拯救DBA!美團(tuán)SQL解析探索實(shí)踐
數(shù)據(jù)庫(kù)作為核心的基礎(chǔ)組件,是需要重點(diǎn)保護(hù)的對(duì)象。任何一個(gè)線上的不慎操作,都有可能給數(shù)據(jù)庫(kù)帶來(lái)嚴(yán)重的故障,從而給業(yè)務(wù)造成巨大的損失。
為了避免這種損失,一般會(huì)在管理上下功夫。比如為研發(fā)人員制定數(shù)據(jù)庫(kù)開發(fā)規(guī)范;新上線的 SQL,需要 DBA 進(jìn)行審核;維護(hù)操作需要經(jīng)過(guò)領(lǐng)導(dǎo)審批等等。
而且如果希望能夠有效地管理這些措施,需要有效的數(shù)據(jù)庫(kù)培訓(xùn),還需要 DBA 細(xì)心的進(jìn)行 SQL 審核。
很多中小型創(chuàng)業(yè)公司,可以通過(guò)設(shè)定規(guī)范、進(jìn)行培訓(xùn)、完善審核流程來(lái)管理數(shù)據(jù)庫(kù)。
隨著美團(tuán)業(yè)務(wù)的不斷發(fā)展和壯大,上述措施的實(shí)施成本越來(lái)越高。如何更多的依賴技術(shù)手段,來(lái)提高效率,越來(lái)越受到重視。
業(yè)界已有不少基于 MySQL 源碼開發(fā)的 SQL 審核、優(yōu)化建議等工具,極大的減輕了 DBA 的 SQL 審核負(fù)擔(dān)。
那么我們能否繼續(xù)擴(kuò)展 MySQL 的源碼,來(lái)輔助 DBA 和研發(fā)人員來(lái)進(jìn)一步提高效率呢?
比如,更全面的 SQL 優(yōu)化功能;多維度的慢查詢分析;輔助故障分析等。要實(shí)現(xiàn)上述功能,其中最核心的技術(shù)之一就是 SQL 解析。
現(xiàn)狀與場(chǎng)景
SQL 解析是一項(xiàng)復(fù)雜的技術(shù),一般都是由數(shù)據(jù)庫(kù)廠商來(lái)掌握,當(dāng)然也有公司專門提供 SQL 解析的 API。
由于這幾年 MySQL 數(shù)據(jù)庫(kù)中間件的興起,需要支持讀寫分離、分庫(kù)分表等功能,就必須從 SQL 中抽出表名、庫(kù)名以及相關(guān)字段的值。
因此像 Java 語(yǔ)言編寫的 Druid,C 語(yǔ)言編寫的 MaxScale,Go 語(yǔ)言編寫的 Kingshard 等,都會(huì)對(duì) SQL 進(jìn)行部分解析。
而真正把 SQL 解析技術(shù)用于數(shù)據(jù)庫(kù)維護(hù)的產(chǎn)品較少,主要有如下幾個(gè):
- 美團(tuán)點(diǎn)評(píng)開源的 SQLAdvisor。它基于 MySQL 原生態(tài)詞法解析,結(jié)合分析 SQL 中的 where 條件、聚合條件、多表 Join 關(guān)系給出索引優(yōu)化建議。
- 去哪兒開源的 Inception。側(cè)重于根據(jù)內(nèi)置的規(guī)則,對(duì) SQL 進(jìn)行審核。
- 阿里的 Cloud DBA。根據(jù)官方文檔介紹,其也是提供 SQL 優(yōu)化建議和改寫。
上述產(chǎn)品都有非常合適的應(yīng)用場(chǎng)景,在業(yè)界也被廣泛使用。但是 SQL 解析的應(yīng)用場(chǎng)景遠(yuǎn)遠(yuǎn)沒有被充分發(fā)掘,比如:
- 基于表粒度的慢查詢報(bào)表。比如,一個(gè) Schema 中包含了屬于不同業(yè)務(wù)線的數(shù)據(jù)表,那么從業(yè)務(wù)線的角度來(lái)說(shuō),其希望提供表粒度的慢查詢報(bào)表。
生成 SQL 特征。將 SQL 語(yǔ)句中的值替換成問(wèn)號(hào),方便 SQL 歸類。雖然可以使用正則表達(dá)式實(shí)現(xiàn)相同的功能,但是其 Bug 較多,可以參考 pt-query-digest。
- 比如 pt-query-digest 中,會(huì)把遇到的數(shù)字都替換成“?”,導(dǎo)致無(wú)法區(qū)別不同數(shù)字后綴的表。
- 高危操作確認(rèn)與規(guī)避。比如,DBA 不小心 Drop 數(shù)據(jù)表,而此類操作,目前還無(wú)有效的工具進(jìn)行回滾,尤其是大表,其后果將是災(zāi)難性的。
