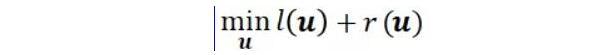大規模機器學習系統中的No Free Lunch
作為第四范式•先知平臺核心機器學習框架GDBT的設計者,涂威威在大規模分布式機器學習系統架構、機器學習算法設計和應用等方面有深厚積累。演講中,涂威威表示,現在有越來越多的企業開始利用機器學習技術,把數據轉換成智能決策引擎。企業機器學習應用系統中的核心模型訓練系統有著什么樣的設計和優化的考慮?與教科書中的機器學習應用相比,企業實際的機器學習應用中有哪些容易被人忽略的陷阱?涂威威對此作了經驗分享,同時給出了一些可供參考的解決方案。
工業界大規模分布式機器學習計算框架的設計經驗
機器學習的經典定義,是利用經驗(數據)來改善系統性能。在應用過程中,首先要明確機器學習目標的定義,也就是用機器學習來做什么事情。以谷歌提升搜索廣告業務收入為例,谷歌首先對提升收入的目標進行拆解,廣告收入=平均單次點擊價格點擊率廣告展現量,其中“廣告展現量”被硬性控制(考慮到政策法規和用戶體驗),“單次點擊價格”受廣告主主動出價影響,與上面兩者不同,“點擊率”的目標明確,搜索引擎記錄了大量的展現點擊日志,而廣告候選集很大,不同廣告的點擊率差別很大,谷歌廣告平臺有控制廣告展現的自主權,因此對于谷歌提升搜索廣告收入的問題而言,機器學習最適合用來優化“廣告點擊率”。在確定了機器學習具體的優化目標是廣告點擊率之后,谷歌機器學習系統會循環執行四個系統:數據收集→數據預處理→模型訓練→模型服務(模型服務產生的數據會被下一個循環的數據收集系統收集)。在這四個系統中,與機器學習算法最相關的就是模型訓練系統。

在涂威威看來,計算框架設計上,沒有普適的***框架,只有最適合實際計算問題的框架。
針對機器學習的兼顧開發效率和執行效率的大規模分布式并行計算框架
在工業應用中,有效數據、特征維度正在迅速攀升。在數據量方面,以往一個機器學習任務僅有幾萬個數據,如今一個業務的數據量已很容易達到千億級別。在特征維度方面,傳統的機器學習采用“抓大放小”的方式—只使用高頻宏觀特征,忽略包含大量信息的低頻微觀特征—進行訓練,但隨著算法、計算能力、數據收集能力的不斷增強,更多的低頻微觀特征被加入到機器學習訓練中,使模型的效果更加出色。
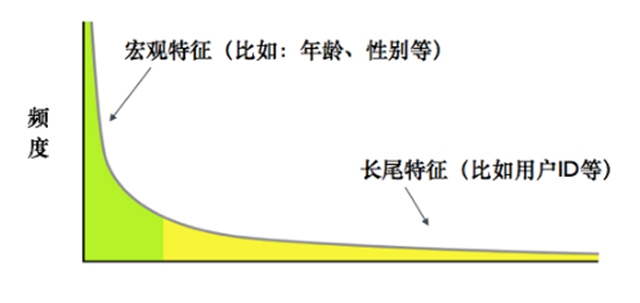
特征頻率分布
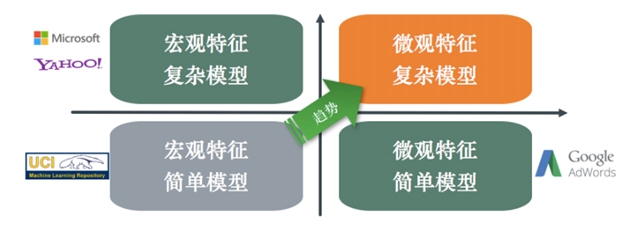
