













如何做好文本關鍵詞提取?從達觀數據應用的三種算法說起
簡介
在自然語言處理領域,處理海量的文本文件最關鍵的是要把用戶最關心的問題提取出來。而無論是對于長文本還是短文本,往往可以通過幾個關鍵詞窺探整個文本的主題思想。同時,不管是基于文本的推薦還是基于文本的搜索,對于文本關鍵詞的依賴也很大,關鍵詞提取的準確程度直接關系到推薦系統或者搜索系統的最終效果。因此,關鍵詞提取在文本挖掘領域是一個很重要的部分。

關于文本的關鍵詞提取方法分為有監督、半監督和無監督三種:
- 有監督的關鍵詞抽取算法是將關鍵詞抽取算法看作是二分類問題,判斷文檔中的詞或者短語是或者不是關鍵詞。既然是分類問題,就需要提供已經標注好的訓練語料,利用訓練語料訓練關鍵詞提取模型,根據模型對需要抽取關鍵詞的文檔進行關鍵詞抽取。
- 半監督的關鍵詞提取算法只需要少量的訓練數據,利用這些訓練數據構建關鍵詞抽取模型,然后使用模型對新的文本進行關鍵詞提取,對于這些關鍵詞進行人工過濾,將過濾得到的關鍵詞加入訓練集,重新訓練模型。
- 無監督的方法不需要人工標注的語料,利用某些方法發現文本中比較重要的詞作為關鍵詞,進行關鍵詞抽取。
有監督的文本關鍵詞提取算法需要高昂的人工成本,因此現有的文本關鍵詞提取主要采用適用性較強的無監督關鍵詞抽取。其文本關鍵詞抽取流程如下:

圖 1 無監督文本關鍵詞抽取流程圖
無監督關鍵詞抽取算法可以分為三大類,基于統計特征的關鍵詞抽取、基于詞圖模型的關鍵詞抽取和基于主題模型的關鍵詞抽取。
1. 基于統計特征的關鍵詞抽取算法
基于統計特征的關鍵詞抽取算法的思想是利用文檔中詞語的統計信息抽取文檔的關鍵詞。通常將文本經過預處理得到候選詞語的集合,然后采用特征值量化的方式從候選集合中得到關鍵詞。基于統計特征的關鍵詞抽取方法的關鍵是采用什么樣的特征值量化指標的方式,目前常用的有三類:
(1) 基于詞權重的特征量化
基于詞權重的特征量化主要包括詞性、詞頻、逆向文檔頻率、相對詞頻、詞長等。
(2) 基于詞的文檔位置的特征量化
這種特征量化方式是根據文章不同位置的句子對文檔的重要性不同的假設來進行的。通常,文章的前N個詞、后N個詞、段首、段尾、標題、引言等位置的詞具有代表性,這些詞作為關鍵詞可以表達整個的主題。
(3) 基于詞的關聯信息的特征量化
詞的關聯信息是指詞與詞、詞與文檔的關聯程度信息,包括互信息、hits值、貢獻度、依存度、TF-IDF值等。
我們介紹幾種常用的特征值量化指標。
1.1 詞性
詞性是通過分詞、語法分析后得到的結果。現有的關鍵詞中,絕大多數關鍵詞為名詞或者動名詞。一般情況下,名詞與其他詞性相比更能表達一篇文章的主要思想。但是,詞性作為特征量化的指標,一般與其他指標結合使用。
1.2 詞頻
詞頻表示一個詞在文本中出現的頻率。一般我們認為,如果一個詞在文本中出現的越是頻繁,那么這個詞就越有可能作為文章的核心詞。詞頻簡單地統計了詞在文本中出現的次數。但是,只依靠詞頻所得到的關鍵詞有很大的不確定性,對于長度比較長的文本,這個方法會有很大的噪音。
1.3 位置信息
一般情況下,詞出現的位置對于詞來說有著很大的價值。例如,標題、摘要本身就是作者概括出的文章的中心思想,因此出現在這些地方的詞具有一定的代表性,更可能成為關鍵詞。但是,因為每個作者的習慣不同,寫作方式不同,關鍵句子的位置也會有所不同,所以這也是一種很寬泛的得到關鍵詞的方法,一般情況下不會單獨使用。
1.4 互信息
互信息是信息論中的概念,是變量之間相互依賴的度量。互信息并不局限于實值隨機變量,它更加一般且決定著聯合分布 p(X,Y) 和分解的邊緣分布的乘積 p(X)p(Y) 的相似程度。互信息的計算公式如下:
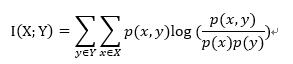
其中,p(x,y)是X和Y的聯合概率分布函數,p(x)和p(y)分別為X和Y的邊緣概率分布函數。
當使用互信息作為關鍵詞提取的特征量化時,應用文本的正文和標題構造PAT樹,然后計算字符串左右的互信息。
1.5 詞跨度
詞跨度是指一個詞或者短語在文中***出現和末次出現之間的距離,詞跨度越大說明這個詞對文本越重要,可以反映文本的主題。一個詞的跨度計算公式如下:
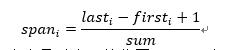
其中, 表示詞i在文本中***出現的位置, 表示詞i在文本中***次出現的位置,sum表示文本中詞的總數。
