如何向普通人解釋機器學(xué)習(xí)、數(shù)據(jù)挖掘
隨著數(shù)據(jù)科學(xué)在人工智能發(fā)展中大放異彩,數(shù)據(jù)挖掘、機器學(xué)習(xí)進入了越來越多人的視野。而對于很多人來說,諸如機器學(xué)習(xí)之類的名次聽起來是神乎其技,但其真正的內(nèi)涵卻不為一般人所知。
特別是對于從事數(shù)據(jù)科學(xué)領(lǐng)域的人來說,如何向外行人解釋自己所從事的工作幾乎是一個超級難題。那么到底什么是機器學(xué)習(xí),如何用通俗易懂的語言來解釋?我們通過以下幾重境界來解釋。
一、專業(yè)理論型
百科定義+專業(yè)術(shù)語,讓人聽起來不明覺厲,實則一臉懵逼
機器學(xué)習(xí)(Machine Learning, ML)是一門多領(lǐng)域交叉學(xué)科,涉及概率論、統(tǒng)計學(xué)、逼近論、凸分析、算法復(fù)雜度理論等多門學(xué)科。專門研究計算機怎樣模擬或?qū)崿F(xiàn)人類的學(xué)習(xí)行為,以獲取新的知識或技能,重新組織已有的知識結(jié)構(gòu)使之不斷改善自身的性能。
它是人工智能的核心,是使計算機具有智能的根本途徑,其應(yīng)用遍及人工智能的各個領(lǐng)域,它主要使用歸納、綜合而不是演繹。
機器學(xué)習(xí)已經(jīng)有了十分廣泛的應(yīng)用,例如:數(shù)據(jù)挖掘、計算機視覺、自然語言處理、生物特征識別、搜索引擎、醫(yī)學(xué)診斷、檢測信用卡欺詐、證券市場分析、DNA序列測序、語音和手寫識別、戰(zhàn)略游戲和機器人運用。
機器學(xué)習(xí)從本質(zhì)上來說是一種學(xué)習(xí)結(jié)構(gòu), 整個結(jié)構(gòu)包括環(huán)境、知識庫和執(zhí)行三個部分。 在整個過程中,環(huán)境向系統(tǒng)提供信息,系統(tǒng)利用這些信息修改知識庫,以增進系統(tǒng)執(zhí)行部分完成任務(wù)的效能,執(zhí)行部分根據(jù)知識庫完成任務(wù),同時把獲得的信息反饋給學(xué)習(xí)部分,從而繼續(xù)改進知識庫。
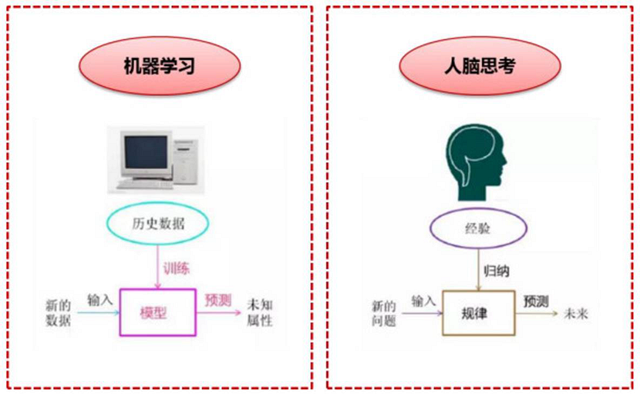
在具體的應(yīng)用中,環(huán)境、知識和執(zhí)行部分決定了具體的工作內(nèi)容,學(xué)習(xí)部分所需要解決的問題完全由上述三部分確定。 簡單來說,機器學(xué)習(xí)就是計算機利用已有的數(shù)據(jù),得出了某種模型,并利用此模型預(yù)測未來的一種方法, 這與人腦的思考方式非常類似。
二、以小見大型
以某種機器學(xué)習(xí)具體的案例來說明,讓人恍然大悟
一開始我們先來看一個人為設(shè)計的場景。假設(shè)一個房間里神奇地漂浮著無數(shù)個小球。我們想搞清楚這些小球停留的位置是否存在著一種特定的結(jié)構(gòu)。比方說,小球是不是更易集中在某一特定區(qū)域?是不是故意避開某些點位?它們是均勻分布于整個空間嗎?
