













從MySQL到HBase:數(shù)據(jù)存儲(chǔ)方案轉(zhuǎn)型演進(jìn)
本文大致會(huì)從以下幾個(gè)方面入手,談?wù)劰P者對(duì)數(shù)據(jù)存儲(chǔ)方案選型的看法:
- 從MySQL到HBase集群化方案的演化
- MySQL與HBase的性能取舍
- 不同方案的優(yōu)化思路
- 總結(jié)
一、集群化方案
1、MySQL應(yīng)用的演化
MySQL與HBase說(shuō)到最核心的點(diǎn),是一種數(shù)據(jù)存儲(chǔ)方案。方案本身沒(méi)有對(duì)錯(cuò)、沒(méi)有好壞,只有合適與否。相信多數(shù)公司都與MySQL有著不解之緣,部分學(xué)校的課程甚至直接以SQL語(yǔ)言作為數(shù)據(jù)庫(kù)講解。我想借自身經(jīng)歷,先來(lái)談?wù)凪ySQL應(yīng)用的演化。

只有MySQL
筆者之前曾在一家O2O創(chuàng)業(yè)公司工作,公司所有數(shù)據(jù)都存儲(chǔ)在同一個(gè)MySQL里,而且沒(méi)有任何主備方案。相信這是很多初創(chuàng)公司會(huì)用到的一個(gè)典型解決辦法,當(dāng)時(shí)這臺(tái)MySQL為用戶、訂單、物流服務(wù),同時(shí)也為線下分析服務(wù)。
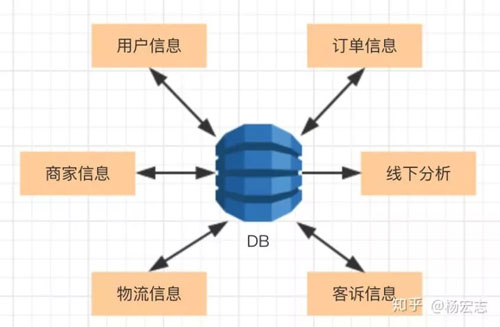
單實(shí)例的問(wèn)題:
- 一旦MySQL掛了,服務(wù)全部停止;
- 一旦MySQL的磁盤(pán)壞了,公司的所有服務(wù)都沒(méi)有了 (一般會(huì)定時(shí)備份數(shù)據(jù)文件)。
主從方案
隨著業(yè)務(wù)增加,單個(gè)DB是無(wú)法承載這么多請(qǐng)求的。于是就有了主從復(fù)制、讀寫(xiě)分離的解決方案。
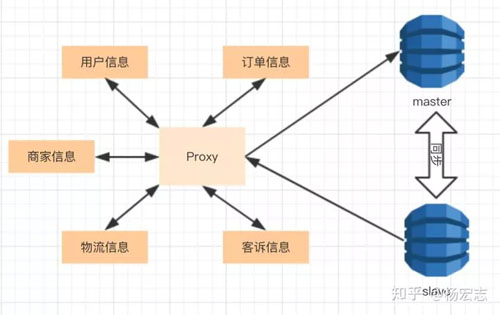
master只負(fù)責(zé)寫(xiě)請(qǐng),slave同步master用來(lái)服務(wù)讀請(qǐng)求:
- 為了擴(kuò)展讀能力可以增加多個(gè)slave;
- 允許slave同步有一定的延遲;
- 一致性要求嚴(yán)格的,可以指定讀主庫(kù)。
主從功能的問(wèn)題:
- 需要增加管理Proxy層,分配寫(xiě)請(qǐng)求、讀請(qǐng)求;
- 節(jié)點(diǎn)故障:其它節(jié)點(diǎn)應(yīng)該快速接管故障節(jié)點(diǎn)的功能。
垂直拆分
業(yè)務(wù)繼續(xù)增長(zhǎng),master甚至無(wú)法承載所有的寫(xiě)請(qǐng)求,數(shù)據(jù)庫(kù)需要按業(yè)務(wù)拆分。
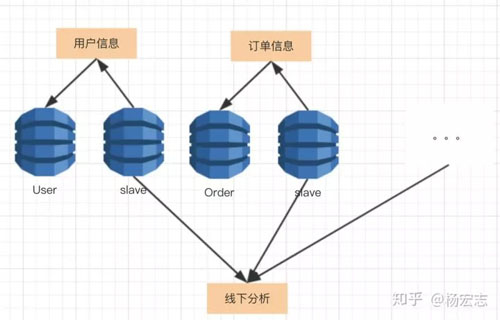
垂直拆分的問(wèn)題:
- 線下分析,需要在業(yè)務(wù)代碼里join各個(gè)表。因?yàn)椴鸪啥鄠€(gè)庫(kù),已經(jīng)無(wú)法join了。
- 不容易做數(shù)據(jù)庫(kù)的事務(wù)性,用戶余額減少與下單成功的情況下無(wú)法使用MySQL的事務(wù)功能。
水平拆分
業(yè)務(wù)繼續(xù)增長(zhǎng),訂單表有大量的并發(fā)寫(xiě)入,而且已經(jīng)有了幾千萬(wàn)行數(shù)據(jù)。
- 單個(gè)庫(kù)無(wú)法承載大量的并發(fā)寫(xiě)入;
- 上千萬(wàn)行的大表,數(shù)據(jù)寫(xiě)入可能需要調(diào)整一棵巨大的B+樹(shù);
