關于數據庫連接池的極簡教程
一,常規數據庫連接
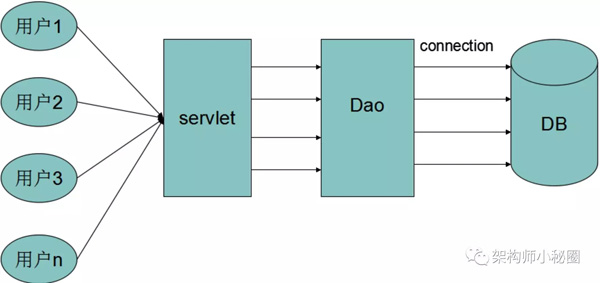
常規數據庫連接一般由以下六個步驟構成:
- 裝載數據庫驅動程序;
- 建立數據庫連接;
- 創建數據庫操作對象
- 訪問數據庫,執行sql語句;
- 處理返回結果集
- 斷開數據庫連接。
- public class TestMysqlConn {
- public static void main(String[] args) {
- Connection con;
- Statement stmt;
- ResultSet rs;
- try {
- //1,裝載數據庫驅動程序
- Class.forName("com.mysql.jdbc.Driver").newInstance();
- //2,建立數據庫連接
- con = DriverManager.getConnection("jdbc:mysql://3xmq.com:3306/test","root","root");
- //3,創建數據庫操作對象
- stmt = con.createStatement();
- //4,執行sql語句
- rs = stmt.executeQuery("select * from _test");
- //5,處理返回結果集
- while(rs.next()){
- int num = rs.getInt("id");
- String name = rs.getString("name");
- String des = rs.getString("description");
- System.out.println(num + " " + name + " " + des);
- }
- //6,斷開數據庫連接
- stmt.close();
- conn.close();
- } catch (Exception e) {
- e.printStackTrace();
- System.out.println("連接失敗");
- }
- }
- }
二,常規數據庫連接底層原理
數據庫本身實際上就是一個Server端程序在跑,我們開發的程序連接數據庫,相當于啟動了一個Client端,連接到Server端,也就是C/S模式!那么數據庫連接本質上是基于什么協議呢?以mysql連接為例,常見兩種連接場景命令如下:
1,mysql -h localhost -uroot -p(本地模式)
2,mysql -h 127.0.0.1 -uroot -p(IP模式)
對場景一,使用tcpdump抓包如下:

可以看到并沒有抓到網絡請求數據,說明它走的是本地socket協議,unix domain socket。
對場景二,使用tcpdump進行抓包如下:
可以看到,mysql的連接過程,內部實際上是經過tcp/ip協議的,mysql上層基于tcp/ip協議封裝了自己的一套消息協議!說白了,底層是基于tcp/ip socket 協議!
在mysql中使用命令:show status,可以看到mysql實際上會創建一個線程來處理客戶端連接上來的連接!如下圖:

Threads_connected連接數是1,mysql此時有一個連接!
Threads_created為3,說明曾經有3個connection連接過數據庫!
Threads_cached為2,mysql內部的線程連接池,將空閑的連接不是立即銷毀而是放到線程連接池中,如果新加進來連接不是立刻創建線程而是先從線程連接池中找到空閑的連接線程,然后分配,如果沒有才創建新的線程。可見mysql內部已經為我們做優化了。
Threads_running為1,當前活躍線程數為1。
小提示:
1,Threads_catched值不是無限大的,一般為32左右。 mysql是可以調整單線程和多線程模式的,單線程只允許一個線程連接mysql,其他連接將會被拒絕。
2,數據庫本地unix domain socket連接快于tcp/ip連接
三,常規數據庫連接優化空間
以mysql為例,要做優化,首先要尋找數據庫連接占用的資源有哪些?
