挨踢部落直播課堂第六期:精益化數據分析—如何讓你的企業具有BAT一樣的分析能力
原創每一個企業建設大數據平臺時都希望建設的大而全,但是實踐證明可持續的大數據平臺都通過精益化數據分析理論逐步建立而成的。精益化數據分析的理論就是通過建立最小的商業閉環,逐步驗證和擴大數據分析平臺最終實現與BAT一樣的數據分析能力。其中,核心技術、業務分析目標在不斷成長都會遇到各種挑戰。今天,易觀CTO郭煒老師分享了企業建設大數據平臺中精益化建設思路以及建設月活5.2億大數據分析平臺成長歷程。
主要分享內容如下
一、精益化數據分析
二、常見的精益化數據分析場景
三、大數據技術框架迭代與擴展
四、用戶精益化分析到大數據平臺
各位好,我是易觀CTO郭煒,非常高興今天能夠在這里和大家做一個分享。希望能讓大家有所收獲。 我今天演講的題目是精益化數據分析——如何讓你的企業具有BAT一樣的分析能力。
? ?
?
先簡單介紹一下我自己:
? ?
?
郭煒先生2016年加入易觀,擔任易觀CTO,構建易觀技術團隊完成易觀大數據采集、平臺、數據挖掘等技術架構與體系,從無到有完成易觀混合云搭建、易觀SDK升級并發布易觀秒算實時計算平臺,目前易觀大數據平臺日處理數據量30T,252億條,月活用戶5.2億。
郭煒先生畢業于北京大學,加入易觀之前,曾任聯想研究院大數據總監,萬達電商數據部總經理,并曾在中金、IBM、Teradata公司擔任大數據方向重要崗位,對大數據前沿領域研究,包括視頻、智能WIFI等大數據軟硬數據一體技術有獨特的見解。
? ?
?
一、精益化數據分析
先說說,精益化數據分析思路的由來——精益創業
精益創業(Lean Startup)由硅谷創業家Eric Rise2012年8月在其著精益創業作《精益創業》一書中首度提出。
三個重點:最小可用品(MVP)、客戶反饋、快速迭代。
精益化數據分析是什么呢?
精益化分析的核心就是以業務最小閉環開始,每次形成業務效果的閉環,達到業務目標,再擴展下一步的大數據分析內容,或者建立相關的系統,或者建立相關的平臺。
? 最小化可行產品進行優化,而不是對其設定硬指標 v.s. 決策層說“我們要建設大數據項目“
? 與最終客戶與業務保持同步 v.s. “先有平臺再加業務”
? 業務閉環,并形成針對大數據的數據分析 v.s. “管理層看到了Dashboard”
? 增速/轉型/創新 ——***的挑戰,在于企業文化的改變
這幾點,一定是優先選擇前者,我10幾年的數據從業經歷而言,不要漫無目的為了大數據而大數據,這樣大數據平臺即使建立起來了也不能長久,一定是有策略的建立精益化化大數據平臺。
重要事情重復三遍,不要漫無目的為了大數據而大數據,這樣大數據平臺即使建立起來了也不能長久,一定是有策略的建立精益化化大數據平臺。
不要漫無目的為了大數據二大數據,這樣大數據平臺即使建立起來了也不能長久,一定是有策略的建立精益化化大數據平臺。
? ?
?
? ?
?
不要漫無目的為了大數據而大數據,這樣大數據平臺即使建立起來了也不能長久,一定是有策略的建立精益化化大數據平臺。那么怎么建設呢,我個人建議先從互聯網/移動互聯網用戶運營開始,因為這塊在近些年來痛點比較明顯,業務閉環也比較容易尋找。
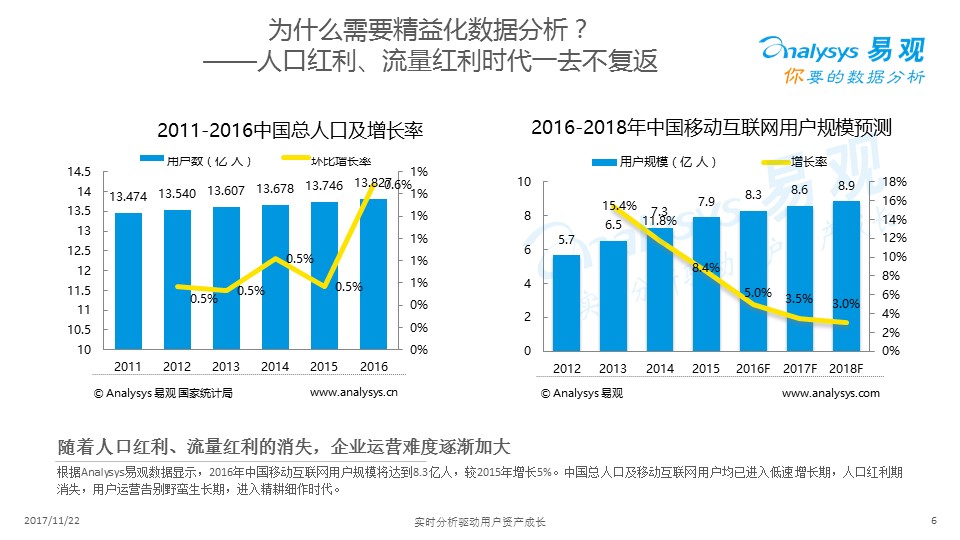
大家知道,互聯網進入下半場以后,我們過去做一個APP不用做什么活動就能心大量新增用戶的日子一去不復返了,現在哪怕精準拉新的效果也不一定好,所以,目前對現有的這些用戶如何進一步運營成為現在主要的業務需求。
? ?
?
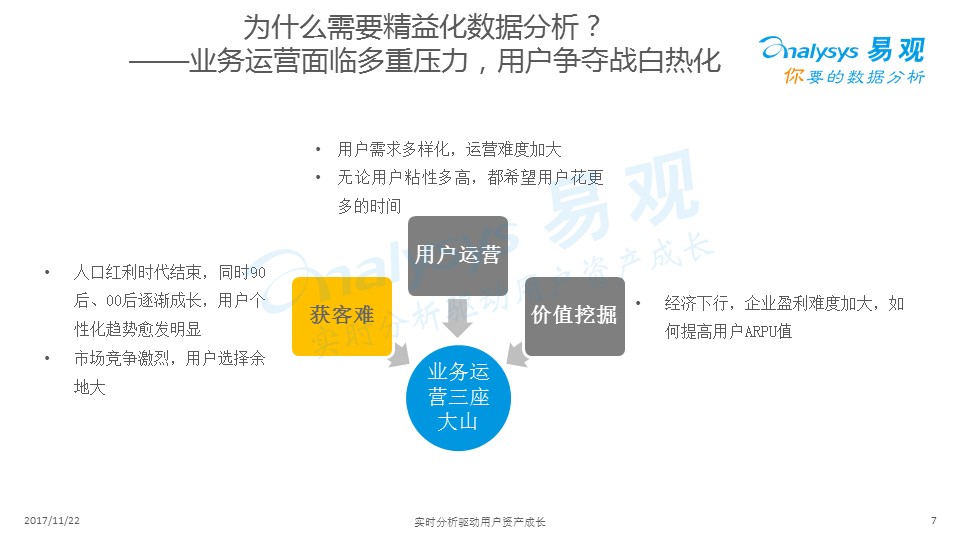
大家可以看到,中國人口的增長,已經不是像每年百分之幾的增長,而是被每年零點幾在增長,同樣移動互聯網的用戶的增長也日漸趨緩,所以現在不是看怎么去拿新,而是看我們怎樣對留住用戶提高用戶的收入。
? ?