- SQL 合法性判斷。為了安全、審計(jì)、控制等方面的原因,美團(tuán)點(diǎn)評(píng)不會(huì)讓研發(fā)人員直接操作數(shù)據(jù)庫(kù),而是提供 RDS 服務(wù)。
尤其是對(duì)于數(shù)據(jù)變更,需要研發(fā)人員的上級(jí)主管進(jìn)行業(yè)務(wù)上的審批。如果研發(fā)人員,寫了一條語(yǔ)法錯(cuò)誤的 SQL,而 RDS 無(wú)法判斷該 SQL 是否合法,就會(huì)造成不必要的溝通成本。
因此為了讓所有有需要的業(yè)務(wù)都能方便的使用 SQL 解析功能,我們認(rèn)為應(yīng)該具有如下特性:
- 直接暴露 SQL 解析接口,使用盡量簡(jiǎn)單。比如,輸入 SQL,則輸出表名、特征和優(yōu)化建議。
- 接口的使用不依賴于特定的語(yǔ)言,否則維護(hù)和使用的代價(jià)太高。比如,以 HTTP 等方式提供服務(wù)。
千里之行,始于足下,下面我先介紹下 SQL 的解析原理。
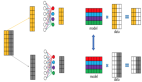
SQL 解析原理
SQL 解析與優(yōu)化屬于編譯器范疇,和 C 等其他語(yǔ)言的解析沒有本質(zhì)的區(qū)別。
其中分為,詞法分析、語(yǔ)法和語(yǔ)義分析、優(yōu)化、執(zhí)行代碼生成。對(duì)應(yīng)到 MySQL 的部分,如下圖:
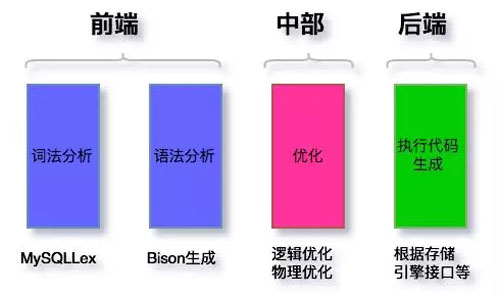
圖 1:SQL 解析原理
詞法分析
SQL 解析由詞法分析和語(yǔ)法/語(yǔ)義分析兩個(gè)部分組成。詞法分析主要是把輸入轉(zhuǎn)化成一個(gè)個(gè) Token。其中 Token 中包含 Keyword(也稱 Symbol)和非 Keyword。
例如,SQL 語(yǔ)句 select username from userinfo,在分析之后,會(huì)得到 4 個(gè) Token。
其中有 2 個(gè) Keyword,分別為 select 和 from:

通常情況下,詞法分析可以使用 Flex 來(lái)生成,但是 MySQL 并未使用該工具,而是手寫了詞法分析部分(據(jù)說(shuō)是為了效率和靈活性,參考此文)。具體代碼在 sql/lex.h 和 sql/sql_lex.cc 文件中。
MySQL 中的 Keyword 定義在 sql/lex.h 中,如下為部分 Keyword:
- { "&&", SYM(AND_AND_SYM)},
- { "<", SYM(LT)},
- { "<=", SYM(LE)},
- { "<>", SYM(NE)},
- { "!=", SYM(NE)},
- { "=", SYM(EQ)},
- { ">", SYM(GT_SYM)},
- { ">=", SYM(GE)},
- { "<<", SYM(SHIFT_LEFT)},
- { ">>", SYM(SHIFT_RIGHT)},
- { "<=>", SYM(EQUAL_SYM)},
- { "ACCESSIBLE", SYM(ACCESSIBLE_SYM)},
- { "ACTION", SYM(ACTION)},
- { "ADD", SYM(ADD)},
- { "AFTER", SYM(AFTER_SYM)},
- { "AGAINST", SYM(AGAINST)},
- { "AGGREGATE", SYM(AGGREGATE_SYM)},
- { "ALL", SYM(ALL)},
詞法分析的核心代碼在 sql/sql_lex.c 文件中的 MySQLLex→lex_one_Token,有興趣的同學(xué)可以下載源碼研究。
語(yǔ)法分析
語(yǔ)法分析就是生成語(yǔ)法樹的過(guò)程。這是整個(gè)解析過(guò)程中最精華,最復(fù)雜的部分,不過(guò)這部分 MySQL 使用了 Bison 來(lái)完成。
即使如此,如何設(shè)計(jì)合適的數(shù)據(jù)結(jié)構(gòu)以及相關(guān)算法,去存儲(chǔ)和遍歷所有的信息,也是值得在這里研究的。
語(yǔ)法分析樹
SQL 語(yǔ)句:
- select username, ismale from userinfo where age > 20 and level > 5 and 1 = 1
會(huì)生成如下語(yǔ)法樹:
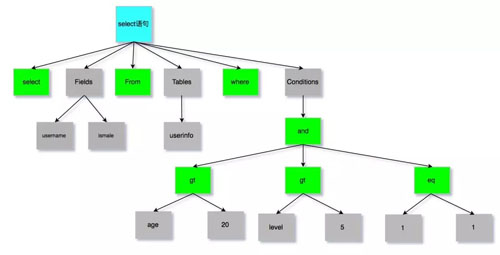
圖 2:語(yǔ)法樹