但是房間一片漆黑,我們什么也看不見。于是我們找來了一部帶閃光燈的照相機,想把漂浮在整個房間的小球都拍下來。照片猶如下圖一樣:
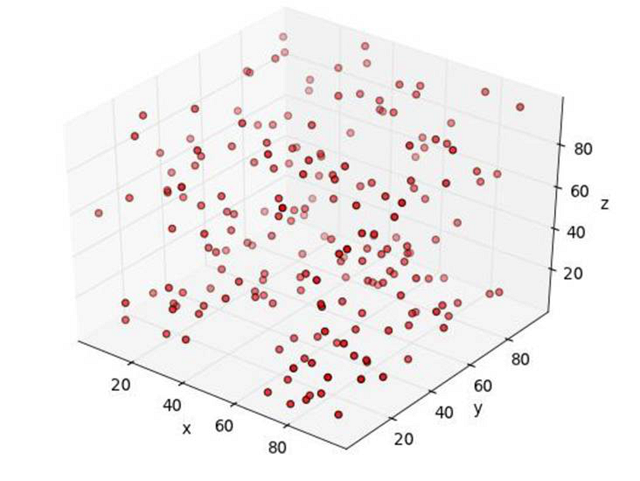
就算小球的位置之間確實存在某種聯(lián)系,從這張照片上我們也看不出個所以然。看上去小球就像是均勻分布的一樣。所以我們嘗試著換了下位置,從新的角度拍下了第二張照片。
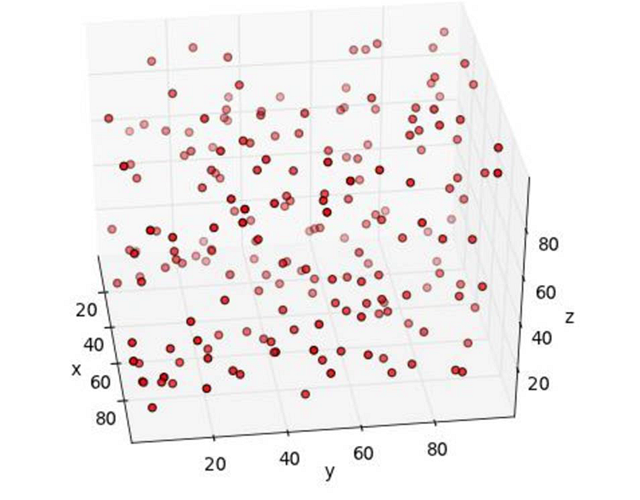
照片上的小球看起來還是隨機分布的,沒有任何規(guī)律。讓我們換個高點的角度試試看。
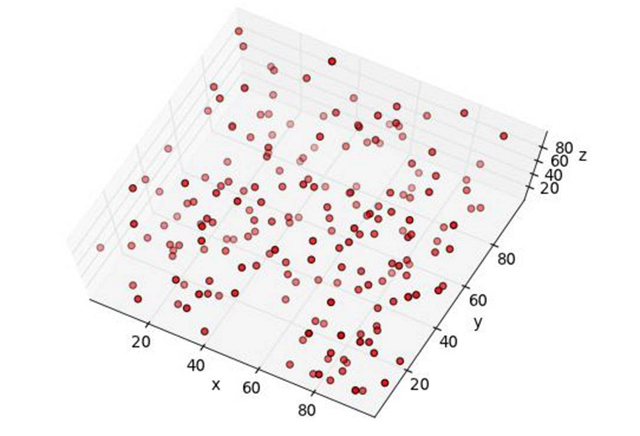
呃,還是看不出有什么規(guī)律來。那我們***再換個低點的角度試一次。
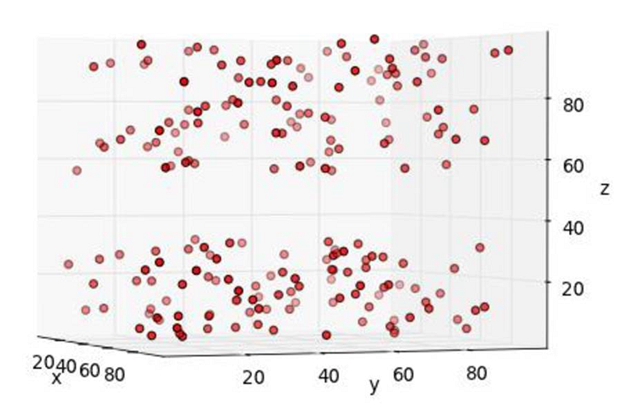
啊哈,這次有點意思了:看起來小球集中分布在靠近屋頂和地面的兩個區(qū)域,中間這段沒有一個小球。因此,為了發(fā)現(xiàn)這個規(guī)律,我們在拍照時就必須找到一個“好”的角度。如果角度不對,那我們永遠都不可能找出任何規(guī)律。
在上面這個例子中,我們想說的其實是三維數(shù)據(jù)點。每個小球的位置都可以由3個數(shù)字來表示,每個數(shù)字分別代表它在XYZ三條軸上的位置。在實際的電腦運算中,數(shù)據(jù)點的位置會由更多的數(shù)字組合來表示。