- 上千萬(wàn)行,B+樹(shù)過(guò)深,讀寫(xiě)需要更多的磁盤(pán)IO;
- 很多老數(shù)據(jù)訪問(wèn)較少,B+樹(shù)上層緩存的部分信息無(wú)用;
- ……
參考:大眾點(diǎn)評(píng)訂單系統(tǒng)分庫(kù)分表實(shí)踐
https://zhuanlan.zhihu.com/p/24036067
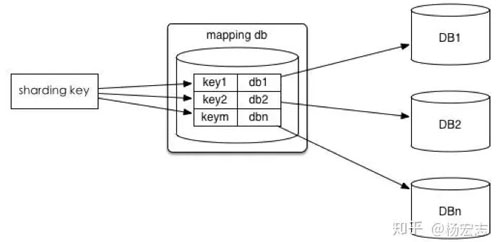
水平分庫(kù)/分表帶來(lái)的問(wèn)題:
- 維護(hù)map方案;
- 輔助索引只能局部有效;
- 由于分庫(kù),無(wú)法使用join等函數(shù);由于分表count、order、group等聚合函數(shù)也無(wú)法做了;
- 擴(kuò)容:需要再次水平拆分的:修改map,遷移數(shù)據(jù)……
2、MySQL的問(wèn)題
MySQL的主要瓶頸,單機(jī)單進(jìn)程。CPU有限、內(nèi)存/磁盤(pán)功能、連接數(shù)有限、網(wǎng)卡吞吐有限……
- 集群的限制點(diǎn):
- 關(guān)系型數(shù)據(jù)庫(kù),縱向的外鍵相互join;
- 范式參考鏈接:https://zhuanlan.zhihu.com/p/20028672
- 數(shù)據(jù)庫(kù)事務(wù)性,基于單機(jī)的鎖機(jī)制,無(wú)法擴(kuò)展到集群中使用;
- 全局有序列性基于B+樹(shù),數(shù)據(jù)有序聚合存儲(chǔ),集群化后無(wú)法保證;
- 數(shù)據(jù)本地存儲(chǔ),擴(kuò)容需要遷移數(shù)據(jù)。
集群的方案:
- 放棄部分功能,輔助索引檢索、join、全局事務(wù)性、聚合函數(shù)等;
- 水平拆分:存儲(chǔ)KV化,用機(jī)械的map思路實(shí)現(xiàn)集群;
- 擴(kuò)容方案:手動(dòng)導(dǎo)數(shù)據(jù),開(kāi)發(fā)數(shù)據(jù)遷移腳本;
- 事務(wù)性:兩階段事務(wù)、paxos、單庫(kù)事務(wù)……
- 備份容災(zāi):從節(jié)點(diǎn)同步主節(jié)點(diǎn),但有一定的數(shù)據(jù)延遲;
- 服務(wù)穩(wěn)定性:主節(jié)點(diǎn)掛了,Proxy會(huì)將從節(jié)點(diǎn)升級(jí)為主節(jié)點(diǎn);從節(jié)點(diǎn)掛了會(huì)被其它從節(jié)點(diǎn)替換。
3、HBase集群化解決方案
水平拆分:
- region:拆分后的子表;
- Region Server:管理這些數(shù)據(jù)的server,相當(dāng)于一個(gè)MySQL實(shí)例;
- .META.表存儲(chǔ)拆分信息map<row, server>。
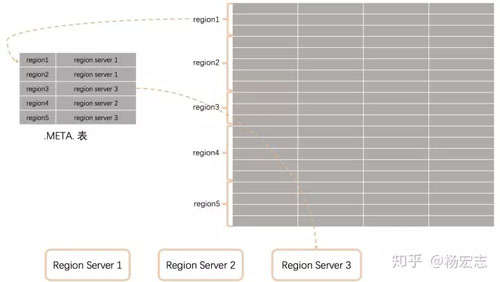
單個(gè)region過(guò)大,RegionServer會(huì)將region均分為兩個(gè)(自動(dòng)、手工)。然后更新.META.表。
擴(kuò)容方案:
RegionServer向HMaster匯報(bào)狀態(tài)。HMaster為RegionServer負(fù)載均衡,調(diào)整其負(fù)責(zé)的region 。
增/刪RegionServer后,會(huì)為重新調(diào)整region的分配方式。
服務(wù)穩(wěn)定性:
RegionServer只是計(jì)算單元,掛掉后Hmaster可以隨便再找一個(gè)節(jié)點(diǎn)代替壞節(jié)點(diǎn)服務(wù)。
事務(wù)性:
HBase只保證行級(jí)事務(wù),單行數(shù)據(jù)肯定存在同一臺(tái)機(jī)器(單機(jī)事務(wù)很好做)。
備份容災(zāi):
- 數(shù)據(jù)使用HDFS存儲(chǔ),多復(fù)本,任何一個(gè)復(fù)本掛掉都不影響功能;
- RegionServer只是計(jì)算單元,掛掉后不影響服務(wù)。
二、性能取舍
1、數(shù)據(jù)請(qǐng)求流程
HBase:
- Client會(huì)通過(guò)Zookeeper定位到 .META. 表;
- 根據(jù) .META. 查找需要服務(wù)的RegionServer,連接RegionServer進(jìn)行讀寫(xiě);
- Client會(huì)緩存 .META. 表信息,下次可以直接連到RegionServer 。
MySQL:
- Client通過(guò)Proxy,查找需要連接的MySQL實(shí)例,連接并進(jìn)行讀寫(xiě)。
Rquest的路由流程,MySQL與HBase基本一致,那么RegionServer與MySQL的性能差異如何呢?
2、Hbase寫(xiě)得快
新增
為什么MySQL建議自增主鍵?(MySQL隨機(jī)插入的代價(jià))
- 主鍵索引是有序的B+樹(shù)結(jié)構(gòu),新增條目的ID肯定是***的,新增給B+結(jié)構(gòu)帶來(lái)的調(diào)整最小;
- 主鍵索引是聚簇的:新增條目,ID是***的。其data追加在上一次插入的后面,磁盤(pán)更容易順序?qū)憽?/li>
輔助索引,插入基本是隨機(jī)的:
- 插入條目,可能會(huì)引起B(yǎng)+樹(shù)結(jié)構(gòu)很大的調(diào)整。
HBase可以隨機(jī)插入:
- HBase的所有插入只是寫(xiě)入內(nèi)存memstore,只保證內(nèi)存數(shù)據(jù)的有序即可(很快、很容易);
- 為防止數(shù)據(jù)丟失寫(xiě)入memstore前,先寫(xiě)入wal(可以關(guān)閉,速度更快);
- HBase沒(méi)有輔助索引需要維護(hù);
- memstore寫(xiě)滿了,申請(qǐng)一塊新的內(nèi)存,舊的memstore被后臺(tái)線程刷盤(pán),存入HFile。
修改
MySQL數(shù)據(jù)變化引起存儲(chǔ)變動(dòng):
- 數(shù)據(jù)塊大小變化:磁盤(pán)空間不足,可能需要調(diào)整磁盤(pán)存儲(chǔ)結(jié)構(gòu),引起大量的磁盤(pán)隨機(jī)讀寫(xiě);
- 輔助索引發(fā)生變化:可能需要重新調(diào)整輔助索引B+樹(shù)。
HBase直接將變化寫(xiě)入到memstore,沒(méi)有其它開(kāi)銷。
刪除
MySQL數(shù)據(jù)刪除:
- 直接操作B+樹(shù)的節(jié)點(diǎn),肯定需要刷新磁盤(pán);
- 如果引起樹(shù)結(jié)構(gòu)變化,甚至可能需要多次刷新磁盤(pán)。
HBase只是在memstore記錄刪除標(biāo)記,沒(méi)有其它開(kāi)銷。
3、結(jié)論
HBase寫(xiě)入內(nèi)存+后臺(tái)刷盤(pán)(最多是WAL,磁盤(pán)順序?qū)懀籑ySQL需要維護(hù)B+樹(shù),大量的磁盤(pán)隨機(jī)讀寫(xiě)。
MySQL要求盡量追加寫(xiě)(自增 ID),速度較慢;HBase可以隨機(jī)插入,速度很快。