對(duì)于未接觸過(guò)編譯器實(shí)現(xiàn)的同學(xué),肯定會(huì)好奇如何才能生成這樣的語(yǔ)法樹。其背后的原理都是編譯器的范疇。
本人也是在學(xué)習(xí) MySQL 源碼過(guò)程中,閱讀了部分內(nèi)容。由于編譯器涉及的內(nèi)容過(guò)多,本人經(jīng)歷和時(shí)間有限,不做過(guò)多探究。
從工程的角度來(lái)說(shuō),學(xué)會(huì)如何使用 Bison 去構(gòu)建語(yǔ)法樹,來(lái)解決實(shí)際問(wèn)題,對(duì)我們的工作也許有更大幫助。下面我就以 Bison 為基礎(chǔ),探討該過(guò)程。
MySQL 語(yǔ)法分析樹生成過(guò)程
全部的源碼在 sql/sql_yacc.yy 中,在 MySQL 5.6 中有 17K 行左右代碼。這里列出涉及到的 SQL:
- select username, ismale from userinfo where age > 20 and level > 5 and 1 = 1
解析過(guò)程的部分代碼摘錄出來(lái)。有了 Bison 之后,SQL 解析的難度也沒有想象的那么大,特別是這里給出了解析的脈絡(luò)之后。
- select /*select語(yǔ)句入口*/:
- select_init
- {
- LEX *lex= Lex;
- lex->sql_command= SQLCOM_SELECT;
- }
- ;
- select_init:
- SELECT_SYM /*select 關(guān)鍵字*/ select_init2
- | '(' select_paren ')' union_opt
- ;
- select_init2:
- select_part2
- {
- LEX *lex= Lex;
- SELECT_LEX * sel= lex->current_select;
- if (lex->current_select->set_braces(0))
- {
- my_parse_error(ER(ER_SYNTAX_ERROR));
- MYSQL_YYABORT;
- }
- if (sel->linkage == UNION_TYPE &&
- sel->master_unit()->first_select()->braces)
- {
- my_parse_error(ER(ER_SYNTAX_ERROR));
- MYSQL_YYABORT;
- }
- }
- union_clause
- ;
- select_part2:
- {
- LEX *lex= Lex;
- SELECT_LEX *sel= lex->current_select;
- if (sel->linkage != UNION_TYPE)
- mysql_init_select(lex);
- lex->current_select->parsing_place= SELECT_LIST;
- }
- select_options select_item_list /*解析列名*/
- {
- Select->parsing_place= NO_MATTER;
- }
- select_into select_lock_type
- ;
- select_into:
- opt_order_clause opt_limit_clause {}
- | into
- | select_from /*from 字句*/
- | into select_from
- | select_from into
- ;
- select_from:
- FROM join_table_list /*解析表名*/ where_clause /*where字句*/ group_clause having_clause
- opt_order_clause opt_limit_clause procedure_analyse_clause
- {
- Select->context.table_list=
- Select->context.first_name_resolution_table=
- Select->table_list.first;
- }
- | FROM DUAL_SYM where_clause opt_limit_clause
- /* oracle compatibility: oracle always requires FROM clause,
- and DUAL is system table without fields.