詞跨度被作為提取關鍵詞的方法是因為在現實中,文本中總是有很多噪聲(指不是關鍵詞的那些詞),使用詞跨度可以減少這些噪聲。
1.6 TF-IDF值
一個詞的TF是指這個詞在文檔中出現的頻率,假設一個詞w在文本中出現了m次,而文本中詞的總數為n,那么
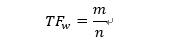
一個詞的IDF是根據語料庫得出的,表示這個詞在整個語料庫中出現的頻率。假設整個語料庫中,包含詞w的文本一共有M篇,語料庫中的文本一共有N篇,則
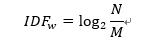
由此可得詞w的TF-IDF值為:
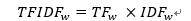
TF-IDF的優點是實現簡單,相對容易理解。但是,TFIDF算法提取關鍵詞的缺點也很明顯,嚴重依賴語料庫,需要選取質量較高且和所處理文本相符的語料庫進行訓練。另外,對于IDF來說,它本身是一種試圖抑制噪聲的加權,本身傾向于文本中頻率小的詞,這使得TF-IDF算法的精度不高。TF-IDF算法還有一個缺點就是不能反應詞的位置信息,在對關鍵詞進行提取的時候,詞的位置信息,例如文本的標題、文本的首句和尾句等含有較重要的信息,應該賦予較高的權重。
基于統計特征的關鍵詞提取算法通過上面的一些特征量化指標將關鍵詞進行排序,獲取TopK個詞作為關鍵詞。
基于統計特征的關鍵詞的重點在于特征量化指標的計算,不同的量化指標得到的記過也不盡相同。同時,不同的量化指標也有其各自的優缺點,在實際應用中,通常是采用不同的量化指標相結合的方式得到Topk個詞作為關鍵詞。
2. 基于詞圖模型的關鍵詞抽取算法
基于詞圖模型的關鍵詞抽取首先要構建文檔的語言網絡圖,然后對語言進行網絡圖分析,在這個圖上尋找具有重要作用的詞或者短語,這些短語就是文檔的關鍵詞。語言網絡圖中節點基本上都是詞,根據詞的鏈接方式不同,語言網絡的主要形式分為四種:共現網絡圖、語法網絡圖、語義網絡圖和其他網絡圖。
在語言網絡圖的構建過程中,都是以預處理過后的詞作為節點,詞與詞之間的關系作為邊。語言網絡圖中,邊與邊之間的權重一般用詞之間的關聯度來表示。在使用語言網絡圖獲得關鍵詞的時候,需要評估各個節點的重要性,然后根據重要性將節點進行排序,選取TopK個節點所代表的詞作為關鍵詞。節點的重要性計算方法有以下幾種方法。
2.1 綜合特征法
綜合特征法也叫社會網絡中心性分析方法,這種方法的核心思想是節點中重要性等于節點的顯著性,以不破壞網絡的整體性為基礎。此方法就是從網絡的局部屬性和全局屬性角度去定量分析網絡結構的拓撲性質,常用的定量計算方法如下。
(1) 度
節點的度是指與該節點直接向量的節點數目,表示的是節點的局部影響力,對于非加權網絡,節點的度為:
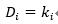
對于加權網絡,節點的度又稱為節點的強度,計算公式為:
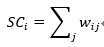
(2) 接近性
節點的接近性是指節點到其他節點的最短路徑之和的倒數,表示的是信息傳播的緊密程度,其計算公式為:
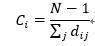
(3) 特征向量
特征向量的思想是節點的中心化測試值由周圍所有連接的節點決定,即一個節點的中心化指標應該等于其相鄰節點的中心化指標之線性疊加,表示的是通過與具有高度值的相鄰節點所獲得的間接影響力。特征向量的計算公式如下:
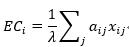
(4) 集聚系數
節點的集聚系數是它的相鄰的節點之間的連接數與他們所有可能存在鏈接的數量的比值,用來描述圖的頂點之間階級成團的程度的系數,計算公式如下:
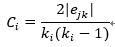
(5) 平均最短路徑
節點的平均最短路徑也叫緊密中心性,是節點的所有最短路徑之和的平均值,表示的是一個節點傳播信息時對其他節點的依賴程度。如果一個節點離其他節點越近,那么他傳播信息的時候也就越不需要依賴其他人。一個節點到網絡中各點的距離都很短,那么這個點就不會受制于其他節點。計算公式如下:
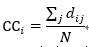
