













學霸君首席科學家陳銳鋒:借力技術削減知識孤島,實現教學增效
原創【51CTO.com原創稿件】學習壓力大、教育資源分配失衡的中國教育,衍生出數萬在線教育類應用。隨著應用數量的遞增,教育內容和方式在總量上也水漲船高,但其中免費應用占比多,因缺乏內容支撐導致同質化的問題越來越嚴重。學霸君首席科學家陳銳鋒在專訪中表示,公司定位在成立之初就很明確,教師和學生是最重要的合作伙伴,學霸君不會替代老師,只會借力 ABCD 對抗知識孤島,實現 EEE。
那 ABCD 是什么?EEE 又是什么呢?陳銳鋒把學霸君的技術面歸納為ABCDEEE:
- A=AI。
- B=Big Data。
- C=Cloud。
- D= Delivery。
- EEE=Educational Efficiency Enhancement。
這些因素是為了增強教學效率,并沒有直接 Education。也就是說,ABCD 不論如何開拓,都不能替代教育過程中教師這個環節,從開發拍照搜題軟件,到線上一對一輔導,再到智慧教育平臺,學霸君做的一切都是圍繞這個觀點進行。
打通知識痛點,把知識輔導變成知識圖譜結構
學霸君一系列產品的核心目的是打通知識痛點,把知識輔導變成知識圖譜結構,供老師和學生教學使用。想要實現這個目的,就要觀測學生所看的各種數據,如書籍、試卷等。這些數據都是成框架體系的,但很多學生并不知情或不關注,只是無奈陷入題海圍攻。框架體系就像人的神經網絡,可以串起每一塊肌肉,每一塊骨頭的運動。或許有人會說,書的大綱不就是框架體系嗎。其實不然,還有更深層次的大綱并沒有體現。
在學習過程中,框架的價值是非常重要的,如果理不清整個思路,隨機游走的效率非常低,就像在沙漠中找綠洲,沒有 GPS,成功尋到的機會非常渺茫。
如何構建這個框架呢?這就要靠人工智能、大數據收集分析、云計算服務和針對性內容推送,也就是前面提到的 ABCD!
大規模收集行為、知識等學習數據
2013 年,學霸君在思考采用什么方式,才能洞悉學生學什么,不懂什么?無論選擇何種方式,數據都是基石,所以首先要做的事情是大規模收集數據。
閱卷系統是傳統收集數據的方式,但存在邊界限制,不僅難覆蓋全國范圍的學生、推廣成本也很高,學霸君是通過拍照答疑場景來獲取數據的。
具體實現是團隊采用拍照上傳的方式,讓每個用戶主動地告知后臺服務器自己什么地方不懂,每一個圖片的上傳,代表了用戶的一個能力缺失點。同時,文字識別技術的采用,將圖片轉化成為可關聯分析的重要內容。
第二步,在識別的基礎上,系統采用自然語言處理技術對識別后的結果進行分析和加工,將原始的識別文本打上相應的知識點標簽,這就使數據能關聯到同一個知識點下的考題,實現初步的推薦。
第三步,知識點標簽大規模形成之后,教研老師們結合數據挖掘的支撐,將離散的題目梳理、聚合成關聯的結構,并抽取出知識圖譜。
經歷了這幾個步驟,目前數據加工團隊已形成了結合識別、自動標簽和關聯分析的處理流程。
中國還有一個非常特殊的數據產生機制,那就是考試。考試環境帶來了世界上其他國家都沒有的高量級數據,即海量題庫。
題庫內除客觀題,還有大量的主觀題,而且每道題都有相應的答案。這些題目是由眾多中國老師做好標注的數據,每個答案是這道題的數據標記。
這個海量題庫使得我國在教育領域的智能分析有可能形成區別歐美國家的特色技術,因為它還被中國上億的學生應用,行為也關聯在其中。
除了上述行為數據、知識數據之外,還有一些社會數據。比如說學生跟家長的關聯,家長跟老師的關聯,老師跟學生的關聯等等。
針對海量數據進行智能分析
