令人激動的語音UI背后那些事
亞馬遜Echo和Echo Dot智能音箱獲得了成功,它已經(jīng)使語音命令(通常稱為語音UI或語音UI)出現(xiàn)在了新技術(shù)產(chǎn)品中。在每一部智能手機(jī)和平板電腦上,大多數(shù)新型汽車上,以及快速增長的音頻產(chǎn)品中,都有這個(gè)功能。最終,大多數(shù)家用電器,音頻和視頻產(chǎn)品,甚至像健身跟蹤器這樣的可穿戴設(shè)備,最終也都會有語音命令功能。
“所需信號(用戶的聲音)與噪聲(任何其他聲音)的比率越好,語音UI系統(tǒng)越更可靠地工作。“
現(xiàn)在,數(shù)以百萬計(jì)的語音UI產(chǎn)品已經(jīng)出現(xiàn),開始看到消費(fèi)者對這些設(shè)備的預(yù)期——以及滿足這些期望的挑戰(zhàn)性。有限的成功以及更原始的語音命令產(chǎn)品表明,除了了解喚醒詞,比如"Alexa"或者"OK Google",消費(fèi)者不愿意適應(yīng)這些產(chǎn)品可能對他們的其他要求,比如按下按鈕叫醒設(shè)備,或直接進(jìn)入遠(yuǎn)程控制。至少在家里,消費(fèi)者期望一個(gè)語音UI產(chǎn)品來響應(yīng)來自房間的指令,如果可能的話,甚至是來自不同房間的指令。無論房間的聲學(xué)特性如何,不管產(chǎn)品放在房間的哪個(gè)位置,都期望可靠的聲音識別,希望語音UI即使在中等噪音的環(huán)境噪聲下也能工作。
雖然先進(jìn)的語音識別系統(tǒng)依賴于基于互聯(lián)網(wǎng)的計(jì)算能力,但語音UI系統(tǒng)的大部分性能取決于系統(tǒng)接收的語音信號質(zhì)量。"garbage in, garbage out",同樣適用于這些系統(tǒng),就像它適用于任何其他技術(shù)一樣。對噪音(任何其他聲音)所需信號(用戶的聲音)的比例越好,語音UI系統(tǒng)就越可靠。
語音UI系統(tǒng)使用多個(gè)麥克風(fēng)接收指令,聲音識別系統(tǒng)的準(zhǔn)確性很大程度上取決于這些陣列是否能夠?qū)W⒂谟脩舻穆曇簦约熬芙^不必要的刺激,如環(huán)境噪聲或設(shè)備本身發(fā)出的聲音。對于優(yōu)化這些陣列和控制算法的大多數(shù)研究都是開發(fā)這些產(chǎn)品的公司密切關(guān)注的,這使得產(chǎn)品開發(fā)者較少。
讓事情變得復(fù)雜的是對麥克風(fēng)陣列設(shè)計(jì)的不熟悉。 雖然無數(shù)的工程師擁有擴(kuò)音器設(shè)計(jì)和應(yīng)用方面的專業(yè)知識,但在麥克風(fēng)上經(jīng)驗(yàn)要少得多——盡管大多數(shù)工程師的耳朵通常能夠?qū)P(yáng)聲器的問題有一個(gè)粗略的概念,但是要評估麥克風(fēng)的性能則要困難得多。 當(dāng)一個(gè)陣列的麥克風(fēng)數(shù)量成倍增加時(shí),挑戰(zhàn)就變得越來越復(fù)雜。 現(xiàn)在,工程師必須確定哪些類型的麥克風(fēng)最適合陣列使用,使用的麥克風(fēng)數(shù)量,以及放置的物理配置。