機器學習技術也在工業應用中不斷發展,最早期的機器學習工業應用只利用宏觀特征、簡單模型,到后來發展為兩個不同的流派:以微軟、雅虎為代表的只利用宏觀特征但使用復雜模型流派,以谷歌為代表的使用簡單模型但利用微觀特征流派,到現在,利用更多微觀特征以及復雜模型去更精細地刻畫復雜關系已是大勢所趨。這便對模型訓練提出了更高的要求。
其一,訓練系統需要分布式并行。由于功率墻(Power Wall,芯片密度不能***增長)和延遲墻(Latency Wall,光速限制,芯片規模和時鐘頻率不能***增長)的限制,摩爾定律正在慢慢失效,目前,提升計算能力的方式主要是依靠并行計算,從早期的以降低執行延遲為主到現在的以提升吞吐量為主。在模型訓練的高性能計算要求下,單機在IO、存儲、計算方面的能力力不從心,機器學習模型訓練系統需要分布式并行化。當然我們也需要牢記Amdahl定律。
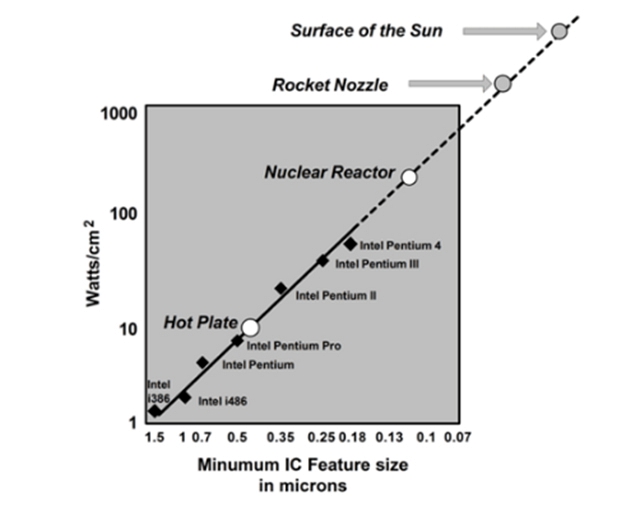
Power Wall,功耗隨著集成電路密度指數提升
其二,訓練框架需要高開發效率。機器學習領域里,一個著名的定理叫No Free Lunch[Wolpert and Macready 1997],是指任意算法(包括隨機算法)在所有問題上的期望性能一樣,不存在通用的算法,因此需要針對不同的實際問題,研發出不同的機器學習算法。這就需要機器學習計算框架的開發效率非常高。
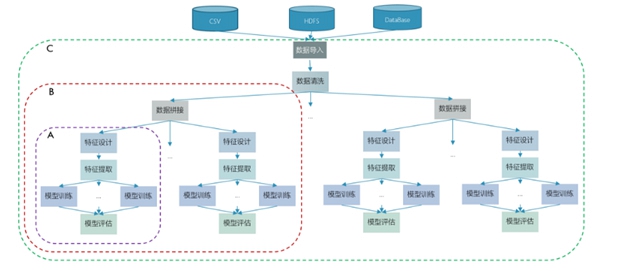
典型的機器學習建模過程
其三,訓練系統需要高執行效率。在面對實際問題時,需要對數據、特征表達、模型、模型參數等進行多種嘗試,且每一次嘗試,都需要單獨做模型訓練。所以,模型訓練是整個機器學習建模過程中被重復執行最多的模塊,執行效率也就成為了重中之重。
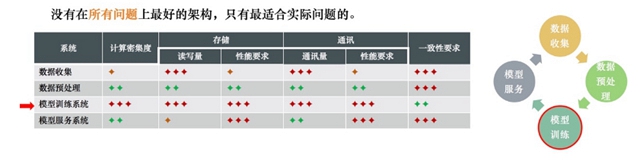
機器學習核心系統對計算資源的需求對比
其四,底層框架的No Free Lunch。對于不同的計算問題,計算的模式和對各種計算資源的需求都是不一樣的,因此沒有在所有問題上***的架構,只有最適合實際問題的架構。針對機器學習任務的特性進行框架設計才能更有效地解決大規模機器學習模型訓練的計算問題。
開發效率的優化
在提高開發效率上,這里分享計算和編程模式的選擇、編程語言的選擇兩個方面。
并行計算范式分為兩種,一種是基于共享內存的并行計算范式,不同的計算節點共享同一塊內存,這里底層需要處理訪存沖突等問題,這種模式一般被用在小規模處理器的情況,比如單機多處理器;另外一種是基于消息傳遞的并行計算范式,每個計算節點使用自己的內存,計算節點之間通過消息傳遞的模式進行并行計算。在實際的分布式并行系統中,多機器之間一般基于消息傳遞,單機內部一般基于共享內存(也有一些系統基于消息傳遞)。