1,mysql每個連接是會創建一個線程的,可以登錄mysql輸入show status查看Threads_connected和Threads_created的大小,那么我們每連接一次mysql就會創建一個線程,每次斷開又會銷毀一個線程。
數據庫連接的創建和銷毀本質就是線程的創建和銷毀,而創建線程和銷毀線程的資源消耗是非常大的。系統為每個線程分配棧空間,可以通過ulimis -s來查看,ubuntu 14.04默認是8M,那么100個連接就是800M,很吃內存的。其次mysql數據庫會為每個連接分配連接緩沖區和結果緩沖區,也是要消耗時間的。
2,mysql的每次連接,都會進行tcp3次握手和斷開時的4次揮手,分配一些緩存空間,也會消耗一定的時間。
如下圖:
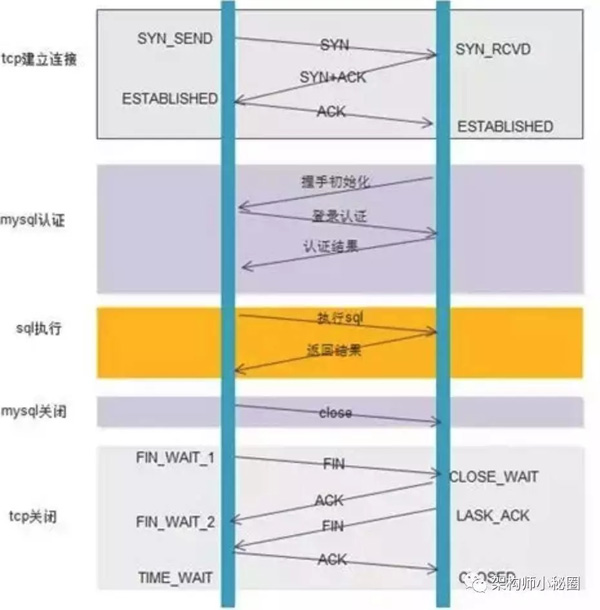
數據庫連接池有效的避免了上述的問題,數據庫連接池技術的思想非常簡單,將數據庫連接作為對象存儲在一個Vector對象中,一旦數據庫連接建立后,不同的數據庫訪問請求就可以共享這些連接,這樣,通過復用這些已經建立的數據庫連接,可以克服上述缺點,極大地節省系統資源和時間。
也就是我們提前創建好這些連接,然后需要用去取連接即可。和線程池的思想是一致的。
四,數據庫連接池
數據庫連接池(Connection pooling)是程序啟動時建立足夠的數據庫連接,并將這些連接組成一個連接池,由程序動態地對池中的連接進行申請,使用,釋放。創建數據庫連接是一個很耗時的操作,也容易對數據庫造成安全隱患。所以,在程序初始化的時候,集中創建多個數據庫連接,并把他們集中管理,供程序使用,可以保證較快的數據庫讀寫速度,還更加安全可靠。
連接池基本的思想是在系統初始化的時候,將數據庫連接作為對象存儲在內存中,當用戶需要訪問數據庫時,并非建立一個新的連接,而是從連接池中取出一個已建立的空閑連接對象。使用完畢后,用戶也并非將連接關閉,而是將連接放回連接池中,以供下一個請求訪問使用。而連接的建立、斷開都由連接池自身來管理。同時,還可以通過設置連接池的參數來控制連接池中的初始連接數、連接的上下限數以及每個連接的最大使用次數、最大空閑時間等等,也可以通過其自身的管理機制來監視數據庫連接的數量、使用情況等。如下圖:

數據庫連接池機制:
(1)建立數據庫連接池對象(服務器啟動)。
(2)按照事先指定的參數創建初始數量的數據庫連接(即:空閑連接數)。
(3)對于一個數據庫訪問請求,直接從連接池中得到一個連接。如果數據庫連接池對象中沒有空閑的連接,且連接數沒有達到最大(即:最大活躍連接數),創建一個新的數據庫連接。
(4)存取數據庫。
(5)關閉數據庫,釋放所有數據庫連接(此時的關閉數據庫連接,并非真正關閉,而是將其放入空閑隊列中。如實際空閑連接數大于初始空閑連接數則釋放連接)。
(6)釋放數據庫連接池對象(服務器停止、維護期間,釋放數據庫連接池對象,并釋放所有連接)。
數據庫連接池在初始化時,按照連接池最小連接數,創建相應數量連接放入池中,無論是否被使用。當連接請求數大于最大連接數閥值時,會加入到等待隊列!
數據庫連接池的最小連接數和最大連接數的設置要考慮到以下幾個因素:
最小連接數:是連接池一直保持的數據庫連接,所以如果應用程序對數據庫連接的使用量不大,將會有大量的數據庫連接資源被浪費.
最大連接數:是連接池能申請的最大連接數,如果數據庫連接請求超過次數,后面的數據庫連接請求將被加入到等待隊列中,這會影響以后的數據庫操作
如果最小連接數與最大連接數相差很大:那么最先連接請求將會獲利,之后超過最小連接數量的連接請求等價于建立一個新的數據庫連接.不過,這些大于最小連接數的數據庫連接在使用完不會馬上被釋放,他將被放到連接池中等待重復使用或是空間超時后被釋放.