然后需要一個(gè)處理算法,使麥克陣列能夠識別用戶聲音的方向,并在拒絕其他聲音的同時(shí)專注于這個(gè)聲音。許多這樣的算法都是可用的,但所有的算法都必須優(yōu)化,以適應(yīng)麥克風(fēng)的性能,陣列的大小和配置,以及安裝外殼的聲學(xué)效果。
語音UI中使用的麥克風(fēng)
在語音UI產(chǎn)品中使用的幾乎都是單音麥克風(fēng)。MEMS(Micro Electrical Mechanical Systems)在設(shè)計(jì)語音UI產(chǎn)品的麥克風(fēng)陣列中有許多優(yōu)勢:
小尺寸: MEMS通常每邊不超過5毫米,因此可以在一個(gè)小的產(chǎn)品中安裝多達(dá)7個(gè)麥克風(fēng)。表面安裝設(shè)計(jì)進(jìn)一步減少了他們的痕跡。
低成本: 隨著產(chǎn)品中麥克風(fēng)數(shù)量的增加,成本成為一個(gè)重要的考慮因素。 MEMS集成電路往往是廉價(jià)的,它們也可以與具有PDM (脈沖數(shù)字調(diào)制)端口的處理器直接接口,而不需要昂貴的A/D轉(zhuǎn)換器。
一致性: 麥克風(fēng)陣列的可預(yù)測功能要求陣列中的多個(gè)指標(biāo)匹配良好。由于 MEMS麥克風(fēng)的制造采用了一個(gè)完全自動化的過程,就像用來制造IC一樣,所以單元間的一致性通常是好的。
在語音UI產(chǎn)品中使用的大多數(shù)麥克風(fēng)都是全向的,可以從各個(gè)方向接收聲音。 由于麥克風(fēng)陣列的方向性是通過一種算法而不是通過麥克固有的方向性來構(gòu)建的,所以使用全向麥克可以讓算法在處理各種麥克風(fēng)信號時(shí)在拾取波束的方式上具有完全的靈活性。
全向麥克的另一個(gè)好處是,它們比定向麥克風(fēng)更能滿足頻率響應(yīng)。這種特性降低了算法的處理負(fù)載,因此,在產(chǎn)品組裝中的方向不再是問題。在可用的MEMS 麥克風(fēng)選擇中,麥克風(fēng)陣列設(shè)計(jì)師可以從敏感性、噪聲、頻率響應(yīng)匹配以及數(shù)字和模擬輸出等一系列功能和特性中進(jìn)行選擇。
語音UI算法的組件
語音UI產(chǎn)品中的算法實(shí)際上是幾種算法的集合,每個(gè)算法都有一個(gè)特定的功能,可以幫助麥克風(fēng)陣列專注于用戶的聲音,忽略不需要的聲音。下面是語音UI中通常算法的簡要描述。
觸發(fā)/喚醒詞
語音UI系統(tǒng)使用一個(gè)指定的喚醒詞,如"Alexa"或者"OK Google"——用戶使用這個(gè)單詞來激活語音UI設(shè)備。這個(gè)喚醒詞會有挑戰(zhàn)的,因?yàn)樵O(shè)備必須立即在設(shè)備上使用自己的算法進(jìn)行識別,而使用互聯(lián)網(wǎng)資源會造成太多的延遲。設(shè)備必須在某種程度上保持活躍,因?yàn)樗仨毑粩嗟乇O(jiān)聽喚醒詞。