因為每個算法的側重方向的不同,在實際的問題中所選取的定量分析方法也會不一樣。同時,對于關鍵詞提取來說,也可以和上一節所提出的統計法得到詞的權重,例如詞性等相結合構建詞搭配網絡,然后利用上述方法得到關鍵詞。
2.2 系統科學法
系統科學法進行中心性分析的思想是節點重要性等于這個節點被刪除后對于整個語言網絡圖的破壞程度。重要的節點被刪除后會對網絡的連通性等產生變化。如果我們在網絡圖中刪除某一個節點,圖的某些指定特性產生了改變,可以根據特性改變的大小獲得節點的重要性,從而對節點進行篩選。
2.3 隨機游走法
隨機游走算法是網絡圖中一個非常著名的算法,它從給定圖和出發點,隨機地選擇鄰居節點移動到鄰居節點上,然后再把現在的節點作為出發點,迭代上述過程。
隨機游走算法一個很出名的應用是大名鼎鼎的PageRank算法,PageRank算法是整個Google搜索的核心算法,是一種通過網頁之間的超鏈接來計算網頁重要性的技術,其關鍵的思想是重要性傳遞。在關鍵詞提取領域, Mihalcea 等人所提出的TextRank算法就是在文本關鍵詞提取領域借鑒了這種思想。
PageRank算法將整個互聯網看作一張有向圖,網頁是圖中的節點,而網頁之間的鏈接就是圖中的邊。根據重要性傳遞的思想,如果一個大型網站A含有一個超鏈接指向了網頁B,那么網頁B的重要性排名會根據A的重要性來提升。網頁重要性的傳遞思想如下圖所示,
")
圖 2 PageRank簡單描述(來自PageRank論文)
在PageRank算法中,最主要的是對于初始網頁重要性(PR值)的計算,因為對于上圖中的網頁A的重要性我們是無法預知的。但是,在原始論文中給出了一種迭代方法求出這個重要性,論文中指出,冪法求矩陣特征值與矩陣的初始值無關。那么,就可以為每個網頁隨機給一個初始值,然后迭代得到收斂值,并且收斂值與初始值無關。
PageRank求網頁i的PR值計算如下:
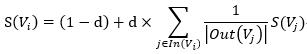
其中,d為阻尼系數,通常為0.85。 是指向網頁i的網頁集合。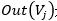 是指網頁j中的鏈接指向的集合,
是指網頁j中的鏈接指向的集合,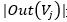 是指集合中元素的個數。
是指集合中元素的個數。
TextRank在構建圖的時候將節點由網頁改成了句子,并為節點之間的邊引入了權值,其中權值表示兩個句子的相似程度。其計算公式如下:
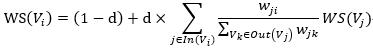
公式中的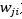 為圖中節點
為圖中節點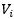 和
和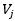 的邊的權重。其他符號與PageRank公式相同。
的邊的權重。其他符號與PageRank公式相同。
TextRank算法除了做文本關鍵詞提取,還可以做文本摘要提取,效果不錯。但是TextRank的計算復雜度很高,應用不廣。
3. 基于主題模型的關鍵詞抽取
基于主題模型的關鍵詞提取算法主要利用的是主題模型中關于主題的分布的性質進行關鍵詞提取。算法步驟如下:
- 從文章中獲取候選關鍵詞。即將文本分詞,也可以再根據詞性選取候選關鍵詞。
- 根據大規模預料學習得到主題模型。
- 根據得到的隱含主題模型,計算文章的主題分布和候選關鍵詞分布。
- 計算文檔和候選關鍵詞的主題相似度并排序,選取前n個詞作為關鍵詞。
算法的關鍵在于主題模型的構建。主題模型是一種文檔生成模型,對于一篇文章,我們的構思思路是先確定幾個主題,然后根據主題想好描述主題的詞匯,將詞匯按照語法規則組成句子,段落,***生成一篇文章。主題模型也是基于這個思想,它認為文檔是一些主題的混合分布,主題又是詞語的概率分布,pLSA模型就是***個根據這個想法構建的模型。同樣地,我們反過來想,我們找到了文檔的主題,然后主題中有代表性的詞就能表示這篇文檔的核心意思,就是文檔的關鍵詞。
pLSA模型認為,一篇文檔中的每一個詞都是通過一定概率選取某個主題,然后再按照一定的概率從主題中選取得到這個詞語,這個詞語的計算公式為:
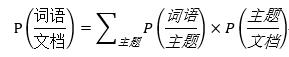