?
獲客難、留不住用戶、挖不到價值是現在互聯網運營人員身上的三座大山。
?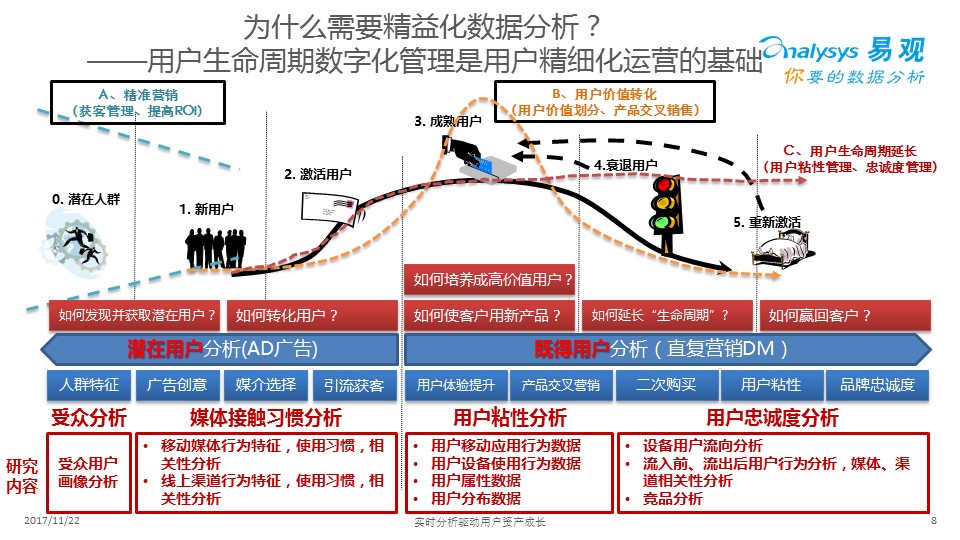 ?
?
精益化數據分析下的用戶全生命周期管理就是一個重要的抓手:在獲客的時候精準營銷,提高渠道的ROI,在成熟用戶里提高ARPU,在用戶離開的時候,去用各種各樣的條件挽留他。這就需要對用戶的行為、屬性、渠道特征、忠誠度分析做各種各樣的分析。
?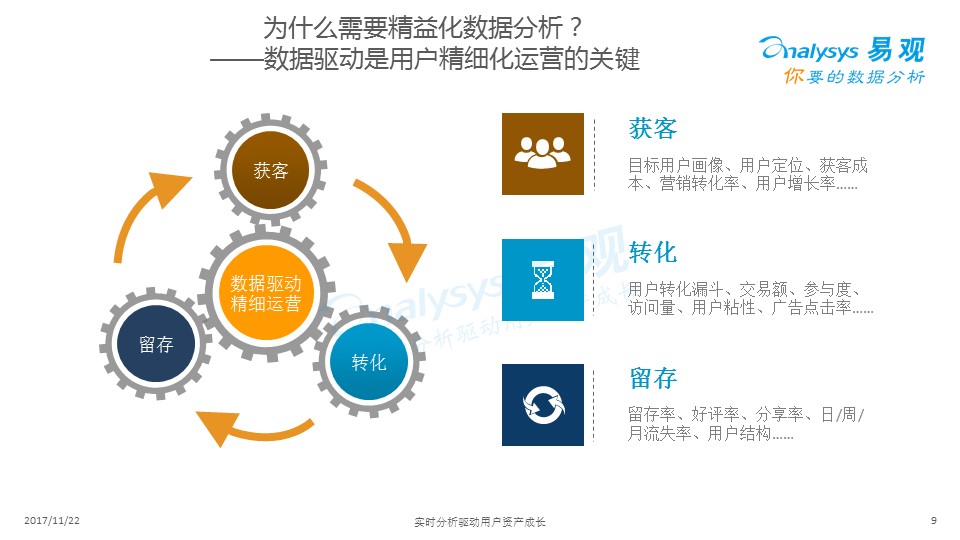 ?
?
其中、獲客、留存、轉化就是精益化數據運營的主要需求,圖中列舉了各種需要做的數據分析的指標供大家參考。
?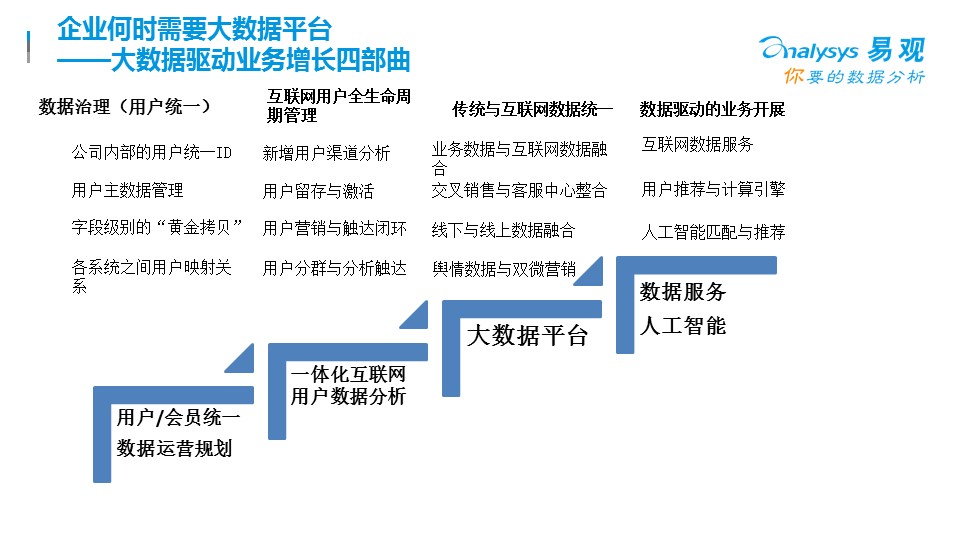 ?
?
大數據驅動業務增長節奏怎樣把控?我建議分四步走,先對用戶、會員做內部的統一(這部分建議是企業自己來梳理完成,各種各樣的數據只有企業自己最清晰);第二部,自己建立/外部采購互聯網用戶生命周期管理的平臺——這塊可以最快的看到效果,符合精益化思路;第三部,建立企業大數據平臺,將互聯網與內部系統打通;第四部,可以利用自己的數字資產建立數據服務或者進一步升級企業的人工智能平臺。
二、常見的精益化數據分析場景
下面分享一下常用的精益化數據分析的場景。
?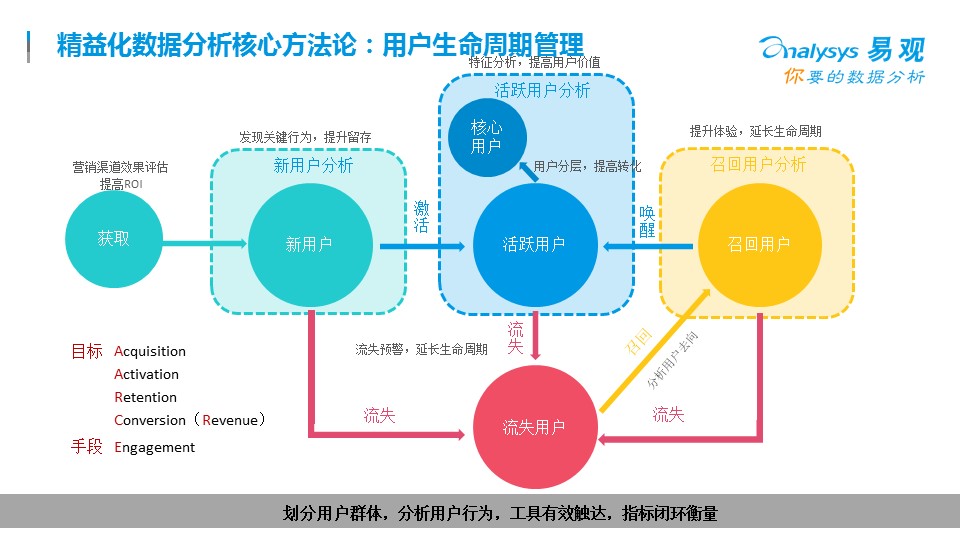 ?