我們對行為、知識的數據進行量化,為每個知識點配置相應的權重、難度和考試頻次,為人工智能要做的事情做積累。
分析出高頻題目,重點學習
假設構建一個有幾千知識點的知識樹,通過分析,就可從中判斷出近百個高頻知識點。學生只需要覆蓋到最高頻的題目,就可以獲得相對較好的成績,考上一所不錯的大學,同時又對重要的知識有一個更強的認知。
具體實現可通過大數據平臺,對題庫中的題目進行題目畫像,分析出相應知識點和難度。再結合學生的行為對學生進行用戶畫像。
最后對題目和學生進行關聯分析,不僅能夠提取出歷年高考的高頻考點,還能針對每一個學生提供個性化的學習方案。
那么反過來說,是不是一定要刷海量題庫?答案是不一定的。之所以去盲目的刷海量題庫,是因為不知道哪些是重點。
當知道內容重點的情況下,學生只需要刷 50%,甚至 40% 的基本題,就可以獲得好的分數,且知識框架更為牢固。所以說,在不需要題海戰術的情況下,學生就可以更大的產能去覆蓋更好的空間。
搭建圖譜化題庫,實現精準知識搜取
梳理數據,利用深度學習、機器學習等技術手段搭建題庫,再針對數學、化學、物理、生物這些主要學科搭建知識圖譜,能夠有效的組織 k12 領域(幼兒園到高中階段)的各種知識的結構化。
有了這個特殊的題庫,當學生在搜索某個知識點時,雖然行為看起來很微觀,但實際打開之后,是更宏觀的世界,如下圖:
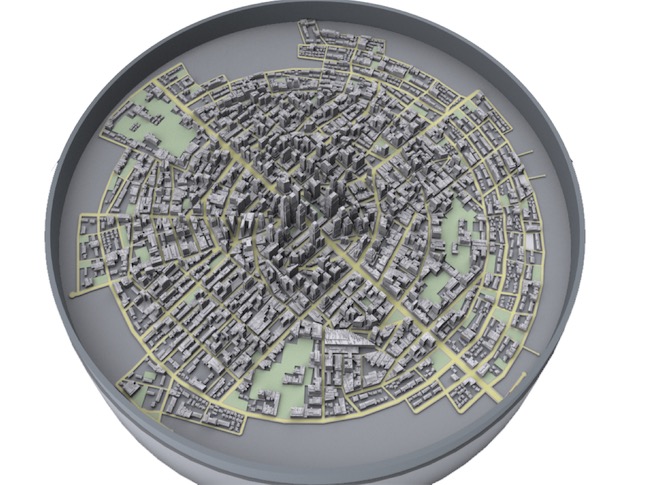
宏觀的世界就像是地圖,把每棟樓比作一道題,重新深入學習,把知識點較近的題目聚攏到一起,偏離較遠的排斥開,映射成一張類似于地圖的結構。這樣做有什么好處呢?陳銳鋒把學習過程類比成騎摩拜單車,騎過路線等同于做作業、考試學習的內容。當學生做某一道題,拍過或者閱讀過某道題,就會把位置記錄下來,就像摩拜記錄在某個地方取車還車一樣。
同時還可以記錄學生對錯的數據,基于錯題分析,進行個人畫像,如下圖:
當對一個學生有一定的數據積累以后,就可以更清晰地勾勒他的學習軌跡。這樣一來,就很好地避免了千人一面的問題。也就是把電商常用的千人千面或出行常用的技術用到教育領域。
還有一個效果是對學生做某些題目的對錯情況進行分析,可對這個學生進行歸類,歸到已有學生群體中的某一類。如這個學生幾何好,就為他排除幾何題,推薦代數題。因為不同的知識點,不同的板塊的學習內容,對學生抽象思維的能力要求各有不同;如男生在創新、沒有邊界的方向上會比較強,而女生在嚴謹性、嚴密性和架構性上會更強一點。
構建學習場景為教學做支撐
在大規模收集數據,利用智能手段進行分析搭建題庫之后,下面要做的就是構建學習場景,為教學做支撐。
場景一:遇到問題,拍照搜題,實時得到解答
記憶不可以移植,所以老師一講,學生就懂這種理想的狀態很少見。一般來說,課堂授課猶如撥號上網會產生丟包,老師講了很多,學生收集到的只是整個網絡里面的一些節點。學生以為聽懂了,但這其中的關聯和關系并沒有記憶在大腦里,所以就需要拍照搜題這一功能。大腦,對于我們來說就是一個黑盒,理論來講對于不可觀不可控的黑盒系統,需要通過它外圍的情況去捕捉有用的數據。
想要知道一個學生不懂什么,就要觀測他經常關注哪些,做什么樣的題目出現了問題,這些可以直觀反映出他不懂的內容并進行標識。拍照搜題,就是一個天然的收集學生不懂問題的通道。這里涉及到眾多的識別技術,如下圖:
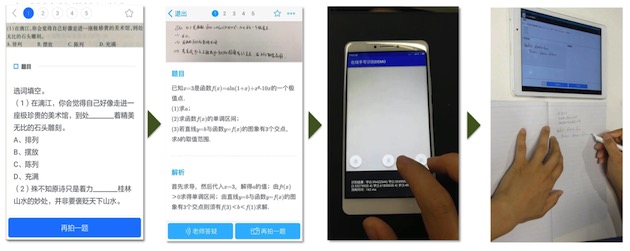
圖中依次是對印刷體拍攝、手寫體拍攝、手寫單字聯機、復雜手寫體聯機的識別,智能識別引擎在這里發揮著作用。