比如醫(yī)院病人的病歷可能會包含500組數(shù)字,包括他的生日年月日、身高、體重、血壓、最近一次的看病記錄、膽固醇指標等等。我們會想要搞清楚不同病人的數(shù)據(jù)點之間是否存在某種規(guī)律,如心臟病人的數(shù)據(jù)點是否會集中分布?如果數(shù)據(jù)點確實會集中分布,當(dāng)我們發(fā)現(xiàn)新入院病人的數(shù)據(jù)點也出現(xiàn)同樣的趨勢時,我們就可以推斷這位病人很可能犯心臟病。當(dāng)然,實際操作起來肯定不會如此簡單。
一個人是不可能用肉眼看到這些數(shù)據(jù)點的。人怎么可能分得清500個維度呢?就像在上面那個例子中,沒有人能看得清“黑屋”中小球,我們也同樣看不見500個維度中的那些數(shù)據(jù)點。我們可以用二維圖片來展示位于三維空間中的數(shù)據(jù)點,用同樣的方法,我們也可以更低維度的“照片”來表現(xiàn)擁有500個維度的數(shù)據(jù)點。
只有從合適的“角度”拍下“照片”,我們才可以從中找出不同數(shù)據(jù)點之間的規(guī)律,不然將很難有所發(fā)現(xiàn)。這就是人們所說的如何從“大數(shù)據(jù)”中“發(fā)現(xiàn)見解”。
三、曉之以情,動之以理
這樣來說,你家寵物應(yīng)該都可以聽明白了
買點芒果去
假設(shè)有一天你準備去買點芒果。有個小販擺放了一車。你可以一個一個挑,然后小販根據(jù)你挑的芒果的斤兩來算錢(在印度的典型情況)。顯然,你想挑最甜最熟的芒果對吧(因為小販是按芒果的重量來算錢,而不是按芒果的品質(zhì)來算錢的)。可是你準備怎么挑呢?
你記得奶奶和你說過, 嫩黃的芒果比暗黃的甜。 所以你有了一個簡單的判斷標準:只挑嫩黃的芒果。你檢查各個芒果的顏色, 挑了些嫩黃的,買單,走人,爽不?