?
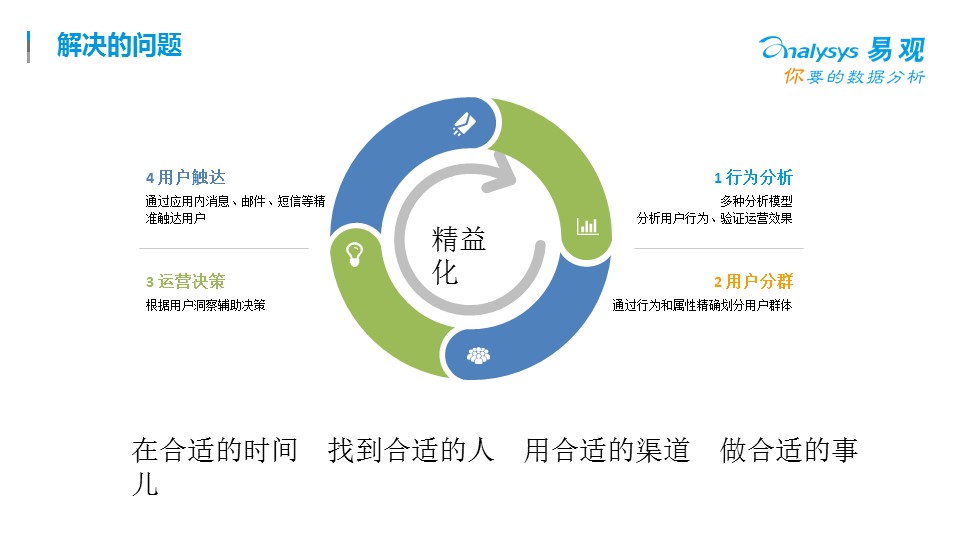
精益化數據分析,面對用戶這方面,用戶全生命周期管理的核心方法論是AARCE模型,每一個步驟都會有很多的分析可以做,下面我舉個比較常見的場景:
? ?
?
? ?
?
尋找優質渠道,提升關鍵路徑轉化,找回流失用戶,提升用戶留存和活躍度是幾個最常見的精益化分析模型。
? ?
?
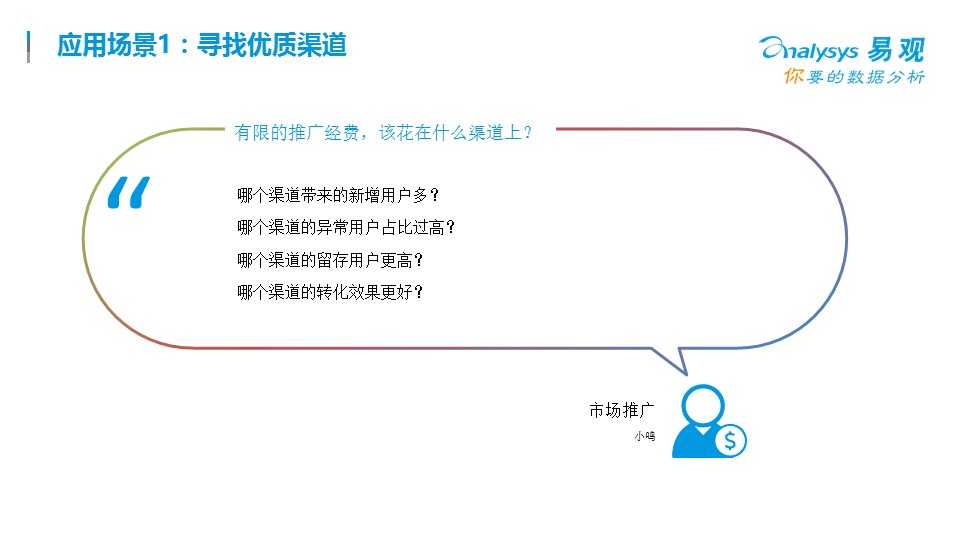
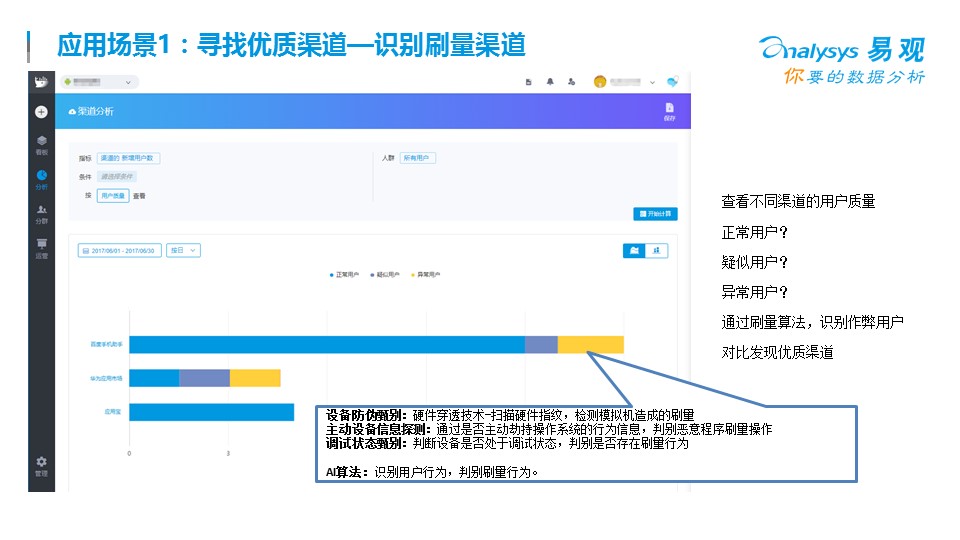
對于每個企業的運營和市場部來講,如果找到合適的渠道,發展用戶是每天都要面臨的問題,衡量每一個渠道的質量情況,轉化情況,留存情況就是一個典型的精益化數據分析場景。
? ?
?
? ?
?
? ?
?
