顛覆傳統安全方式,AI重新定義Web安全
從 2006 年 Amazon 發布 EC2 服務至今,已經過去了 11 年。在這 11 年里,AWS 收入從幾十萬美金上漲到 100 多億美金,讓云計算走進每一家企業。
根據信通院發布的“2016 云計算白皮書”,目前近 90% 的企業已經開始使用云計算(包括公有云、私有云等),這說明大規模云化對于企業而言已經不只是趨勢,更是確鑿的既成事實。
云化普及的同時也給安全帶來很多挑戰,主要包括:
01云化導致以硬件設備為主的傳統安全方式失效
在跟企業交流時,不止一家企業提出了這樣的擔心:在上公有云的過程中,因為無法把已購買的硬件防護搬到云上,所以非常擔心業務安全性。
有趣的是,他們對于上云后的流量層攻擊反倒不擔心,因為他們認為云上的高防 IP 等產品可以解決大部分問題。云化導致了業務層的安全空白,這不僅發生在公有云環境,在私有云環境也時有發生。
02云化導致攻擊/作惡成本大大降低
云是 IT 領域里“共享經濟”的再升級,從最早的 IDC 租用升級進化到 Linux kernel namespace 租用,但這種“共享經濟”在給企業帶來成本降低、使用便利等益處的同時,也給攻擊者帶來了同樣的好處。
按目前市場行情,攻擊者租用一個公網彈性 IP 的成本可低至 1 元/天,租用一個 IaaS 平臺的 hypervisor 層的計算環境,每日成本也只有幾元,如果是 container 層的計算環境,成本還要更低。
在如此低的成本下,致使攻擊者不再像過去那樣花大力氣挖掘培養肉機,而是可以在瞬間輕松擁有用于攻擊的計算網絡資源。
以某著名互聯網招聘領域網站為例,攻擊者最多可以在一天內動用上萬個 IP 以極低的頻率爬取核心用戶簡歷。
03云化導致業務可控性降低,遭遇攻擊的風險大大提高
云客觀造成了業務的復雜性和不可控性:大量自身或合作方的業務都跑在同一個云上,其中任何一個業務被攻擊,都有可能對其他部分造成影響。
不可否認的是,現有的 hypervisor 隔離技術很成熟,以 CPU 為例,通過計算時間片分配進而在執行指令間插入各種自旋鎖,可以精確控制執行體的 CPU 分配,其他資源包括內存、IO 也都可以恰當的控制。
但在所有資源里,隔離性最脆弱的就是網絡,尤其是公網,畢竟 NAT 出口、域名等很難被隔離。
所以,我們不得不面對這樣的現實:在享受云計算時代紅利的同時,面臨的業務層安全問題也越來越嚴重。
機器學習是解決安全問題的金鑰匙
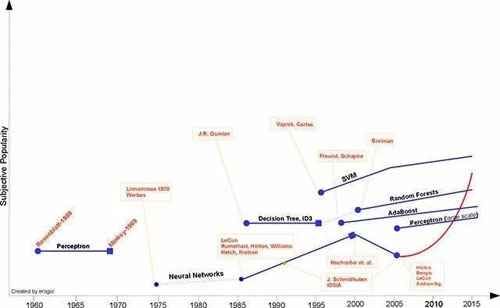
機器學習發展史
由上圖可以看出,目前大紅大紫的深度學習,其源頭-神經網絡,早在上世紀 70 年代就已經被提出。
從上世紀 80 年代到本世紀,機器學習經歷了幾次平淡期和爆發期,隨著大數據的發展和一些熱點事件(如 AlphaGo 戰勝李世石),機器學習又一次進入爆發期。
那么,大數據和機器學習有什么關系呢?這還要和深度學習掛鉤,從理論上講,深度學習本質上是利用多層的神經網絡計算,代替傳統特征工程的特征選取,從而達到媲美甚至超越傳統特征工程進行分類算法的效果。
基于這個邏輯,當標注樣本足夠多時(即所謂“大數據”),通過深度學習就可以構造出非常強大的分類器,如判斷一個圍棋的棋局對哪方有利。
AI 隨著深度學習的火爆看似非常強大,但不幸的是,目前 AI 的發展成熟度遠沒有達到可以取代人腦抑或接近人腦的水平。根據圖靈測試理論,AI 本身要解決的問題有:識別、理解、反饋。
