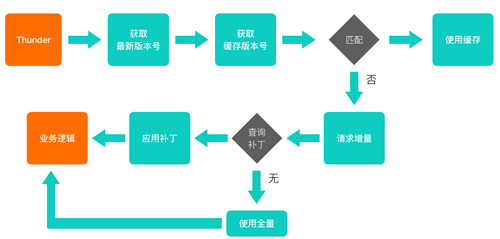
增量更新的客戶端流程圖
我們的增量更新通過在瀏覽器端部署一個 SDK 來發(fā)起,這個 SDK 我們稱之為 Thunder.js 。
Thunder.js 在頁面加載時,會從頁面中讀取***靜態(tài)資源的版本號。同時, Thunder.js 也會從瀏覽器的緩存(通常是 localStorage)中讀取我們已經緩存的版本號。這兩個版本號進行匹配,如果發(fā)現(xiàn)一致,那么我們可以直接使用緩存當中的版本;反之,我們會向增量更新服務發(fā)起一個增量補丁的請求。
增量服務收到請求后,會調取新舊兩個版本的文件進行對比,將差異作為補丁返回。Thunder.js 拿到請求后,即可將補丁打在老文件上,這樣就得到了新文件。
總之一句話:老文件 + 補丁 = 新文件。
增量補丁的生成,主要依賴于 Myers 的 diff 算法。生成增量補丁的過程,就是尋找兩個字符串最短編輯路徑的過程。算法本身比較復雜,大家可以在網上找一些比較詳細的算法描述,比如這篇 《The Myers diff algorithm》,這里就不詳細介紹了。
補丁本身是一個微型的 DSL(Domain Specific Language)。這個 DSL 一共有三種微指令,分別對應保留、插入、刪除三種字符串操作,每種指令都有自己的操作數。
例如,我們要生成從字符串“abcdefg”到“acdz”的增量補丁,那么一個補丁的全文就類似如下:
=1\t-1\t=2\t-3\t+z
這個補丁當中,制表符\t是指令的分隔符,=表示保留,-表示刪除,+表示插入。整個補丁解析出來就是:
- 保留1個字符
- 刪除1個字符
- 保留2個字符
- 刪除3個字符
- 插入1個字符:z
具體的 JavaScript 代碼就不在這里粘貼了,流程比較簡單,相信大家都可以自己寫出來,只需要注意轉義和字符串下標的維護即可。
增量更新其實不是前端的新鮮技術,在客戶端領域,增量更新早已經應用多年。看過我們《美團金融掃碼付靜態(tài)資源加載優(yōu)化實踐》的朋友,應該知道我們其實之前已有實踐,在當時僅僅靠增量更新,日均節(jié)省流量達30多GB。而現(xiàn)在這個數字已經隨著業(yè)務量變得更高了。
那么我們是不是就已經做到萬事無憂了呢?
我們之前的增量更新實踐遇到了什么問題
我們最主要的問題是增量計算的速度不夠快。
之前的優(yōu)化實踐中,我們絕大部分的優(yōu)化其實都是為了優(yōu)化增量計算的速度。文本增量計算的速度確實慢,慢到什么程度呢?以前端比較常見的JS資源尺寸——200KB——來進行增量計算,進行一次增量計算的時間依據文本不同的數量,從數十毫秒到十幾秒甚至幾十秒都有可能。
對于小流量業(yè)務來說,計算一次增量補丁然后緩存起來,即使***次計算耗時一些也不會有太大影響。但用戶側的業(yè)務流量都較大,每月的增量計算次數超過 10 萬次,并發(fā)計算峰值超過 100 QPS 。
那么不夠快的影響是什么呢?
