深度學習的異構加速技術(一):AI 需要一個多大的“心臟”?
一、概述:通用=低效
作為通用處理器,CPU (Central Processing Unit) 是計算機中不可或缺的計算核心,結合指令集,完成日常工作中多種多樣的計算和處理任務。然而近年來,CPU在計算平臺領域一統天下的步伐走的并不順利,可歸因于兩個方面,即自身約束和需求轉移。
(1)自身約束又包含兩方面,即半導體工藝,和存儲帶寬瓶頸。
一方面,當半導體的工藝制程走到7nm后,已逼近物理極限,摩爾定律逐漸失效,導致CPU不再能像以前一樣享受工藝提升帶來的紅利:通過更高的工藝,在相同面積下,增加更多的計算資源來提升性能,并保持功耗不變。為了追求更高的性能,更低的功耗,來適應計算密集型的發展趨勢,更多的設計通過降低通用性,來提升針對某一(或某一類)任務的性能,如GPU和定制ASIC。
另一方面,CPU內核的計算過程需要大量數據,而片外DDR不僅帶寬有限,還具有較長的訪問延遲。片上緩存可以一定程度上緩解這一問題,但容量極為有限。Intel通過數據預讀、亂序執行、超線程等大量技術,解決帶寬瓶頸,盡可能跑滿CPU,但復雜的調度設計和緩存占用了大量的CPU硅片面積,使真正用來做運算的邏輯,所占面積甚至不到1%[1]。同時,保證程序對之前產品兼容性的約束,在一定程度上制約了CPU構架的演進。
(2)需求轉移,主要體現在兩個逐漸興起的計算密集型場景,即云端大數據計算和深度學習。
尤其在以CNN為代表的深度學習領域,準確率的提升伴隨著模型深度的增加,對計算平臺的性能要求也大幅增長,如圖1所示[2]。相比于CPU面對的通用多任務計算,深度學習計算具有以下特點:任務單一,計算密度大,較高的數據可復用率。對計算構架的要求在于大規模的計算邏輯和數據帶寬,而不在于復雜的任務調度,因此在CPU上并不能跑出較好的性能。
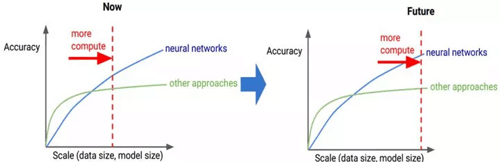
圖1.1 深度學習的發展趨勢:更高精度與更深的模型,伴隨著更高的計算能力需求。
基于上述原因,CPU構架在深度學習、大數據分析,以及部分嵌入式前端應用中并不具備普適性,此時,異構計算開始進入人們的視野。本文主要針對深度學習的計算構架進行討論。
在討論之前,先上一張經典的類比圖:分別以“可編程能力/靈活性”和“開發難度/定制性/計算效率/能耗”為橫軸和縱軸,將CPU與當前主流異構處理器,如GPU、FPGA、專用ASIC等進行比較。
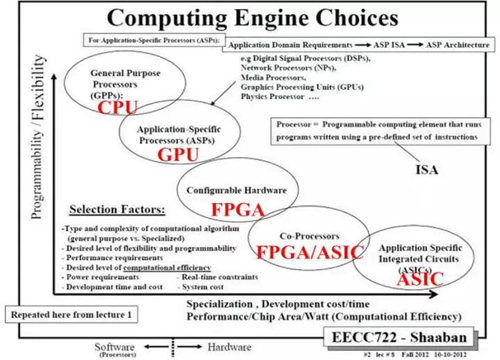
圖1.2 計算平臺選擇依據
