













日存儲量超10TB,海量數(shù)據(jù)挑戰(zhàn)下騰訊全鏈路日志監(jiān)控平臺實踐
本文主要介紹騰訊 SNG 開發(fā)全鏈路日志監(jiān)控平臺所經(jīng)歷的挑戰(zhàn)及解決方案。
背景
全鏈路日志監(jiān)控在現(xiàn)在盛行的微服務(wù)和分布式環(huán)境下,能有效地提高問題定位分析效率,成為開發(fā)和運維利器。
當(dāng)前已有開源解決方案和成熟的廠商提供,比如 Twitter 的 zipkin,基于 Google 的 Dapper 論文設(shè)計開發(fā)了分布式跟蹤系統(tǒng),用于采集各處理節(jié)點間的日志和耗時信息,幫助用戶排查請求鏈路的異常環(huán)節(jié)。
在有統(tǒng)一 RPC 中間件框架的業(yè)務(wù)部門比較容易接入 zipkin,但織云全鏈路日志監(jiān)控平臺(后成全鏈路)面對的實際業(yè)務(wù)場景更為復(fù)雜。
全鏈路日志監(jiān)控實現(xiàn)遇到了更多的挑戰(zhàn),全鏈路技術(shù)選型經(jīng)歷了從開源組件到自研的變化。
當(dāng)前織云全鏈路日志監(jiān)控平臺已接入空間和視頻云業(yè)務(wù)日志數(shù)據(jù),每日數(shù)據(jù)存儲量 10TB,可做到 1/10 的壓縮比,峰值流量 30GB/s。
我們先分享一個案例場景:
2017 年 8 月 31 日 21:40~21:50,X 業(yè)務(wù)模塊指標(biāo)異常,成功率由 99.988% 降為 97.325%,如下圖所示:
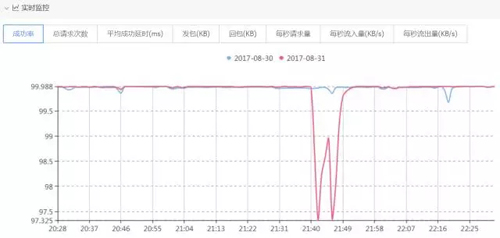
收到成功率異常告警后,在多維監(jiān)控系統(tǒng)上通過畫像下鉆發(fā)現(xiàn)是空間點播業(yè)務(wù)的 iPhone 客戶端成功率下降,返回碼為-310110004。如下圖:
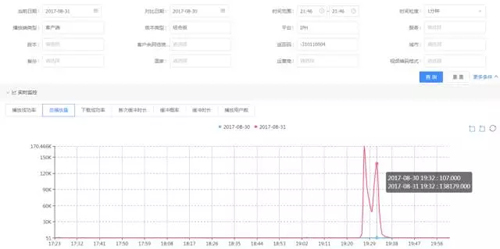
通過大盤多維數(shù)據(jù)分析發(fā)現(xiàn)異常原因后,因涉及 APP 問題,還需要進一步分析用戶出現(xiàn)異常的上下文。
因而需要查看出現(xiàn)異常的用戶在異常時間點的全鏈路日志數(shù)據(jù)。在全鏈路視圖上,可以展示查詢出來符合異常條件的用戶日志和操作過程。
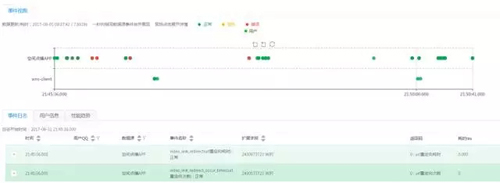
以上是從面到點的異常分析案例。
使用場景
全鏈路日志監(jiān)控的使用場景主要有三大類:
- 個例分析,主要有處理用戶投訴和從面到點的異常分析。
- 開發(fā)調(diào)試,主要用于開發(fā)過程中查看關(guān)聯(lián)模塊的日志和作為測試提單線索。
- 監(jiān)控告警,主要是從日志數(shù)據(jù)中提取維度,統(tǒng)計為多維數(shù)據(jù)用于異常檢測和原因分析。
遇到的挑戰(zhàn)
在構(gòu)建織云全鏈路日志監(jiān)控平臺時,織云監(jiān)控模塊經(jīng)歷了從傳統(tǒng)監(jiān)控和質(zhì)量統(tǒng)計到大數(shù)據(jù)多維監(jiān)控平臺的轉(zhuǎn)型。我們踩過了大數(shù)據(jù)套件的坑,也遇到過業(yè)務(wù)場景的挑戰(zhàn)。
業(yè)務(wù)多樣性挑戰(zhàn)
QQ 體系內(nèi)有豐富多樣的業(yè)務(wù),例如:手 Q、空間、直播、點播、會員等。