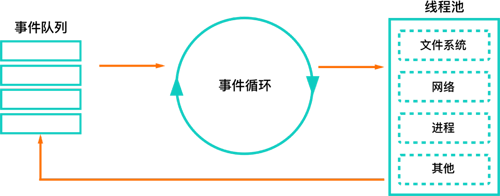
我們之前的設計大致思想是用一個服務來承接流量,再用另一個服務來進行增量計算。這兩個服務均由 Node.js 來實現(xiàn)。對于前者, Node.js 的事件循環(huán)模型本就適合進行 I/O 密集型業(yè)務;然而對于后者,則實際為 Node.js 的軟肋。 Node.js 的事件循環(huán)模型,要求 Node.js 的使用必須時刻保證 Node.js 的循環(huán)能夠運轉,如果出現(xiàn)非常耗時的函數,那么事件循環(huán)就會陷入進去,無法及時處理其他的任務。常見的手法是在機器上多開幾個 Node.js 進程。然而一臺普通的服務器也就8個邏輯CPU而已,對于增量計算來說,當我們遇到大計算量的任務時,8個并發(fā)可能就會讓 Node.js 服務很難繼續(xù)響應了。如果進一步增加進程數量,則會帶來額外的進程切換成本,這并不是我們的***選擇。
更高性能的可能方案
“讓 JavaScript 跑的更快”這個問題,很多前輩已經有所研究。在我們思考這個問題時,考慮過三種方案。
Node.js Addon
Node.js Addon 是 Node.js 官方的插件方案,這個方案允許開發(fā)者使用 C/C++ 編寫代碼,而后再由 Node.js 來加載調用。由于原生代碼的性能本身就比較不錯,這是一種非常直接的優(yōu)化方案。
ASM.js / WebAssembly
后兩種方案是瀏覽器側的方案。
其中 ASM.js 由 Mozilla 提出,使用的是 JavaScript 的一個易于優(yōu)化的子集。這個方案目前已經被廢棄了。
取而代之的 WebAssembly ,由 W3C 來領導,采用的是更加緊湊、接近匯編的字節(jié)碼來提速。目前在市面上剛剛嶄露頭角,相關的工具鏈還在完善中。 Mozilla 自己已經有一些嘗試案例了,例如將 Rust 代碼編譯到 WebAssembly 來提速 sourcemap 的解析。
然而在考慮了這三種方案之后,我們并沒有得到一個很好的結論。這三個方案的都可以提升 JavaScript 的運行性能,但是無論采取哪一種,都無法將單個補丁的計算耗時從數十秒降到毫秒級。況且,這三種方案如果不加以復雜的改造,依然會運行在 JavaScript 的主線程之中,這對 Node.js 來說,依然會發(fā)生嚴重的阻塞。
于是我們開始考慮 Node.js 之外的方案。換語言這一想法應運而生。
換語言
更換編程語言,是一個很慎重的事情,要考慮的點很多。在增量計算這件事上,我們主要考慮新語言以下方面:
- 運行速度
- 并發(fā)處理
- 類型系統(tǒng)
- 依賴管理
- 社區(qū)
當然,除了這些點之外,我們還考慮了調優(yōu)、部署的難易程度,以及語言本身是否能夠快速駕馭等因素。
最終,我們決定使用 Go 語言進行增量計算服務的新實踐。
選擇Go帶來了什么
高性能
增量補丁的生成算法,在 Node.js 的實現(xiàn)中,對應 diff 包;而在 Go 的實現(xiàn)中,對應 go-diff 包。
在動手之前,我們首先用實際的兩組文件,對 Go 和 Node.js 的增量模塊進行了性能評測,以確定我們的方向是對的。
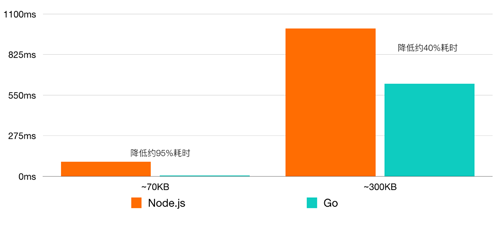
相同算法、相同文件的計算時間對比
結果顯示,盡管針對不同的文件會出現(xiàn)不同的情況,Go 的高性能依然在計算性能上碾壓了 Node.js 。這里需要注意,文件長度并不是影響計算耗時的唯一因素,另一個很重要的因素是文件差異的大小。
不一樣的并發(fā)模型
Go 語言是 Google 推出的一門系統(tǒng)編程語言。它語法簡單,易于調試,性能優(yōu)異,有良好的社區(qū)生態(tài)環(huán)境。和 Node.js 進行并發(fā)的方式不同, Go 語言使用的是輕量級線程,或者叫協(xié)程,來進行并發(fā)的。
專注于瀏覽器端的前端同學,可能對這種并發(fā)模型不太了解。這里我根據我自己的理解來簡要介紹一下它和 Node.js 事件驅動并發(fā)的區(qū)別。
如上文所說, Node.js 的主線程如果陷入在某個大計算量的函數中,那么整個事件循環(huán)就會阻塞。協(xié)程則與此不同,每個協(xié)程中都有計算任務,這些計算任務隨著協(xié)程的調度而調度。一般來說,調度系統(tǒng)不會把所有的 CPU 資源都給同一個協(xié)程,而是會協(xié)調各個協(xié)程的資源占用,盡可能平分 CPU 資源。
