管理數據命根子的數據庫種類越來越多,有哪些您不了解的內幕呢?
數據是企業的命根子。數據種類增多,數據量增大,應用需求多樣化,導致數據庫的種類也不斷增多。除了以前說的交易類、事務處理類、嵌入類等常用的分類方法以外,根據不同應用需求而出現的新型數據正在不斷發展壯大。
作為全球最專業的按采用用戶數量對各類數據庫系統進行排名的機構,DB-Engines最近公布了***的排名,即2018年3月份排名,本文以2月的數據為例進行分析。
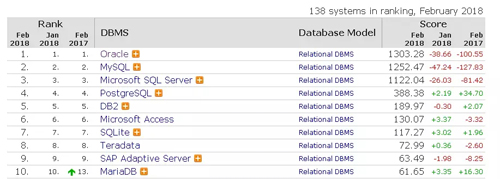
不得不說,在這份排名中,占據***陣營的是傳統的關系型數據庫的三大領頭羊Oracle、MySQL 和Microsoft SQL Server,與第二陣營與第三陣營的分值相差挺大。
透過這份排名,我們來看看數據庫系統的發展軌跡與趨勢。
關系型數據庫占據主流,新型數據庫后生可畏
341種數據庫被納入統計,按照所采用的數據模型的不同,被歸類到13個大類。不過,同樣的一個數據庫管理系統,可以被歸納到超過一種數據庫類型。
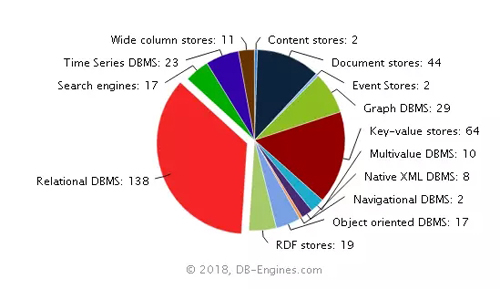
圖1 不同類型數據庫的數量
圖1顯示的就是每一類數據庫系統的數量。我們可以看出,數量最多的數據庫依然為傳統的關系型數據庫,138個;鍵值數據庫,64個;分布式文檔存儲數據庫,44個;圖形數據庫,29個;時序數據庫23個,等等。每一類數據所占的比例如圖2所示。
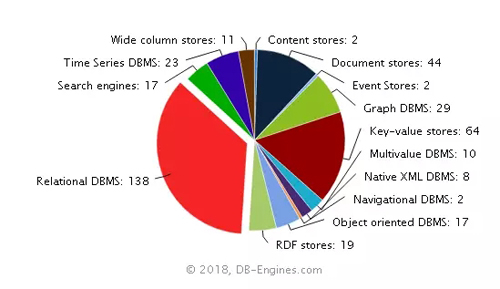
圖2 每一類數據所占的比例
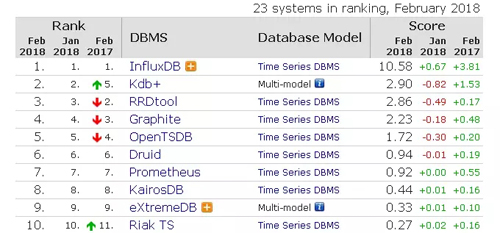
最近24個月以來,各類數據庫產品的聲望的變化情況如圖3所示,由此可以看出每類數據庫流行度的變化情況。其中,傳統關系型數據庫一直是市場的主流,聲望變化不大,處于中間值100附近,并稍有下降。聲望提高比較快的是時序數據庫、圖形數據庫、鍵值數據庫等幾類。
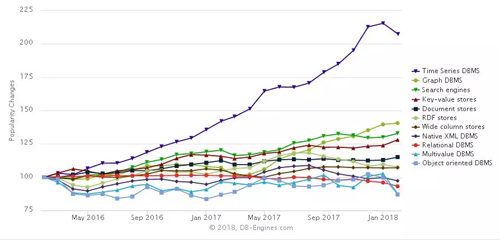
圖3 每類數據庫聲望的變化情況
開源系統與商業系統旗鼓相當,開源系統發展勢頭不減
DB-Engines榜單中另一個有意義的指標是開源系統與傳統商業數據庫系統的對比。在341套系統中,開源系統與商業系統數量旗鼓相當,不分伯仲,如圖4所示。
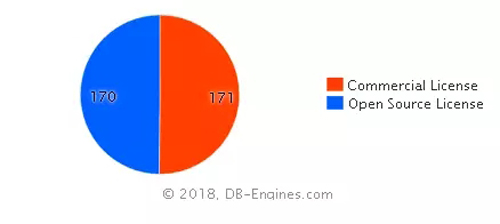
圖4 開源系統與商業系統數量
自2013年以來,商業系統與開源系統的發展趨勢如圖5所示,開源系統數量逐漸增多,商業系統逐漸減少,兩者趨向對半分。
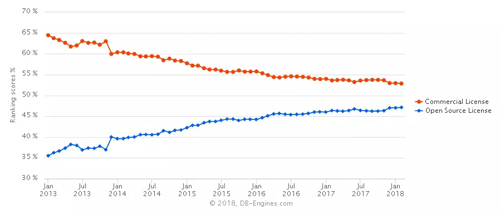
圖5 商業系統與開源系統的發展趨勢