機器學習的分布式模式,又分為數據分布式和模型分布式。數據分布式是指將訓練數據切成很多份,不同的機器處理一部分數據。但對于一些較大的模型,單機可能沒有辦法完成整個模型的運算,于是把模型切成很多份,不同機器計算模型的不同部分。在實際應用過程中,根據不同的場景需要,二者一般是并存的。
數據分布式和模型分布式
機器學習模型訓練中常見的分布式并行計算模型
最常見的就是分布式數據流計算模型。數據流模型是一種數據驅動的并行計算執行模型。數據流計算邏輯基于數據流圖表達。 用戶通過描述一個計算流圖來完成計算,對計算流圖中的計算節點進行定義,用戶一般不需要指定具體執行流程。數據流圖內部不同數據的計算一般是異步完成的,其中的計算節點只要上游ready就可以執行計算邏輯。目前主流的ETL(Extract-Transform-Load)數據處理框架比如Hadoop、Spark、Flink等都是基于數據流計算模型。但是機器學習計算任務有一個共享的不斷被擦寫的中間狀態:模型參數,計算過程會不斷的讀寫中間狀態。數據流的計算模型在執行過程中一般是異步的,所以很難對共享中間狀態——模型參數,進行很好的一致性控制。所以基于數據流計算模型的一致性模型一般都是同步的,在數據流內部保證強一致性,但是基于同步的系統執行性能取決于最慢的計算節點,計算效率比較低。
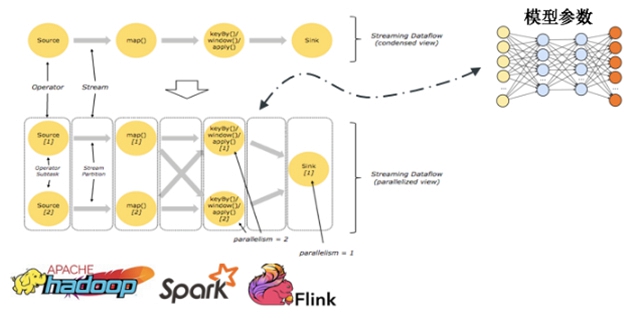
數據流計算模型中的模型參數困惑
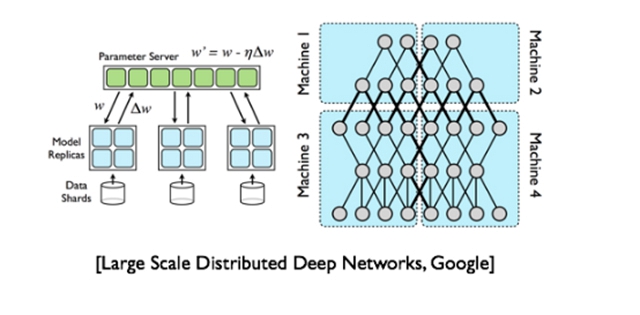
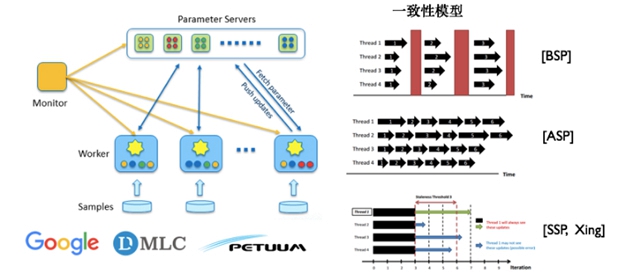
另一個常見的分布式并行計算模型就是基于參數服務器的分布式計算模型。參數服務器就是對機器學習模型訓練計算中的共享狀態——模型參數管理的一種直觀的抽象,對模型參數的讀寫由統一的參數服務器管理,參數服務器本質上就是一個支持多種一致性模型的高性能Key-Value存儲服務。基于參數服務器可以實現不同的一致性模型,一個極端就是BSP(Bulk Synchronous Parallel,同步并行),所有的計算節點在計算過程中都獲取一致的模型參數,對于算法實現而言有一致性的保障,但是代價是同步造成的資源浪費;另一個極端是ASP(Asynchronous Parallel,異步并行),所有的計算節點在計算過程中彼此之間的模型參數沒有任何的一致性保證,計算節點之間完全異步執行,這種一致性模型計算效率很高,但是模型參數沒有一致性保證,不同節點獲取到的是不同版本的模型,訓練過程不穩定,影響算法效果;CMU的Erix Xing教授提出了介于BSP和ASP兩者之間的SSP(Stale Synchronous Parallel),通過限制***不一致的參數版本數來控制整體的同步節奏,這樣既能緩解由于同步帶來的執行效率問題,又使得算法相對于ASP在收斂性質上有更好的保證。基于不同的一致性模型可以很好地在運行速度和算法效果上進行權衡。
