Spring Cloud Hystrix的請(qǐng)求合并
通常微服務(wù)架構(gòu)中的依賴通過(guò)遠(yuǎn)程調(diào)用實(shí)現(xiàn),而遠(yuǎn)程調(diào)用中最常見(jiàn)的問(wèn)題就是通信消耗與連接數(shù)占用。在高并發(fā)的情況之下,因通信次數(shù)的增加,總的通信時(shí)間消耗將會(huì)變的不那么理想。同時(shí),因?yàn)閷?duì)依賴服務(wù)的線程池資源有限,將出現(xiàn)排隊(duì)等待與響應(yīng)延遲的情況。為了優(yōu)化這兩個(gè)問(wèn)題,Hystrix提供了HystrixCollapser來(lái)實(shí)現(xiàn)請(qǐng)求的合并,以減少通信消耗和線程數(shù)的占用。
HystrixCollapser實(shí)現(xiàn)了在HystrixCommand之前放置一個(gè)合并處理器,它將處于一個(gè)很短時(shí)間窗(默認(rèn)10毫秒)內(nèi)對(duì)同一依賴服務(wù)的多個(gè)請(qǐng)求進(jìn)行整合并以批量方式發(fā)起請(qǐng)求的功能(服務(wù)提供方也需要提供相應(yīng)的批量實(shí)現(xiàn)接口)。通過(guò)HystrixCollapser的封裝,開(kāi)發(fā)者不需要去關(guān)注線程合并的細(xì)節(jié)過(guò)程,只需要關(guān)注批量化服務(wù)和處理。下面我們從HystrixCollapser的使用實(shí)例,對(duì)其合并請(qǐng)求的過(guò)程一探究竟。
Hystrix的請(qǐng)求合并示例
- public abstract class HystrixCollapser<BatchReturnType, ResponseType, RequestArgumentType> implements
- HystrixExecutable<ResponseType>, HystrixObservable<ResponseType> {
- ...
- public abstract RequestArgumentType getRequestArgument();
- protected abstract HystrixCommand<BatchReturnType> createCommand(Collection<CollapsedRequest<ResponseType, RequestArgumentType>> requests);
- protected abstract void mapResponseToRequests(BatchReturnType batchResponse, Collection<CollapsedRequest<ResponseType, RequestArgumentType>> requests);
- ...
- }
從HystrixCollapser抽象類的定義中可以看到,它指定了三個(gè)不同的類型:
- BatchReturnType:合并后批量請(qǐng)求的返回類型
- ResponseType:?jiǎn)蝹€(gè)請(qǐng)求返回的類型
- RequestArgumentType:請(qǐng)求參數(shù)類型
而對(duì)于這三個(gè)類型的使用可以在它的三個(gè)抽象方法中看到:
- RequestArgumentType getRequestArgument():該函數(shù)用來(lái)定義獲取請(qǐng)求參數(shù)的方法。
- HystrixCommand<BatchReturnType> createCommand(Collection<CollapsedRequest<ResponseType, RequestArgumentType>> requests):合并請(qǐng)求產(chǎn)生批量命令的具體實(shí)現(xiàn)方法。
- mapResponseToRequests(BatchReturnType batchResponse, Collection<CollapsedRequest<ResponseType, RequestArgumentType>> requests):批量命令結(jié)果返回后的處理,這里需要實(shí)現(xiàn)將批量結(jié)果拆分并傳遞給合并前的各個(gè)原子請(qǐng)求命令的邏輯。
接下來(lái),我們通過(guò)一個(gè)簡(jiǎn)單的示例來(lái)直觀的理解實(shí)現(xiàn)請(qǐng)求合并的過(guò)程。
假設(shè),當(dāng)前微服務(wù)USER-SERVICE提供了兩個(gè)獲取User的接口:
- /users/{id}:根據(jù)id返回User對(duì)象的GET請(qǐng)求接口。
- /users?ids={ids}:根據(jù)ids參數(shù)返回User對(duì)象列表的GET請(qǐng)求接口,其中ids為以逗號(hào)分割的id集合。
