引言
用最短的時間寫一個最簡單的爬蟲,可以抓一些簡單的論壇、帖子、網頁。
入門
1.準備工作
- 安裝Python
- 安裝scrapy框架
- 一個IDE或者可以用自帶的
2.開始寫爬蟲

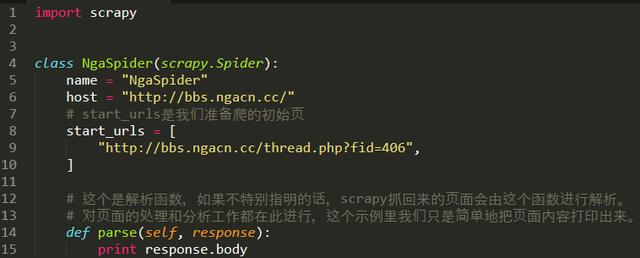
在spiders文件夾中創建一個python文件,比如miao.py,來作為爬蟲的腳本。
代碼如下:
3.運行一下
如果用命令行的話就這樣:


解析
1.試試神奇的xpath

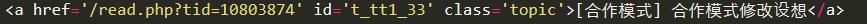

2.看看xpath的效果
在最上面加上引用:
from scrapy import Selector
把parse函數改成:
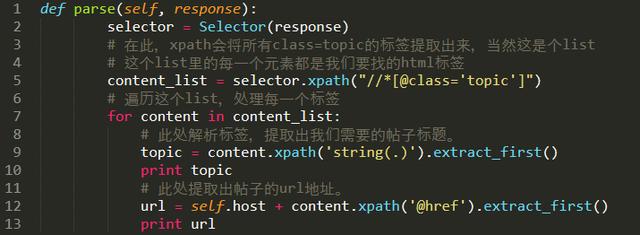
我們再次運行一下,你就可以看到輸出“壇星際區”***頁所有帖子的標題和url了。
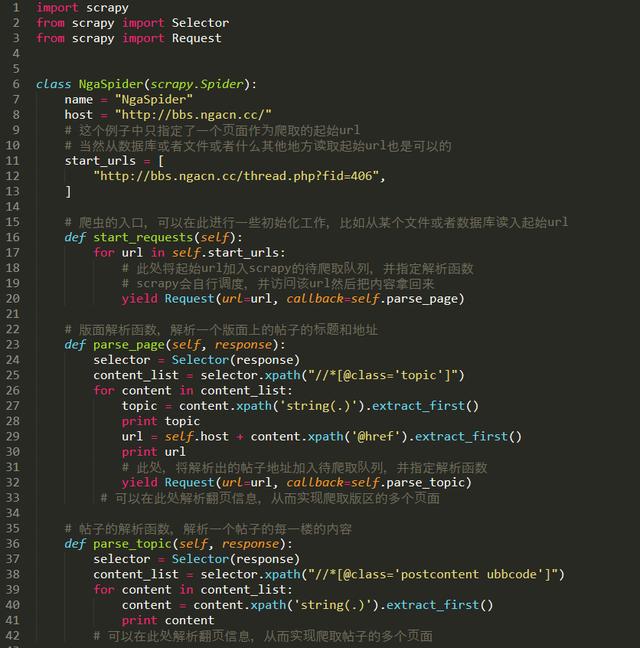
遞歸

完整的代碼如下:

Pipelines——管道
現在是對已抓取、解析后的內容的處理,我們可以通過管道寫入本地文件、數據庫。
1.定義一個Item
在miao文件夾中創建一個items.py文件
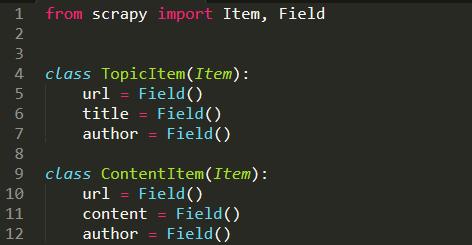
這里我們定義了兩個簡單的class用來描述我們爬取的結果。
2. 處理方法

