數據庫schema遷移數據實踐
如何進行大規模在線數據遷移
工程團隊常面臨一項共同挑戰:重新設計數據模型以支持清晰準確的抽象和更復雜的功能。這意味著,在生產環境中,需要遷移數以百萬計的活躍數據對象,并且重構上千行代碼。
用戶期望 Stripe API 保障可用性和一致性。所以在進行遷移時,需要格外謹慎,必須保證數據的數值正確無誤,并且 Stripe 的服務始終保持可用。
本文將展示國外移動支付服務商 Stripe 如何安全地對數以億計的 Subscriptions(訂閱服務)對象進行大規模遷移。
為什么遷移困難?
1.數據規模
數以億計的 Subscriptions 對象。在生產環境數據庫上進行涉及到所有這些對象的大規模遷移會有巨大的工作量。
想象一下,遷移一個 Subscription 對象需要花費一秒鐘,若以順序方式遷移一億個對象將花費超過三年的時間。
2.服務運行時間
商業機構持續通過 Stripe 的服務進行交易。所有的基礎設施升級都是在線進行,而不依賴于有計劃的維護時段。因為不能在遷移過程中中斷 Subscriptions 服務,在這個遷移過程中必須要保證所有服務 100% 處于可用狀態。
3.數據正確性
代碼庫中的很多代碼都在使用 Subscriptions 數據庫表。如果試圖一次性修改整個 Subscriptions 服務中數以千計的代碼行,那幾乎肯定會忽視一些邊界情況 。工程團隊必須確保每項服務都能夠持續獲取正確無誤的數據。
在線遷移的模式
將數百萬個對象從舊數據庫表遷移到新表是很有難度的,但許多公司需要去做這樣的事情。
以下是在進行大型在線遷移中常用的 4 步”雙寫模式“,具體步驟是:
- 向舊表和新表雙寫數據以保證它們之間的數據是同步的。
- 修改代碼庫中所有的數據讀取路徑以從新表讀取數據。
- 修改代碼庫中所有的數據寫入路徑以將數據只寫入新表。
- 刪除依賴過時數據模型的舊數據。
遷移示例:Subscriptions
什么是Subscriptions?為什么需要進行數據遷移?
Stripe 的 Subscriptions 用于幫助 DigitalOcean 和 Squarespace 這類用戶構建并管理他們客戶的循環計費。在過去幾年中,我們穩步增加了一些功能來支持更復雜的計費模式,例如多訂閱、試用、優惠券和發票。
在早期,每個 Customer 對象最多只有一個 subscription 。 customers 信息存儲為單獨的記錄。因為 customers 到 subscriptions 之間的映射關系非常簡單,所以subscriptions 信息與 customers 信息存儲在一起。
- class Customer
- Subscription subscription
- end
最終,我們的用戶想要具有多個 subscriptions 的 customers 。我們決定將單一的 subscription 字段轉換為 subscriptions 字段,以便存儲具有多個 subscription 的數組。
- class Customer
- array: Subscription subscriptions
- end
當添加新功能時,這個數據模型便出現問題了。任何對 subscriptions 的修改都會引發整條 Customer 記錄的更新,以及 subscriptions 相關的查詢都要通過掃描 customer 對象實現。所以我們決定將 subscriptions 獨立存儲。
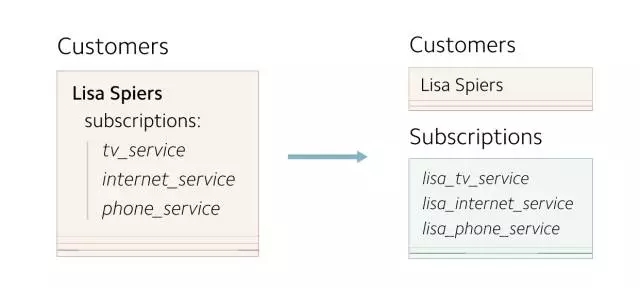