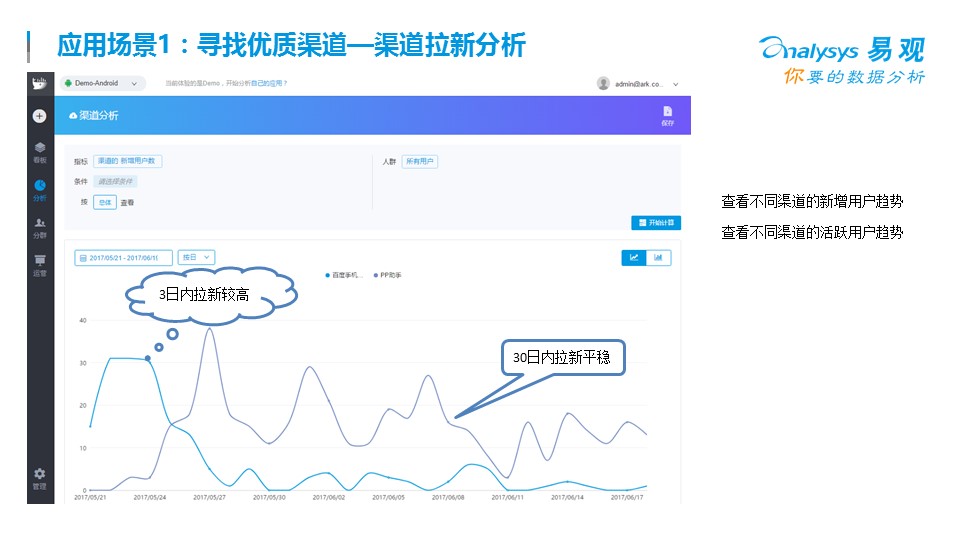
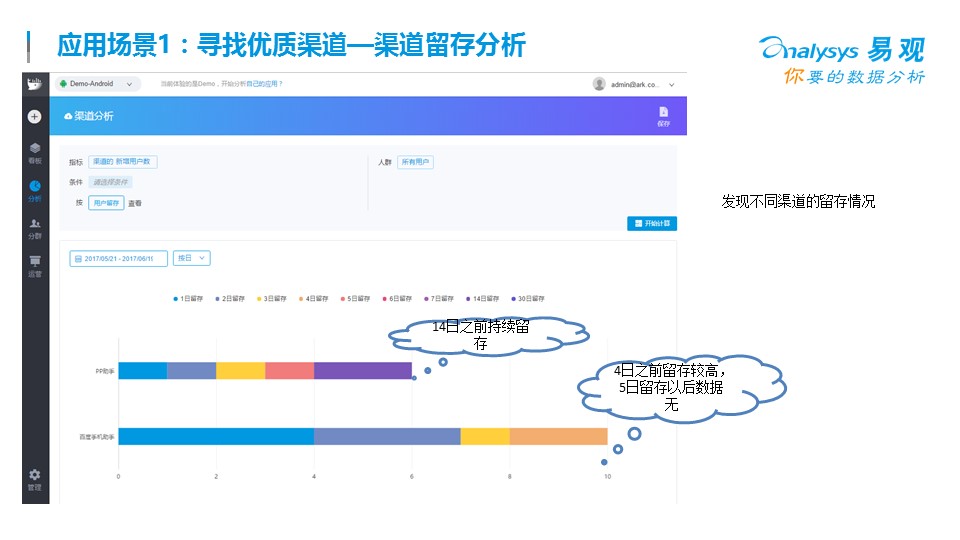
衡量渠道的時候,可以從新增、留存、防刷量幾個角度來做數據分析。大部分的渠道都會存在一些水分,無論是自建還是外購,幫助企業節約渠道費用,找到更合適的渠道會直接讓管理層感受到大數據的作用,我個人經驗是,數據分析的業務閉環,距離錢越近的分析越容易獲得公司的認可。光有渠道發展還是不夠的,還需要提高用戶的轉化,這里也有一些常用的指標和方法給大家參考
? ?
?
這是每一個產品經理會遇到的問題
? ?
?
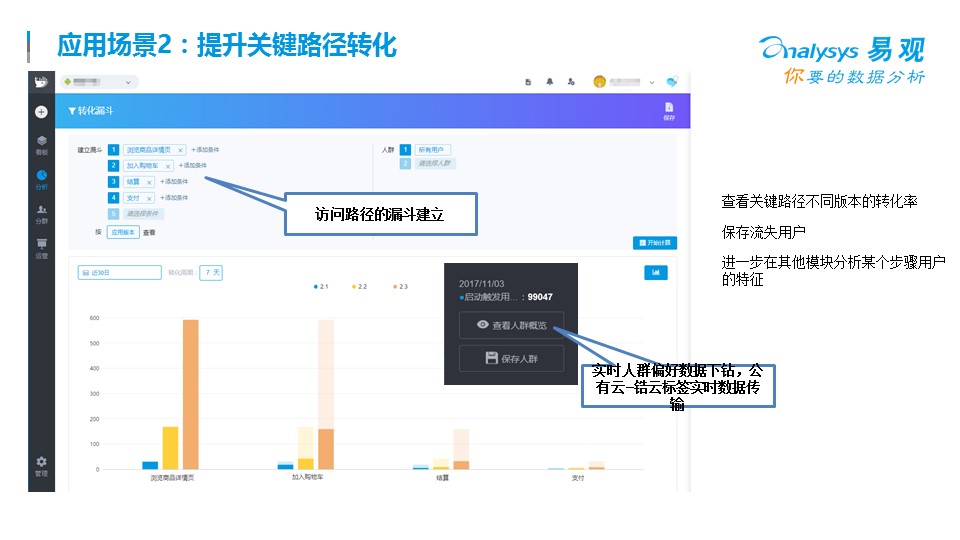
每一個關鍵路徑,都需要下轉化分析,看究竟那些用戶留下來了,那些用戶離開了。更重要的是,要看離開的這些用戶是否到競爭對手哪里去了,或者留下來的用戶是不是我們的目標客群。
? ?
?
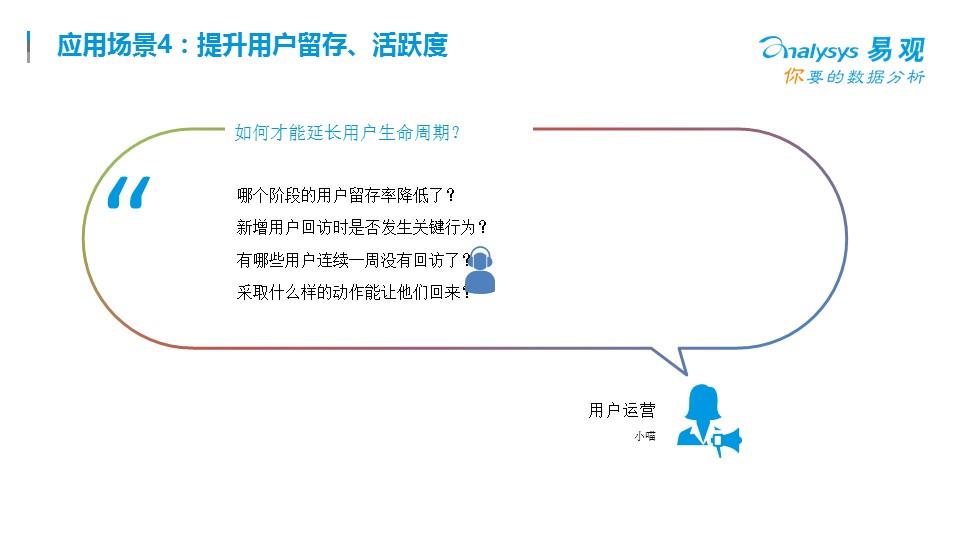
這需要每個公司建立自己的用戶畫像系統,對流失的客戶做全景的用戶行為洞察。說到流失,每個公司在建立精益化大數據分析平臺的時候,都會有一個很典型的功能,就是召回流失用戶,一般說來,都要先定義流失用戶-->流失原因分析-->流失營銷活動-->營銷活動效果評估這幾步
? ?