- Is "SELECT 1 FROM DUAL" any better than "SELECT 1" ?
- Hmmm :) */
- ;
- where_clause:
- /* empty */ { Select->where= 0; }
- | WHERE
- {
- Select->parsing_place= IN_WHERE;
- }
- expr /*各種表達(dá)式*/
- {
- SELECT_LEX *select= Select;
- select->where= $3;
- select->parsing_place= NO_MATTER;
- if ($3)
- $3->top_level_item();
- }
- ;
- /* all possible expressions */
- expr:
- | expr and expr %prec AND_SYM
- {
- /* See comments in rule expr: expr or expr */
- Item_cond_and *item1;
- Item_cond_and *item3;
- if (is_cond_and($1))
- {
- item1= (Item_cond_and*) $1;
- if (is_cond_and($3))
- {
- item3= (Item_cond_and*) $3;
- /*
- (X1 AND X2) AND (Y1 AND Y2) ==> AND (X1, X2, Y1, Y2)
- */
- item3->add_at_head(item1->argument_list());
- $$ = $3;
- }
- else
- {
- /*
- (X1 AND X2) AND Y ==> AND (X1, X2, Y)
- */
- item1->add($3);
- $$ = $1;
- }
- }
- else if (is_cond_and($3))
- {
- item3= (Item_cond_and*) $3;
- /*
- X AND (Y1 AND Y2) ==> AND (X, Y1, Y2)
- */
- item3->add_at_head($1);
- $$ = $3;
- }
- else
- {
- /* X AND Y */
- $$ = new (YYTHD->mem_root) Item_cond_and($1, $3);
- if ($$ == NULL)
- MYSQL_YYABORT;
- }
- }
在大家瀏覽上述代碼的過(guò)程,會(huì)發(fā)現(xiàn) Bison 中嵌入了 C++ 的代碼。通過(guò) C++ 代碼,把解析到的信息存儲(chǔ)到相關(guān)對(duì)象中。
例如表信息會(huì)存儲(chǔ)到 TABLE_LIST 中,order_list 存儲(chǔ) order by 子句里的信息,where 字句存儲(chǔ)在 Item 中。
有了這些信息,再輔助以相應(yīng)的算法就可以對(duì) SQL 進(jìn)行更進(jìn)一步的處理了。
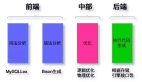
核心數(shù)據(jù)結(jié)構(gòu)及其關(guān)系