選擇一個(gè)合適的喚醒詞,對操作語音UI設(shè)備至關(guān)重要。喚醒詞必須足夠復(fù)雜,以便在麥克風(fēng)輸出處產(chǎn)生一個(gè)獨(dú)特的波形,該算法可以很容易地區(qū)分出正常的語音,否則成功識別的百分比可能低得令人無法接受。喚醒詞不能是通常使用的單詞或短語,否則誤喚醒的頻率可能高得令人無法接受。它也不應(yīng)該太長,因?yàn)樵介L的短語,用戶就越有可能認(rèn)為這個(gè)設(shè)備很糟糕。通常,用三到五個(gè)音節(jié)的喚醒詞是***的選擇。
在評估喚醒詞算法的性能時(shí),需要考慮兩個(gè)主要因素。首先,當(dāng)沒有喚醒時(shí),算法多久會指示一個(gè)喚醒? 這被測量為每小時(shí)誤喚醒。其次,算法在背景噪聲的存在下能否正確地檢測到喚醒詞?這是以識別率來衡量的。
大多數(shù)喚醒算法都有不同的尺寸。 小型的算法可以減少內(nèi)存和CPU處理,但會有多一些的錯(cuò)誤; 大型算法需要更多的資源,但是犯錯(cuò)更少。模型也是可調(diào)整的,允許產(chǎn)品設(shè)計(jì)師使他們更嚴(yán)格(更少的誤喚醒但較難喚醒)或者更寬松(更多的誤喚醒但更容易喚醒)。大多數(shù)產(chǎn)品設(shè)計(jì)師選擇更加嚴(yán)格的調(diào)整,因?yàn)楫?dāng)用戶在發(fā)布命令時(shí)往往會接受偶爾重復(fù)自己的話,但他們對誤喚醒卻不那么寬容。
"選擇一個(gè)合適的喚醒詞以納入算法,是喚醒詞識別的關(guān)鍵,從而操作語音UI設(shè)備。"
假喚醒是通過播放數(shù)小時(shí)的口語內(nèi)容并計(jì)算誤喚醒的頻率來衡量的。在這個(gè)測試中,不同的模型大小在性能上的差異變得很明顯。圖1比較了用于不同調(diào)優(yōu)的小型、中型和大型喚醒詞模型的性能。 在這種情況下,每小時(shí)不超過一次的錯(cuò)誤觸發(fā)是一個(gè)合理的目標(biāo)。 這個(gè)小模型只能通過圖左邊兩個(gè)最嚴(yán)格的調(diào)整來實(shí)現(xiàn)這一點(diǎn)。 中型和大型模型在更廣泛的操作范圍內(nèi)實(shí)現(xiàn)這一目標(biāo)。
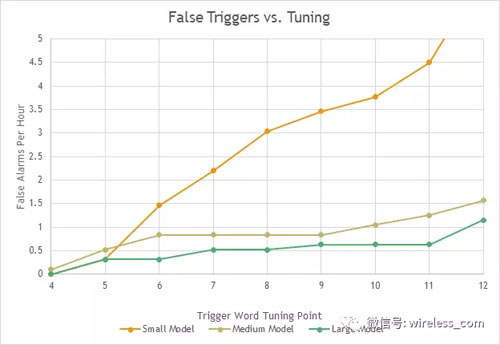
圖1: 用小型、中型和大型算法模型測試每小時(shí)誤喚醒,左邊更嚴(yán)格,右邊更寬松
