













編程和數學基礎不佳如何入門人工智能?
一、人工智能的發展現狀
1.1 概念
根據維基百科的解釋,人工智能是被機器展示的智力,與人類和其他動物的自然智能相反,在計算機科學中 AI 研究被定義為 “代理人軟件程序”:任何能夠感受周圍環境并且能最大化它成功機會的設備。
1.2 重大事件
- 2016 年 3 月 ,AlphaGo 與當時世界排名第四、職業九段棋手李世石,進行圍棋人機大戰,以 4:1 總比分獲勝。
- 2016 年 10 月 ,美國白宮發布了《為未來人工智能做好準備》和《美國國家人工智能研究與發展策略規劃》兩份重磅報告,詳細闡述了美國未來的人工智能發展規劃以及人工智能給政府工作帶來的挑戰與機遇。
VentureBeat 對這兩份報告進行了總結,得出了 7 個淺顯易懂的要點:
1. 人工智能應當被用于造福人類;
2. 政府應該擁抱人工智能;
3. 需要對自動汽車和無人機進行管制;
4. 要讓所有孩子都跟上技術的發展;
5. 使用人工智能補充而非取代人類工作者;
6. 消除數據中的偏見或不要使用有偏見的數據;
7. 考慮安全和全球影響。
- 2016 年雙十一 ,魯班首次服務雙十一,制作了 1.7 億章商品展示廣告,提升商品點擊率 100%。如果全靠設計師人手來完成,假設每張圖需要耗時 20 分鐘,滿打滿算需要 100 個設計師連續做 300 年。
2017 年,魯班的設計水平顯著提升,目前已經學習百萬級的設計師創意內容,擁有演變出上億級的設計能力。此外,魯班已經實現一天制作 4000 萬張海報能力,沒有一張會完全一樣。

- 2017 年 5 月 ,AlphaGo Master 戰勝世界冠軍柯潔。
- 2017 年 10 月 18 日 ,DeepMind 團隊公布了最強版本 AlphaGo, 代號 AlphaGo Zero。
- 2017 年 10 月 25 日 ,在沙特舉行的未來投資計劃大會上,沙特阿拉伯授予美國漢森機器人公司生產的 “女性” 機器人索菲亞公民身份。
作為世界上首個獲得公民身份的機器人,索菲亞當天說,“她” 希望用人工智能 “幫助人類過上更好的生活”,同時對支持 “AI 威脅論” 的馬斯克說 “人不犯我,我不犯人”!
會后,馬斯克在推特上說:“把電影《教父》輸入了人工智能系統,還能有什么比這個更糟的?” 教父是好萊塢經典電影,劇情充滿了背叛和謀殺。
索菲亞被授予公民身份后所產生的倫理問題也是人們不得不考慮的
近幾年人工智能領域的大新聞太多,這里不一一列舉
二、人工智能、深度學習、機器學習、增強學習之間的關系是怎樣的
如圖所示,人工智能是一個大類,包括專家系統、知識表示、機器學習等等,其中機器學習是目前最火也是發展最好的一個分支,機器學習中又包括監督學習、非監督學習、深度學習,增強學習等等。
監督學習 ,就是人們常說的分類,通過已有的訓練樣本(即已知數據以及其對應的輸出)去訓練得到一個最優模型(這個模型屬于某個函數的集合,最優則表示在某個評價準則下是最佳的)。
再利用這個模型將所有的輸入映射為相應的輸出,對輸出進行簡單的判斷從而實現分類的目的,也就具有了對未知數據進行分類的能力。



舉例來說,我們上幼兒園的時候經常做的一個活動叫 看圖識字 ,如上圖所示,老師會給我們看很多圖片,下面配了文字,時間長了之后,我們大腦中會形成抽象的概念,兩個犄角,一條短尾巴,胖胖的(特征)…
這樣的動物是牛;圓的,黃的,發光的,掛在天上的 … 是太陽;人長這樣。等再看到類似的東西時我們便能認出來,即使跟以前看到的不完全一樣,但是符合在我們大腦中形成的概念,如下圖所示。
非監督學學習 則是另一種研究的比較多的學習方法,它與監督學習的不同之處,在于我們事先沒有任何訓練樣本,而需要直接對數據進行建模。
舉個例子,如圖所示,在沒有任何提示(無訓練集)的情況下,需要把下列六個圖形分成兩類,你會怎么分呢,當然是第一排一類,第二排一類,因為第一排形狀更接近,第二排形狀更接近。
非監督學習就是在實現不知道數據集分類的情況下在數據中尋找特征。
深度學習 是基于機器學習延伸出來的一個新的領域,由以人大腦結構為啟發的神經網絡算法為起源加之模型結構深度的增加發展,并伴隨大數據和計算能力的提高而產生的一系列新的算法。
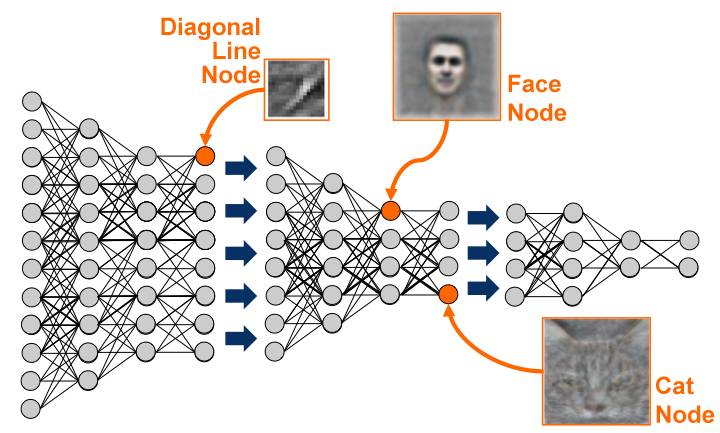