?
?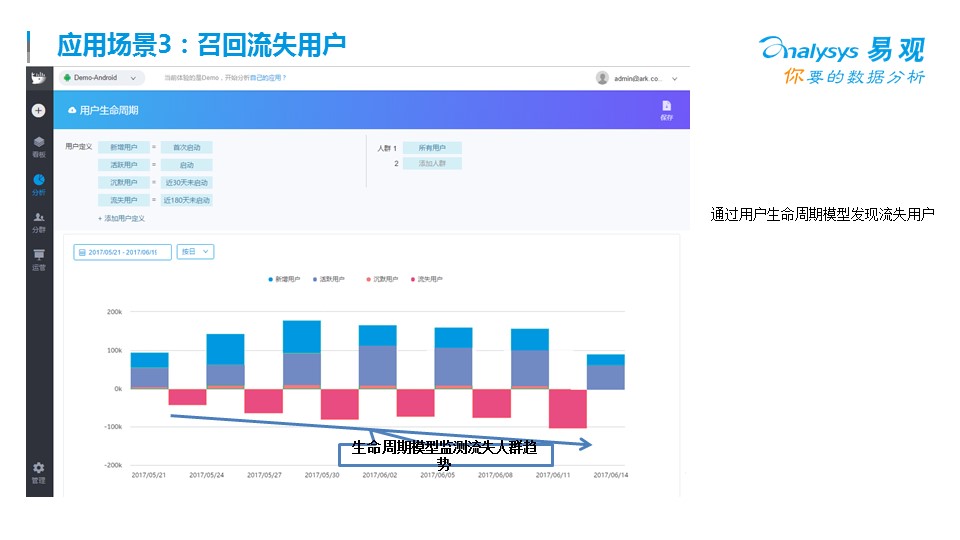 ?
?
?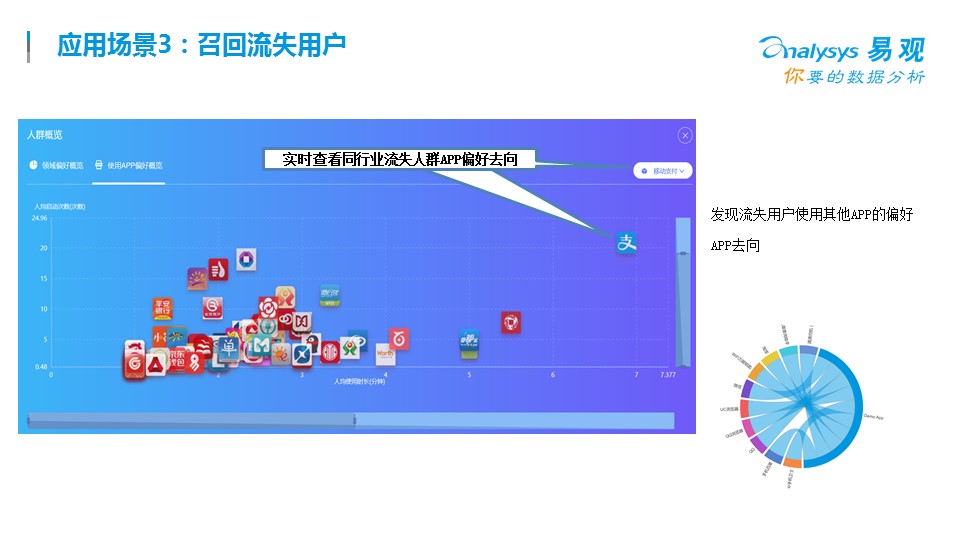 ?
?
?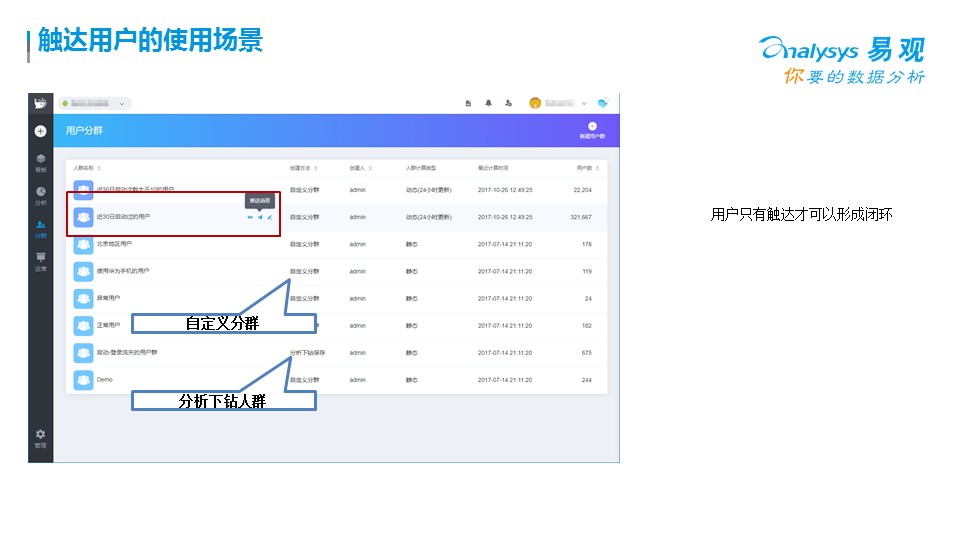 ?
?
?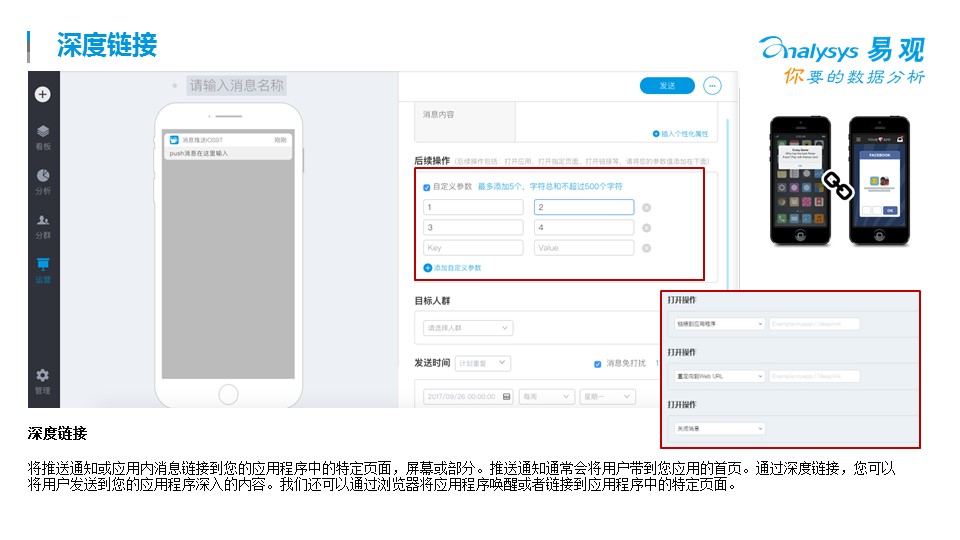 ?
?
? ?
?
? ?
?