其實,數據流計算模型和參數服務器計算模型刻畫了機器學習模型訓練計算過程的不同方面,機器學習的樣本數據的流動用數據流來描述就很自然,模型訓練過程中的中間狀態可以被參數服務器計算模型自然的描述。因此,這兩者進行結合是整體的發展趨勢:在數據流中對參數服務器進行讀寫操作,比如Intel就開發了Spark上的參數服務器。但是數據流計算模型和參數服務器計算模型的一致性模型不盡相同,參數服務器的一致性模型比如BSP或者SSP都會打破數據流原有的異步計算邏輯。參數服務器和數據流結合的災備策略和一致性管理策略需要仔細的設計才能很好地統一和融合。
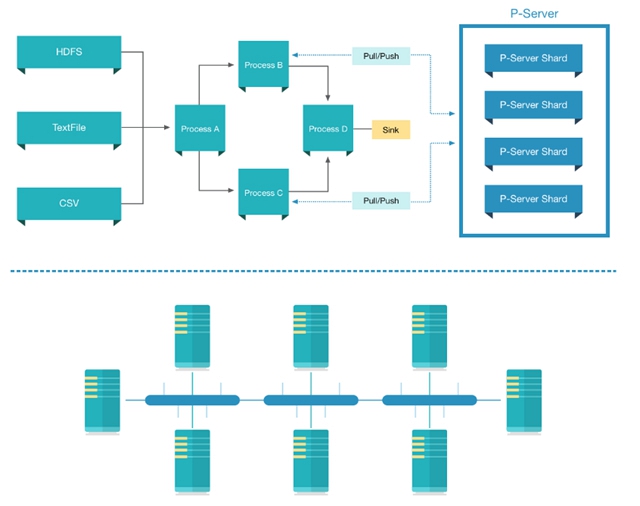
數據流和參數服務器結合的架構
編程模型和編程語言的選擇
編程范式可以分為兩種,命令式與聲明式。命令式編程通過顯式指定具體執行流程來進行編程,常見的命令式語言是C/C++等;與命令式編程不同,聲明式編程不顯示指定具體執行流程,只定義描述計算任務目標,將具體執行交由底層計算框架決定。命令式編程由于顯式指定具體執行流程會顯得更加靈活,而聲明式編程底層計算框架可以針對執行流程進行更深入的優化從而可能會更加高效。在實際的機器學習模型訓練計算框架中,兩者其實一般是并存的,比如MxNet、Tensorflow等。

求和運算的命令式實現和聲明式實現比較
為了兼顧運行效率和易用性,機器學習模型訓練計算框架的編程語言的選擇一般采用前后端分離的方式:以C/C++、Java/Scala等作為后端以保證系統運行效率,使用Python、R等作為前端以提供更為易用的編程接口。對于后端語言的選擇上,主流的就是Java和C++,這兩者各有優劣:
在生態上,Java由于易于開發使得其生態要遠遠好于C++,很多大數據計算框架都基于Java或者類Java語言開發;
在可移植性上,由于JVM屏蔽了很多底層差異性,所以Java要優于C++;
在內存管理上,基于GC的Java在大數據、同步分布式并行的情況下,效率要遠低于優化過的C++的效率,因為大數據情況下,GC的概率會很高,而一旦一臺服務器開始GC其計算能力將受很大影響,整體集群尤其在同步情況下的計算效率也會大打折扣,而機器數增加的情況下,在一定時刻觸發GC的概率也會大大增加;
