如何用TensorFlow在安卓設備上實現深度學習推斷
對于個人和公司來說,存在許多狀況是更希望在本地設備上做深度學習推斷的:想象一下當你在旅行途中沒有可靠的互聯網鏈接時,或是要處理傳輸數據到云服務的隱私問題和延遲問題時。邊緣計算(Edge computing)是一種在物理上靠近數據生成的位置從而對數據進行處理和分析的方法,為解決這些問題提供了方案。
以「Ok Google」這個功能為例:用一名用戶的聲音來訓練「Ok Google」,他的手機在接收到這個關鍵詞的時候就會被喚醒。這種小型關鍵詞檢測(small-footprint keyword-spotting,KWS)推斷通常在本地設備上運行,所以你不必擔心服務提供商隨時監聽你的聲音。而云服務只在你發出指令后才啟動。類似的概念可以擴展到智能家用電器或其他物聯網設備上的應用,在這些應用中我們需要不依靠互聯網進行免提語音控制。
更重要的是,邊緣計算不僅為物聯網世界帶來了人工智能,還提供了許多其他的可能性和好處。例如,我們可以在本地設備上將圖像或語音數據預處理為壓縮表示,然后將其發送到云。這種方法解決了隱私和延遲問題。
在 Insight 任職期間,我用 TensorFlow 在安卓上部署了一個預訓練的 WaveNet 模型。我的目標是探索將深度學習模型部署到設備上并使之工作的工程挑戰!這篇文章簡要介紹了如何用 TensorFlow 在安卓上構建一個通用的語音到文本識別應用程序。

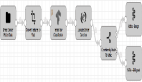
圖 1. 流程概述。將 WaveNet 安裝到安卓的三個步驟。
開發環境信息:
- Pixel, cpu type: ARM64
- Android 7.1.1
- Android NDK 15.2
- Android gradle plugin 2.3.0
- TensorFlow 1.3.0
- bazel 0.5.4-homebrew
詳細教程和實現:https://github.com/chiachunfu/speech
***步:模型壓縮
為了將深度學習模型部署到移動/嵌入式設備上,我們應該致力于減少模型的內存占用,縮短推斷時間,減少耗電。有幾種方法可以實現這些要求,如量化、權重剪枝或將大模型提煉成小模型。
在這個項目中,我使用了 TensorFlow 中的量化工具來進行模型壓縮。目前我只使用權重量化來減小模型大小,因為根據 Mac 上的測試結果,完整 8 位轉換沒有提供額外的好處,比如縮短推斷時間。(由于 requant_range 中的錯誤,無法在 Pixel 上運行完整的 8 位模型)。由于 8 位量化工具不適合 CPU,時間甚至翻了一倍。如果你有興趣了解更多關于量化的實用建議,可以閱讀 Pete Warden 這篇很棒的文章(https://petewarden.com/2017/06/22/what-ive-learned-about-neural-network-quantization/)。
對模型進行權重量化:
- 將模型寫入協議緩沖區文件。
- 從源安裝和配置 TensorFlow(https://www.tensorflow.org/install/install_sources)。
- 在 TensorFlow 目錄下運行下列命令行:
- bazel build tensorflow/tools/graph_transforms:transform_graph
- bazel-bin/tensorflow/tools/graph_transforms/transform_graph \
- --in_graph=/your/.pb/file \
- --outputs="output_node_name" \
- --out_graph=/the/quantized/.pb/file \
- --transforms='quantize_weights'
以我的項目為例,在量化權重后,預訓練的 WaveNet 模型的大小從 15.5Mb 下降到了 4.0Mb。現在可以將這個模型文件移動到安卓項目中的「assets」文件夾。
第二步:適用于安卓的 TensorFlow 庫