可事實沒那么簡單。
生活是很復(fù)雜的
你回到家,開始慢慢品嘗你的芒果。你發(fā)現(xiàn)有一些芒果沒有想的那么甜。你焦慮了。顯然,奶奶的智慧不夠啊。挑芒果可不是看看顏色那么簡答的。
經(jīng)過深思熟慮(并且嘗了各種不同類型的芒果), 你發(fā)現(xiàn)那些大個兒的,嫩黃的芒果絕對是甜的,而小個兒,嫩黃的芒果,只有一半的時候是甜的(比如你買了100個嫩黃的芒果,50個比較大,50個比較小, 那么你會發(fā)現(xiàn)50個大個兒的芒果是甜的,而50個小個兒的芒果,平均只有25個是甜的)。
你對自己的發(fā)現(xiàn)非常開心,下次去買芒果的時候你就將這些規(guī)則牢牢的記在心里。但是下次再來到市集的時候,你發(fā)現(xiàn)你最喜歡的那家芒果攤搬出了鎮(zhèn)子。于 是你決定從其它賣芒果的小販那里購買芒果,但是這位小販的芒果和之前那位產(chǎn)地不同。現(xiàn)在,你突然發(fā)現(xiàn)你之前學(xué)到的挑芒果辦法(大個兒的嫩黃的芒果最甜)又 行不通了。你得從頭再學(xué)過。你在那位小販那里,品嘗了各類芒果,你發(fā)現(xiàn)在這里,小個兒、暗黃的芒果其實才是最甜的。
沒多久,你在其它城市的遠房表妹來看你。你準備好好請她吃頓芒果。但是她說芒果甜不甜無所謂,她要的芒果一定要是最多汁的。于是,你又用你的方法品嘗了各種芒果,發(fā)現(xiàn)比較軟的芒果比較多汁。
之后,你搬去了其它國家。在那里,芒果吃起來和你家鄉(xiāng)的味道完全不一樣。你發(fā)現(xiàn)綠芒果其實比黃芒果好吃。
再接著,你娶了一位討厭芒果的太太。她喜歡吃蘋果。你得天天去買蘋果。于是,你之前積累的那些挑芒果的經(jīng)驗一下子變的一文不值。你得用同樣的方法,去學(xué)習(xí)蘋果的各項物理屬性和它的味道間的關(guān)系。你確實這樣做了,因為你愛她。
有請計算機程序出場
現(xiàn)在想象一下,最近你正在寫一個計算機程序幫你挑選芒果(或者蘋果)。你會寫下如下的規(guī)則:
if(顏色是嫩黃 and 尺寸是大的 and 購自最喜歡的小販): 芒果是甜的
if(軟的): 芒果是多汁的
………………
你會用這些規(guī)則來挑選芒果。你甚至?xí)屇愕男〉苋グ凑者@個規(guī)則列表去買芒果,而且確定他一定會買到你滿意的芒果。
但是一旦在你的芒果實驗中有了新的發(fā)現(xiàn), 你就不得不手動修改這份規(guī)則列表。你得搞清楚影響芒果質(zhì)量的所有因素的錯綜復(fù)雜的細節(jié)。
如果問題越來越復(fù)雜, 則你要針對所有的芒果類型,手動地制定挑選規(guī)就變得非常困難。你的研究將讓你拿到芒果科學(xué)的博士學(xué)位(如果有這樣的學(xué)位的話)。
可誰有那么多時間去做這事兒呢。
有請機器學(xué)習(xí)算法
機器學(xué)習(xí)算法是由普通的算法演化而來。通過自動地從提供的數(shù)據(jù)中學(xué)習(xí),它會讓你的程序變得更“聰明”。
你從市場上的芒果里隨機的抽取一定的樣品(訓(xùn)練數(shù)據(jù)), 制作一張表格, 上面記著每個芒果的物理屬性, 比如顏色, 大小, 形狀, 產(chǎn)地, 賣家, 等等。(這些稱之為特征)。
還記錄下這個芒果甜不甜, 是否多汁,是否成熟(輸出變量)。你將這些數(shù)據(jù)提供給一個機器學(xué)習(xí)算法(分類算法/回歸算法),然后它就會學(xué)習(xí)出一個關(guān)于芒果的物理屬性和它的質(zhì)量之間關(guān)系的模型。
下次你再去市集, 只要測測那些芒果的特性(測試數(shù)據(jù)),然后將它輸入一個機器學(xué)習(xí)算法。算法將根據(jù)之前計算出的模型來預(yù)測芒果是甜的,熟的, 并且/還是多汁的。
該算法內(nèi)部使用的規(guī)則其實就是類似你之前手寫在紙上的那些規(guī)則(例如, 決策樹),或者更多涉及到的東西,但是基本上你就不需要擔(dān)心這個了。
瞧,你現(xiàn)在可以滿懷自信的去買芒果了,根本不用考慮那些挑選芒果的細節(jié)。更重要的是,你可以讓你的算法隨著時間越變越好(增強學(xué)習(xí)),當(dāng)它讀進更多 的訓(xùn)練數(shù)據(jù), 它就會更加準確,并且在做了錯誤的預(yù)測之后自我修正。但是最棒的地方在于,你可以用同樣的算法去訓(xùn)練不同的模型, 比如預(yù)測蘋果質(zhì)量的模型, 桔子的,香蕉的,葡萄的,櫻桃的,西瓜的,讓所有你心愛的人開心:)
這,就是專屬于你的機器學(xué)習(xí),很炫酷吧。