通過前文分析可知,CPU***限度的靈活性是以犧牲計算效率為代價。GPU將應用場景縮減為圖形圖像與海量數據并行計算,設計了數千計算內核,有效的提升了硅片上計算邏輯的比例,但隨之而來的帶寬需求也是相當恐怖的。為了解決這一問題,一方面,為了保證通用性,兼容低數據復用的高帶寬場景,GPU內部設計了大量分布式緩存;另一方面,GPU的顯存始終代表了當前可商用化存儲器的***成果。顯存采用的DDR始終領先服務器內存1~2代,并成為業界首先使用HBM的應用。因此,相比于CPU,GPU具備更高的計算性能和能耗比,但相對的通用性和帶寬競爭使其能耗比依然高于FPGA和ASIC,并且性能依賴于優化程度,即計算模型和數據調度要適配GPU的底層架構。
FPGA和ASIC則更傾向于針對某一特定應用。無疑,專用ASIC具有***的計算效率和***的功耗,但在架構、設計、仿真、制造、封裝、測試等各個環節將消耗大量的人力和物力。而在深度學習模型不斷涌現的環境下,當尚未出現確定性應用時,對CNN、RNN中的各個模型分別進行構架設計甚至定制一款獨立ASIC是一件非常奢侈的事情,因此在AI處理器的設計上,大家的做法逐漸一致,設計一款在AI領域具備一定通用性的FPGA/ASIC構架,稱為領域處理器。使其可以覆蓋深度學習中的一類(如常見CNN模型),或多類(如CNN+RNN等)。
二、嵌入式VS云端,不同場景下,AI處理器的兩個選擇
2.1 AI處理器的發展和現狀
伴隨著深度學習模型的深化和算力需求的提升,從學術界興起的AI處理器方案已經迅速蔓延到工業界。目前,各大互聯網、半導體、初創公司的方案主要分為云端、嵌入式端兩類(或稱為云側和端側),可歸納如表1.1所示若感興趣可轉到唐杉同學維護的列表:https://basicmi.github.io/Deep-Learning-Processor-List/
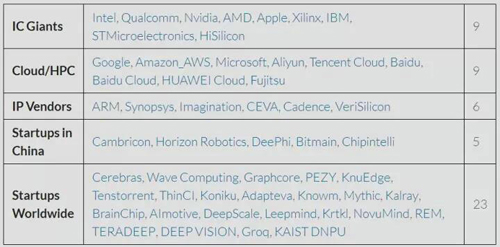
表1.1 深度學習處理器方案列表
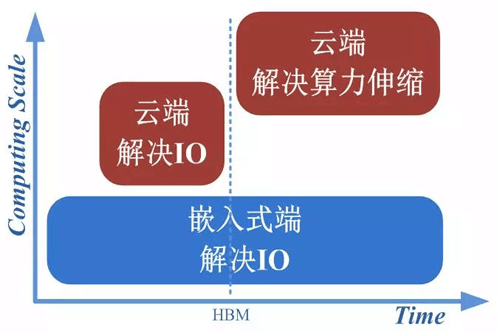
圖1.3 AI處理器的發展和設計目標
AI處理器的發展過程如圖1.3所示。在早期,對AI處理器架構的探討源于學術界的半導體和體系架構領域,此時模型層數較少,計算規模較小,算力較低,主要針對場景為嵌入式前端;隨著模型的逐漸加深,對算力的需求也相應增加,導致了帶寬瓶頸,即IO問題(帶寬問題的成因詳見2.2節),此時可通過增大片內緩存、優化調度模型來增加數據復用率等方式解決;當云端的AI處理需求逐漸浮出水面,多用戶、高吞吐、低延遲、高密度部署等對算力的需求進一步提升。計算單元的劇增使IO瓶頸愈加嚴重,要解決需要付出較高代價(如增加DDR接口通道數量、片內緩存容量、多芯片互聯等),制約了處理器實際應用。此時,片上HBM(High Bandwidth Memory,高帶寬存儲器)的出現使深度學習模型完全放到片上成為可能,集成度提升的同時,使帶寬不再受制于芯片引腳的互聯數量,從而在一定程度上解決了IO瓶頸,使云端的發展方向從解決IO帶寬問題,轉向解決算力伸縮問題。
到目前為止,以HBM/HMC的應用為標志,云端高性能深度學習處理器的發展共經歷了兩個階段:
1.***階段,解決IO帶寬問題;
2.第二階段,解決算力伸縮問題。
2.2 帶寬瓶頸
***階段,囊括了初期的AI處理器,以及至今的大部分嵌入式前端的解決方案,包括***代TPU、目前FPGA方案的相關構架、寒武紀ASIC構架,以及90%以上的學術界成果。欲達到更高的性能,一個有效的方法是大幅度提升計算核心的并行度,但算力的擴張需要匹配相應的IO帶寬。例如,圖1.4中的1個乘加運算單元若運行在500MHz的頻率下,每秒需要4GB的數據讀寫帶寬;一個典型的云端高性能FPGA(以Xilinx KU115為例)共有5520個DSP,跑滿性能需要22TB的帶寬;而一條DDR4 DIMM僅能提供19.2GB的帶寬(上述分析并不嚴謹,但不妨礙對帶寬瓶頸的討論)。因此在***階段,設計的核心是,一方面通過共享緩存、數據調用方式的優化等方式提升數據復用率,配合片上緩存,減少從片外存儲器的數據加載次數。另一方面通過模型優化、低位寬量化、稀疏化等方式簡化模型和計算。
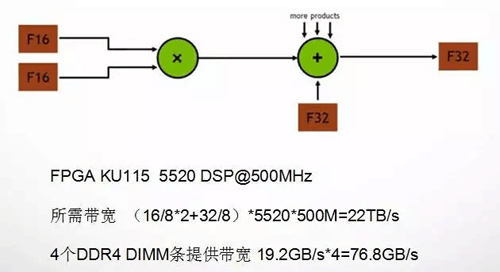
圖1.4 一個乘加單元及其帶寬計算(累加值通常與輸出共用,故未計入帶寬)
2.3 算力伸縮
盡管片上分布的大量緩存能提供足夠的計算帶寬,但由于存儲結構和工藝制約,片上緩存占用了大部分的芯片面積(通常為1/3至2/3),限制了算力提升下緩存容量的同步提升,如圖1.5所示。
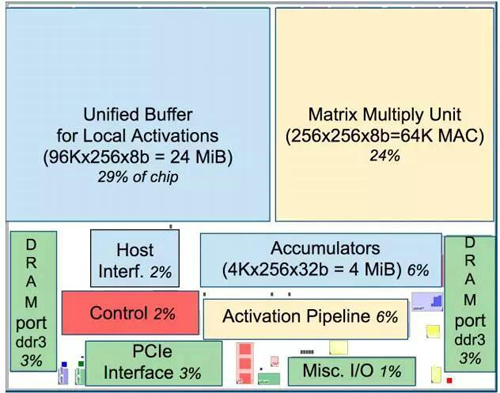

圖1.5 芯片中片上緩存的規模,上圖為Google***代TPU,藍色部分為緩存區域,占用芯片面積的37%;下圖為寒武紀公司的DiaoNao AI ASIC設計,緩存占面積的66.7%(NBin+NBout+SB)。
而以HBM為代表的存儲器堆疊技術,將原本一維的存儲器布局擴展到三維,大幅度提高了片上存儲器的密度,如圖1.6所示,標志著高性能AI處理器進入第二階段。但HBM的需要較高的工藝而大幅度提升了成本,因此僅出現在互聯網和半導體巨頭的設計中。HBM使片上緩存容量從MB級別提升到GB級別,可以將整個模型放到片上而不再需要從片外DDR中加載;同時,堆疊存儲器提供的帶寬不再受限于芯片IO引腳的制約而得到50倍以上的提升,使帶寬不再是瓶頸。此時,設計的核心在于高效的計算構架、可伸縮的計算規模、和分布式計算能力,以應對海量數據的訓練和計算中的頻繁交互。
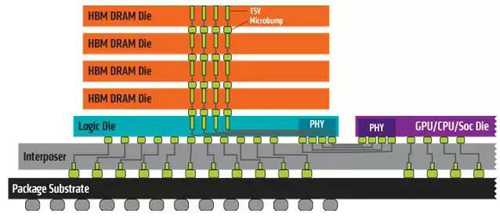
圖1.6 HBM與片內垂直堆疊技術
目前AI構架已從百家爭鳴,逐漸走向應用。在后續的篇幅中,將對這兩個階段進行論述。
原文鏈接:http://suo.im/3NdE0p
作者:kevinxiaoyu
【本文是51CTO專欄作者“騰訊云技術社區”的原創稿件,轉載請通過51CTO聯系原作者獲取授權】