非常有意思的是不同種類數據庫產品中,商業系統和開源系統的比例還是有差距的,如圖6。一個規律就是新型的增長比較快的數據庫類型是開源系統占據主流,而傳統的關系型數據庫,商業系統則占據主流。
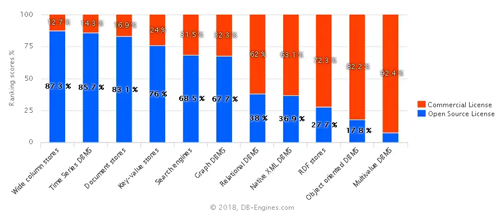
圖6 不同種類數據庫中商業系統和開源系統的比例
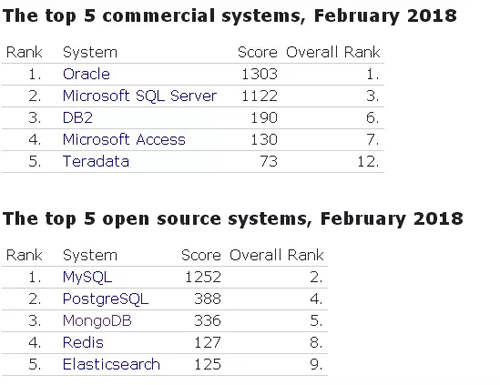
商業數據庫系統的前五名分別是:Oracle 、Microsoft SQL Server、IBM DB2、Microsoft Access,以及Teradata;開源數據庫系統中前五大系統分別是:MySQL、PostgreSQL、MongoDB、Redis、Elasticsearch。
六類數據庫的競爭格局日益清晰,主導系統***發展
關系型數據庫
關系數據庫是建立在關系模型基礎上的數據庫,借助于集合代數等數學概念和方法來處理數據庫中的數據。現實世界中的各種實體以及實體之間的各種聯系均用關系模型來表示。傳統的關系型數據庫其實就是行式數據庫,就是一行一行的方式來存儲信息的。
目前,關系型數據庫一直是市場的主流,也是數據庫市場規模***的領域,典型的產品如排名前五的Oracle、MySQL、SQL Server、PostgressSQL、DB2等。
關系型數據庫的優勢表現在:可以實現復雜查詢,可以用SQL語句方便地在一個表以及多個表之間做非常復雜的數據查詢;事務支持,使得對于安全性能很高的數據訪問要求得以實現。
對于Oracle和微軟SQL Server,大家都比較熟悉,在此不能不談開源數據庫MySQL。在WEB應用方面,MySQL是***的關系數據庫管理系統,也是很流行的關系型數據庫管理系統。基本上能實現用戶的各種功能需求,最初的核心思想主要是開源、簡便、易用,其高并發存取能力并不比大型數據庫差,安裝、使用都非常簡單。
時序數據庫
時間序列數據庫主要用于處理帶時間標簽(按照時間的順序變化,即時間序列化)的數據。時間序列數據主要是由電力行業、化工行業等各類型實時監測、檢查與分析設備所采集、產生的數據,這些工業數據的典型特點是:產生頻率快(每一個監測點一秒鐘內可產生多條數據)、嚴重依賴于采集時間(每一條數據均要求對應唯一的時間)、檢測點多信息量大(常規的實時監測系統均有成千上萬的監測點,監測點每秒鐘都產生數據,每天產生幾十GB的數據量)。
關系型數據庫無法滿足對時間序列數據的有效存儲與處理。目前對于時序大數據的存儲和處理往往采用關系型數據庫的方式進行處理,但關系型數據庫天生的劣勢導致其無法進行高效的數據存儲和查詢。時序大數據解決方案通過使用特殊的存儲方式,極大提高了時間相關數據的處理能力,相對于關系型數據庫的存儲空間減半,查詢速度極大提高。