深度學習概念由著名科學家 Geoffrey Hinton 等人在 2006 年和 2007 年在《Sciences》等上發表的文章被提出和興起。

深度學習,作為機器學習中延伸出來的一個領域,被應用在圖像處理與計算機視覺,自然語言處理以及語音識別等領域。
自 2006 年至今,學術界和工業界合作在深度學習方面的研究與應用在以上領域取得了突破性的進展。以 ImageNet 為數據庫的經典圖像中的物體識別競賽為例,擊敗了所有傳統算法,取得了前所未有的精確度。
增強學習 也是機器學習一個重要的分支,是通過觀察來學習做成如何的動作。每個動作都會對環境有所影響,學習對象根據觀察到的周圍環境的反饋來做出判斷。
三、數學基礎有多重要
對于數學基礎知識,需要高中數學知識加上高數、線性代數、統計學、概率論,即使掌握的不是很完善,但是至少要知道概念,在用到的時候知道去哪查。
如果基礎不好,可以先看看吳軍的《數學之美》,講的比較通俗易懂。也可以邊做邊學,實踐是檢驗真理的唯一標準,畢竟大多數人還是以工程實踐為主,如果你想做研究理論的科學家,并不適合看本文。
四、入門級機器學習算法
4.1 決策樹
判定樹是一個類似于流程圖的樹結構:其中,每個內部結點表示在一個屬性上的測試,每個分支代表一個屬性輸出,而每個樹葉結點代表類或類分布。樹的最頂層是根結點。
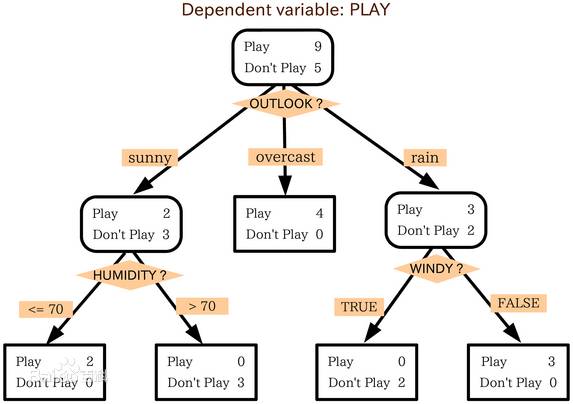
例:現有一個數據集,表示一些的人的年齡、收入、是否是學生、信用、是否會買電腦。年齡有年輕,中年,老年三種;收入有高中低;信用有一般和很好。數據及保存在 AllElectronics.csv 中。
現在在有一個新的人(數據),要判斷這個人是否會買電腦。
- allElectronicsData = open(r'D:\deeplearning\AllElectronics.csv', 'rb')
- reader = csv.reader(allElectronicsData)
- headers = reader.next()
- print(headers)
- featureList = []
- labelList = [] #最后一列
- for row in reader:
- #print(row)
- labelList.append(row[len(row)-1]) #在元祖末尾添加元素
- rowDict = {}
- for i in range(1,len(row)-1):
- rowDict[headers[i]] = row[i]
- featureList.append(rowDict)
- print(featureList)
- print(labelList)
- vec = DictVectorizer()
- dummyX = vec.fit_transform(featureList).toarray()
- print("dummyX:" + str(dummyX))
- print(vec.get_feature_names())
- lb = preprocessing.LabelBinarizer()
- dummyY = lb.fit_transform(labelList)
- print("dummyY:" + str(dummyY))
- clf = tree.DecisionTreeClassifier(criterion='entropy')
- clf = clf.fit(dummyX,dummyY)
- print("clf: "+ str(clf))
- with open("allElectronicInformationGainDri.dot",'w') as f:
- f = tree.export_graphviz(clf,feature_names=vec.get_feature_names(),out_file = f) #在當前工作目錄生成 .dot 文件
- oneRowX = dummyX[0, :]
- print("oneRowx: " + str(oneRowX))
- newRowX = oneRowX
- newRowX[0] = 1
- newRowX[2] = 0
- print("newRowX: " + str(newRowX))
- predictedY = clf.predict(newRowX)
- print("predictedY:" + str(predictedY))
