













正則表達(dá)式-從模糊到清晰
1. 什么是正則
簡(jiǎn)單點(diǎn),正則是一些用來(lái)匹配和處理文本的字符串(或者叫工具),往往用于查找特定的信息(搜索),或者查找并編輯特定的信息(替換)。它是一種內(nèi)置在其他語(yǔ)言里的一種“迷你”語(yǔ)言,比如內(nèi)置在Javscript、Java等語(yǔ)言中。
2. 要認(rèn)可的事實(shí)
正則答案不唯一。幾乎所有的問(wèn)題,往往都會(huì)有不止一種解決方案。有的比較簡(jiǎn)單,有的比較快速,有點(diǎn)兼容性更好,有的功能更全。我們需要依據(jù)自己的需求,確認(rèn)一種最適合自己的方案。
3. 正則引擎概述
正則引擎可以分為2類(lèi)。一種稱(chēng)之為NFA(非確定型有窮自動(dòng)機(jī)),另一種稱(chēng)之為DFA(確定型又窮自動(dòng)機(jī))。嗯,概念不好理解,我們舉個(gè)栗子:
正則:to(Jack|Rose|Jerry)
匹配文本:xxx···toJerry
1)NFA(表達(dá)式主導(dǎo))匹配過(guò)程
正則表達(dá)式從正則的***個(gè) t 開(kāi)始,每次由正則引擎查看表達(dá)式的一部分,同時(shí)檢查當(dāng)前文本是否匹配表達(dá)式的當(dāng)前部分。如果是,則繼續(xù)表達(dá)式的下一部分,如果繼續(xù),直到表達(dá)式的所有部分都能匹配到。此時(shí)發(fā)現(xiàn)當(dāng)檢查到當(dāng)前文本中的字符 t 時(shí),所以正則表達(dá)式的***項(xiàng)匹配成功,接著會(huì)檢查緊跟其后的字符是否能由 o 來(lái)匹配,然后發(fā)現(xiàn)可以,則接著檢查后面的元素,此時(shí)后面的元素是 (Jack|Rose|Jerry) ,引擎會(huì)嘗試著3種可能進(jìn)行分別測(cè)試,直到匹配成功。
2)DFA(文本主導(dǎo))匹配過(guò)程
引擎在掃碼當(dāng)前文本的時(shí)候,會(huì)記錄當(dāng)前有效的所有匹配可能。當(dāng)引擎移動(dòng)到文本的 t 時(shí),它會(huì)在當(dāng)前處理的匹配可能中添加一個(gè)潛在的可能:

接下來(lái)掃描的每個(gè)字符,都會(huì)更新當(dāng)前的可能匹配序列。例如掃碼到匹配文本的 J 時(shí),有效的可能匹配變成了2個(gè),Rose被淘汰出局。

掃描到匹配文本的 e 時(shí),Jack也被淘汰出局,此時(shí)就只剩一個(gè)可能的匹配了。當(dāng)完成后續(xù)的rry的匹配時(shí),整個(gè)匹配完成。

3)兩句話點(diǎn)評(píng)NFA與DFA
1、DFA匹配速度快但特性少(比如不支持捕獲組、反向引用),NFA匹配稍慢但能力強(qiáng)大;