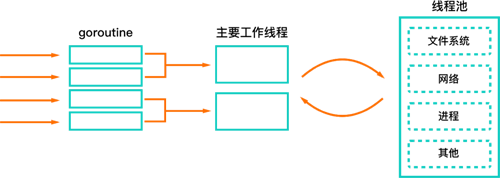
Go 的 goroutine
相比 Node.js ,這種方式更加適合計算密集與 I/O 密集兼有的服務。
當然這種方式也有它的缺點,那就是由于每個協(xié)程隨時會被暫停,因此協(xié)程之間會和傳統(tǒng)的線程一樣,有發(fā)生競態(tài)的風險。所幸我們的業(yè)務并沒有多少需要共享數據的場景,競態(tài)的情況非常少。
實際上 Web 服務類型的應用,通常以請求 -> 返回為模型運行,每個請求很少會和其他請求發(fā)生聯(lián)系,因此使用鎖的場景很少。一些“計數器”類的需求,靠原子變量也可以很容易地完成。
不一樣的模塊機制
Go 語言的模塊依賴管理并不像 Node.js 那么成熟。盡管吐槽 node_modules 的人很多,但卻不得不承認,Node.js 的 CMD 機制對于我們來說不僅易于學習,同時每個模塊的職責和邊界也是非常清晰的。
具體來說,一個 Node.js 模塊,它只需關心它自己依賴的模塊是什么、在哪里,而不關心自己是如何被別人依賴的。這一點,可以從 require 調用看出:
- const util = require('./util');
- const http = require('http');
- module.exports = {};
這是一個非常簡單的模塊,它依賴兩個其他模塊,其中 util 來自我們本地的目錄,而 http 則來自于 Node.js 內置。在這種情形下,只要你有良好的模塊依賴關系,一個自己寫好的模塊想要給別人復用,只需要把整個目錄獨立上傳到 npm 上即可。
簡單來說, Node.js 的模塊體系是一棵樹,最終本地模塊就是這樣:
- |- src
- |- module-a
- |- submodule-aa
- |- submodule-ab
- |- module-b
- |- module-c
- |- submodule-ca
- |- subsubmodule-caa
- |- bin
- |- docs
但 Go 語言就不同了。在 Go 語言中,每個模塊不僅有一個短的模塊名,同時還有一個項目中的“唯一路徑”。如果你需要引用一個模塊,那么你需要使用這個“唯一路徑”來進行引用。比如:
- package main
- import (
- "fmt"
- "github.com/valyala/fasthttp"
- "path/to/another/local/module"
- )
***個依賴的 fmt 是 Go 自帶的模塊,簡單明了。第二個模塊是一個位于 Github 的開源第三方模塊,看路徑形式就能夠大致推斷出來它是第三方的。而第三個,則是我們項目中一個可復用模塊,這就有點不太合適了。其實如果 Go 支持嵌套的模塊關系的話,相當于每個依賴從根目錄算起就可以了,能夠避免出現(xiàn) ../../../../root/something 這種尷尬的向上查找。但是, Go 是不支持本地依賴之間的文件夾嵌套的。這樣一來,所有的本地模塊,都會平鋪在同一個目錄里,最終會變成這樣:
- |- src
- |- module-a
- |- submodule-aa
- |- submodule-ab
- |- module-b
- |- module-c
- |- submodule-ca
- |- subsubmodule-caa
- |- bin
- |- docs
現(xiàn)在你不太可能直接把某個模塊按目錄拆出去了,因為它們之間的關系完全無法靠目錄來斷定了。
較新版本的 Go 推薦將第三方模塊放在 vendor 目錄下,和 src 是平級關系。而之前,這些第三方依賴也是放在 src 下面,非常令人困惑。
目前我們項目的代碼規(guī)模還不算很大,可以通過命名來進行區(qū)分,但當項目繼續(xù)增長下去,就需要更好的方案了。
過于簡單的去中心化第三方包管理
和有 npm 的 Node.js 另一個不一樣是: Go 語言沒有自己的包管理平臺。對于 Go 的工具鏈來說,它并不關心你的第三方包到底是誰來托管的。 社區(qū)里 Go 的第三方包遍布各個 Git 托管平臺,這不僅讓我們在搜索包時花費更多時間,更麻煩的是,我們無法通過在企業(yè)內部搭建一個類似 npm 鏡像的平臺,來降低大家每次下載第三方包的耗時,同時也難以在不依賴外網的情況下,進行包的自由安裝。