(重新設計的數據模型將 subscriptions 轉移到獨立的數據表中)
提醒一下,四步遷移方案如下:
- 向舊表和新表雙寫數據以保證它們之間的數據是同步的。
- 修改代碼庫中所有的數據讀取路徑以從新表讀取數據。
- 修改代碼庫中所有的數據寫入路徑以將數據只寫入新表。
- 刪除依賴過時數據模型的舊數據。
下面介紹這四個步驟的具體實踐。
***步:雙寫
創建一張新的數據庫表,作為遷移的開始。***步是開始復制新數據,同時寫入新舊兩處存儲中。之后,再將缺失的數據回填至新存儲,已使兩處存儲具有相同的數據
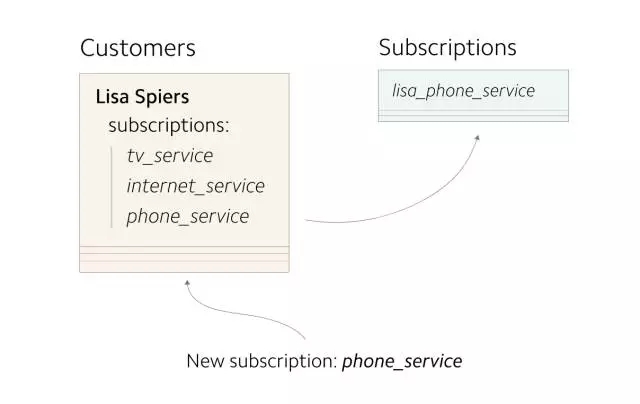
(所有新寫入的數據都應更新新舊兩處存儲)
在 Stripe 的案例中,我們將所有新創建的 subscriptions 同時寫入 Customers 表和 Subscriptions 表。在開始雙寫兩張表之前,需要評估額外的寫入操作對生產環境數據庫性能的潛在影響。可以通過緩慢提高重復對象的百分比來緩解性能問題,同時持續關注系統運行指標。
進行到此時,新創建的對象已同時存在于兩張表中,而舊對象只能在舊表中找到。接下來將以懶惰方式( lazy fashion )開始復制已存在的舊對象:每當對象更新時,將它們自動復制到新表中。這種方式可逐步轉移已存在的數據。
***,將剩余的 subscriptions 數據回填至新表。
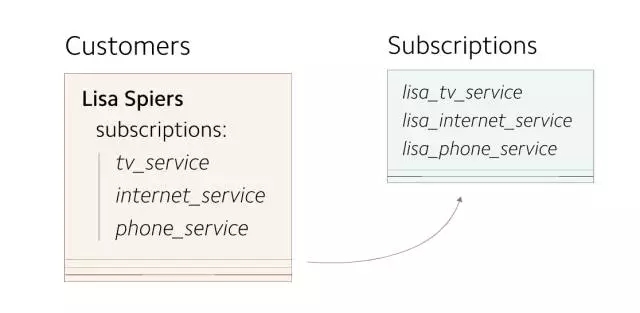
(回填已存在 subscriptions 數據至新表)
在正在對外提供服務的數據庫上找到所有需要遷移的數據是回填操作中代價***的部分。通過查詢數據庫查找所有對象的方式將需要在生產環境數據庫上執行相當多的查詢操作,這將耗費很多時間。幸運的是,可以將數據從線上導入對生產環境數據庫完全無影響的離線流程中。我們創建適用于我們 Hadoop 集群的數據庫快照,這讓我們可以使用 MapReduce 以離線、分布式的方式快速處理數據。
我們使用 Scalding 來管理 MapReduce 作業。 Scalding 是用 Scala 編寫的非常實用的庫,可以很容易地編寫MapReduce作業(10行代碼即可實現一個簡單的作業)。 在這種情況下,使用 Scalding 幫助工程團隊找出所有subscriptions 數據。具體步驟如下:
- 編寫一份 Scalding 作業,提供所有需要復制的 subscription ID 的列表。
- 通過一組進程并行執行來大規模的復制 subscriptions 數據。
- 遷移完成后,需再次運行 Scalding 作業,以確保所有 subscriptions 數據都已存在于 Subscriptions 表中。
第二步:改變所有讀操作路徑
到目前為止,新舊數據表已是同步狀態。下一步要做的是在新表上進行所有的讀操作。
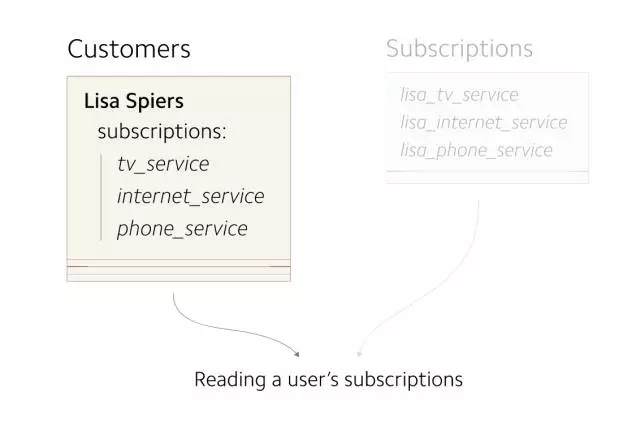
(目前,所有的讀操作在 Customers 表上進行,需要將這些操作轉移到 Subscriptions 表上)
需要確保從新表讀數據是安全的,subscription 在新舊表中的數據應該是一致的。可以使用 GitHub 出品的 Scientist 來輔助驗證讀操作。Scientist 是一個 Ruby 庫, 它可以讓我們在生產環境運行實驗,比對不同代碼的運行結果并對不一致的結果發出警告 。通過 Scientist ,可實時生成針對不一致結果的警告和指標。當實驗代碼中發生錯誤,其余的應用程序是不會受到任何影響的。
實驗按如下進行:
- 使用 Scientist 從 Subscriptions 表和 Customers 表同時讀取數據。
- 如果讀取到的數據不一致,則向工程團隊發出警告。
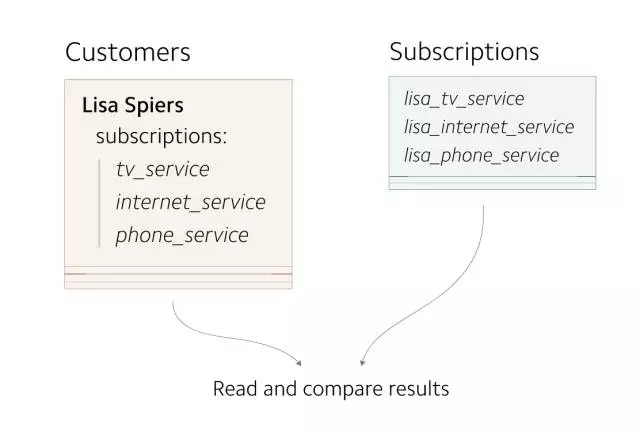
GitHub 的 Scientist 可運行讀取兩張表并對數據做對比的實驗。
在確認所有數據是一致的后,就可以開始從新表讀取數據了。
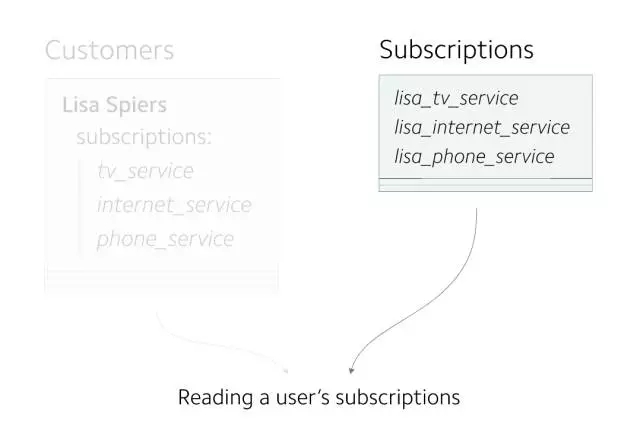
(實驗成功,現在所有的讀操作都在 Subscriptions 表上進行)
第三步:改變所有寫操作路徑
接下來,需要更新寫操作路徑,將數據寫入新的 Subscriptions 表。 實施的目標是逐步推進這些改變,所以需要采取謹慎的策略。
直到現在,數據一直寫入舊表,然后被復制到新表:

現在要顛倒這個順序:先將數據寫入新表,然后將其寫入舊表中。 通過保持這兩張表的一致性,我們可以進行增量更新并仔細觀察每個更改。
重構 subscriptions 的所有寫操作代碼可以說是遷移中***挑戰性的部分。 Stripe 服務中處理 subscriptions 操作的邏輯(例如更新,分期付款、續費)涉及多個服務的數千行代碼。
成功重構的關鍵是增量處理:將盡可能多的代碼路徑分隔成可能的最小單元,以便可以仔細應用每個更改。 新舊兩張表的數據在重構的任何一個階段都需要保持一致。
對于每個代碼路徑,我們需要使用整體方法來確保我們的更改是安全的。 我們不能僅僅只使用新數據替代舊數據:每一個邏輯塊都需要仔細斟酌。 如果錯過了任何情況,可能就會造成數據不一致。 值得慶幸的是,可以運行更多的 Scientist 實驗來提醒工程團隊可能存在的任何不一致。
新的,簡化的寫數據路徑如下所示:

可通過在調用 subscriptions 數組時觸發報錯的方法,確保沒有代碼繼續使用過時的subscriptions 數組:
- class Customer
- def subscriptions
- hard_assertion_failed("Accessing subscriptions array on customer")
- end
- end
第四步:刪除舊數據
***的(也是最令人滿意的)步驟是移除舊的寫操作代碼,并最終刪除。
一旦確定沒有任何代碼依賴過時數據模型的 subscriptions 字段,就不再需要將數據寫入舊表:

隨著這一變化,代碼不再使用舊數據源,新數據源成為唯一數據源。
現在,可以刪除所有 Customer 對象上的 subscriptions 數組,并且逐漸以懶惰的方式處理“刪除”操作。 每次 subscription 被加載后,都會自動清空這個 subscriptions 數組,然后運行 Scalding 作業并遷移,以查找任何剩余的要刪除的對象。 最終的數據模型如下:

結論
在保證 Stripe API 數據一致性的同時進行遷移是非常復雜的工作。安全進行這項遷移的幾個要點是:
- 我們制定了一個四階段遷移策略,可以讓我們在生產環境中不停服進行數據切換。
- 使用Hadoop離線處理數據,使用MapReduce以并行方式處理大量數據,而不是依賴在生產環境數據庫上執行的代價高昂的查詢。
- 所做的所有更改都是漸進式的。 我們從未試圖一次更改幾百行代碼。
- 所有的變化都是高度透明和可觀察的。 Scientist 的實驗只要有一條數據在生產環境中是不一致的,就立即提醒工程團隊。 在整個遷移過程中,我們都對安全的遷移懷有信心。
我們發現這種方法在我們執行過的許多在線數據遷移中都很有效。我們希望這些實踐做法對于其他團隊進行大規模遷移也是有幫助的。