在 SQL 解析中,最核心的結(jié)構(gòu)是 SELECT_LEX,其定義在 sql/sql_lex.h 中。下面僅列出與上述例子相關(guān)的部分。

圖 3:SQL 解析樹結(jié)構(gòu)
上面圖示中,列名 username、ismale 存儲(chǔ)在 item_list 中,表名存儲(chǔ)在 table_list 中,條件存儲(chǔ)在 where 中。
其中以 where 條件中的 Item 層次結(jié)構(gòu)最深,表達(dá)也較為復(fù)雜,如下圖所示:
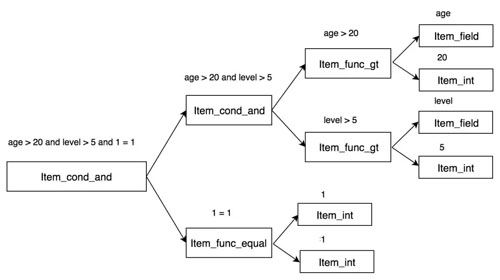
圖 4:where 條件
SQL 解析應(yīng)用
為了更深入的了解 SQL 解析器,這里給出 2 個(gè)應(yīng)用 SQL 解析的例子。
無(wú)用條件去除
無(wú)用條件去除屬于優(yōu)化器的邏輯優(yōu)化范疇,可以僅僅根據(jù) SQL 本身以及表結(jié)構(gòu)即可完成,其優(yōu)化的情況也是較多的,代碼在 sql/sql_optimizer.cc 文件中的 remove_eq_conds 函數(shù)。
為了避免過(guò)于繁瑣的描述,以及大段代碼的粘貼,這里通過(guò)圖來(lái)分析以下四種情況:
- 1=1 and (m > 3 and n > 4)
- 1=2 and (m > 3 and n > 4)
- 1=1 or (m > 3 and n > 4)
- 1=2 or (m > 3 and n > 4)
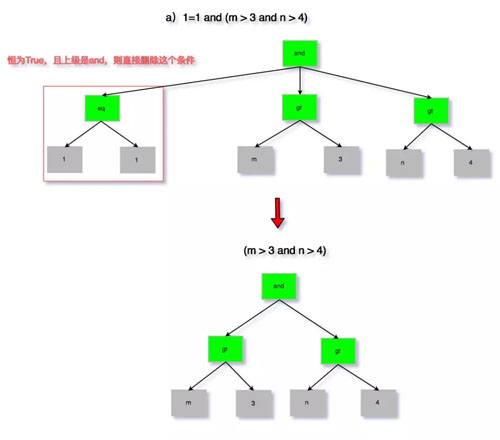
圖 5:無(wú)用條件去除 a
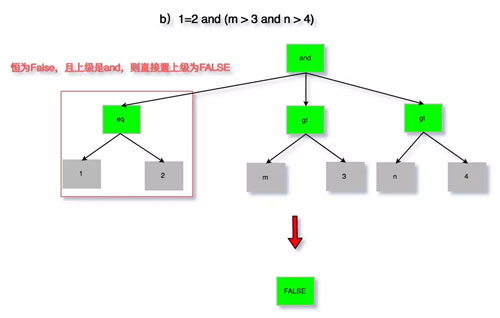
圖 6:無(wú)用條件去除 b
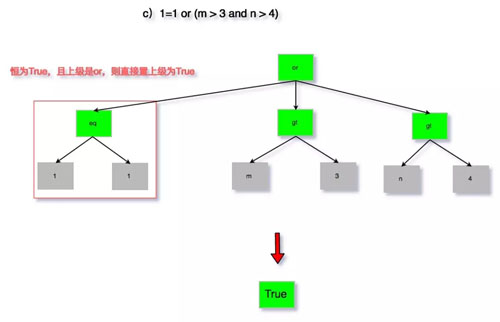
圖 7:無(wú)用條件去除 c
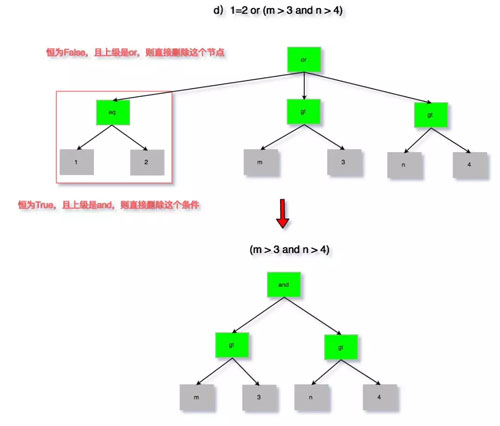
圖 8:無(wú)用條件去除 d
如果對(duì)其代碼實(shí)現(xiàn)有興趣的同學(xué),需要對(duì) MySQL 中的一個(gè)重要數(shù)據(jù)結(jié)構(gòu) Item 類有所了解。
因?yàn)槠浔容^復(fù)雜,所以 MySQL 官方文檔,專門介紹了 Item 類。阿里的 MySQL 小組,也有類似的文章。如需更詳細(xì)的了解,就需要去查看源碼中 sql/item_* 等文件。
SQL 特征生成
為了確保數(shù)據(jù)庫(kù),這一系統(tǒng)基礎(chǔ)組件穩(wěn)定、高效運(yùn)行,業(yè)界有很多輔助系統(tǒng)。比如慢查詢系統(tǒng)、中間件系統(tǒng)。
這些系統(tǒng)采集、收到 SQL 之后,需要對(duì) SQL 進(jìn)行歸類,以便統(tǒng)計(jì)信息或者應(yīng)用相關(guān)策略。歸類時(shí),通常需要獲取 SQL 特征。比如 SQL:
- select username, ismale from userinfo where age > 20 and level > 5;
SQL 特征為:
- select username, ismale from userinfo where age > ? and level > ?