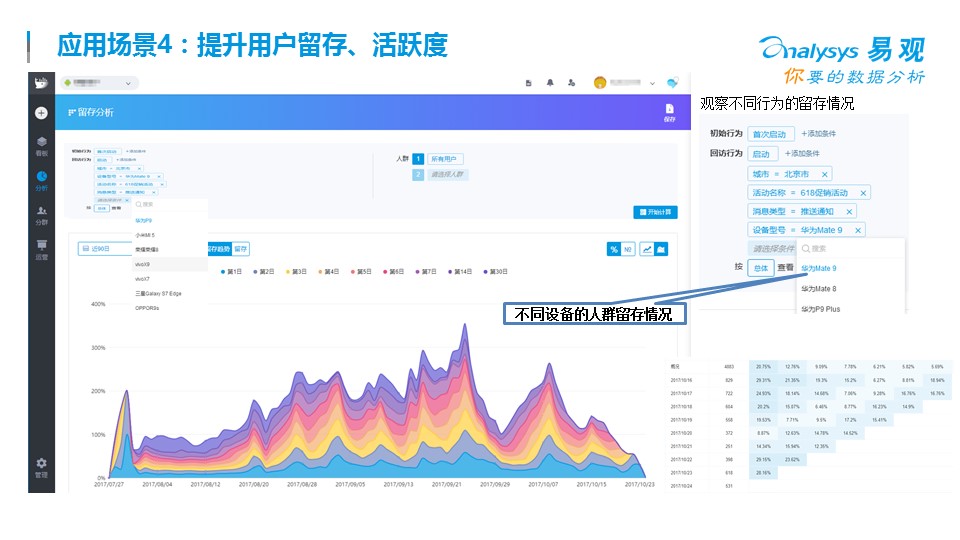
每次活動,是不是有效的觸達了你的定義的人群,是不是有效形成了挽留,都是需要仔細評估的。前面簡單講了一些場景,其實這樣的里例子還有很多,每個從業者需要根據自己企業的場景來做自己的一些場景設計。
三、大數據技術框架迭代與擴展
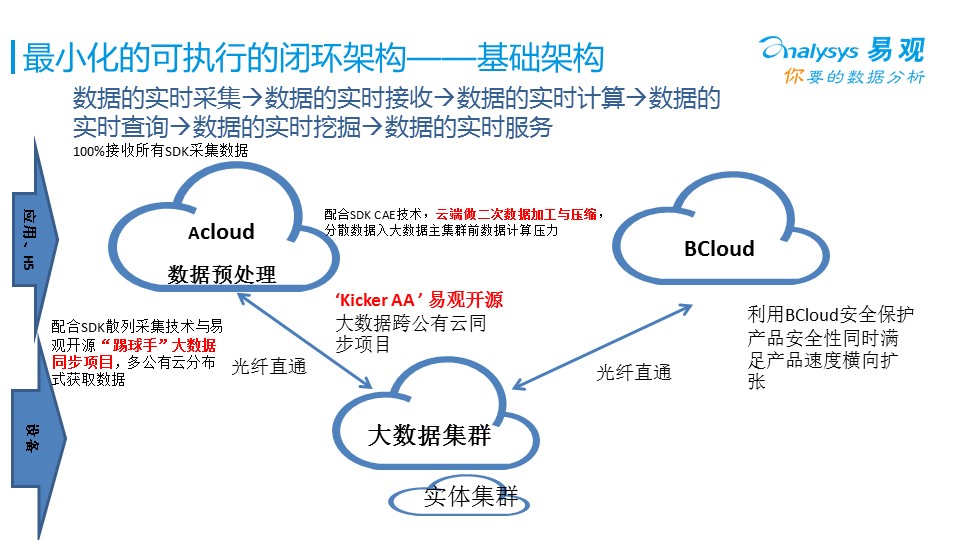
下面我講講精益化大數據分析時技術上有哪些坑需要填。每一個數據分析其實都是從采集-->接受-->計算-->查詢-->挖掘-->服務來做的。
? ?
?
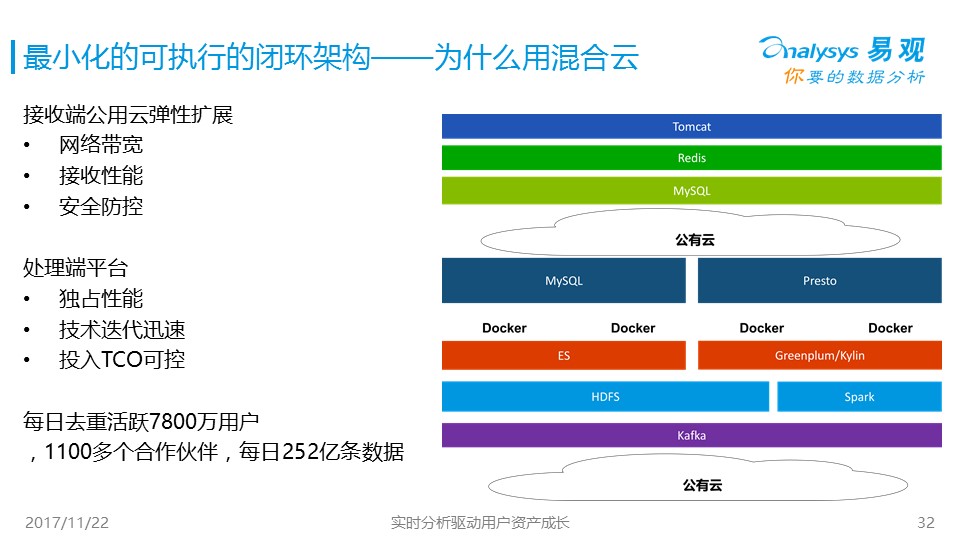
我說說我在易觀的經驗,目前公有云和私有云非常火爆。不過我選擇的是供應商提供的混合云,它既有公有云可擴展的特點、也有私有云的性能保證。現在易觀SDK的月活在5.2億,日活7800萬。這套混合云架構,支撐了這樣大的一個數據規模,每天運轉,提供給易觀內部分析師、外部的產品正常運作,到現在已經2年了,所以我很推薦做底層架構的小伙伴嘗試混合云這種模式。
? ?
?
這里簡單列舉了混合云的一些優勢。光有底層架構還不行,這樣大的數據,接收的方法需要特殊優化,云+端的控制策略就尤為重要了,如果沒有做好,每天數億的設備就會形成一個ddos,把你的服務器集群沖垮。
?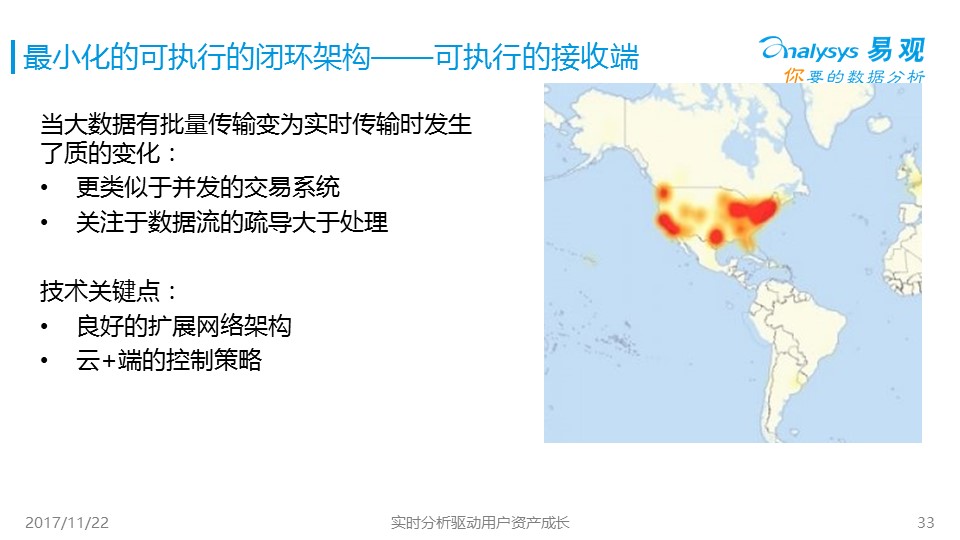 ?