在語言抽象上,C++的模板機制在編譯時刻進行展開,可以做更多的編譯優化,在實際執行時除了產生的程序文件更大一些之外,整體執行效率非常高,而與之對應的Java泛型采用類型擦除方式實現,在實際運行時做數據類型cast,會帶來很多額外的開銷,使得其整體執行效率受到很大影響。
在實際機器學習模型訓練系統的設計上,具體的選擇取決于框架設計者的偏好和實際問題(比如系統部署要求、開發代價等)的需求。
執行效率的優化
執行效率優化方面主要舉例分享計算、存儲、通訊、容錯四個方面的優化。
在計算方面,最重要的優化點就是均衡。均衡不僅包括不同的機器、不同的計算線程之間的負載均衡,還包括算術邏輯運算資源、存儲資源、通訊資源等等各種與計算有關資源之間的均衡,其最終目的是***化所有計算資源的利用率。在實際的優化過程中,需要仔細地對程序進行Profiling,然后找出可能的性能瓶頸,針對性能瓶頸進行優化,解決瓶頸問題,但是這時候性能瓶頸可能會轉移,就要繼續迭代:Profiling→發現瓶頸→解決瓶頸。
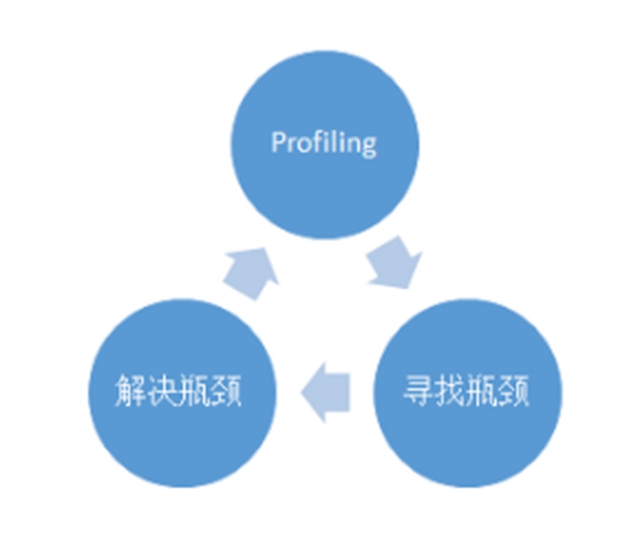
典型的計算性能優化循環
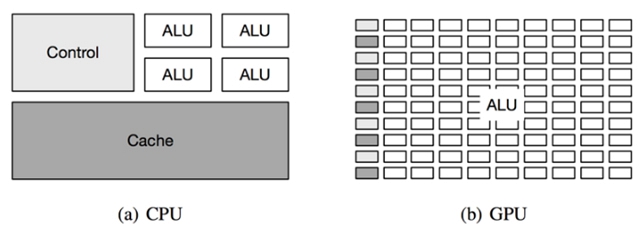
CPU和GPU的架構對比
分布式計算是有代價的,比如序列化代價、網絡通訊代價等等,并不是所有的任務都需要分布式執行,有些情況下任務或者任務的某些部分可以很好地被單機執行,不要為了分布式而分布式。為了得到更好的計算性能,需要對單機和分布式進行分離優化。
CPU、GPU、FPGA等不同硬件有各自的優勢,比如CPU適合復雜指令,有分支預測,大緩存,適合任務并行;GPU有大量的算術邏輯運算單元,但緩存較小,沒有分支預測,適合粗粒度數據并行,但不適合復雜指令執行,可以用來加速比如矩陣運算等粗粒度并行的計算任務;FPGA對于特定的計算任務,比如深度學習預測,經過優化后有著介于CPU和GPU之間的峰值,同時功耗遠低于GPU芯片。針對機器學習任務需要進行合理的任務調度,充分發揮不同計算硬件的優勢,提升計算硬件的利用率。
近些年CPU、GPU等計算硬件的效率提升速度遠高于主存性能的提升速度,所以計算和存儲上的性能差距在不斷擴大,形成了“存儲墻”(Memory Wall),因此在很多問題上,存儲優化更為重要。在存儲方面,從CPU的寄存器到L1、L2等高速緩存,再到CPU本地內存,再到其他CPU內存,還有外存等有著復雜的存儲結構和不同的存儲硬件,訪問效率也有著量級的差距。Jeff Dean建議編程人員牢記不同存儲硬件的性能數據。

存儲層級架構、性能數據和存儲墻
