













Hadoop 3.0版本測試,終將計算與存儲解耦!
傳統的Hadoop架構是建立在相信通過大規模分布式數據處理獲得良好性能的***途徑是將計算帶入數據。在本世紀初,這確實是事實。當時,典型的企業數據中心的網絡基礎架構不能完成在服務器之間移動大量數據的任務,數據必須與計算機共存。
現在,企業數據中心的網絡基礎設施以及公有云提供商的網絡基礎設施不再是大數據計算的瓶頸,是時候將Hadoop的計算與存儲解耦。不少行業分析師也認識到了這一點,正如最近IDC關于分離大數據部署計算和存儲的報告中指出:
“解耦計算和存儲在大數據部署中被證明是有用的,它提供了更高的資源利用率,更高的靈活性和更低的成本。” - Ritu Jyoti,IDC
2018年,關于大數據基礎設施的討論不再圍繞使用高質量的數據布局算法減少網絡流量的方法展開。相反,現在有更多關于如何可靠地降低分布式存儲成本的討論。

Hadoop開源社區最近引入了Apache Hadoop版本3.0,即便被Gartner連續唱衰,但Hadoop發布的3.0版本還是有不少值得注意的改進。這一版本的發布也將計算和存儲解耦的討論推向輿論高峰。Hadoop 3.0的一個關鍵特性是Hadoop分布式文件系統(HDFS)的Erasure Coding (擦除編碼)。作為歷史悠久的HDFS 3x數據復制的替代方案,在配置相同的情況下,Erasure Coding與傳統3x數據復制相比,可以將HDFS存儲成本降低約50%。
在過去幾年,Hadoop社區已經討論了Erasure Coding將為HDFS帶來的潛在存儲成本的降低。鑒于過去十年在硬件和網絡方面的進步,許多人質疑3x數據復制是否有存在的意義。現在,HDFS Erasure Coding已經從根本改變了Hadoop的存儲經濟性——Hadoop社區也最終承認這一事實:數據不必與計算位于同一位置。
為了了解這個結果有多么戲劇性,我們可以比較一下2010年雅虎發布的關于Hadoop擴展的性能數據,并將其與HDFS和Erasure Coding進行比較。
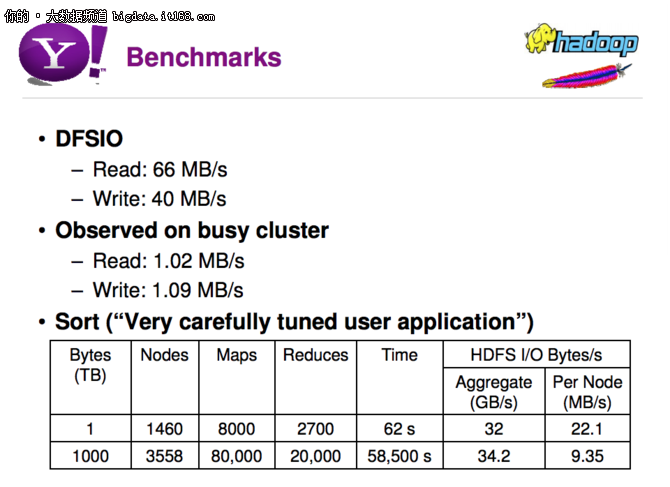
如下的幻燈片上呈現的是DFSIO基準測試,讀取吞吐量為66 MB / s,寫入吞吐量為40 MB / s。Sort基準測試的性能數據是基于非常仔細的調優之后獲得的。曾經,在HDFS中使用3x復制被認為是數據保護和性能提高的強大工具。
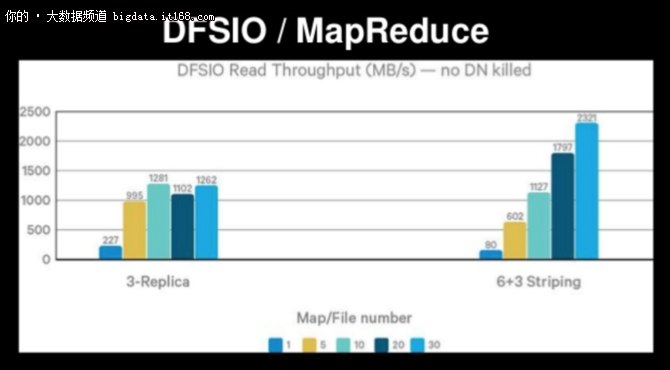
在如下的幻燈片上,同樣基于DFSIO基準,具有3x復制的HDFS讀取吞吐量為1,262MB / s,而對于使用Erasure Coding(6+3 Striping)的HDFS,讀取吞吐量為2,321MB / s。這是30個同步映射器,并沒有提到仔細的應用程序調優!HDFS使用的3x復制現在被視為實現(有限)數據可靠性的陳舊、昂貴和不必要的開銷。
帶有Erasure Coding(EC)的HDFS利用網絡為每個文件讀寫。這也在間接承認網絡不是性能的瓶頸。事實上,HDFS EC的主要性能影響是由于其CPU周期消耗而非網絡延遲。 總的來說,這表明存儲成本顯著降低(在這種情況下,可降低6美元/ TB),而不會犧牲性能。
即便接連被不看好,但Hadoop依舊是大數據領域堅實的底層基礎。隨著新版本被正式推入生產環境,Hadoop生態也開始逐漸壯大,取其精華,去其糟粕,Hadoop生態一直在努力改善表現不佳的組件,并不斷根據新的業務需求進行擴展,Hadoop生態或許并不是老了,而是成熟了。