要用 TensorFlow 構建安卓應用程序,我推薦從 TensorFlow Android Demo開始。在我的項目中,我把 TF speech example 作為模板。這個示例中的 gradle 文件幫助我們構建和編譯安卓的 TF 庫。但是,這個預構建的 TF 庫可能不包括模型所有必要的 ops。我們需要想清楚 WaveNet 中需要的全部 ops,并將它們編譯成適合安卓 apk 的.so 文件。為了找到 ops 的完整列表,我首先使用 tf.train.write_graph 輸出圖的詳細信息。然后在終端中運行下列命令:
- grep "op: " PATH/TO/mygraph.txt | sort | uniq | sed -E 's/^.+"(.+)".?$/\1/g'
接著,編輯/tensorflow/tensorflow/core/kernels/里的 BUILD 文件,在 Android libraries section 中的「android_extended_ops_group1」或「android_extended_ops_group2」里添加缺失的 ops。我們也可以刪除不必要的 ops,使 .so 文件變得更小。現在,運行下列命令:
- bazel build -c opt //tensorflow/contrib/android:libtensorflow_inference.so \
- --crosstool_top=//external:android/crosstool \
- --host_crosstool_top=@bazel_tools//tools/cpp:toolchain \
- --cpu=armeabi-v7a
你將在這里找到 libtensorflow_inference.so 文件:
- bazel-bin/tensorflow/contrib/android/libtensorflow_inference.so
除了 .so 文件之外,我們還需要一個 JAR 文件。運行:
- bazel build
- //tensorflow/contrib/android:android_tensorflow_inference_java
你將在這里找到該文件:
- bazel-bin/tensorflow/contrib/android/libandroid_tensorflow_inference_java.jar
現在,可以將 .so 和 .jar 文件一起移到你的安卓項目中的「libs」文件夾。
第三步:在安卓上的數據預處理
***,讓我們將輸入數據處理成模型訓練所需格式。對于音頻系統來說,原始的語音波被轉換成梅爾頻率倒譜系數(MFCC)來模擬人耳感知聲音的方式。TensorFlow 有一個音頻 op,可以執行該特征提取。然而,事實證明,實現這種轉換存在一些變體。如圖 2 所示,來自 TensorFlow audio op 的 MFCC 不同于 librosa 提供的 MFCC。librosa 是一個被預訓練的 WaveNet 作者們用來轉換訓練數據的 Python 庫。
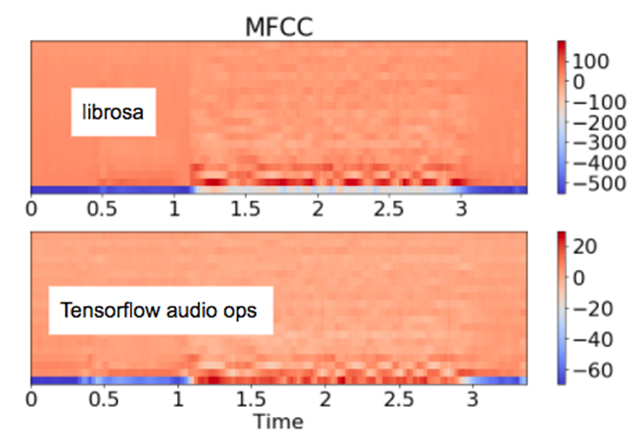
圖 2. 來自 librosa 和 TensorFlow audio ops 的 MFCC 處在不同的刻度范圍。
如果您正在訓練自己的模型或重訓練一個預先訓練好的模型,那么在處理訓練數據時,一定要考慮設備上的數據通道。最終,我在 Java 中重寫了 librosa MFCC 來處理轉換問題。
結果
圖 3 展示了 app 的截圖和示例。由于模型中沒有語言模型,而且識別僅在字符級,因此句子中出現了一些拼寫錯誤。雖然沒有經過嚴格的測試,但在量化之后,我確實發現準確率略有下降,以及整個系統對周圍的噪聲很敏感。
圖 3. App 中兩個示例的截圖。
下表所示推斷時間是對 5 秒音頻的 10 次測試的平均值。推斷時間在兩個平臺上都略有增加,而不是減少,因為權重量化有助于縮小文件大小,但不太能優化推斷時間或耗電情況。
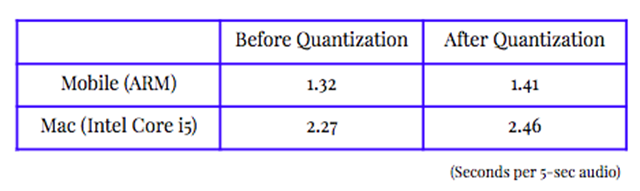
表 1. 權重量化前后的推斷時間。測試環境是我的 Pixel 手機和 Macbook air。
接下來做些什么?
有兩件重要的事情可以讓這個項目更進一步,也可以為社區提供額外的教程和演練,以便在邊緣設備上部署一個現實語音識別系統。
- 提高語音識別性能:添加拼寫校正的語言模型和噪聲下采樣模型,以降低周圍噪聲的影響。
- 改善推斷時間和耗電情況:用 NEON 或其他架構進行低層次優化,用 gemmlowp 進行低精度矩陣計算。