五,常見數據庫連接池
在Java中開源的常用的數據庫連接池有以下幾種 :
1)DBCP
DBCP是一個依賴Jakarta commons-pool對象池機制的數據庫連接池.DBCP可以直接的在應用程序中使用,Tomcat的數據源使用的就是DBCP。
2)c3p0
c3p0是一個開放源代碼的JDBC連接池,它在lib目錄中與Hibernate一起發布,包括了實現jdbc3和jdbc2擴展規范說明的Connection 和Statement 池的DataSources 對象。
3)Druid
阿里出品,淘寶和支付寶專用數據庫連接池,但它不僅僅是一個數據庫連接池,它還包含一個ProxyDriver,一系列內置的JDBC組件庫,一個SQL Parser。支持所有JDBC兼容的數據庫,包括Oracle、MySql、Derby、Postgresql、SQL Server、H2等等。
Druid針對Oracle和MySql做了特別優化,比如Oracle的PS Cache內存占用優化,MySql的ping檢測優化。
Druid提供了MySql、Oracle、Postgresql、SQL-92的SQL的完整支持,這是一個手寫的高性能SQL Parser,支持Visitor模式,使得分析SQL的抽象語法樹很方便。
簡單SQL語句用時10微秒以內,復雜SQL用時30微秒。
通過Druid提供的SQL Parser可以在JDBC層攔截SQL做相應處理,比如說分庫分表、審計等。Druid防御SQL注入攻擊的WallFilter就是通過Druid的SQL Parser分析語義實現的。
六,數據庫連接池配置
連接池配置大體可以分為基本配置、關鍵配置、性能配置等主要配置。

6.1 基本配置
基本配置是指連接池進行數據庫連接的四個基本必需配置:
傳遞給JDBC驅動的用于連接數據庫的用戶名、密碼、URL以及驅動類名。
|
DBCP |
c3p0 |
Druid |
|
|
用戶名 |
username |
user |
username |
|
密碼 |
password |
password |
password |
|
URL |
url |
jdbcUrl |
jdbcUrl |
|
驅動類名 |
driverClassName |
driverClass |
driverClassName |
注:在Druid連接池的配置中,driverClassName可配可不配,如果不配置會根據url自動識別dbType(數據庫類型),然后選擇相應的driverClassName。
6.2 關鍵配置
為了發揮數據庫連接池的作用,在初始化時將創建一定數量的數據庫連接放到連接池中,這些數據庫連接的數量是由最小數據庫連接數來設定的。無論這些數據庫連接是否被使用,連接池都將一直保證至少擁有這么多的連接數量。連接池的最大數據庫連接數量限定了這個連接池能占有的最大連接數,當應用程序向連接池請求的連接數超過最大連接數量時,這些請求將被加入到等待隊列中。
最小連接數:
是數據庫一直保持的數據庫連接數,所以如果應用程序對數據庫連接的使用量不大,將有大量的數據庫資源被浪費。
初始化連接數:
連接池啟動時創建的初始化數據庫連接數量。
最大連接數:
是連接池能申請的最大連接數,如果數據庫連接請求超過此數,后面的數據庫連接請求被加入到等待隊列中。
最大等待時間:
當沒有可用連接時,連接池等待連接被歸還的最大時間,超過時間則拋出異常,可設置參數為0或者負數使得無限等待(根據不同連接池配置)。
|
DBCP |
c3p0 |
Druid |
|
|
最小連接數 |
minIdle(0) |
minPoolSize(3) |
minIdle(0) |
|
初始化連接數 |
initialSize(0) |
initialPoolSize(3) |
initialSize(0) |
|
最大連接數 |
maxTotal(8) |
maxPoolSize(15) |
maxActive(8) |
|
最大等待時間 |
maxWaitMillis(毫秒) |
maxIdleTime(0秒) |
maxWait(毫秒) |
注1:在DBCP連接池的配置中,還有一個maxIdle的屬性,表示最大空閑連接數,超過的空閑連接將被釋放,默認值為8。對應的該屬性在Druid連接池已不再使用,配置了也沒有效果,c3p0連接池則沒有對應的屬性。
注2:數據庫連接池在初始化的時候會創建initialSize個連接,當有數據庫操作時,會從池中取出一個連接。如果當前池中正在使用的連接數等于maxActive,則會等待一段時間,等待其他操作釋放掉某一個連接,如果這個等待時間超過了maxWait,則會報錯;如果當前正在使用的連接數沒有達到maxActive,則判斷當前是否空閑連接,如果有則直接使用空閑連接,如果沒有則新建立一個連接。在連接使用完畢后,不是將其物理連接關閉,而是將其放入池中等待其他操作復用。
6.3 性能配置
預緩存設置:
即是PSCache,PSCache對支持游標的數據庫性能提升巨大,比如說oracle。JDBC的標準參數,用以控制數據源內加載的PreparedStatements數量。但由于預緩存的statements屬于單個connection而不是整個連接池,所以設置這個參數需要考慮到多方面的因素。
單個連接擁有的最大緩存數:要啟用PSCache,必須配置大于0,當大于0時,poolPreparedStatements自動觸發修改為true。在Druid中,不會存在Oracle下PSCache占用內存過多的問題,可以把這個數值配置大一些,比如說100
連接有效性檢測設置:
連接池內部有機制判斷,如果當前的總的連接數少于miniIdle,則會建立新的空閑連接,以保證連接數得到miniIdle。如果當前連接池中某個連接在空閑了timeBetweenEvictionRunsMillis時間后任然沒有使用,則被物理性的關閉掉。有些數據庫連接的時候有超時限制(mysql連接在8小時后斷開),或者由于網絡中斷等原因,連接池的連接會出現失效的情況,這時候設置一個testWhileIdle參數為true,可以保證連接池內部定時檢測連接的可用性,不可用的連接會被拋棄或者重建,最大情況的保證從連接池中得到的Connection對象是可用的。當然,為了保證絕對的可用性,你也可以使用testOnBorrow為true(即在獲取Connection對象時檢測其可用性),不過這樣會影響性能。
超時連接關閉設置:
removeAbandoned參數,用來檢測到當前使用的連接是否發生了連接泄露,所以在代碼內部就假定如果一個連接建立連接的時間很長,則將其認定為泄露,繼而強制將其關閉掉。