在測量噪聲喚醒算法的性能時(shí),研究表明,在環(huán)境噪音的存在下,決定喚醒識別率的主要因素是在麥克風(fēng)上測量的信噪比(SNR)。"信號"表示人的聲音對著麥克風(fēng)的聲音有多大,而"噪音"是背景噪音的水平。 在測試中,使用"babble"噪音來模擬家庭中典型的噪音和波形。 圖2顯示了三個(gè)模型大小的圖形,所有模型已經(jīng)調(diào)整到每小時(shí)不到兩個(gè)錯(cuò)誤的誤喚醒。X軸代表 SNR,其較高的信噪比向右。 Y軸是識別的概率。 在大多數(shù)情況下,算法在1或2分貝內(nèi)有相同的性能。
我們應(yīng)該注意到,相對于大多數(shù)音頻播放設(shè)備的SNR為80至120分貝,10分貝左右的信噪比似乎是不可接受的。 然而,在語音UI應(yīng)用程序中,用戶的聲音通常只比周圍噪音大幾分貝,如下圖所示,10到20分貝的 SNR 可以在語音UI應(yīng)用程序中提供的結(jié)果。 因此,盡管在音頻播放系統(tǒng)中同樣的增長在主觀上是不易察覺的,但SNR增加2分貝可以顯著提高語音UI的性能,。
"... SNR 增加2分貝可以顯著提高語音UI的性能,即使同樣的增長在主觀上在音頻播放系統(tǒng)中是不明顯的。"
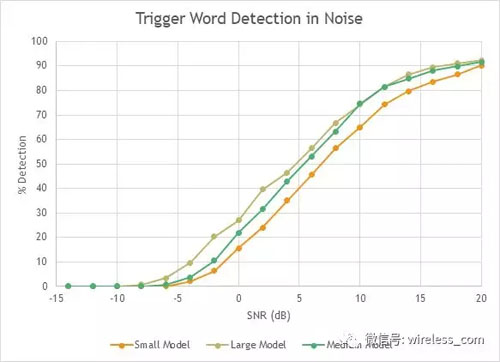
圖2: 觸發(fā)單詞檢測作為 SNR 函數(shù)的性能。 三種不同模式測試,模型越大,性能越好。
DOA 波達(dá)方向
一旦喚醒詞被識別,下一步就是確定用戶聲音的到達(dá)方向。 一旦確定了方向,DOA算法就會告訴beamformer算法把注意力集中在哪個(gè)方向。
DOA算法的核心功能是檢查陣列中不同的麥克風(fēng)發(fā)出信號的相位或時(shí)延關(guān)系,并利用這些信息確定哪一個(gè)麥克風(fēng)首先接收聲音。 然而,這個(gè)任務(wù)比看起來要復(fù)雜得多。 由于房間里的墻壁、地板、天花板和其他物體的反射,用戶的聲音也會從其他方向傳來,而不僅僅是直接從用戶的嘴里傳來。 最初的聲音是所有的 DOA確定所需要的,后來的反射必須被過濾掉。 為此,DOA 算法包括優(yōu)先邏輯,它將較大聲音的初始到達(dá)和較為安靜的反射分開。這個(gè)功能通過電子方式消除了房間內(nèi)的聲音反射,如果仔細(xì)調(diào)整,這個(gè)算法甚至能夠拒絕附近表面的反射,比如在一個(gè)智能音箱的后面有一堵墻。
通過對環(huán)境噪聲水平的自動調(diào)整,增強(qiáng)了 DOA 算法的運(yùn)算效果。該算法測量房間內(nèi)的平均噪音水平,并且只有當(dāng)輸入的信號至少超過環(huán)境噪聲一定的分貝時(shí),才會重新計(jì)算用戶的發(fā)聲位置。 這樣,系統(tǒng)就可以鎖定一個(gè)特定的方向,而不會被相對較低的噪音分散注意力。
測量 DOA 算法的準(zhǔn)確性,需要通過將麥克風(fēng)陣列周圍的8個(gè)揚(yáng)聲器均勻地分布在半徑1米的圓上,以此來測量 DOA 算法的準(zhǔn)確性。 所有8個(gè)揚(yáng)聲器都播放漫反射場背景噪音,而一個(gè)揚(yáng)聲器除了發(fā)出噪音之外還有喚醒詞。聲音水平固定在60 dBa, 測量的麥克風(fēng)和漫反射場噪音的水平是不同的,如圖3所示。