MySQL讀得快
MySQL數(shù)據(jù)是本地存儲(chǔ)的,HBase是基于HDFS,有可能數(shù)據(jù)不在本地。
B+ 樹(shù)天然的全局有序
- 根據(jù)主鍵查詢,可以快速定位到數(shù)據(jù)所在磁盤(pán)塊,只需要極少的磁盤(pán)IO即可拿到數(shù)據(jù):通過(guò)緩存高層節(jié)點(diǎn),主健查詢只需要一次磁盤(pán)IO就可拿到數(shù)據(jù);MySQL單表行數(shù)一般建議不會(huì)超過(guò)2千萬(wàn),千萬(wàn)行以下的大表,B+樹(shù)只需2~3層即可;
- 輔助索引,提供快速定位能力:輔助索引B+樹(shù),可以快速定位到最終所需的主鍵ID,根據(jù)主鍵ID可以快速拿到所需信息。
HBase只有局部信息,沒(méi)有輔助索引
- 查詢會(huì)優(yōu)先查找memstore,如果沒(méi)有會(huì)查找Hfile(存儲(chǔ)結(jié)構(gòu)類似B+樹(shù))。如果***個(gè)Hfile中沒(méi)有所需的信息,則需要去第二、第三個(gè)Hfile中查詢;如果查詢的數(shù)據(jù)恰好在memstore,***個(gè)Hfile,HBase會(huì)優(yōu)于MySQL;平均下來(lái),HBase讀性能一般。減少Hfile數(shù)據(jù)以提速,小的HFile合并成大的HFile文件。這種存儲(chǔ)結(jié)構(gòu)叫LSM樹(shù)(Log-structured merge-tree);
- 如果需要檢索特定的列,可能需要遍歷所有Hfile,成本巨高。
MySQL成也B+,敗也B+;HBase成也LSM,敗也LSM。
4、附錄
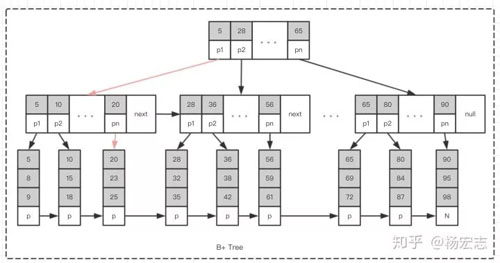
B+ 樹(shù)
查詢“值為25”的節(jié)點(diǎn),只需要2次定位即可。
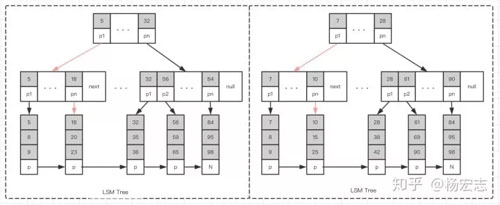
LSM樹(shù)
查詢“值為25”的節(jié)點(diǎn),只需要4次定位即可。
三、優(yōu)化思路
1、HBase優(yōu)化點(diǎn) (主要是讀)
異步化
- 后臺(tái)線程將memstore寫(xiě)入Hfile;
- 后臺(tái)線程完成Hfile合并;
- wal異步寫(xiě)入(數(shù)據(jù)有丟失的風(fēng)險(xiǎn))。
數(shù)據(jù)就近
- blockcache,緩存常用數(shù)據(jù)塊:讀請(qǐng)求先到memstore中查數(shù)據(jù),查不到就到blockcache中查,再查不到就會(huì)到磁盤(pán)上讀,把最近讀的信息放入blockcache,基于LRU淘汰,可以減少磁盤(pán)讀寫(xiě),提高性能;
- 本地化,如果Region Server恰好是HDFS的data node,Hfile會(huì)將其中一個(gè)副本放在本地;
- 就近原則,如果數(shù)據(jù)沒(méi)在本地,Region Server會(huì)取最近的data node中數(shù)據(jù)。
快速檢索
基于bloomfilter過(guò)濾:
- 正常檢索,RegionServer會(huì)遍歷所有Hfile查詢所需數(shù)據(jù)。其中,需要遍歷Hfile的索引塊才能判斷Hfile中是否有所需數(shù)據(jù);
- BloomFiler存儲(chǔ)HFile的摘要,可以通過(guò)極少磁盤(pán)IO,快速判斷當(dāng)前HFile是否有所需數(shù)據(jù):
行緩存:快速判斷Hflie是否有所需要的行,粒度較粗,存儲(chǔ)占用少,磁盤(pán)IO少,數(shù)據(jù)較快;