而在服務(wù)消費(fèi)端,為這兩個(gè)遠(yuǎn)程接口已經(jīng)通過(guò)RestTemplate實(shí)現(xiàn)了簡(jiǎn)單的調(diào)用,具體如下:
- @Service
- public class UserServiceImpl implements UserService {
- @Autowired
- private RestTemplate restTemplate;
- @Override
- public User find(Long id) {
- return restTemplate.getForObject("http://USER-SERVICE/users/{1}", User.class, id);
- }
- @Override
- public List<User> findAll(List<Long> ids) {
- return restTemplate.getForObject("http://USER-SERVICE/users?ids={1}", List.class, StringUtils.join(ids, ","));
- }
- }
接著,我們來(lái)實(shí)現(xiàn)將短時(shí)間內(nèi)多個(gè)獲取單一User對(duì)象的請(qǐng)求命令進(jìn)行合并的實(shí)現(xiàn):
- ***步:為請(qǐng)求合并的實(shí)現(xiàn)準(zhǔn)備一個(gè)批量請(qǐng)求命令的實(shí)現(xiàn),具體如下:
- public class UserBatchCommand extends HystrixCommand<List<User>> {
- UserService userService;
- List<Long> userIds;
- public UserBatchCommand(UserService userService, List<Long> userIds) {
- super(Setter.withGroupKey(asKey("userServiceCommand")));
- this.userIds = userIds;
- this.userService = userService;
- }
- @Override
- protected List<User> run() throws Exception {
- return userService.findAll(userIds);
- }
- }
批量請(qǐng)求命令實(shí)際上就是一個(gè)簡(jiǎn)單的HystrixCommand實(shí)現(xiàn),從上面的實(shí)現(xiàn)中可以看到它通過(guò)調(diào)用userService.findAll方法來(lái)訪問(wèn)/users?ids={ids}接口以返回User的列表結(jié)果。
- 第二步,通過(guò)繼承HystrixCollapser實(shí)現(xiàn)請(qǐng)求合并器:
- public class UserCollapseCommand extends HystrixCollapser<List<User>, User, Long> {
- private UserService userService;
- private Long userId;
- public UserCollapseCommand(UserService userService, Long userId) {
- super(Setter.withCollapserKey(HystrixCollapserKey.Factory.asKey("userCollapseCommand")).andCollapserPropertiesDefaults(
- HystrixCollapserProperties.Setter().withTimerDelayInMilliseconds(100)));
- this.userService = userService;
- this.userId = userId;
- }
- @Override
- public Long getRequestArgument() {
- return userId;
- }
- @Override
- protected HystrixCommand<List<User>> createCommand(Collection<CollapsedRequest<User, Long>> collapsedRequests) {
- List<Long> userIds = new ArrayList<>(collapsedRequests.size());
- userIds.addAll(collapsedRequests.stream().map(CollapsedRequest::getArgument).collect(Collectors.toList()));