Go 有一個命令行工具,專門負責下載第三方包,叫做“ go-get ”。和大家想的不一樣,這個工具沒有版本描述文件。在 Go 的世界里并沒有 package.json 這種文件。這給我們帶來的直接影響就是我們的依賴不僅在外網放著,同時還無法有效地約束版本。同一個go-get命令,這個月下載的版本,可能到下個月就已經悄悄地變了。
目前 Go 社區(qū)有很多種不同的第三方工具來做,我們最終選擇了 glide 。這是我們能找到的最接近 npm 的工具了。目前官方也在孕育一個新的方案來進行統(tǒng)一,我們拭目以待吧。
Go 社區(qū)的各種第三方包管理工具
對于鏡像,目前也沒有太好的方案,我們參考了 moby (就是 docker )的做法,將第三方包直接存入我們自己項目的 Git 。這樣雖然項目的源代碼尺寸變得更大了,但無論是新人參與項目,還是上線發(fā)版,都不需要去外網拉取依賴了。
匱乏的內部基礎設施支持
Go 語言在美團內部的應用較少,直接結果就是,美團內部相當一部分基礎設施,是缺少 Go 語言 SDK 支持的。例如公司自建的 Redis Cluster ,由于根據公司業(yè)務需求進行了一些改動,導致開源的 Redis Cluster SDK ,是無法直接使用的。再例如公司使用了淘寶開源出 KV 數據庫—— Tair ,大概由于開源較早,也是沒有 Go 的 SDK 的。
由于我們的架構設計中,需要依賴 KV 數據庫進行存儲,最終我們還是選擇用 Go 語言實現(xiàn)了 Tair 的 SDK。所謂“工欲善其事,必先利其器”,在 SDK 的編寫過程中,我們逐漸熟悉了 Go 的一些編程范式,這對之后我們系統(tǒng)的實現(xiàn),起到了非常有益的作用。所以有時候手頭可用的設施少,并不一定是壞事,但也不能盲目去制造輪子,而是要思考自己造輪子的意義是什么,以結果來評判。
語言之外
要經受生產環(huán)境的考驗,只靠更換語言是不夠的。對于我們來說,語言其實只是一個工具,它幫我們解決的是一個局部問題,而增量更新服務有很多語言之外的考量。
如何面對海量突發(fā)流量
因為有前車之鑒,我們很清楚自己面對的流量是什么級別的。因此這一次從系統(tǒng)的架構設計上,就優(yōu)先考慮了如何面對突發(fā)的海量流量。
首先我們來聊聊為什么我們會有突發(fā)流量。
對于前端來說,網頁每次更新發(fā)版,其實就是發(fā)布了新的靜態(tài)資源,和與之對應的 HTML 文件。而對于增量更新服務來說,新的靜態(tài)資源也就意味著需要進行新的計算。
有經驗的前端同學可能會說,雖然新版上線會創(chuàng)造新的計算,但只要前面放一層 CDN ,緩存住計算結果,就可以輕松緩解壓力了不是嗎?
這是有一定道理的,但并不是這么簡單。面向普通消費者的 C 端產品,有一個特點,那就是用戶的訪問頻度千差萬別。具體到增量更新上來說,就是會出現(xiàn)大量不同的增量請求。因此我們做了更多的設計,來緩解這種情況。
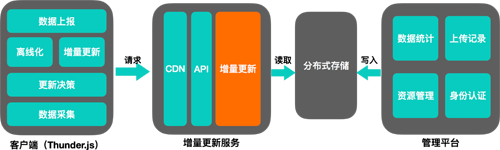
增量服務架構設計
這是我們對增量更新系統(tǒng)的設計。
放在首位的自然是 CDN 。面對海量請求,除了幫助我們削峰之外,也可以幫助不同地域的用戶更快地獲取資源。
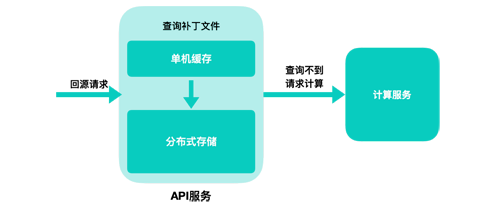
增量服務 API 層
在 CDN 之后,我們將增量更新系統(tǒng)劃分成了兩個獨立的層,稱作 API 層和計算層。為什么要劃分開呢?在過往的實踐當中,我們發(fā)現(xiàn)即使我們再小心再謹慎,仍然還是會有犯錯誤的時候,這就需要我們在部署和上線上足夠靈活;另一方面,對于海量的計算任務,如果實在扛不住,我們需要保有最基本的響應能力。基于這樣的考慮,我們把 CDN 的回源服務獨立成一個服務。這層服務有三個作用:
- 通過對存儲系統(tǒng)的訪問,如果有已經計算好的增量補丁,那么可以直接返回,只把最需要計算的任務傳遞給計算層。
- 如果計算層出現(xiàn)問題,API 層保有響應能力,能夠進行服務降級,返回全量文件內容。
- 將對外的接口管理起來,避免接口變更對核心服務的影響。在這個基礎上可以進行一些簡單的聚合服務,提供諸如請求合并之類的服務。
那如果 API 層沒能將流量攔截下來,進一步傳遞到了計算層呢?