一些貝葉斯學派的研究者對于pLSA模型進行了改進,他們認為,文章對應主題的概率以及主題對應詞語的概率不是一定的,也服從一定的概率,于是就有了現階段常用的主題模型--LDA主題模型。
LDA是D.M.Blei在2003年提出的。LDA采用了詞袋模型的方法簡化了問題的復雜性。在LDA模型中,每一篇文檔是一些主題構成的概率分布,而每一個主題又是很多單詞構成的一個概率分布。同時,無論是主題構成的概率分布還是單詞構成的概率分布也不是一定的,這些分布也服從Dirichlet 先驗分布。
文檔的生成模型可以用如下圖模型表示:
其中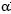 和
和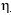 為先驗分布的超參數,
為先驗分布的超參數,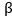 為第k個主題下的所有單詞的分布,
為第k個主題下的所有單詞的分布,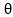 為文檔的主題分布,w為文檔的詞,z為w所對應的主題。
為文檔的主題分布,w為文檔的詞,z為w所對應的主題。

圖 3 Blei在論文中的圖模型
LDA挖掘了文本的深層語義即文本的主題,用文本的主題來表示文本的含義也從一定程度上降低了文本向量的維度,很多人用這種方式對文本做分類,取得了不錯的效果。具體LDA的算法請參考。
LDA關鍵詞提取算法利用文檔的隱含語義信息來提取關鍵詞,但是主題模型提取的關鍵詞比較寬泛,不能很好的反應文檔主題。另外,對于LDA模型的時間復雜度較高,需要大量的實踐訓練。
4. 應用
現在階段,文本的關鍵詞提取在基于文本的搜索、推薦以及數據挖掘領域有著很廣泛的應用。同時在實際應用中,因為應用環境的復雜性,對于不同類型的文本,例如長文本和短文本,用同一種文本關鍵詞提取方法得到的效果并不相同。因此,在實際應用中針對不同的條件環境所采用的算法會有所不同,沒有某一類算法在所有的環境下都有很好的效果。
相對于上文中所提到的算法,一些組合算法在工程上被大量應用以彌補單算法的不足,例如將TF-IDF算法與TextRank算法相結合,或者綜合TF-IDF與詞性得到關鍵詞等。同時,工程上對于文本的預處理以及文本分詞的準確性也有很大的依賴。對于文本的錯別字,變形詞等信息,需要在預處理階段予以解決,分詞算法的選擇,未登錄詞以及歧義詞的識別在一定程度上對于關鍵詞提取會有很大的影響。
關鍵詞提取是一個看似簡單,在實際應用中卻十分棘手的任務,從現有的算法的基礎上進行工程優化,達觀數據在這方面做了很大的努力并且取得了不錯的效果。
5. 總結
本文介紹了三種常用的無監督的關鍵詞提取算法,并介紹了其優缺點。關鍵詞提取在文本挖掘領域具有很廣闊的應用,現有的方法也存在一定的問題,我們依然會在關鍵詞提取的問題上繼續努力研究,也歡迎大家積極交流。
參考文獻
[1] TextRank算法提取關鍵詞和摘要http://xiaosheng.me/2017/04/08/article49/
[2] Page L, Brin S, Motwani R, et al. The PageRank citation ranking: Bringing order to the web[R]. Stanford InfoLab, 1999.
[3] 劉知遠. 基于文檔主題結構的關鍵詞抽取方法研究[D]. 北京: 清華大學, 2011.
[4] tf-idf,https://zh.wikipedia.org/zh-hans/Tf-idf
[5] 一文詳解機器領域的LDA主題模型http://zhuanlan.51cto.com/art/201712/559686.htm?mobile
[6] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of machine Learning research, 2003, 3(Jan): 993-1022.
[7] 趙京勝, 朱巧明, 周國棟, 等. 自動關鍵詞抽取研究綜述[J]. 軟件學報, 2017, 28(9): 2431-2449.
【本文為51CTO專欄作者“達觀數據”的原創稿件,轉載可通過51CTO專欄獲取聯系】