這三個問題逐步遞進,真正智能的機器人最終可以跟人腦一樣反饋,從而在圖靈測試中無法區分它是人還是機器。
按當前 AI 發展情況,“識別”的進展目前效果最好,無論是圖像、語音還是視頻,很多廠商都可以做到很高的識別率;但“理解”就差強人意了,大家都用過蘋果的 Siri,它還未能達到與人真正對話的程度。
而反饋就更難了,這要求在理解的基礎上不斷地應變,同一個問題可能因對方身份、心情、交流場合不同,以不同的語氣語調做出不同反應。
所以,目前應用機器學習效果非常好的領域,幾乎都是某個特定領域內的識別問題,并非通用領域,如人臉識別、人機對弈(人機對弈本質上也是某個棋種領域的識別問題:機器通過學習成千上萬的棋局后,就可以自動識別某一棋局在一方走的情況下對誰有利。)
非常幸運的是,安全領域中的問題大多是特定場景下的識別問題,而非通用場景,也并未涉及理解和反饋,你只需要把相關數據交給機器學習系統,讓它做出識別判斷即可:安全或者不安全,不安全的原因。
正因為安全問題本質是特定領域內的識別問題,所以從理論上講,機器學習非常適合應用在安全領域,是解決安全問題的金鑰匙。
機器學習在安全領域的應用難點
雖然機器學習早已存在,但是長久以來并未改變安全市場,究其原因,主要有以下幾點:
01安全領域的樣本標注成本較高
對于機器學習而言,擁有海量、完整、客觀、準確的標注樣本異常重要,標注樣本越多、越全面,訓練出來的分類器才可能越準確。
對于所有行業來講,獲取樣本(標注樣本)都不容易,而安全領域尤為困難。如對人臉識別的標注,初中生甚至小學生就可以完成,但對于一次安全的威脅事件,就需要極具經驗的安全人員才可以完成,兩者的成本差距十分巨大。
![]()
某個注入攻擊
如上圖所示,這個注入攻擊經多次復雜編碼,非專業人事很難進行樣本標注。所以目前在通用場景下,安全領域的深度學習落地并不多,主要原因也是很難獲取海量的標注數據。
02安全領域的場景特點更加明顯
判斷攻擊的標準會隨著業務特點的不同而不同。以最簡單的 CC 攻擊為例,600 次/ 分鐘的訪問對于某些企業可能意味著破壞性攻擊,但對其他企業則屬于正常訪問范圍。
所以,即便有大量的標注樣本,某一企業的標注樣本可能對于其他企業毫無用處,這也是導致安全領域應用機器學習較為困難的另一個重要原因。
03針對傳統的文本型攻擊,傳統思維認為簡單的特征工程,甚至直接的正則匹配更有效
我們把 Web 攻擊分為行為型攻擊和文本型攻擊兩類:
- 行為型攻擊。每個請求看起來都是正常的,但將其連接成請求走勢圖時,就會發現問題,如爬蟲、撞庫、刷單、薅羊毛等。
以刷粉行為為例:每個請求看起來都是正常的,但攻擊者可能動用大量 IP 在短時間內注冊大量賬號,并關注同一個用戶。只有我們把這些行為連接起來一起分析時,才能發現問題。
- 文本型攻擊。傳統的漏洞類攻擊,如 SQL 注入、命令注入、XSS 攻擊等,單純的把一個請求看成是一段文本,通過文本的特征即可識別其是否為攻擊。
當特征的維度空間較低,且有些維度的區分度很高時,通過簡單的線性分類器,就可以實現不錯的準確率。
例如我們簡單的制定一些 SQL 注入的正則規則,也可以適用于很多場景。但是,這樣的傳統思維卻忽略了召回率問題,實際上也很少有人知道,通過 SQL 注入的正則規則,可以達到多少的召回率。
同時,在某些場景,假如業務的正常接口通過 JSON 傳遞 SQL 語句,那么這種基于正則規則的分類器就會產生極高的誤判。