增量服務計算層
為了防止過量的計算請求進入到計算環(huán)節(jié),我們還針對性地進行了流量控制。通過壓測,我們找到了單機計算量的瓶頸,然后將這個限制配置到了系統(tǒng)中。一旦計算量逼近這個數字,系統(tǒng)就會對超量的計算請求進行降級,不再進行增量計算,直接返回全量文件。
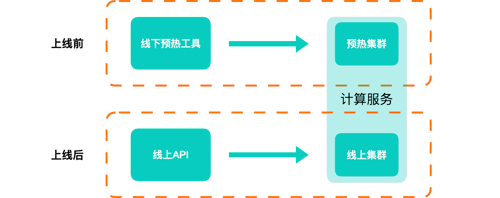
預熱的設計
另一方面,我們也有相應的線下預熱機制。我們?yōu)闃I(yè)務方提供了一個預熱工具,業(yè)務方在上線前調用我們的預熱工具,就可以在上線前預先得到增量補丁并將其緩存起來。我們的預熱集群和線上計算集群是分離的,只共享分布式存儲,因此雙方在實際應用中互不影響。
如何容災
- 有關容災,我們總結了以往見到的一些常見故障,分了四個門類來處理。
- 線路故障。我們在每一層服務中都內置了單機緩存,這個緩存的作用一方面是可以泄洪,另一方面,如果線路出現(xiàn)故障,單機緩存也能在一定程度上降低對線路的依賴。
- 存儲故障。對于存儲,我們直接采用了兩種公司內非常成熟的分布式存儲系統(tǒng),它們互為備份。
CDN 故障。做前端的同學或多或少都遇到過 CDN 出故障的時候,我們也不例外。因此我們準備了兩個不同的 CDN ,有效隔離了來自 CDN 故障的風險。
***,在這套服務之外,我們?yōu)g覽器端的 SDK 也有自己的容災機制。我們在增量更新系統(tǒng)之外,單獨部署了一套 CDN ,這套 CDN 只存儲全量文件。一旦增量更新系統(tǒng)無法工作, SDK 就會去這套 CDN 上拉取全量文件,保障前端的可用性。
回顧與總結
服務上線運轉一段時間后,我們總結了新實踐所帶來的效果:

考慮到每個業(yè)務實際的靜態(tài)文件總量不同,在這份數據里我們刻意包含了總量和人均節(jié)省流量兩個不同的值。在實際業(yè)務當中,業(yè)務方自己也會將靜態(tài)文件根據頁面進行拆分(例如通過 webpack 中的 chunk 來分),每次更新實際不會需要全部更新。
由于一些邊界情況,增量計算的成功率受到了影響,但隨著問題的一一修正,未來增量計算的成功率會越來越高。
現(xiàn)在來回顧一下,在我們的新實踐中,都有哪些大家可以真正借鑒的點:
- 不同的語言和工具有不同的用武之地,不要試圖用錘子去鋸木頭。該換語言就換,不要想著一個語言或工具解決一切。
- 更換語言是一個重要的決定,在決定之前首先需要思考是否應當這么做。
- 語言解決更多的是局部問題,架構解決更多的是系統(tǒng)問題。換了語言也不代表就萬事大吉了。
- 構建一個系統(tǒng)時,首先思考它是如何垮的。想清楚你的系統(tǒng)潛在瓶頸會出現(xiàn)在哪,如何加強它,如何考慮它的備用方案。
對于 Go 語言,我們也是摸著石頭過河,希望我們這點經驗能夠對大家有所幫助。
***,如果大家對我們所做的事情也有興趣,想要和我們一起共建大前端團隊的話,歡迎發(fā)送簡歷至 liuyanghe02@meituan.com 。
作者簡介
洋河,2013年加入攜程UED實習,參與研發(fā)了人生中***個星數超過100的 Github 開源項目。2014年加入小米云平臺,同時負責網頁前端開發(fā)、客戶端開發(fā)及路由器固件開發(fā),積累了豐富的端開發(fā)經驗。2017年加入美團,現(xiàn)負責金服平臺基礎組件的開發(fā)工作。
【本文為51CTO專欄機構“美團點評技術團隊”的原創(chuàng)稿件,轉載請通過微信公眾號聯(lián)系機構獲取授權】