典型系統如InfluxDB 就是一個開源分布式時序、事件和指標數據庫,目標是實現分布式和水平伸縮擴展。它有三大特性:Time Series (時間序列),你可以使用與時間有關的相關函數(如***,最小,求和等);Metrics(度量),你可以實時對大量數據進行計算; Eevents(事件),它支持任意的事件數據。
列式數據庫
列式數據庫一般應用于大量的字符串數據,列式數據庫從一開始就是面向大數據環境下數據倉庫的數據分析而產生,主要適合于批量數據處理和即時查詢。其優勢包括:極高的裝載速度(***可以等于所有硬盤I/O 的總和);適合大量的數據而不是小數據;實時加載數據僅限于增加(刪除和更新需要解壓縮Block ,然后計算和重新壓縮儲存);高效的壓縮率,因為存儲的數據類型是一樣的,不僅節省儲存空間,也節省計算內存和CPU,非常適合做聚合操作。
典型系統如Cassandra、HBase、Sybase IQ、HP Vertica、EMC Greenplum等。
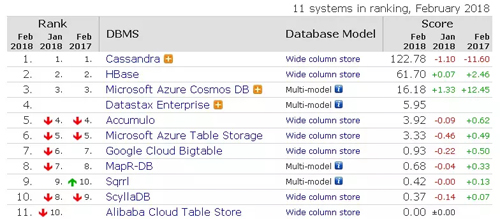
HBase–Hadoop Database是一個高可靠性、高性能、面向列、可伸縮的分布式存儲系統,利用HBase技術可在廉價PC Server上搭建起大規模結構化存儲集群。
HBase是Google Bigtable的開源實現,類似Google Bigtable利用GFS作為其文件存儲系統,HBase利用Hadoop HDFS作為其文件存儲系統;Google運行MapReduce來處理Bigtable中的海量數據,HBase同樣利用Hadoop MapReduce來處理HBase中的海量數據;Google Bigtable利用 Chubby作為協同服務,HBase利用Zookeeper作為對應。
鍵值數據庫
即Key-Value存儲,簡稱KV存儲。它是NoSQL存儲的一種方式。它的數據按照鍵值對的形式進行組織、索引和存儲。
KV存儲非常適合不涉及過多數據關系業務的數據,同時能有效減少讀寫磁盤的次數,比SQL數據庫存儲擁有更好的讀寫性能。典型的產品有Redis、DynamoDB等。
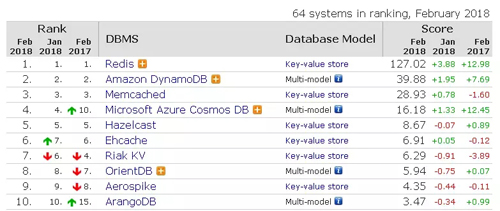
Redis 是完全開源免費的,遵守BSD協議,是一個高性能的key-value數據庫。
Redis 與其他 key-value 緩存產品一樣具有以下三個特點:Redis支持數據的持久化,可以將內存中的數據保存在磁盤中,重啟的時候可以再次加載進行使用。
Redis不僅僅支持簡單的key-value類型的數據,同時還提供list、set、zset、hash等數據結構的存儲。
Redis支持數據的備份,即master-slave模式的數據備份。
圖形數據庫