04傳統安全人員并不了解機器學習
大量傳統安全公司的安全人員精于構造各種漏洞探測、挖掘各種邊界條件繞過,善于制定一個又一個的補丁策略,卻并不擅長 AI 機器學習方面的內容,這也說明了這種跨界人才的稀缺和重要。
機器學習重新定義 Web 安全
如何解決安全領域的樣本標注問題呢?機器學習分為兩大類:
監督學習。要求有精準的標注樣本。
無監督學習。無需標注樣本,即可以針對特征空間進行聚類計算。在標注困難的安全領域,顯然無監督學習是一把利器。
01無監督學習
無監督學習無需事先準備大量標注樣本,通過特征聚類就可以將正常用戶和異常用戶區分開,從而避免大量樣本標注的難題。
聚類的方式有很多,如距離聚類、密度聚類等,但其核心仍是計算兩個特征向量的距離。
在 Web 安全領域,我們獲得的數據往往是用戶的 HTTP 流量或 HTTP 日志,在做距離計算時,可能會遇到如下問題。
例如:每個維度的計算粒度不一樣,如兩個用戶的向量空間里 HTTP 200 返回碼比例的距離是兩個 float 值的計算,而 request length 的距離則是兩個 int 值的計算,這就涉及粒度統一歸一化的問題。
在這方面有很多技巧,比如可以使用 Mahalanobis 距離來代替傳統的歐式距離,Mahalanobis 距離的本質是通過標準差來約束數值,當標準差大時,說明樣本的隨機性大,則降低數值的權值。
反之,當標準差小的時候,說明樣本具有相當的規律性,則提高數值的權值。
無監督的聚類可以利用 EM 計算模型,可以把類別、簇數或者輪廓系數(Silhouette Coefficient)看成 EM 計算模型中的隱變量,然后不斷迭代計算來逼近最佳結果。
最終我們會發現,正常用戶和異常聚成不同的簇,之后就可以進行后續處理了。當然,這只是理想情況,更多情況下是正常行為與異常行為分別聚成了很多簇,甚至還有一些簇混雜著正常和異常行為,那么這時就還需要額外的技巧處理。
02學習無監督聚類的規律
無監督聚類的前提是基于用戶的訪問行為構建的向量空間,向量空間類似:
- [key1:value1,key2:value2,key3:value3...]
這里就涉及兩個問題:“如何找到 key”以及“如何確定 value”。
找到合適 key 的本質是特征選擇問題,如何從眾多的特征維度中,選擇最具有區分度和代表性的維度。
為什么不像某些 Deep Learning 一樣,將所有特征一起計算?這主要是考慮到計算的復雜度。請注意:特征選擇并不等同于特征降維,我們常用的 PCA 主成分和 SVD 分解只是特征降維,本質上 Deep Learning 的前幾層某種意義上也是一種特征降維。
特征選擇的方法可以根據實際情況進行。實驗表明在有正反標注樣本的情況下,隨機森林是一個不錯的選擇。如果標注樣本較少或本身樣本有問題,也可以使用 Pearson 距離來挑選特征。
最終,用戶的訪問行為會變成一組特征,那特征的 value 如何確定?以最重要的特征——訪問頻率為例,多高的訪問頻率值得我們關注?這需要我們對于每個業務場景進行學習,才能確定這些 key 的 value。
學習的規律主要包括兩大類:
- 行為規律。自動找出路徑的關鍵點,根據狀態轉移概率矩陣,基于 PageRank 的 power method 計算原理,網站路徑的狀態轉移矩陣的最大特征值就代表其關鍵路徑(關鍵匯聚點和關鍵發散點),然后順著關鍵點,就可以學習到用戶的路徑訪問規律。