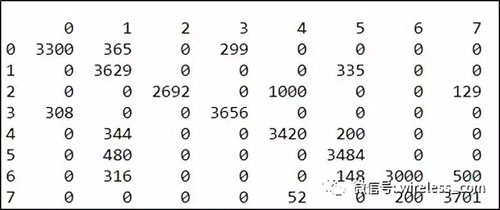
圖3: 矩陣顯示波達(dá)方向測試的結(jié)果。
行索引對應(yīng)聲音來自的實(shí)際方向; 列索引表示 DOA 算法返回的方向。
將矩陣壓縮成一個(gè)數(shù)字,代表算法在特定噪音水平上的整體精確性。 在 DOA 算法中,根據(jù)它們與正確值的距離來權(quán)衡錯(cuò)誤,因此使用的單數(shù)結(jié)果是某個(gè) SNR 的度數(shù)誤差。圖4顯示DOA算法在一個(gè)非常小的平均誤差下運(yùn)行良好。
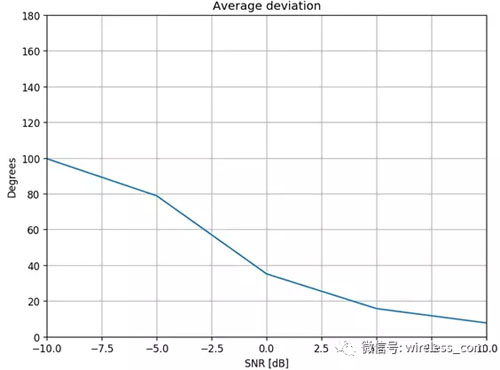
圖4: DOA 綜合結(jié)果。
X軸代表了喚醒詞的信噪比,Y軸是偏差誤差。
DOA算法在大于0 dB的SNR上開始提供有效性能,SNR的精確性能在5dB以上。
AEC 回聲消除
在一個(gè)集成了揚(yáng)聲器或汽車音響系統(tǒng)的語音UI設(shè)備中,干擾語音指令的一種噪音來源是揚(yáng)聲器本身,它可以播放聲音反饋、音樂、收音機(jī)等等。 語音UI設(shè)備必須在麥克錄音時(shí)減去揚(yáng)聲器發(fā)出的聲音。
這看起來可能很簡單,就像將揚(yáng)聲器的反相信號與來自麥克風(fēng)的信號混合,稍加延遲,以彌補(bǔ)聲音從揚(yáng)聲器傳到麥克風(fēng)所需的時(shí)間。 然而,這個(gè)過程僅僅是一個(gè) AEC 算法的起點(diǎn); 它不足以處理現(xiàn)實(shí)世界應(yīng)用程序所帶來的許多復(fù)雜問題。
***個(gè)復(fù)雜因素是,揚(yáng)聲器、用于平衡揚(yáng)聲器的 DSP 和陣列中使用的麥克風(fēng)可能被具體材料改變了波形。 幸運(yùn)的是,可以將麥克的輸入信號與原(dsp)輸入信號進(jìn)行比較,并計(jì)算出修正曲線。
然而,也受到聲波反射的影響。 這些反射可能數(shù)以千計(jì),在一個(gè)大的起居室里,他們可能在發(fā)言者發(fā)出直接聲音后一秒鐘內(nèi)后到達(dá)麥克風(fēng)。根據(jù)房間模式和房間家具的吸收效果,反射譜含量將不同于說話者直接聲音的內(nèi)容。 這些影響在每個(gè)環(huán)境中都會有所不同,而且隨著人們和寵物在房間里走動,或者隨著車內(nèi)乘客數(shù)量的變化而改變。
為了從麥克風(fēng)信號中減去足夠多的聲學(xué)回波以達(dá)到可接受的信噪比,AEC 算法必須在一定誤差范圍內(nèi)尋找與材料相匹配的聲音(以彌補(bǔ)聲學(xué)引起的波形變化) ,并且在一個(gè)定義的時(shí)間窗口上對應(yīng)于預(yù)期的混響時(shí)間。 由于陣列中的麥克風(fēng)之間的距離,每個(gè)麥克風(fēng)接收到一組略微不同的回聲和來自揚(yáng)聲器的不同直接聲音,所以實(shí)現(xiàn)***的信噪比需要對每個(gè)麥克風(fēng)進(jìn)行單獨(dú)的 AEC 處理。