針對存儲的層次結構和各個層級存儲硬件的性能特性,可以采取數據本地化及訪存模式等存儲優化的策略。因為機器學習是迭代的,可以將一些訓練數據或者一些中間計算結果放在本地,再次訓練時,無需請求遠端的數據;另外在單機情況下,也可以嘗試不同的內存分配策略,調整計算模式,增強數據本地化。在訪存模式優化方面,也可以進行很多優化:數據訪問重新排序,比如GPU中紋理渲染和矩陣乘法運算中常見的Z秩序曲線優化;調整數據布局,比如可以采用更緊致的數據結構,提升順序訪存的緩存***率,同時,在多線程場景下,盡量避免線程之間頻繁競爭申請釋放內存,會競爭同一把鎖。除此之外還可以將冷熱數據進行分離,提升緩存***率;數據預取,比如可以用另外一根線程提前預取數據到更快的存儲中,提升后續計算的訪存效率。
通信是分布式機器學習計算系統中至關重要的部分。通訊包括點對點通訊和組通訊(如AllReduce、AllGather等)。可通過軟件優化、硬件優化的形式提高執行效率。
在軟件優化方面,可以通過比如序列化框架優化、通訊壓縮、應用層優化的方式進行優化:
通訊依賴于序列化,通用序列化框架比如ProtoBuffer、Thrift等,為了通用性、一些前后兼容性和跨語言考慮等會犧牲一定的效率,針對特定的通訊場景可以設計更加簡單的序列化框架,提升序列化效率。
在帶寬成為瓶頸時,可以考慮使用CPU兌換帶寬的方式,比如利用壓縮技術來降低帶寬壓力。
更重要的優化來自于考慮應用層通訊模式,可以做更多的優化:比如參數服務器的客戶端,可以將同一臺機器中多個線程的請求進行請求合并,因為同一次機器學習訓練過程中,不同線程之間大概率會有很多重復的模型參數請求;或者根據參數服務器不同的一致性模型,可以做請求緩存,提升查詢效率,降低帶寬;或者對于不同的網絡拓撲,可以采取不同的組通訊實現方式。
除了軟件優化之外,通訊架構需要充分利用硬件特性,利用硬件來提升網絡吞吐、降低網絡延遲,比如可以配置多網卡建立冗余鏈路提升網絡吞吐,或者部署 Infiniband提升網絡吞吐、降低網絡延遲等。
在容錯方面,對于不同的系統,容錯策略之間核心的區別就在于選擇最適合的Tradeoff。這里的Tradeoff是指每次失敗后恢復任務所需要付出的代價和為了降低這個代價所付出的overhead之間的權衡。在選擇機器學習模型訓練系統的容錯策略時,需要考慮機器學習模型訓練任務的特點:首先機器學習模型訓練是一個迭代式的計算任務,中間狀態較多;其次機器學習模型訓練系統中模型參數是最重要的狀態;***,機器學習模型訓練不一定需要強一致性。