4.2 最臨近取樣
最臨近取樣就是把已有數據分成幾類,對新輸入的數據計算與已知數據的距離,距離哪一個近,就把新數據分到哪一類,例如下圖所示的電影分類,對于最后一行未知電影類型的電影,根據打斗次數和接吻次數,距離浪漫型更近,應該被歸類為浪漫型電影。

例:irisdata.txt 實在網上下載的鳶尾屬植物數據集,根據數據集合,對新的數據進行分類
- # coding:utf-8
- #不調用庫,自己實現 knn 算法
- import csv #讀取 CSV 文件用的模塊,讀取數據用的
- import random #隨機數計算
- import math #數學計算
- import operator
- from bokeh.util.session_id import random
- from boto.beanstalk import response
- from dask.array.learn import predict
- # 裝載數據集 filename:數據集文件名 split:以數據集中某個位置為結點,把數據集分為 trainingSet 和 testSet
- def loadDataSet(filename, split, trainingSet=[], testSet=[]):
- with open(filename, 'rb') as csvfile:
- lines = csv.reader(csvfile) #把所有行存入 lines
- dataset = list(lines) #把數據轉換為 list 格式
- for x in range(len(dataset)-1):
- for y in range(4):
- dataset[x][y] = float(dataset[x][y])
- if random.random() < split: #如果隨機值小于 split
- trainingSet.append(dataset[x]) #則加到 trainingSet
- else:
- testSet.append(dataset[x])
- #歐幾里德距離 :坐標差的平方的和再開根號 還有曼哈頓距離
- def euclideanDistance(instance1, instance2, length):
- distance = 0
- for x in range(length):
- distance += pow((instance1[x] -instance2[x]), 2)
- return math.sqrt(distance)
- #返回距離 testInstance 最近 trainingSet 的 K 個鄰居
- def getNeighbours(trainingSet, testInstance, k):
- distances = []
- length =len(testInstance) - 1
- for x in range(len(trainingSet)):
- dist = euclideanDistance(testInstance, trainingSet[x], length) #每一個訓練集數據和實例數據之間的距離
- distances.append((trainingSet[x],dist))
- distances.sort(key=operator.itemgetter(1)) #sort 排序為從小到大
- #取前 k 個最近的 neighbors
- neighbors = []
- for x in range(k):
- neighbors.append(distances[x][0])
- return neighbors
- #根據少數服從多數的原則判斷要預測實例屬于哪一類。計算 testInstance 到 trainingSet 距離最近的個數,返回最多的那一類
- def getResponse(neighbors):
- classVotes = {}
- for x in range(len(neighbors)):
- response = neighbors[x][-1]
- if response in classVotes:
- classVotes[response] += 1
- else:
- classVotes[response] = 1
- sortedVotes = sorted(classVotes.iteritems(), key=operator.itemgetter(1), reverse=True)
- return sortedVotes[0][0]
- #獲取預測的準確率 testSet:測試數據集 predictions:用代碼預測的類別集合
- def getAccuracy(testSet, predictions):
- correct = 0
- for x in range(len(testSet)):
- if testSet[x][-1] == predictions[x]: #-1 表示數組的最后一個值。
- correct += 1
- return(correct/float(len(testSet))) * 100.0
- def main():
- trainingSet=[]
- testSet=[]
- split = 0.67 #三分之二為訓練集 , 三分之一為數據集
- loadDataSet(r'C:\Users\ning\workspace\KNNdata\irisdata.txt', split, trainingSet, testSet)
- print 'Train Set: ' + repr(len(trainingSet)) #repr 轉化為字符串
- print 'Test Set: ' + repr(len(testSet))
- predictions = []
- k = 3
- for x in range(len(testSet)):
- neighbors = getNeighbours(trainingSet, testSet[x], k)
- result = getResponse(neighbors)
- predictions.append(result)
- print("> predicted=" + repr(result) + ', actual=' + repr(testSet[x][-1]))
- accuarcy = getAccuracy(testSet, predictions)
- print('Accuracy: ' + repr(accuarcy) + '%')
- main()
4.3 支持向量機
支持向量機(SVM)是從線性可分情況下的最優分類面發展而來。最優分類面就是要求分類線不但能將兩類正確分開 (訓練錯誤率為 0), 且使分類間隔最大。
SVM 考慮尋找一個滿足分類要求的超平面 , 并且使訓練集中的點距離分類面盡可能的遠 , 也就是尋找一個分類面使它兩側的空白區域 (margin) 最大。
這兩類樣本中離分類面最近的點且平行于最優分類面的超平面上 H1,H2 的訓練樣本就叫做支持向量。

例:使用 sklearn 庫實現 svm 算法, 俗稱調庫,實際上調庫是一個很簡單的過程,初級階段甚至都不需要知道原理。
- # coding:utf-8
- from sklearn import svm
- X = [[2,0], [1,1], [2,3]]
- y = [0,0,1]
- clf = svm.SVC(kernel = 'linear')
- clf.fit(X,y) #ͨ通過 .fit 函數已經可以算出支持向量機的所有參數并保存在 clf 中
- print clf
- # get support vectors
- print clf.support_vectors_
- #get index of support vectors
- print clf.support_
- #get number of support vectors for each class
- print clf.n_support_
- #predict data , 參數是二維數組
- print clf.predict([[2, 0], [10,10]])
五、書單推薦
- 《數學之美》吳軍
- 《機器學習》 周志華
- 《漫談人工智能》 集智俱樂部
- 《機器學習實戰》 Peter Harrington
- 《TensorFlow 技術解析與實戰》 李嘉璇
- 《統計學習方法》 李航




























