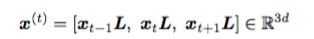深度學(xué)習(xí)也解決不掉語音識別問題
自從深度學(xué)習(xí)被引入語音識別后,誤字率迅速下降。不過,雖然你可能讀到過一些相關(guān)文章,但其實(shí)語言識別仍然還沒有達(dá)到人類水準(zhǔn)。語音識別已經(jīng)有了很多失敗的模式。而要將 ASR(自動語音識別)從僅在大部分時間適用于一部分人發(fā)展到在任何時候適用于任何人,唯一的方法就是承認(rèn)這些失敗并采取措施解決它們。
在交換臺通話(Switchboard conversational)語音識別標(biāo)準(zhǔn)測試中誤字率方面的進(jìn)展。這個數(shù)據(jù)集采集于 2000 年,它由四十個電話通話組成,這些通話分別屬于隨機(jī)的兩個以英語為母語的人。
僅僅基于交換臺通話的結(jié)果就聲稱已經(jīng)達(dá)到人類水準(zhǔn)的語音識別,就如同在某個天氣晴朗、沒有車流的小鎮(zhèn)成功測試自動駕駛就聲稱已經(jīng)達(dá)到人類駕駛水準(zhǔn)一樣。近期語音識別領(lǐng)域的發(fā)展確實(shí)非常震撼。但是,關(guān)于那些聲稱達(dá)到人類水準(zhǔn)的說法就太寬泛了。下面是一些還有待提升的領(lǐng)域。
口音和噪聲
語音識別中最明顯的一個缺陷就是對口音 [1] 和背景噪聲的處理。最直接的原因是大部分的訓(xùn)練數(shù)據(jù)都是高信噪比、美式口音的英語。比如在交換臺通話的訓(xùn)練和測試數(shù)據(jù)集中只有母語為英語的通話者(大多數(shù)為美國人),并且背景噪聲很少。
而僅憑訓(xùn)練數(shù)據(jù)自身是無法解決這個問題的。在許許多多的語言中又擁有著大量的方言和口音,我們不可能針對所有的情況收集到足夠的加注數(shù)據(jù)。單是為美式口音英語構(gòu)建一個高質(zhì)量的語音識別器就需要 5000 小時以上的轉(zhuǎn)錄音頻。
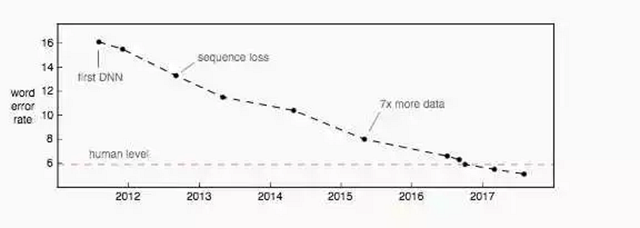
人工轉(zhuǎn)錄和百度的 Deep Speech 2 模型在各類語音中的比較 [2] 。注意人工在轉(zhuǎn)錄非美式口音時總表現(xiàn)得更差,這可能要?dú)w咎于轉(zhuǎn)錄員群體中的美國偏見。我更期望為各地區(qū)安排本土的轉(zhuǎn)錄員,讓地區(qū)口音的錯誤率更低。
關(guān)于背景噪聲,像在移動的汽車中信噪比(SRN)低至 -5dB 的情況并不罕見。在這樣的環(huán)境中人們并非難以交流,而另一方面,噪聲環(huán)境中語音識別能力卻急速下降。上圖中可以看到從高信噪比到低信噪比,人與模型只見的錯誤率差距急劇擴(kuò)大。
語義錯誤
通常語音識別系統(tǒng)的實(shí)際目標(biāo)并不是誤字率。我們更關(guān)心的是語義錯誤率,就是被誤解的那部分話語。
舉個語義錯誤的例子,比如某人說“let’s meet up Tuesday”,但語音識別預(yù)測為“let’s meet up today”。我們也可能在單詞錯誤的情況下保持語義正確,比如語音識別器漏掉了“up”而預(yù)測為“let’s meet Tuesday”,這樣話語的語義是不變的。
在使用誤字率作為指標(biāo)時必須要小心。舉一個最壞的例子,5% 的誤字率大概相當(dāng)于每 20 個單詞漏掉 1 個。如果每個語句有 20 個單詞(大約是英語語句平均值),那么語句錯誤率可能高達(dá) 100%。希望錯誤的單詞不會改變句子的語義,否則即便只有 5% 的誤字率也可能會導(dǎo)致每個句子都被誤讀。
將模型與人工進(jìn)行比較時的重點(diǎn)是查找錯誤的本質(zhì),而不僅僅是將誤字率作為一個決定性的數(shù)字。在我的經(jīng)歷里,人工轉(zhuǎn)錄會比語音識別更少產(chǎn)生極端語義錯誤。
最近微軟的研究人員將他們的人工級語音識別器的錯誤與人類進(jìn)行了比較 [3]。他們發(fā)現(xiàn)的一個差異是該模型比人更頻繁地混淆“uh”和“uh huh”。而這兩條術(shù)語的語義大不相同:“uh”只是個填充詞,而“uh huh”是一個反向確認(rèn)。這個模型和人出現(xiàn)了許多相同類型的錯誤。
單通道和多人會話
由于每個通話者都由單獨(dú)的麥克風(fēng)進(jìn)行記錄,所以交換臺通話任務(wù)也變得更加簡單。在同一個音頻流里沒有多個通話者的重疊。而另一方面,人類卻可以理解有時同時發(fā)言的多個會話者。