?
? ?
?
? ?
?
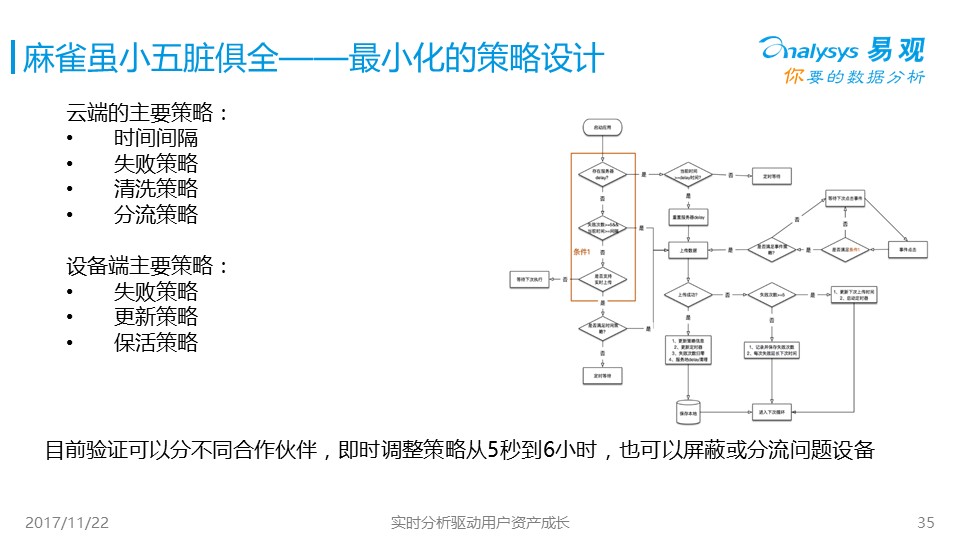
這里列舉了,在數據采集和數據接收時的一些策略選擇,以及通用的數據采集應該具有那些技術框架和模塊給大家參考。這些框架可以支持到月活數億級別,所以大家可以放心使用。時間不太多了哈,我挑兩個大數據處理和查詢中比較大的坑再說一下。
一個是我們內部的需求,需要選擇具有一部分標簽特性用戶,看他們的用戶行為特征是什么:例如,看95后,愛看視頻的女性,晚上10:00-11:00經常打開APP的Top5。數據存儲邏輯結構很簡單,一個是用戶標簽表,用戶ID,標簽ID;另一個是用戶ID,時間戳,APP名稱。簡單的想法就是join一下,where一下orderby。但是大家要知道,易觀有21.9億的用戶畫像了,用戶行為每天252億條,一個月就有數千億條了,怎么能簡單的join就解決了呢?每個企業也會遇到類似的情況,我的建議就是,去Join!在大數據環境下不要用join來解決任何問題,先用ES做用戶過濾,然后將用戶行為篩選縱轉橫變成bitmap,再通過與或關系來計算***結果,感興趣的小伙伴可以另外討論,今天不能深入講了。
? ?
?
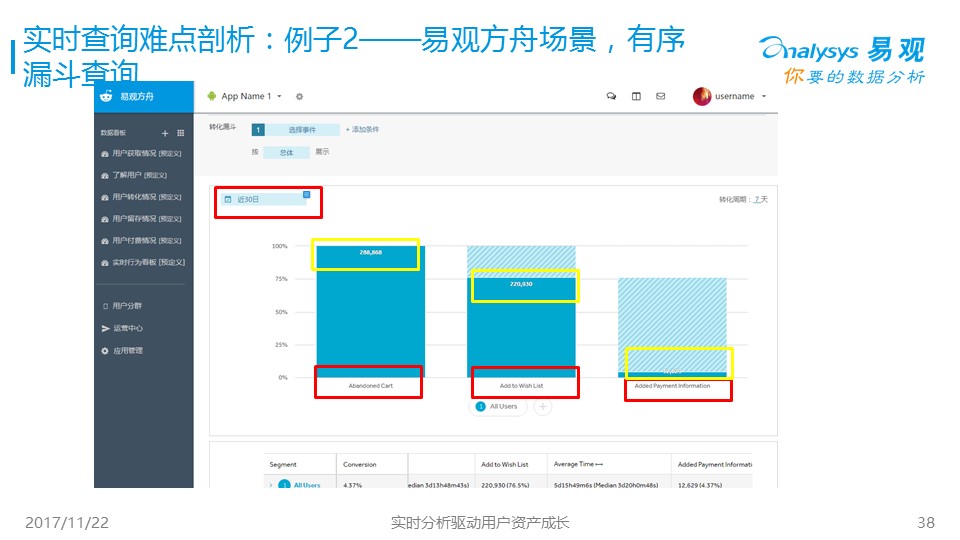
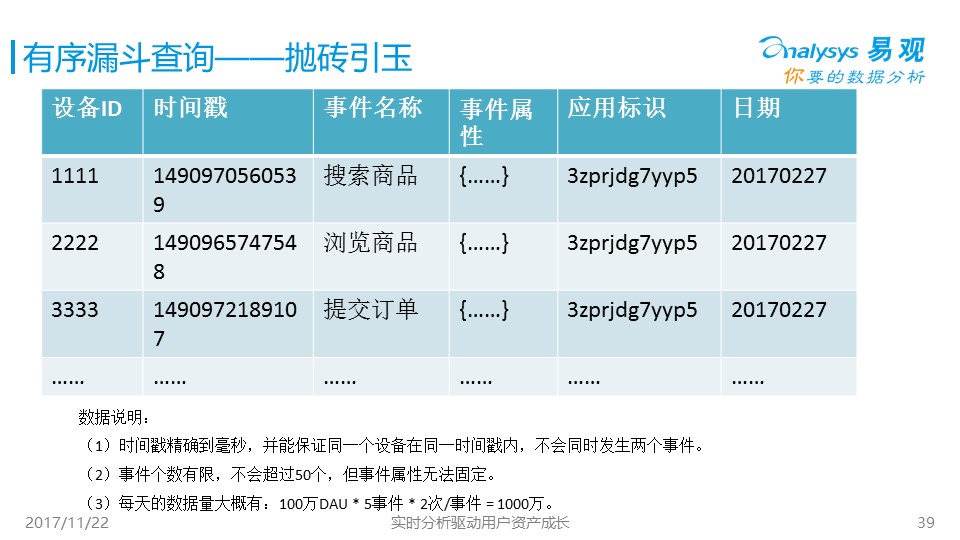
另一個就是有序轉化漏斗的問題,就是我前面舉的具體的例子,每個人都想知道到底多少用戶從瀏覽商品-->下單-->付款,是要按照順序來的,不能先付款,再瀏覽,使用大數據解決這個問題就難了,因為用戶行為會非常大,如何找到有序的轉化組合,而且要秒級別返回,是一個很有挑戰的問題,前段時間,我也組織了一個OLAP大賽,很多牛人、牛公司來參加這個問題的比賽,開源組的***名也獲得了10萬元獎金。這里我給出一個簡單思路,供大家參考研習,2018年7月開始我還會舉辦這樣的比賽,也歡迎大家來玩。
? ?