回波消除器的性能通常由其"回波返回?fù)p耗增強(qiáng)"或 ERLE 來定義。 這是增益的減少,回波消除器能夠減少在麥克風(fēng)上的揚(yáng)聲器信號。 回波消除器一般可以取消至少25分貝,具有良好的性能,***的可以取消超過30分貝。
AEC尋找反射的時(shí)間被稱為"回聲尾長" 回波尾長度越長,可以取消的反射越多,算法的性能就越好。 然而,更長的波尾需要更多的內(nèi)存和CPU。圖5顯示了回波返回?fù)p失作為尾長的函數(shù)。 這種測量是在一個(gè)半消聲室中進(jìn)行的。可以看到,大部分都是通過200毫秒的尾長和較長的波尾來實(shí)現(xiàn)的。
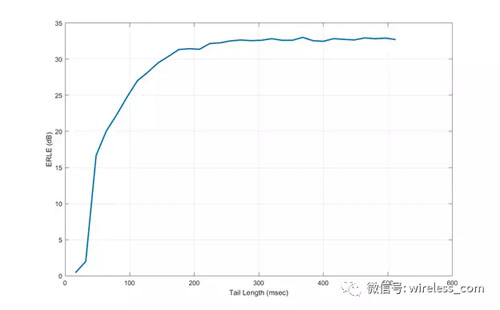
圖5: 回波消除器的性能作為尾長的函數(shù)。
測量是在一個(gè)半回聲的聲音室進(jìn)行,表明200毫秒之后幾乎沒有改善。
半回聲的房間是相當(dāng)容易處理,但不代表真實(shí)世界的使用。 圖6顯示了回波消除器在逐漸增加的混響室中的性能。 現(xiàn)在對于更長聲尾的需求是顯而易見的,***的反射空間可以從更長的回聲尾中受益。
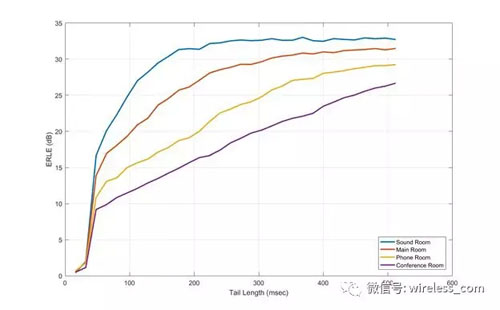
圖5: 4個(gè)房間中的回聲消除測試
當(dāng)揚(yáng)聲器以線性方式執(zhí)行時(shí),AEC 算法的性能更好。 如果揚(yáng)聲器在很大的程度上表現(xiàn)出失真,那么將產(chǎn)生失真諧波,而 AEC 將不會認(rèn)識到這些是原反射,因此不能取消它們。 揚(yáng)聲器的總諧波失真(或 THD)是其線性程度的度量。 THD 占信號水平的百分比越低,說話人的行為就越靈活。 由于 AEC 無法取消,揚(yáng)聲器的失真將出現(xiàn)在 AEC 的輸出中。
例如,如果揚(yáng)聲器有1% 的 THD,那么失真組件將比信號水平低40分貝。 如果回波消除器有30 dB 的 ERLE,那么 THD 為1% 是可以接受的。 現(xiàn)在考慮一下10% 的 THD。 在這種情況下,失真組件是低于信號水平20分貝,這將會淹沒 AEC。 3% 的 THD 將產(chǎn)生30分貝以下的失真,這仍然會影響 AEC。
重要的是要測量整個(gè)系統(tǒng),包括揚(yáng)聲器和麥克風(fēng)。 僅僅測量揚(yáng)聲器的聲學(xué)輸出是不夠的,因?yàn)橛糜谠S多語音UI產(chǎn)品的外殼可以直接從揚(yáng)聲器傳到麥克風(fēng)上。 考慮下一頁圖7所示的圖。 這個(gè)圖表顯示了用外部參考麥克風(fēng)測量揚(yáng)聲器的 THD。 每一行代表一個(gè)不同的播放級別。 對于每一個(gè)回放級別,記錄測量的 SPL 和在整個(gè)音頻頻譜的多個(gè)頻率的 THD。 圖上的圓形氣泡表明,測量的 THD 只出現(xiàn)在 THD 高于3% 的水平。 揚(yáng)聲器的行為是線性的,只有在很大的程度時(shí),才會在較大的扭曲。