這些業(yè)務(wù)產(chǎn)生不同樣式的日志格式,并且沒有一致的 RPC 中間件框架。這個背景決定系統(tǒng)需要支持靈活的日志格式和多種采集方式。
海量數(shù)據(jù)挑戰(zhàn)
同時在線超 2 億用戶上報的狀態(tài)數(shù)據(jù),日存儲量超 10T,帶寬超過 30GB/s,需要穩(wěn)定和高效的數(shù)據(jù)處理、高性能和低成本的數(shù)據(jù)存儲服務(wù)。
在使用開源組件完成原型開發(fā)后,逐漸遇到性能瓶頸和穩(wěn)定性挑戰(zhàn),驅(qū)使我們通過自研逐漸替換開源組件。
應(yīng)對挑戰(zhàn)
日志多樣化
日志的價值除提供查詢檢索外,還可做統(tǒng)計分析和異常檢測告警。為此我們將日志數(shù)據(jù)規(guī)范化后分流到多維監(jiān)控平臺,復(fù)用監(jiān)控平臺已有的能力。
基于前面積累的監(jiān)控平臺開發(fā)經(jīng)驗,我們在織云全鏈路日志監(jiān)控平臺設(shè)計時取長補短,通過自研日志存儲平臺解決開源存儲組件遇到的成本、性能和穩(wěn)定性瓶頸。
織云全鏈路日志監(jiān)控平臺提供了 4 種數(shù)據(jù)格式支持,分別是:
- 分隔符
- 正則解析
- json 格式
- api 上報
分隔符、正則解析和 json 格式用于非侵入式的數(shù)據(jù)采集,靈活性好。但是服務(wù)端的日志解析性能較低,分隔符的數(shù)據(jù)解析只能做到 4W/s 的處理性能。
而 api 方式則能達到 10W/s 處理性能,對于內(nèi)部業(yè)務(wù),我們推薦采用統(tǒng)一的日志組件,并嵌入 api 上報數(shù)據(jù)。
系統(tǒng)自動容災(zāi)和擴縮容
對于海量的日志監(jiān)控系統(tǒng)設(shè)計,***步是將模塊做無狀態(tài)化設(shè)計。比如系統(tǒng)的接入模塊、解析模塊和處理模塊,這類無需狀態(tài)同步的模塊,可單獨部署提供服務(wù)。
但對這類無狀態(tài)業(yè)務(wù)模塊,需要增加剔除異常鏈路機制。也就是數(shù)據(jù)處理鏈路中如果中間一個節(jié)點異常,則該節(jié)點往后的其他節(jié)點提供的服務(wù)是無效的,需要中斷當(dāng)前的鏈路,異常鏈路剔除機制有多種,如通過 zk 的心跳機制剔除。
為避免依賴過多的組件,我們做了一個帶狀態(tài)的心跳機制。上游節(jié)點 A 定時向下游節(jié)點 B 發(fā)送心跳探測請求,時間間隔為 6s,B 回復(fù)心跳請求時帶上自身的服務(wù)可用狀態(tài)和鏈路狀態(tài)。
上游節(jié)點 A 收到 B 心跳帶上的不可用狀態(tài)后,如果 A 下游無其他可用節(jié)點,則 A 的下游鏈路狀態(tài)也置為不可用狀態(tài),心跳狀態(tài)依次傳遞,最終自動禁用整條鏈路。
有狀態(tài)的服務(wù)通常是存儲類服務(wù),這類服務(wù)通過主備機制做容災(zāi)。如果同一時間只允許一個 master 提供服務(wù)則可采用 zk 的選舉機制實現(xiàn)主備切換。
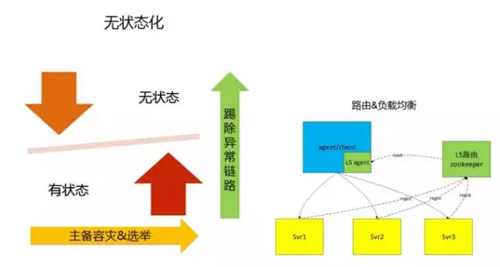
做到系統(tǒng)自動容災(zāi)和擴縮容的第二步是實現(xiàn)通過路由機制實現(xiàn)名字服務(wù)和負載均衡。
使用開源組件 zookeeper 能快速實現(xiàn)名字服務(wù)功能,要求在服務(wù)端實現(xiàn)注冊邏輯,在客戶端實現(xiàn)路由重載邏輯。
數(shù)據(jù)通道的容災(zāi)
我們采用兩種機制:
- 雙寫方式,對于數(shù)據(jù)質(zhì)量要求高的監(jiān)控數(shù)據(jù),采用雙寫方式實現(xiàn)。這種方式要求后端有足夠的資源應(yīng)對峰值請求,提供的能力是低延時和高效的數(shù)據(jù)處理能力。
- 消息隊列,對于日志數(shù)據(jù)采用具備數(shù)據(jù)容災(zāi)能力的消息隊列實現(xiàn)。使用過的選型方案有 kafka 和 rabbitmq+mongodb。
采用消息隊列能應(yīng)對高吞吐量的日志數(shù)據(jù),并帶有削峰作用,其副作用是在高峰期數(shù)據(jù)延時大,不能滿足實時監(jiān)控告警需求。
采用消息隊列還需要注意規(guī)避消息積壓導(dǎo)致的隊列異常問題,例如使用 kafka 集群,如果消息量累積量超過磁盤容量,會造成整個隊列吞吐量下降,影響數(shù)據(jù)質(zhì)量。
我們后來采用 rabbitmq+mongodb 方案:數(shù)據(jù)在接入層按 1 萬條或累積 30s 形成一個數(shù)據(jù)塊,將數(shù)據(jù)庫隨機寫入由多個 mongodb 實例構(gòu)成的集群。再將 mongodb 的 ip 和 key 寫入 rabbitmq 中。
后端處理集群從 rabbitmq 獲取待消費的信息后,從對應(yīng)的 mongodb 節(jié)點讀取數(shù)據(jù)并刪除。通過定時統(tǒng)計 rabbitmq 和 mongodb 的消息積壓量,如何超過閾值則實施自動清理策略。
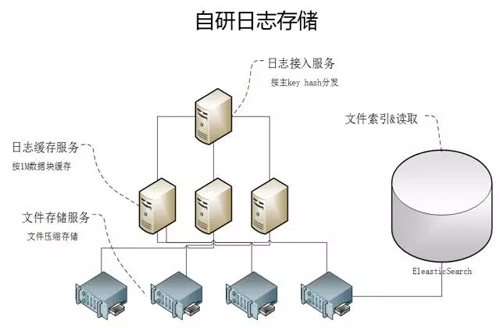
查詢
日志的存儲方案為應(yīng)對高效和低成本查詢,我們采用自研的方式實現(xiàn)。全鏈路上報的數(shù)據(jù)按用戶 ID 或請求 ID 作為主 key 進行 hash 分片。
分片后的數(shù)據(jù)在緩存模塊累積 1min 或 1M 大小,然后寫入文件服務(wù)器集群;文件寫入集群后,將 hash 值與文件路徑的映射關(guān)系寫入 Elastic Search。
查詢數(shù)據(jù)提供兩類能力:
- 按主 key 查詢。查詢方式是對待查詢 key 計算 hash 值,從 ES 中檢索出文件路徑后送入查詢模塊過濾查找。
- 非主 key 的關(guān)鍵字查找。根據(jù)業(yè)務(wù)場景,提供的查詢策略是查詢到含關(guān)鍵字的日志即可,該策略的出發(fā)點是平衡查詢性能,避免檢索全量文本。
也就是***次查詢 1000 個文件,如果有查詢結(jié)果則停止后續(xù)的查詢;如果無查詢結(jié)果返回,則遞增查找 2000 個文件,直到查詢 10 萬個文件終止。
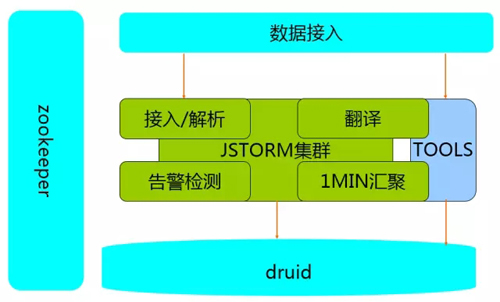
為滿足多樣的業(yè)務(wù)場景,我們在數(shù)據(jù)處理模塊抽象了 ETL 能力,做到插件化擴展和可配置實現(xiàn),并提供統(tǒng)一的任務(wù)管理和集群管理能力。
總結(jié)
全鏈路日志監(jiān)控的開發(fā)過程有以下經(jīng)驗可借鑒:
- 使用成熟的開源組件構(gòu)建初級業(yè)務(wù)功能。
- 在業(yè)務(wù)運行過程中,通過修改開源組件或自研提升系統(tǒng)處理能力和穩(wěn)定性,降低運營成本和提升運維效率。
- 采用無狀態(tài)化和路由負載均衡能力實現(xiàn)標(biāo)準(zhǔn)化。
- 抽象提煉功能模型,建立平臺化能力,滿足多樣業(yè)務(wù)需求。