一個好的會話語音識別器必須能夠根據(jù)誰在說話對音頻進(jìn)行劃分(Diarisation),還應(yīng)該能弄清重疊的會話(聲源分離)。它不只在每個會話者嘴邊都有麥克風(fēng)的情況下可行,進(jìn)一步才能良好地應(yīng)對發(fā)生在任何地方的會話。
領(lǐng)域變化
口音和背景噪聲只是語音識別有待強(qiáng)化的兩個方面。這還有一些其他的:
- 來自聲環(huán)境變化的混響
- 硬件造成的偽影
- 音頻的編解碼器和壓縮偽影
- 采樣率
- 會話者的年齡
大多數(shù)人甚至都不會注意 mp3 和 wav 文件的區(qū)別。但在聲稱達(dá)到人類水準(zhǔn)的性能之前,語音識別還需要進(jìn)一步增強(qiáng)對文件來源多樣化的處理。
上下文
你會注意到像交換臺這樣人類水準(zhǔn)誤字率的基準(zhǔn)實(shí)際上是非常高的。如果你在跟一個朋友交流時,他每 20 個單詞就誤解其中一個,溝通會很艱難。
一個原因在于這樣的評估是上下文無關(guān)的。而實(shí)際生活中我們會使用許多其他的線索來輔助理解別人在說什么。列舉幾個人類使用上下文而語音識別器沒有的情況:
- 歷史會話和討論過的話題
- 說話人的視覺暗示,包括面部表情和嘴唇動作
- 關(guān)于會話者的先驗(yàn)知識
目前,Android 的語音識別器已經(jīng)掌握了你的聯(lián)系人列表,它能識別出你朋友的名字 [4]。地圖產(chǎn)品的語音搜索則通過地理定位縮小你想要導(dǎo)航的興趣點(diǎn)范圍 [5]。
當(dāng)加入這些信號時,ASR 系統(tǒng)肯定會有所提高。不過,關(guān)于可用的上下文類型以及如何使用它,我們才剛剛觸及皮毛。
部署
在會話語音方面的最新進(jìn)展都還不能展開部署。如果要解決新語音算法的部署,需要考慮延遲和計(jì)算量這兩個方面。這兩者之間是有關(guān)聯(lián)的,算法計(jì)算量的增加通常都導(dǎo)致延遲增加。不過簡單起見,我將它們分開討論。
延遲:關(guān)于延遲,這里我指的是用戶說完到轉(zhuǎn)錄完成的時間。低延遲是 ASR 中一個普遍的產(chǎn)品約束,它明顯影響到用戶體驗(yàn)。對于 ASR 系統(tǒng)來說,10 毫秒的延遲要求并不少見。這聽起來可能有點(diǎn)極端,但是請記住文字轉(zhuǎn)錄通常只是一系列復(fù)雜計(jì)算的第一步。例如在語音搜索中,實(shí)際的網(wǎng)絡(luò)搜索只能在語音識別之后進(jìn)行。
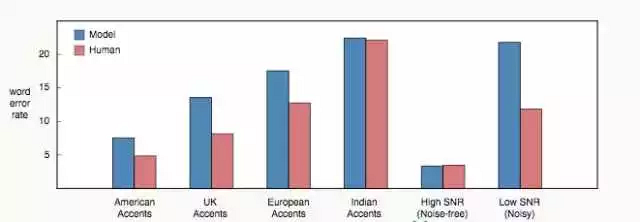
一個關(guān)于延遲方面難以改進(jìn)的例子是雙向循環(huán)層。當(dāng)前所有最先進(jìn)的會話語音識別都在使用它。其問題在于我們無法在第一層計(jì)算任何東西,而必須要等到用戶說完。所以這里的延遲跟話語時長有關(guān)。
上圖:只有一個前向循環(huán),可以在轉(zhuǎn)錄時進(jìn)行計(jì)算。
下圖:在雙向循環(huán)的情況下,必須要等待全部話語說完才能計(jì)算轉(zhuǎn)錄。
在語音識別中如何有效結(jié)合未來信息仍然是一個開放問題。
計(jì)算:轉(zhuǎn)錄語音所需的計(jì)算能力是一個經(jīng)濟(jì)約束。我們必須考慮語音識別器每次精度改進(jìn)的性價比。如果改進(jìn)達(dá)不到一個經(jīng)濟(jì)門檻,那它就無法部署。
一個從未部署的持續(xù)改進(jìn)的典型案例就是集成。1% 或者 2% 的誤差減少很少值得 2-8 倍的計(jì)算量增長。新一代 RNN 語言模型也屬于這一類,因?yàn)樗鼈冇迷谑阉鲿r代價昂貴,不過預(yù)計(jì)未來會有所改變。
需要說明的是,我并不認(rèn)為研究如何在巨大計(jì)算成本上提高精度是無用的。我們已經(jīng)看到過“先慢而準(zhǔn),然后提速”模式的成功。要提的一點(diǎn)是在改進(jìn)到足夠快之前,它還是不可用的。
未來五年
語音識別領(lǐng)域仍然存在許多開放性和挑戰(zhàn)性的問題:
- 在新地區(qū)、口音、遠(yuǎn)場和低信噪比語音方面的能力擴(kuò)展
- 在識別過程中引入更多的上下文
- Diarisation 和聲源分離
- 評價語音識別的語義錯誤率和創(chuàng)新方法
- 超低延遲和高效推理
我期待著今后 5 年在以上以及其他方面取得的進(jìn)展。