?
? ?
?
當然技術是無止境的,還有個重要樣的技術我們會要逐步去迭代。
? ?
?
四、用戶精益化分析到大數據平臺
***時間不多了,我簡單把易觀內部的大數據平臺和大家分享一下,希望對大家有啟發。
?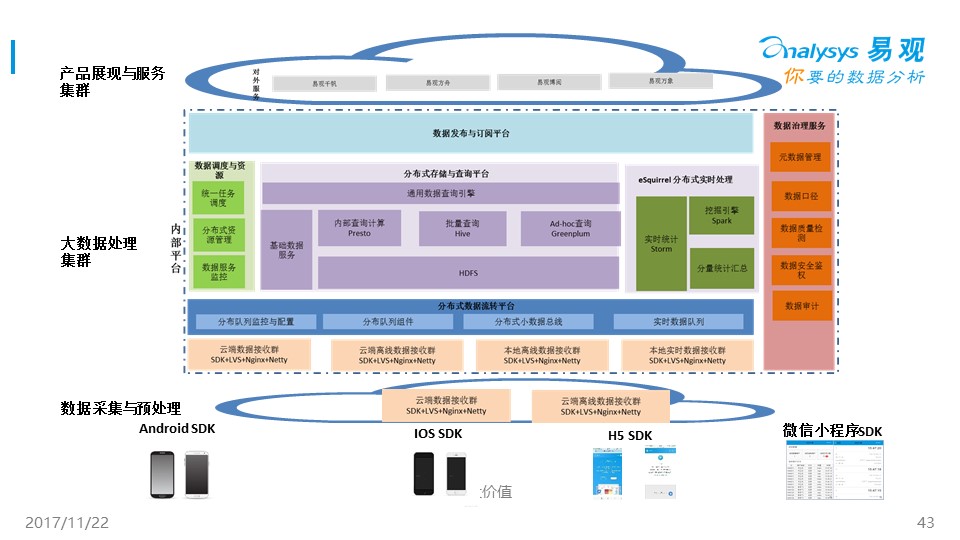 ?
?
數據存儲部分,易觀用了HDFS、Spark和Hive,也用了presto和greenplum,這塊幾個開源大數據存儲的對比如下。
?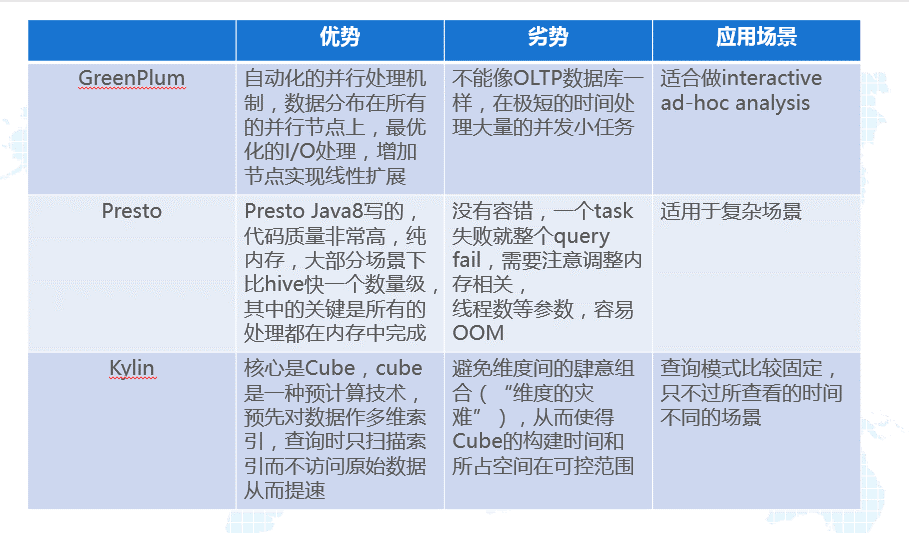 ?
?
這里需要強調的是,大家不要把眼睛都放在大數據存儲平臺上,資源的調度平臺,數據治理的服務也同樣重要。這塊時間不多了,大家可以線下或者搜我過去的文章來進一步了解。
? ?
?
***也歡迎大家訪問ark.analysys.cn。體驗易觀的大數據服務,還是強調那一點,大數據分析只是過程,不是結果。只有形成業務閉環的精益化分析才是可持續發展之路。圖里是我的微信和微博,歡迎大家關注。
以下問題是來自51CTO開發者社群小伙伴們的提問和分享
Q:東營日報-志道:郭老師,現在很多單位要求做大數據,概念比較空,有什么好的思路不管是從技術還是產品方面,去給領導或者同事講清楚嗎?
A:易觀CTO郭煒老師:我覺得大數據的確容易很***半部分的精益化思路給你借鑒,一定要找到業務閉環,做大數據你為了解決什么業務問題。前面兩部分講的精益化給你參考,也推薦你2本書,一個是《精益化創業》,一個是《精益化數據分析》。包括今天PPT中很多的思路也得益于Eric給我的啟發。
Q:東營日報-志道:很感謝。我們是報業單位,現在領導對大數據這塊比較感興趣,讓我們拿方案,束手無策,其實這也是行業的需求,每個行業都有自己的數據,如果挖掘加以利用就是很好的數據分析,但是作為我們自己做這樣的方案比較難,咱們易觀有這樣的方案嗎?
A:易觀CTO郭煒老師:具體需求我們互加一下私聊。
Q:數據-unicorn-北京:私有部署的化,是否會授權二次開發?
A:易觀CTO郭煒老師:當然。
Q:王軍-北京-hadoop:我現在使用hbase+phoenix做oltp查詢,現在join一張kw級別的表和一張10w級別的表很慢,需要30秒,這個怎么優化?我是用hbase+phoenix做oltp,用hive on spark 做olap。olap的數據處理完后放到hbase做查詢,現在問題是oltp查詢很慢。維度不固定,我想問問怎么優化hbase+phoenix,現在問題是通過phoenix查詢hbase數據比較慢,kw表join一張10w的表時間需要40秒。這個肯定接受不了。key基本就是幾個字段的組合。現在是分析出來的數據放到hbase,需要在hbase進行查詢。
A:易觀CTO郭煒老師:你用hadoop做?我建議你試用一下Greenplum。
A:數據-unicorn-北京:建議分析一下應用場景,再選取數據庫。如果維度不固定,又要查詢快,mongodb是不錯的選擇。如果是數據處理,比如join之類,hive的優勢比較明顯,或者存儲用hive,調用使用Presto(暫時不是很成熟隱藏問題較多,比如數據類型等)。
A:半個開發-小星星-廣州:這個不能完全賴在數據庫上,首先索引、sql優化什么的這些先排除掉。印象中,mysql數據瓶頸應該在3kw左右,pg多一點。當然,還得看where條件的寫法,像 or、<>、表達式左邊有計算等等,會使索引失效。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】