- 文本規律。對于 API,可以通過學習得出其輸入輸出規律,如輸入參數數量、每個參數的類型(字符串 or 數字 or 郵箱地址等)、參數長度分布情況,任何一個維度都會被學習出其概率分布函數。
然后就可以根據該函數計算其在群體中的比例。即便是最不確定的隨機分布,利用切比雪夫理論也可以告訴我們這些值異常。
假如 GET /login.php?username = 中的 username 參數,經過統計計算得出平均長度是 10,標準差是 2,如果有一個用戶輸入的 username 長度是 20,那么該用戶的輸入在整體里就屬于占比小于 5% 群體的小眾行為。
通過特征選擇和行為、文本規律學習,我們就可以構建出一套完整且準確的特征空間將用戶的訪問向量化,進而進行無監督學習。
03讓系統越來越聰明
如果一個系統沒有人的參與,是無法變得越來越聰明的,如 AlphaGo 也需要在同人類高手對弈中不斷強化自己。
在安全領域,雖然完全的樣本標注不可能,但是我們可以利用半監督學習的原理,挑選具有代表性的行為交給專業的安全人員判斷,經過評定校正,整個系統會越發聰明。
安全人員的校正可以與強化學習和集成學習結合實現,對于算法判斷準確的情況,可以加大參數權重,反之則可以適當減少。
類似的想法出現于國際人工智能頂級會議 CVPR 2016 的最佳論文之一,“AI2: Training a big data machine to defend”,MIT 的 startup 團隊,提出了基于半監督學習的 AI2 系統,可以在有限人工參與的情況下,讓安全系統更安全更智能。
04重新定義 Web 安全
基于上述幾點,我們基本可以勾勒出基于 AI 的 Web 安全的基本要素:
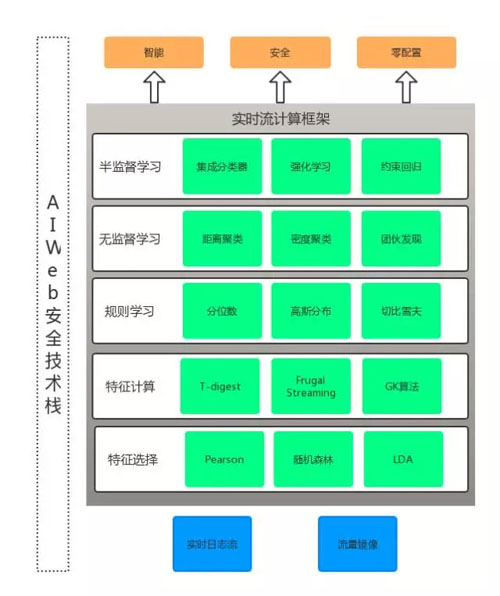
AI Web 安全技術棧
從上圖可以看到,所有算法均包含在實時計算框架內。實時計算框架要求數據流的輸入、計算、輸出都是實時的,這樣才可以保證在威脅事件發生時,系統可以迅速做出反應。
但是,實時計算的要求也增加了很多挑戰和難點,一些傳統離線模式下不是問題的問題,在實時計算下會突然變成難題。
比如最簡單的中位數計算,要設計一套在實時流輸入的情況下,同時還能保證準確性的中位數算法并不容易,T-digest 是一個不錯的選擇,可以限定在 O(K)的內存使用空間。還有一些算法可以實現在 O(1)內存占用的情況下計算相對準確的中位數。
綜上所述,我們可以看出利用 AI 實現 Web 安全是一個必然的趨勢,它可以顛覆傳統基于 policy 配置模式的安全產品,實現準確全面的威脅識別。
但是,構造基于 AI 的安全產品本身也是一個復雜的工程,它涉及特征工程、算法設計和驗證,以及穩定可靠的工程實現。

總之,基于 AI 的 Web 安全是新興的技術領域,雖然目前還處于發展期,但最終一定會取代以 policy 為驅動的傳統安全產品,成為保證企業 Web 安全的基石。
叢磊
白山云科技合伙人兼工程副總裁
2006 年至 2015 年就職于新浪,原 SAE(SinaAppEngine)創始人,曾任總負責人兼首席架構師。2010 年起,帶領新浪云計算團隊從事云相關領域的技術研發工作。他擁有 10 項發明專利,現任工信部可信云服務認證評委。2016 年加入白山云,主要負責云聚合產品的研發管理和云鏈產品體系構建等。