2、DFA就好比搭載電動(dòng)發(fā)動(dòng)機(jī)的汽車(chē),加速度很快,但續(xù)航短,不能出遠(yuǎn)門(mén),而NFA可以認(rèn)為是汽油發(fā)動(dòng)機(jī)的汽車(chē),加速度沒(méi)那么快,但是適應(yīng)性廣,哪里都能去,但由于適應(yīng)性廣,所以調(diào)教很重要。
4)需要注意的
Java、Javascript、PHP、Python這些都是NFA引擎。
4. 過(guò)基礎(chǔ)(老手請(qǐng)?zhí)^(guò))
5. 要點(diǎn)講解
1)貪婪與懶惰
貪婪模式:
盡可能匹配更多的字符。舉個(gè)栗子:
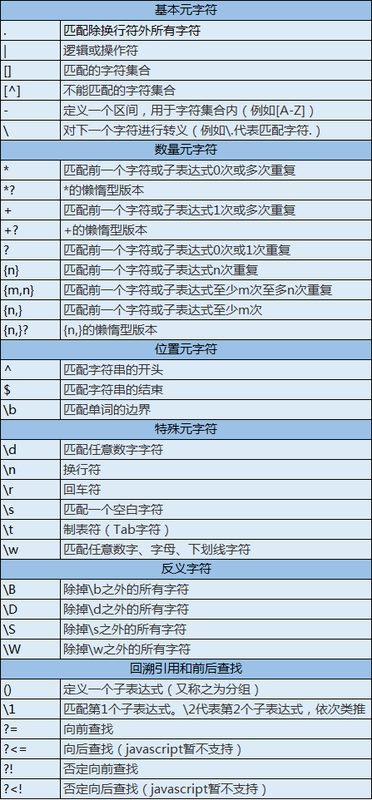
正則:<p>.*</p>
結(jié)果:
從匹配過(guò)程我們也可以發(fā)現(xiàn)對(duì)于 .* 這個(gè)表達(dá)式會(huì)嘗試盡可能多的匹配字符,直到匹配到盡頭,才嘗試匹配正則結(jié)尾的 </p> 。
懶惰模式:
與貪婪模式相反,盡可能匹配更少的字符。舉個(gè)栗子:
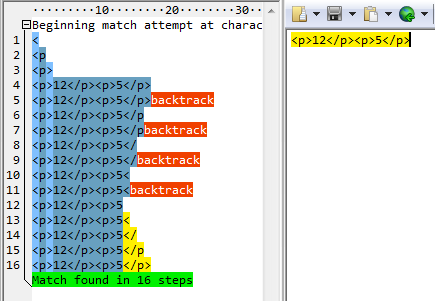
正則:<p>.*?</p>
結(jié)果:
從匹配過(guò)程我們也可以發(fā)現(xiàn),會(huì)優(yōu)先匹配正則結(jié)尾的 </p> ,在沒(méi)有滿足此結(jié)尾的情況下,才盡可能的去少匹配 .*? 這個(gè)表達(dá)式。
2)子表達(dá)式與反向引用
子表達(dá)式:
考慮這種場(chǎng)景,有些短語(yǔ)雖然由多個(gè)單詞構(gòu)成,但其實(shí)是一個(gè)整體,需要把它當(dāng)做一個(gè)獨(dú)立元素來(lái)使用,這種時(shí)候就需要使用子表達(dá)式。子表達(dá)式必須用()圓括號(hào)括起來(lái)。用途就是,可以精確的設(shè)定需要重復(fù)匹配的文本及重復(fù)次數(shù)。
反向引用:
它允許我們?cè)谡齽t中引用之前子表達(dá)式匹配到的結(jié)果。這有什么用?還是舉個(gè)栗子:
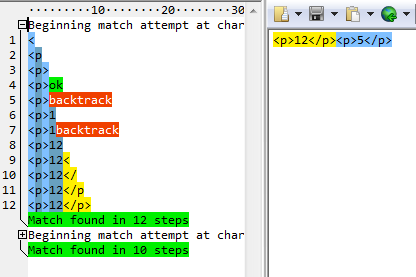
需求:匹配Html代碼片段中的h1~h6標(biāo)簽
正則:<h[1-6]>.*?</h[1-6]>(沒(méi)有使用反向引用)
結(jié)果:
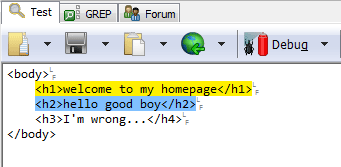
正則:<h([1-6])>.*?</h1>(使用了反向引用)
結(jié)果:
3)回溯
NFA引擎匹配能力強(qiáng)大,但是調(diào)教不好,有可能引發(fā)性能問(wèn)題,它有另一個(gè)叫法,叫做回溯失控。那么問(wèn)題來(lái)了,什么是回溯?