- return new UserBatchCommand(userService, userIds);
- }
- @Override
- protected void mapResponseToRequests(List<User> batchResponse, Collection<CollapsedRequest<User, Long>> collapsedRequests) {
- int count = 0;
- for (CollapsedRequest<User, Long> collapsedRequest : collapsedRequests) {
- User user = batchResponse.get(count++);
- collapsedRequest.setResponse(user);
- }
- }
- }
在上面的構(gòu)造函數(shù)中,我們?yōu)檎?qǐng)求合并器設(shè)置了時(shí)間延遲屬性,合并器會(huì)在該時(shí)間窗內(nèi)收集獲取單個(gè)User的請(qǐng)求并在時(shí)間窗結(jié)束時(shí)進(jìn)行合并組裝成單個(gè)批量請(qǐng)求。下面getRequestArgument方法返回給定的單個(gè)請(qǐng)求參數(shù)userId,而createCommand和mapResponseToRequests是請(qǐng)求合并器的兩個(gè)核心:
- createCommand:該方法的collapsedRequests參數(shù)中保存了延遲時(shí)間窗中收集到的所有獲取單個(gè)User的請(qǐng)求。通過(guò)獲取這些請(qǐng)求的參數(shù)來(lái)組織上面我們準(zhǔn)備的批量請(qǐng)求命令
- UserBatchCommand實(shí)例。
mapResponseToRequests:在批量命令UserBatchCommand實(shí)例被觸發(fā)執(zhí)行完成之后,該方法開(kāi)始執(zhí)行,其中batchResponse參數(shù)保存了createCommand中組織的批量請(qǐng)求命令的返回結(jié)果,而collapsedRequests參數(shù)則代表了每個(gè)被合并的請(qǐng)求。在這里我們通過(guò)遍歷批量結(jié)果batchResponse對(duì)象,為collapsedRequests中每個(gè)合并前的單個(gè)請(qǐng)求設(shè)置返回結(jié)果,以此完成批量結(jié)果到單個(gè)請(qǐng)求結(jié)果的轉(zhuǎn)換。
請(qǐng)求合并的原理分析
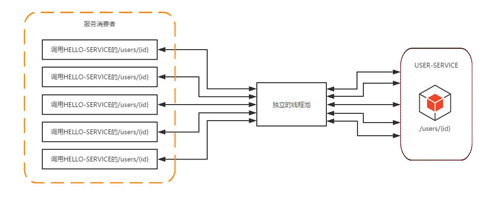
下圖展示了在未使用HystrixCollapser請(qǐng)求合并器之前的線程使用情況。可以看到當(dāng)服務(wù)消費(fèi)者同時(shí)對(duì)USER-SERVICE的/users/{id}接口發(fā)起了五個(gè)請(qǐng)求時(shí),會(huì)向該依賴服務(wù)的獨(dú)立線程池中申請(qǐng)五個(gè)線程來(lái)完成各自的請(qǐng)求操作。
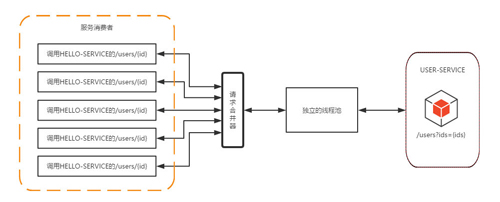
而在使用了HystrixCollapser請(qǐng)求合并器之后,相同情況下的線程占用如下圖所示。由于同一時(shí)間發(fā)生的五個(gè)請(qǐng)求處于請(qǐng)求合并器的一個(gè)時(shí)間窗內(nèi),這些發(fā)向/users/{id}接口的請(qǐng)求被請(qǐng)求合并器攔截下來(lái),并在合并器中進(jìn)行組合,然后將這些請(qǐng)求合并成一個(gè)請(qǐng)求發(fā)向USER-SERVICE的批量接口/users?ids={ids},在獲取到批量請(qǐng)求結(jié)果之后,通過(guò)請(qǐng)求合并器再將批量結(jié)果拆分并分配給每個(gè)被合并的請(qǐng)求。從圖中我們可以看到以來(lái),通過(guò)使用請(qǐng)求合并器有效地減少了對(duì)線程池中資源的占用。所以在資源有效并且在短時(shí)間內(nèi)會(huì)產(chǎn)生高并發(fā)請(qǐng)求的時(shí)候,為避免連接不夠用而引起的延遲可以考慮使用請(qǐng)求合并器的方式來(lái)處理和優(yōu)化。
使用注解實(shí)現(xiàn)請(qǐng)求合并器
在快速入門(mén)的例子中,我們使用@HystrixCommand注解優(yōu)雅地實(shí)現(xiàn)了HystrixCommand的定義,那么對(duì)于請(qǐng)求合并器是否也可以通過(guò)注解來(lái)定義呢?答案是肯定!