在業界常見的有Data Lineage和Checkpointing兩種機器學習訓練任務災備方案。Data Lineage通過記錄數據的來源,簡化了對數據來源的追蹤,一旦數據發生錯誤或者丟失,可以根據Data Lineage找到之前的數據利用重復計算進行數據恢復,常見的開源項目Spark就使用這種災備方案。Data Lineage的粒度可大可小,同時需要一個比較可靠的維護Data Lineage的服務,總體overhead較大,對于機器學習模型訓練中的共享狀態——模型參數不一定是很好的災備方式,因為模型參數是共享的有著非常多的中間狀態,每個中間狀態都依賴于之前版本的模型參數和中間所有數據的計算;與Data Lineage不同,機器學習模型訓練系統中的Checkpointing策略,一般會重點關注對機器學習模型參數的災備,由于機器學習是迭代式的,可以利用這一點,在滿足機器學習一致性模型的情況下,在單次或多次迭代之間或者迭代內對機器學習模型參數以及訓練進度進行災備,這樣在發生故障的情況下,可以從上一次迭代的模型checkpoint開始,進行下一輪迭代。相比于Data Lineage,機器學習模型訓練系統對模型參數和模型訓練進度進行Checkpointing災備是更加自然和合適的,所以目前主流的專門針對機器學習設計的計算框架比如Tensorflow、Mxnet等都是采用Checkpointing災備策略。
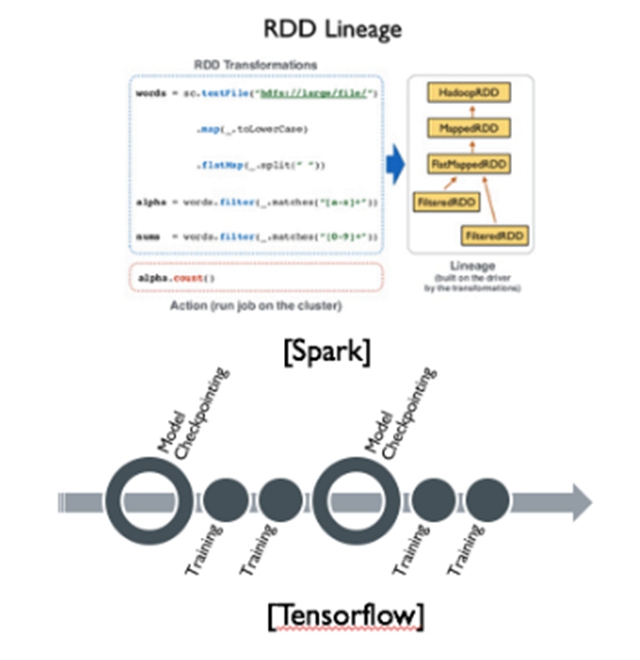
除了上述的容錯方式之外,還可以使用傳統災備常用的部署冗余系統來進行災備,根據災備系統的在線情況,可以分為冷、溫和熱備份方式,實際應用中可以根據實際的資源和計算性能要求選擇最合適實際問題的冗余容錯方式。
機器學習實際應用的常見陷阱
在實際的機器學習應用中,經常會遇到一些容易被忽視的陷阱。這里舉例分享一些常見的陷阱:一致性、開放世界、依賴管理、可理解性/可調試性。
一致性陷阱
一致性陷阱是最常見的容易被忽視的陷阱。
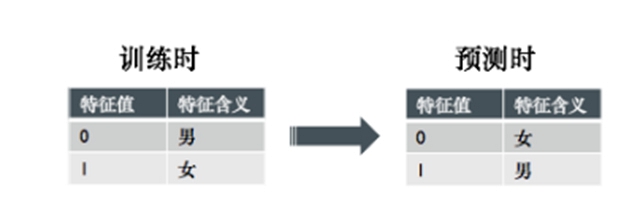
首先訓練/預估一致性問題是最常見的,其中包括特征表達不一致以及目標含義不一致。特征表達不一致較為常見,起因也有很多:表達方式不一是比較常見的,比如在訓練數據中0代表男,1代表女,可是在預估數據中1代表女,0代表男;訓練和評估特征提取中,某一方或者兩方都出現了邏輯錯誤,會導致不一致;有一種比較隱秘的不一致叫“穿越”,尤其在時序數據上特別容易發生,“穿越”就是指特征里包含了違反時序或者因果邏輯的信息,比如有特征是在整個訓練數據集中取該特征時正負例的個數/比例,這里其實隱含使用到了樣本的標注信息,但是實際在預估過程中是不可能提前拿到標注信息的(否則就不需要預估了);又比如某些特征使用了當前樣本時間點之后的信息,但是這在實際的預估中是做不到的,因為目前還無法穿越到未來。還有一種不一致性是目標含義的不一致性,比如目標是優化搜索結果的用戶滿意度,但是卻用用戶點擊作為機器學習的目標,用戶點擊了某個搜索結果不代表用戶對這個結果滿意。