舉個(gè)栗子:
我們醒來(lái)的時(shí)候,突然發(fā)現(xiàn)被困在山洞里,這時(shí)候需要尋找出路,然而前方是一個(gè)岔路口。這個(gè)時(shí)候也并沒(méi)有任何依據(jù)可以告訴我們哪一條是出路,只有挨個(gè)嘗試,于是我們可以在岔路口做個(gè)標(biāo)記,以便萬(wàn)一選擇的這條路走不通,可以原路返回,直到遇見(jiàn)做了標(biāo)記的岔路口,以便繼續(xù)嘗試另一條路是不是出路。我們可以把每次嘗試失敗然后往回走,找到之前做標(biāo)記的地方的這個(gè)過(guò)程,稱(chēng)之為回溯。
很多情況下,依據(jù)你寫(xiě)的正則表達(dá)式,正則引擎或多或少都需要進(jìn)行這種2個(gè)或者多個(gè)選項(xiàng)的選擇。
4)斷言(環(huán)視)
先不做專(zhuān)業(yè)術(shù)語(yǔ)解釋?zhuān)葋?lái)看這么一個(gè)應(yīng)用場(chǎng)景
需求:匹配網(wǎng)頁(yè)里所有PC商品詳情頁(yè)地址所包含的sku信息
PC商品詳情頁(yè)地址格式://item.jd.com/xxxxxx.html
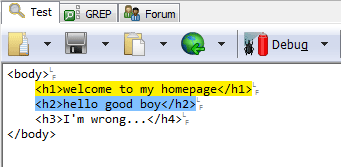
方法一:先正則匹配,再截?cái)嗪竺婀潭ǖ?html
正則:/d+\.html/g
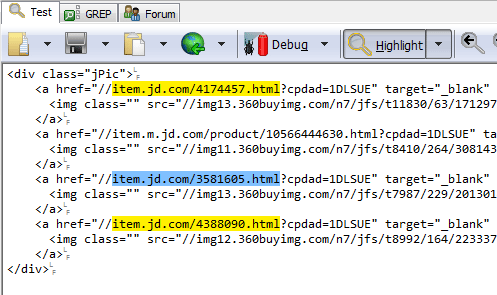
方法二:先正則匹配,再截?cái)嗲昂蠊潭ǖ淖址?/p>
正則:/item\.jd\.com/d+\.html/g
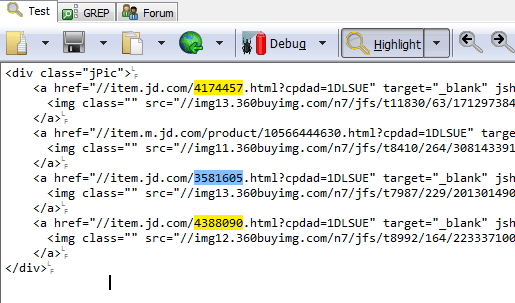
方法三:使用正向斷言和反向斷言,保證準(zhǔn)確性,同時(shí)只返回sku數(shù)字
正則:/(?<=item\.jd\.com/)d+(?=\.html)/g
斷言分類(lèi):正向肯定斷言、正向否定斷言、反向肯定斷言、反向否定斷言
需要注意的:Javascript不支持反向斷言,Java也是有限制的支持反向斷言
總而言之,言而總之,當(dāng)我們匹配目標(biāo)關(guān)鍵字的時(shí)候,同時(shí)期望對(duì)目標(biāo)關(guān)鍵字的前后進(jìn)行限制,并且又不期望這些限制會(huì)出現(xiàn)在匹配結(jié)果中。這時(shí)候,就可以使用斷言。
6. 正則優(yōu)化
1)怎樣才算是一個(gè)好正則
準(zhǔn)確性:只匹配期望的文本,排除掉不期望的文本
需求:匹配jshop手機(jī)活動(dòng)頁(yè)url的域名部分
jshop手機(jī)活動(dòng)頁(yè)URL格式://xxxx.jd.xxx/m/act/xxxxxx.html
正則:///(.*)(?=/m)/g
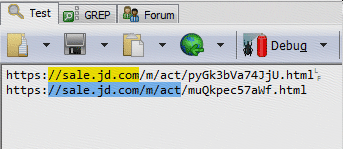
正則:///(1*)/g
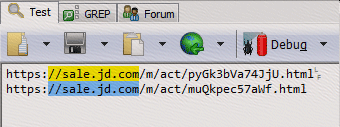
點(diǎn)評(píng):如果不需要匹配/,那就應(yīng)該在正則表達(dá)式中作出這樣的規(guī)定