以上面實(shí)現(xiàn)的請(qǐng)求合并器為例,也可以通過(guò)如下方式實(shí)現(xiàn):
- @Service
- public class UserService {
- @Autowired
- private RestTemplate restTemplate;
- @HystrixCollapser(batchMethod = "findAll", collapserProperties = {
- @HystrixProperty(name="timerDelayInMilliseconds", value = "100")
- })
- public User find(Long id) {
- return null;
- }
- @HystrixCommand
- public List<User> findAll(List<Long> ids) {
- return restTemplate.getForObject("http://USER-SERVICE/users?ids={1}", List.class, StringUtils.join(ids, ","));
- }
- }
@HystrixCommand我們之前已經(jīng)介紹過(guò)了,可以看到這里通過(guò)它定義了兩個(gè)Hystrix命令,一個(gè)用于請(qǐng)求/users/{id}接口,一個(gè)用于請(qǐng)求/users?ids={ids}接口。而在請(qǐng)求/users/{id}接口的方法上通過(guò)@HystrixCollapser注解為其創(chuàng)建了合并請(qǐng)求器,通過(guò)batchMethod屬性指定了批量請(qǐng)求的實(shí)現(xiàn)方法為findAll方法(即:請(qǐng)求/users?ids={ids}接口的命令),同時(shí)通過(guò)collapserProperties屬性為合并請(qǐng)求器設(shè)置相關(guān)屬性,這里使用@HystrixProperty(name="timerDelayInMilliseconds", value = "100")將合并時(shí)間窗設(shè)置為100毫秒。這樣通過(guò)@HystrixCollapser注解簡(jiǎn)單而又優(yōu)雅地實(shí)現(xiàn)了在/users/{id}依賴服務(wù)之前設(shè)置了一個(gè)批量請(qǐng)求合并器。
請(qǐng)求合并的額外開(kāi)銷
雖然通過(guò)請(qǐng)求合并可以減少請(qǐng)求的數(shù)量以緩解依賴服務(wù)線程池的資源,但是在使用的時(shí)候也需要注意它所帶來(lái)的額外開(kāi)銷:用于請(qǐng)求合并的延遲時(shí)間窗會(huì)使得依賴服務(wù)的請(qǐng)求延遲增高。比如:某個(gè)請(qǐng)求在不通過(guò)請(qǐng)求合并器訪問(wèn)的平均耗時(shí)為5ms,請(qǐng)求合并的延遲時(shí)間窗為10ms(默認(rèn)值),那么當(dāng)該請(qǐng)求的設(shè)置了請(qǐng)求合并器之后,最壞情況下(在延遲時(shí)間窗結(jié)束時(shí)才發(fā)起請(qǐng)求)該請(qǐng)求需要15ms才能完成。
由于請(qǐng)求合并器的延遲時(shí)間窗會(huì)帶來(lái)額外開(kāi)銷,所以我們是否使用請(qǐng)求合并器需要根據(jù)依賴服務(wù)調(diào)用的實(shí)際情況來(lái)選擇,主要考慮下面兩個(gè)方面:
- 請(qǐng)求命令本身的延遲。如果依賴服務(wù)的請(qǐng)求命令本身是一個(gè)高延遲的命令,那么可以使用請(qǐng)求合并器,因?yàn)檠舆t時(shí)間窗的時(shí)間消耗就顯得莫不足道了。
- 延遲時(shí)間窗內(nèi)的并發(fā)量。如果一個(gè)時(shí)間窗內(nèi)只有1-2個(gè)請(qǐng)求,那么這樣的依賴服務(wù)不適合使用請(qǐng)求合并器,這種情況下不但不能提升系統(tǒng)性能,反而會(huì)成為系統(tǒng)瓶頸,因?yàn)槊總€(gè)請(qǐng)求都需要多消耗一個(gè)時(shí)間窗才響應(yīng)。相反,如果一個(gè)時(shí)間窗內(nèi)具有很高的并發(fā)量,并且服務(wù)提供方也實(shí)現(xiàn)了批量處理接口,那么使用請(qǐng)求合并器可以有效的減少網(wǎng)絡(luò)連接數(shù)量并極大地提升系統(tǒng)吞吐量,此時(shí)延遲時(shí)間窗所增加的消耗就可以忽略不計(jì)了。
【本文為51CTO專欄作者“翟永超”的原創(chuàng)稿件,轉(zhuǎn)載請(qǐng)通過(guò)51CTO聯(lián)系作者獲取授權(quán)】