圖形數據庫不是專門用來存儲圖形圖像的,而是因為其用圖狀結構來維持其數據之間的關系,所以叫做圖形數據庫。
在圖數據結構中,只有兩種基本的數據類型,即節點(Node)和關系(Relationship),節點可以擁有屬性,關系(Relationship)也可以擁有屬性 ,屬性都是以鍵值對的方式存儲,節點與節點的聯系通過關系(Relationship)進行建立,他們建立的關系是有方向的。
Neo4j、Sones就是其典型代表。
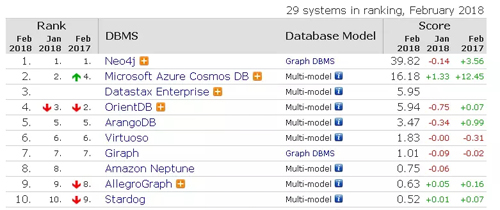
Neo4j是一個高性能的NoSQL圖形數據庫,它將結構化數據存儲在網絡上而不是表中。Neo4j也可以被看作是一個高性能的圖引擎,該引擎具有成熟數據庫的所有特性。程序員工作在一個面向對象的、靈活的網絡結構下而不是嚴格、靜態的表中——但是他們可以享受到具備完全的事務特性、企業級的數據庫的所有好處。Neo4j因其嵌入式、高性能、輕量級等優勢,越來越受到關注。其支持幾乎所有的主流的開發語言。
分布式文檔存儲數據庫
文檔存儲數據庫不需要定義,應用靈活,文檔存儲支持對結構化數據的訪問。不同于關系模型的是,文檔存儲沒有強制的架構,文檔存儲模型支持嵌套結構。例如,文檔存儲模型支持XML和JSON文檔,字段的“值”又可以嵌套存儲其它文檔。文檔存儲模型也支持數組和列值鍵。與鍵值存儲不同的是,文檔存儲關心文檔的內部結構。這使得存儲引擎可以直接支持二級索引,從而允許對任意字段進行高效查詢。支持文檔嵌套存儲的能力,使得查詢語言具有搜索嵌套對象的能力,XQuery就是一個例子。
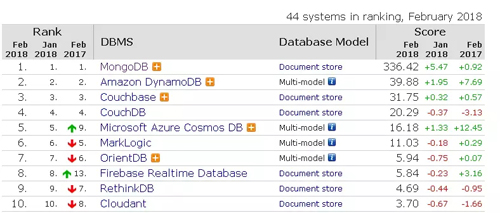
MongoDB是一個基于分布式文件存儲的數據庫,旨在為WEB應用提供可擴展的高性能數據存儲解決方案。MongoDB是一個介于關系數據庫和非關系數據庫之間的產品,是非關系數據庫當中功能最豐富,最像關系數據庫的。他支持的數據結構非常松散,是類似JSON的BSON格式,因此可以存儲比較復雜的數據類型。Mongo***的特點是他支持的查詢語言非常強大,其語法有點類似于面向對象的查詢語言,幾乎可以實現類似關系數據庫單表查詢的絕大部分功能,而且還支持對數據建立索引。
2月16日,MongoDB在西雅圖大會上宣布,MongoDB將在4.0版本中正式推出多文檔ACID事務支持。ACID 多文檔事務,可以理解為關系型數據庫的多行事務。在關系型的事務支持中,大家幾乎無一例外支持同一事務內操作的原子性,即要么全部提交,要么全部回滾。這個同一事務內可以有多個操作,針對于多個表,或者是同一個表內的多行數據。
這么多種類的數據庫,其實每一種都有自己的優勢和不足,也特別適合某一種數據應用。在數據存儲與處理方面,數據庫的發展還是活力實足,后勁實足。