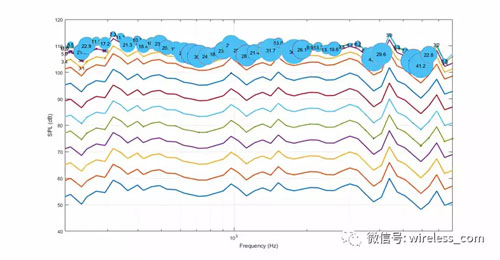
圖7: 利用外置麥克風(fēng)測量揚(yáng)聲器失真情況。 揚(yáng)聲器是線性的,只有在高SPL時(shí)才會扭曲。
這種測量方法現(xiàn)在正在重復(fù)使用機(jī)載語音接收麥克風(fēng),它位于一個(gè)典型的帶有語音UI的"智能揚(yáng)聲器"的外殼頂部。 在這種情況下,如圖8所示,在500至800赫茲的范圍內(nèi),與500至800赫茲的麥克風(fēng)結(jié)合在一起,這是不可接受的; 必須重新設(shè)計(jì),以增加剛度和更好的隔音效果。
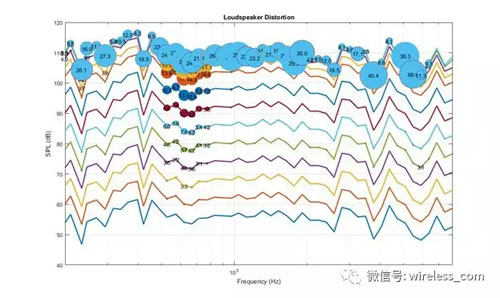
圖8: 用產(chǎn)品本身的麥克風(fēng)測量同一個(gè)揚(yáng)聲器的畸變,聲音會在500至800赫茲之間的失真。
Beamforming 成形
多麥克風(fēng)陣列常用于語音UI系統(tǒng)的原因是,多個(gè)麥克風(fēng)可以使陣列變得方向化ーー專注于來自特定方向的聲音。 這個(gè)過程被稱為成形過程。 它有助于隔離用戶的聲音,同時(shí)拒絕來自其他方向的聲音,提高了 SNR。
例如,如果用戶在麥克風(fēng)陣列的一邊,而另一邊是空調(diào),空調(diào)器的聲音首先到達(dá)用戶對面的麥克風(fēng),然后到達(dá)用戶最近的麥克風(fēng)。 算法使用這些時(shí)差來消除空調(diào)聲音,同時(shí)保留用戶的聲音。
陣列中的麥克風(fēng)越多,有效的波束形成效果就越好。一個(gè)有兩個(gè)麥克風(fēng)的陣列取消聲音的能力有限,但是一個(gè)有多個(gè)麥克風(fēng)的陣列可以抵消來自更多方向的聲音。麥克風(fēng)越少,性能就會隨著視角的變化而變化——用戶的聲音和語音UI產(chǎn)品之間的角度變化而變化。
可以通過動態(tài)調(diào)整其性能優(yōu)化 SNR 以形成波束算法。 可以收緊波束寬度,以便更好地關(guān)注用戶的聲音,更有效地拒絕來自其他方向的聲音,但語音UI系統(tǒng)將需要評估和調(diào)整并確保波束集中在用戶身上。 這種努力增加了對系統(tǒng)的需求,因此大多數(shù)波束維持一個(gè)相當(dāng)寬的光束。 例如,一個(gè)典型的七麥克風(fēng)陣列的波束寬度相對于DOA而言大約為60度。
圖9顯示了波束形成消除背景噪音的能力。 上面顯示了一個(gè)麥克風(fēng)的頻譜。 底部的數(shù)字是一個(gè)7麥克風(fēng)的輸出。 水平條紋是與語音信號相關(guān)的和聲,背景的橙色/紅色是嘈雜的噪音。 理想的結(jié)果將是被黑暗區(qū)域所包圍的條紋。 在前置波束的測量中,語音被保留下來,背景噪聲減少了6到7分貝。這在語音識別方面提供了明顯的改進(jìn)。