列緩存:快速判斷Hfile是否有所需的列,粒度較細(xì),但存儲(chǔ)占用較多。
基于timestamp過(guò)濾:
- HFile基于日志追加、合并,維護(hù)了版本信息;
- 當(dāng)查詢1小時(shí)內(nèi)提交的信息時(shí),可以跳過(guò)只包含1小時(shí)前數(shù)據(jù)的文件。
HFile存儲(chǔ)結(jié)構(gòu):
HFile存儲(chǔ)格式
參考鏈接:
https://link.zhihu.com/?target=https%3A//blog.csdn.net/yangbutao/article/details/8394149
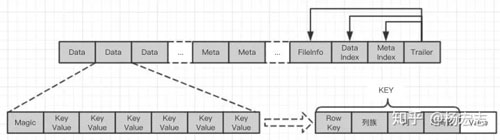
- Trailer存儲(chǔ)整個(gè)Hfile的定位信息;
- DataIndex存儲(chǔ)Data塊的索引信息:Data存儲(chǔ)為一組磁盤(pán)塊,存儲(chǔ)數(shù)據(jù)信息;DataIndex功能類似于B+樹(shù)的非葉子節(jié)點(diǎn);Data每個(gè)磁盤(pán)塊中的數(shù)據(jù)按key有序,加載到內(nèi)存后可以用二分查找定位;Key按行 + 列族 + 列 + 時(shí)間戳生成,按字典序排序(***查詢方式:最左匹配);
- MetaIndex存儲(chǔ)Meta的索引信息,Meta存儲(chǔ)一系列元信息;MetaIndex功能類似于B+樹(shù)的非葉子節(jié)點(diǎn);Meta存儲(chǔ)bloomfiler等輔助信息。
2、MySQL優(yōu)化點(diǎn)(主要是寫(xiě))
查詢緩存
將SQL執(zhí)行結(jié)果放入緩存。
緩存B+高層節(jié)點(diǎn)
一千萬(wàn)行的大表,一般只需要一棵3層的B+樹(shù),其中索引節(jié)點(diǎn) (非葉子節(jié)點(diǎn)) 的大小約20MB。完全可以考慮將大部葉子節(jié)點(diǎn)緩存,基于主鍵查詢只需要一次IO。
減少隨機(jī)寫(xiě)——緩沖:延遲寫(xiě)/批量寫(xiě)
上節(jié)提到,B+樹(shù)通過(guò)自增主鍵大量減少隨機(jī)插入。由于輔助索引的存在,插入、修改、刪除操作,輔助索引可能引起大量的隨機(jī)IO。
插入緩沖:只是將被插入數(shù)據(jù)寫(xiě)入insert buffer;定期將其merge到B+樹(shù);
修改緩沖:類似于insert buffer的思路。
減少隨機(jī)讀——MRR
- SELECT * FROM t WHERE key_part1 >= 1000 AND key_part1 < 2000 AND key_part2 = 10000;
- # 普通操作分解:
- key_part1= 1000, key_part2=1000, id = 1
- select * from t where id=1
- key_part1= 1001, key_part2=1000, id = 10
- select * from t where id=10
- ...
- # MRR 操作分解:
- SELECT * FROM t WHERE key_part1 >= 1000 AND key_part1 < 2000 AND key_part2 = 10000;
- key_part1= 1000, key_part2=1000, id = 1
- buffer.append(1)
- key_part1= 1000, key_part2=1000, id = 10
- buffer.append(10)
- ...