對于印刷體的識別,使用卷積神經網絡提取圖像特征,進行版面分析,將圖像切分,之后分別識別出每一個字。對于手寫體的識別,將在下面講到。
場景二:根據作業情況有針對性的刷題和推薦練習
在 C 端,學生完成作業之后,拍照上傳幾分鐘就可以知道所有題目的對錯,系統會自動給出評判,根據結果給出自適應練習,做到今日事今日畢。
如下圖,是學習數據識別與收集的流程:

學生手寫的解題答案,首選通過卷積層神經網絡進行初步計算,之后通過循環神經網絡形成有梯度的數據結構,最后到達解碼層進行解碼。
針對學生的手寫筆跡,首先采用卷積神經網絡對圖像進行多次卷積下采樣,實現手寫筆跡的行分割,之后對每一行結合非極大抑制方法進行筆畫分割,從而把每一行的筆跡都轉化為序列識別問題。再通過多層循環神經網絡解碼輸出高精度的識別結果。
在 B 端,如果每個班級的學生都把作業上傳,由系統進行評改之后,映射到知識圖譜、行為圖譜中,老師就可以掌握每個學生的學習情況。
傳統教學中,就算是特級老師也沒有辦法記憶每個學生的每個細節,沒法形成閉環,因為相關數據不進系統,需要老師去完成閉環銜接的環節。
這時老師就變成這個環節里面的一個瓶頸,從某種程度來說,既弱化了老師的價值,又使得學生的需求得不到及時響應。
老師最大的價值應該是育人,去引導,而不是幫每個學生去記憶哪個題存在問題。而采用這樣的方式后,節省人力的同時還可以把這些相關數據都沉淀下來,形成閉環。
場景三:學生可以進行自我評測和練習
學霸君基于大數據與智能分析對 8000 萬題庫進行了梳理,提供給學生做自適應的自我評測。然后把評測結果反饋給學生的同時有針對性地推薦練習題。
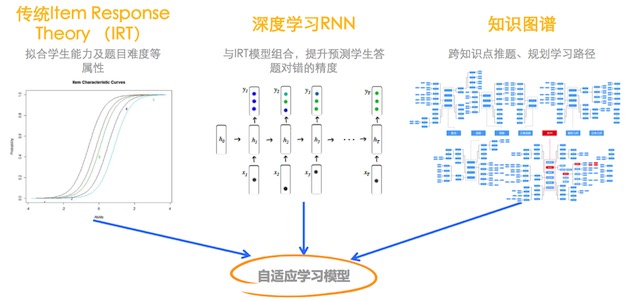
目前實現的效果是綜合學生能力、題目難度等屬性,與 IRT 模型相組合,提升預測學生答題對錯的精度,并為學生跨知識點推送題目、規劃學習路徑。
關于未來
當問及對未來教育方面的暢想,陳銳鋒回答:“未來希望學習過程更輕松一點,把學習變成一個愉快的事情,把反復的遇到瓶頸并且得不到解答的痛苦減到最小,有問題可以得到及時的解答。想了解的,通過無論是軟件資源,還是遠程的老師資源,得到一些支持服務,使學生在信息的獲取上得到及時響應。當然,這需要有大量的數據沉淀,真正了解學生背后想了解什么,才能做到個性化的推送所需要的內容知識。”
做到這些還需要面臨很多的挑戰:
更深度層次,更智能化的,更能抓住細節的一個分析框架。如,是不是能夠分析學生手寫的節奏,進而分析他的性格,像比較好動、比較拖延等性格行為,且從性格行為上給予梳理。因為有時候,學生的行為不僅僅是知識,也可以影響學習效率。
能否擁有一個更全的數據。因為無論是做題庫,做內容,做文庫,做其他相應的學習視頻,數據量雖然很大,但只是覆蓋了其中一部分,我們還想覆蓋得更全。
理論層次上有更體系化的梳理。中國現在的 AI+ 教育或是教育 +AI,實際上是沒有一個非常成型的理論體系,希望能夠把這兩個模塊放在一塊,產生行之有效的理論方向,能夠指導去做后面的事情。
新加坡國立大學博士,2013 年入職學霸君,擔任技術研究負責人職務,組建智能計算團隊,主攻文字識別、圖像算法和數據挖掘方向。帶領團隊在國內率先開創同時適應自然場景、復雜版式圖像拍照識別引擎,為搜題及 1V1 實時答疑業務奠定了技術基礎。同時,將基于深度學習的文本挖掘技術引入產品,實現高效而智能化的知識導航。

【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】

