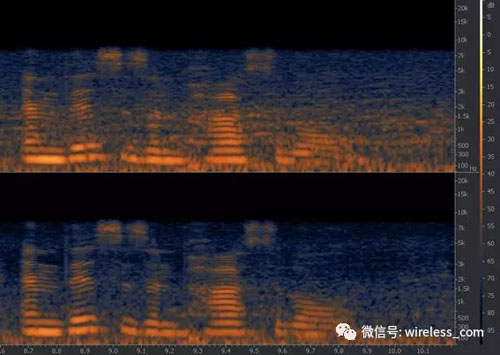
圖9: beamformer的實(shí)現(xiàn)來減少背景噪音, 暗段對應(yīng)于較低的信號水平。
Noise Reduction減噪
雖然麥克風(fēng)陣列系統(tǒng)使用方向拾取模式來過濾掉不想要的聲音(比如噪音) ,但是有些不想要的聲音還可以通過一種算法來減弱或消除,這種算法可以識別它們與所需信號分離的特性,然后去除不需要的聲音。 一個(gè)減噪算法可以運(yùn)行在一個(gè)單一的麥克風(fēng)或一個(gè)陣列,可以幫助喚醒詞識別和提高語音UI性能。 因此,減噪可以用于語音UI信號處理鏈的多個(gè)階段。
聲音命令是暫時(shí)的事件,而不是穩(wěn)定的狀態(tài)。 任何存在的或重復(fù)的聲音,都可以從麥克風(fēng)陣列發(fā)出的信號中被探測到并消除。 例如汽車的道路噪音,以及家庭中的洗碗機(jī)和暖通空調(diào)系統(tǒng)的噪音。 高于或低于人類聲音頻譜的聲音也可以被過濾。
減噪算法已經(jīng)被廣泛使用了很多年,但是大多數(shù)都是針對手機(jī)應(yīng)用而不是語音UI優(yōu)化的。 它們傾向于強(qiáng)調(diào)對人類理解最重要的頻譜,而不是電子頻譜中最關(guān)鍵的聲音分離和理解語音指令的系統(tǒng)。 大多數(shù)用于手機(jī)的降噪算法實(shí)際上降低了語音UI的性能。 簡單地說,人類聽到的東西和語音UI系統(tǒng)不同。
一個(gè)衡量降噪算法工作效果的方法是看看它在回波消除器的輸出中提供了多少額外的dB信號。 圖10顯示了 DSP 在頻域降噪算法的性能,減少了多達(dá)12dB 的殘余回波。
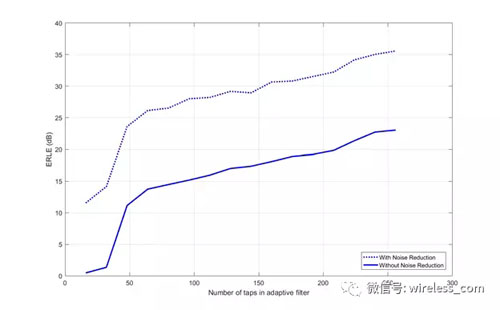
圖10: 減噪算法對 ERL 的影響。 曲線越高,衰減越大,效果越好。
聲音質(zhì)量的主觀提高立即得到了認(rèn)可,但是它能改善語音識別算法的性能嗎? 這需要額外的測量來量化。 圖11重現(xiàn)了圖2中的那些曲線, 與原始內(nèi)容相比,噪聲減小使曲線向左移動了2分貝。 實(shí)驗(yàn)結(jié)果表明,該算法提高了語音識別的整體性能。
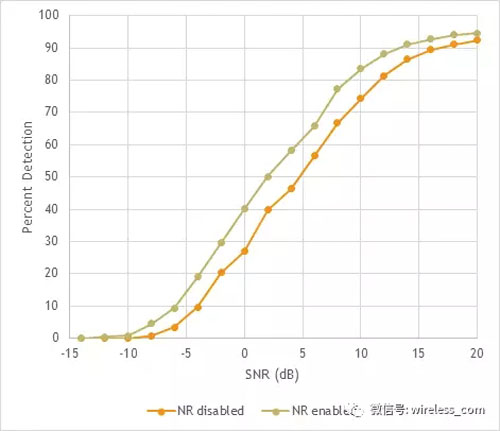
圖11: 減噪算法對 ERL 的影響。 曲線越高,衰減越大,效果越好
這就是對語音UI系統(tǒng)基本原理的理解。 進(jìn)一步,可以研究不同的麥克風(fēng)陣列配置和不同的麥克風(fēng)選擇的影響。 在檢查了這些效果之后,工程師和產(chǎn)品設(shè)計(jì)團(tuán)隊(duì)可以為產(chǎn)品獲得更可靠的性能。
【本文來自51CTO專欄作者“老曹”的原創(chuàng)文章,作者微信公眾號:喔家ArchiSelf,id:wrieless-com】