- sort(buffer)
- select * from t where id in (buffer)
索引下推
- MySQL的server處理完索引后,會(huì)將索引其它部分傳給引擎層;
- 引擎層根據(jù)過(guò)濾條件過(guò)濾掉無(wú)用的行,減少數(shù)據(jù)量,進(jìn)而優(yōu)化server的性能。
3、集群化數(shù)據(jù)庫(kù)的輔助索引
InnoDB的輔助索引
- B+樹(shù)全局有序,葉子節(jié)點(diǎn)存儲(chǔ)的是主鍵。基于輔助索引定位主鍵,再用主鍵定位數(shù)據(jù)。MySQL水平切分后,沒(méi)辦法跨庫(kù)維持建立全局有序索引:
- 單實(shí)例維護(hù)索引,喪失了全局有序性;
再做一個(gè)基于新索引分庫(kù)方案,喪失了輔助索引維護(hù)的事務(wù)性。
HBase相同問(wèn)題
- 仿照InnoDB實(shí)現(xiàn)輔助索引,輔助索引可以做成單獨(dú)的key,其value是被索引行的key;
- 可以做到全局信息的維護(hù),但沒(méi)法保證事務(wù)性。
4、HBase異步合并帶來(lái)的好處
- TTL:基于后臺(tái)合并,TTL很容易做;
- 數(shù)據(jù)多版本支持:基于“追加”,HBase天然的可以支持多版本;
- 版本數(shù)量:基于后臺(tái)合并,可以將太舊版本干掉。
四、總結(jié)
不知道BigTable的前輩們是出于什么思路,本人冒昧揣測(cè)一下,多少應(yīng)該是受到SQL數(shù)據(jù)庫(kù)的影響。個(gè)人感覺(jué),這些或許就是一脈相承的演進(jìn),至少用這種思路學(xué)習(xí)不顯突兀。HBase不是憑空而來(lái),也絕對(duì)不是解決所有問(wèn)題的***靈丹。
最直接的存儲(chǔ)思路肯定是“文件”,當(dāng)“文件”不能滿足需求,就有了數(shù)據(jù)的組織方式,進(jìn)而演進(jìn)到關(guān)系數(shù)據(jù)庫(kù)如MySQL。
MySQL以其“單機(jī)”很好地解決了ACID問(wèn)題,但是,性能再好的“單機(jī)”勢(shì)必演變成“單點(diǎn)”瓶頸,進(jìn)而,分布式思路成為必然。
最簡(jiǎn)單的是擴(kuò)展讀,“***”掛slave;進(jìn)而拆分寫(xiě)節(jié)點(diǎn),多點(diǎn)寫(xiě)入:垂直拆庫(kù)、水平拆庫(kù)。一旦選擇分布式,就涉及如何主從一致、如何發(fā)現(xiàn)節(jié)點(diǎn)、如何運(yùn)維、ACID的如何保證等問(wèn)題。
進(jìn)而就是一系列分布式方案,而HBase就是其中一種解決思路——只讀主庫(kù)保證一致,水平拆分、zk等機(jī)制保證自動(dòng)運(yùn)維、單行級(jí)ACID。至于性能方面,由于存儲(chǔ)思路不同,MySQL與HBase分別取舍了不同的讀寫(xiě)性能。繼而,就衍生出了如何針對(duì)性進(jìn)行優(yōu)化。
以這種思路,HBase不是憑空出現(xiàn)。以個(gè)人淺顯的目光所及,沒(méi)有***的架構(gòu),也沒(méi)有絕對(duì)厲害的設(shè)計(jì)。固然SQL類數(shù)據(jù)庫(kù)有其獨(dú)領(lǐng)風(fēng)騷的場(chǎng)景,NoSQL數(shù)據(jù)庫(kù)自然也有縱橫馳騁的疆域,無(wú)論是哪種架構(gòu),都有自己鞭長(zhǎng)莫及的角落。
所以,應(yīng)該說(shuō)任何一種方案都沒(méi)有***,只有合適。而所有的合適都是演變而來(lái),萬(wàn)變不離其宗:更好的解決問(wèn)題。


