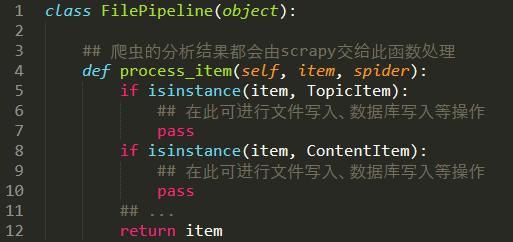
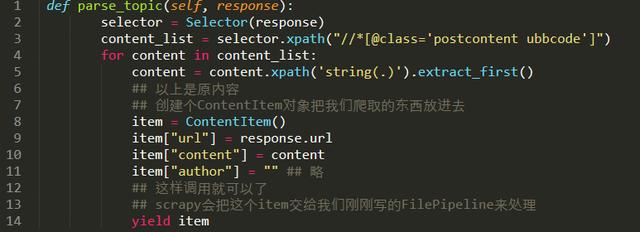
3.在爬蟲中調用這個處理方法。

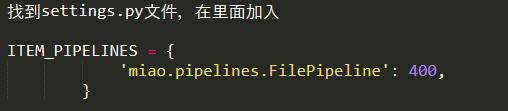
4.在配置文件里指定這個pipeline

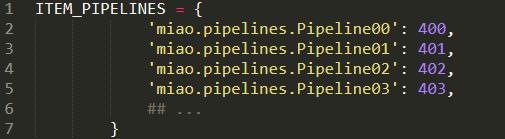
可以這樣配置多個pipeline:
Middleware——中間件

1.Middleware的配置


2.破網站查UA, 我要換UA

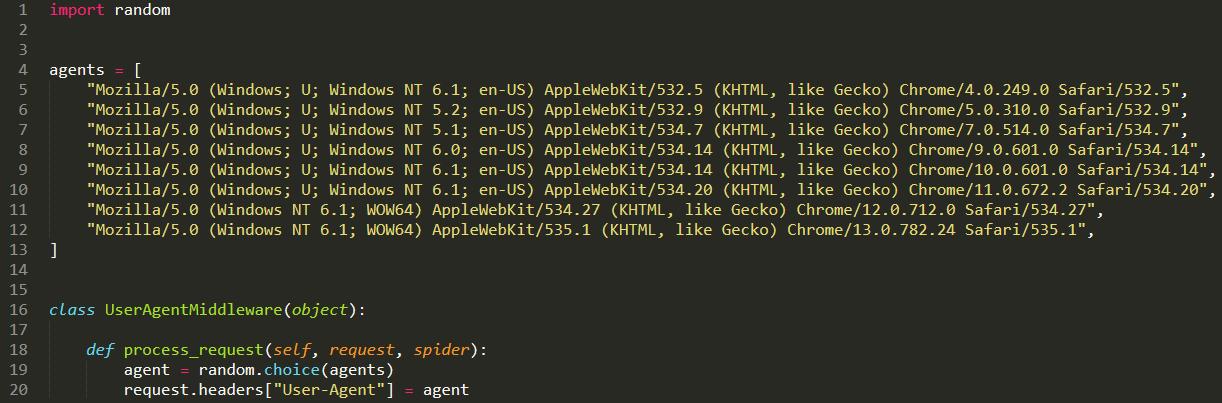
這里就是一個簡單的隨機更換UA的中間件,agents的內容可以自行擴充。
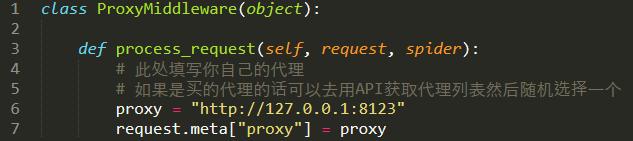
3.破網站封IP,我要用代理