業(yè)界著名的慢查詢分析工具 pt-query-digest,通過(guò)正則表達(dá)式實(shí)現(xiàn)這個(gè)功能但是這類處理辦法 Bug 較多。接下來(lái)就介紹如何使用 SQL 解析,完成 SQL 特征的生成。
SQL特征生成分兩部分組成:
- 生成 Token 數(shù)組
- 根據(jù) Token 數(shù)組,生成 SQL 特征
首先回顧在詞法解析章節(jié),我們介紹了 SQL 中的關(guān)鍵字,并且每個(gè)關(guān)鍵字都有一個(gè) 16 位的整數(shù)對(duì)應(yīng),而非關(guān)鍵字統(tǒng)一用 ident 表示,其也對(duì)應(yīng)了一個(gè) 16 位整數(shù)。如下表:

將一個(gè) SQL 轉(zhuǎn)換成特征的過(guò)程:

在 SQL 解析過(guò)程中,可以很方便的完成 Token 數(shù)組的生成。而一旦完成 Token 數(shù)組的生成,就可以很簡(jiǎn)單的完成 SQL 特征的生成。
SQL 特征被廣泛用于各個(gè)系統(tǒng)中,比如 pt-query-digest 需要根據(jù)特征對(duì) SQL 歸類,然而其基于正則表達(dá)式的實(shí)現(xiàn)有諸多 Bug。
下面列舉幾個(gè)已知 Bug:

學(xué)習(xí)建議
最近,在對(duì) SQL 解析器和優(yōu)化器探索的過(guò)程中,從一開始的茫然無(wú)措到有章可循,也總結(jié)了一些心得體會(huì),在這里跟大家分享一下:
- 閱讀相關(guān)書籍,書籍能給我們一個(gè)系統(tǒng)的認(rèn)識(shí)解析器和優(yōu)化器的角度。但是該類針對(duì) MySQL 的書籍市面上很少,目前中文作品可以看下《數(shù)據(jù)庫(kù)查詢優(yōu)化器的藝術(shù):原理解析與SQL性能優(yōu)化》。
- 閱讀源碼,但是***以某個(gè)版本為基礎(chǔ),比如 MySQL 5.6.23,因?yàn)?SQL 解析、優(yōu)化部分的代碼在不斷變化。尤其是在跨越大的版本時(shí),改動(dòng)力度大。
- 多使用 GDB 調(diào)試,驗(yàn)證自己的猜測(cè),檢驗(yàn)閱讀質(zhì)量。
- 需要寫相關(guān)代碼驗(yàn)證,只有寫出來(lái)了才能算真正的掌握。
作者:廣友、金龍、邢帆
簡(jiǎn)介:廣友,美團(tuán)到店綜合事業(yè)群資深 MySQL DBA,2012 年畢業(yè)于中國(guó)科學(xué)技術(shù)大學(xué),2017 年加入美團(tuán)點(diǎn)評(píng),長(zhǎng)期致力于 MySQL 及周邊工具的研究。
金龍,2014 年加入美團(tuán),主要從事相關(guān)的數(shù)據(jù)庫(kù)運(yùn)維、高可用和相關(guān)的運(yùn)維平臺(tái)建設(shè)。
邢帆,美團(tuán) DBA,2017 年研究生畢業(yè)后加入美團(tuán)點(diǎn)評(píng),目前對(duì) MySQL 運(yùn)維有一定經(jīng)驗(yàn),并編寫了一些自動(dòng)化腳本。