匹配效率:很快返回匹配結(jié)果,如果不能匹配,盡可能短的時(shí)間報(bào)告匹配失敗
前面有提到過(guò),NFA引擎功能強(qiáng)大,但是寫(xiě)不好很容易引發(fā)效率問(wèn)題。其中太多的多選分支很容易成為效率殺手,因?yàn)槿魏味噙x分支只要匹配失敗,都會(huì)導(dǎo)致回溯。所以提高正則匹配效率的方法之一就是減少多選分支。
舉個(gè)栗子:
需求:匹配用戶輸入的一個(gè)字符串是否是一個(gè)4位IP里的一位,直白的說(shuō)就是匹配0~255
分析:可能有1位,也可能有2位,也可能有3位。3位的時(shí)候需要分開(kāi)判斷,當(dāng)***位是0或者1的時(shí)候,后面兩位可以是任意數(shù)字。當(dāng)***位是2的時(shí)候,第二位只能是0-5。并且當(dāng)?shù)诙皇?-4的時(shí)候,第三位可以是任意數(shù)字,但第二位是5的時(shí)候,第三位只能是0-5。
翻譯過(guò)來(lái)正則:/d|dd|[01]dd|2[0-4]d|25[0-5]/
合并同類(lèi)項(xiàng)后:/[01]?dd?|2[0-4]d|25[0-5]/
點(diǎn)評(píng):可以通過(guò)合并同類(lèi)項(xiàng)來(lái)減少多選分支。同時(shí)***個(gè)多選分支使用的是 dd? 而不是 d?d ,這樣如果根本不存在數(shù)字,NFA引擎會(huì)更快地報(bào)告失敗
易讀性
……
2)使用工具
分析正則表達(dá)式
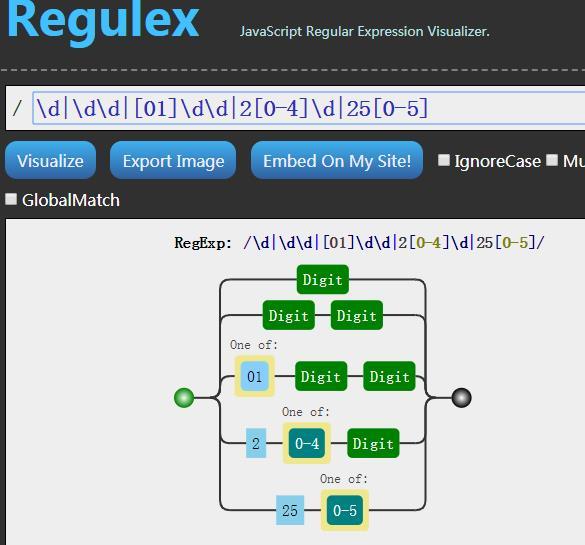
比如這個(gè)網(wǎng)站 https://jex.im/regulex
可以實(shí)現(xiàn)對(duì)復(fù)雜整個(gè)表達(dá)式的一個(gè)
測(cè)試正則表達(dá)式性能
比如這個(gè)貓頭鷹工具 RegexBuddy
可以用來(lái)測(cè)試正則表達(dá)式的匹配過(guò)程以及性能,包括各種語(yǔ)言下的正則特性支持情況。
3)優(yōu)化手段
優(yōu)化方針:減少回溯
1、減少或者合并多選分支
2、避免量詞的嵌套
3、占有優(yōu)先量詞。可以減少回溯,遺憾的是js不支持,但java支持。
舉個(gè)栗子:考慮到 /a+b/ 和 /a++b/ 兩個(gè)正則,測(cè)試的字符串 aaaa

/a+b/ 的匹配過(guò)程
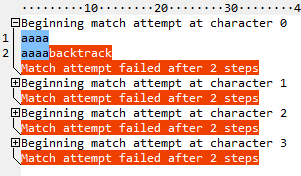
/a++b/ 的匹配過(guò)程
4、使用正確的邊界匹配器(^、$、b、B等),限定搜索字符串位置
5、盡量不使用通配符".";字符使用具體的元字符、字符類(lèi)(d、w、s等)(推薦)
6、使用正確的量詞(+、*、?、{n,m}),如果能夠限定長(zhǎng)度,匹配***
7、使用非捕獲型括號(hào)。如果不需要引用括號(hào)內(nèi)的文本,請(qǐng)使用非捕獲型括號(hào)(?:……),好處就是節(jié)省捕獲時(shí)間,同時(shí)減少回溯使用的狀態(tài)數(shù)量。

