另外一種容易被忽視的一致性是字段含義會隨著時間的推移會發生變化。
在實際應用中需要重點關注一致性測試,留意特征的具體物理含義,避免出現特征表達不一致、目標含義不一致、隨時間變化的不一致的問題。
開放世界陷阱
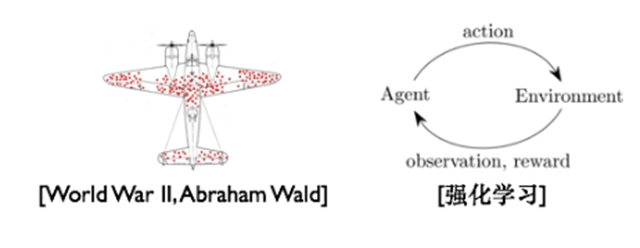
機器學習系統被應用到實際業務中去時,面對的就是一個開放世界,機器學習系統不再是一個靜態孤立的系統,而是需要跟外部世界打交道,這里就有很多的陷阱。其中有一個非常著名的幸存者偏差問題,因為當前的模型會影響下一次模型的訓練數據,如果不做干涉,那么訓練數據是有偏差的。這個偏差***的起源來自二戰期間,科學家團隊研究如何對飛機加固來提升飛機在戰場的存活率,他們找來了戰場上存活下來的飛機上的彈孔進行分析,***得出結論:腹部中彈最多,所以需要在腹部進行加固,可提高存活率。但是,統計學家Abraham Wald指出他們忽略了那些被摧毀的飛機,因為它們被擊中了機翼、引擎等關鍵部位,所以可能更好地保護機翼、引擎等關鍵部位才能提升飛機在戰場上的存活率。在推薦系統、搜索引擎等系統中這樣的問題是非常常見的,用戶看到的結果是基于機器學習模型推薦出來的,而這些結果又會成為下一次機器學習模型訓練的數據,但是這些數據是有模型偏置的。本質上這是一個Exploitation和Exploration上權衡的問題,需要以長期效果為目標,解決這樣的問題可以參考強化學習中的解決方案。除了幸存者偏差陷阱之外,機器學習系統在實際業務系統中也可能會與其他系統進行配合,機器學習系統的輸出會隨著數據而發生變化,但是如果與之配合的系統中依賴機器學習系統輸出的參數比如閾值等卻固定不變,就可能會影響整個系統的效果。實際應用中需要監控機器學習系統的輸出分布和對其他系統的影響,可采取比如預估分布矯正等策略。
依賴陷阱
不謹慎的依賴容易導致非常災難性的結果,但是在實際應用中往往會被忽視。常見的依賴有:
數據依賴:與傳統軟件系統不同,機器學習系統的表現依賴于外部數據。而數據依賴相比于代碼依賴會更加可怕,因為很多情況下是隱式的很難察覺或分析。
在大公司中經常發生的情況是模型之間的依賴,在解決某個業務問題時,建立了機器學習模型B,為了圖快,依賴了其他團隊模型A的輸出,但是如果依賴的團隊升級了模型A,那么對于B而言將會是災難性的。
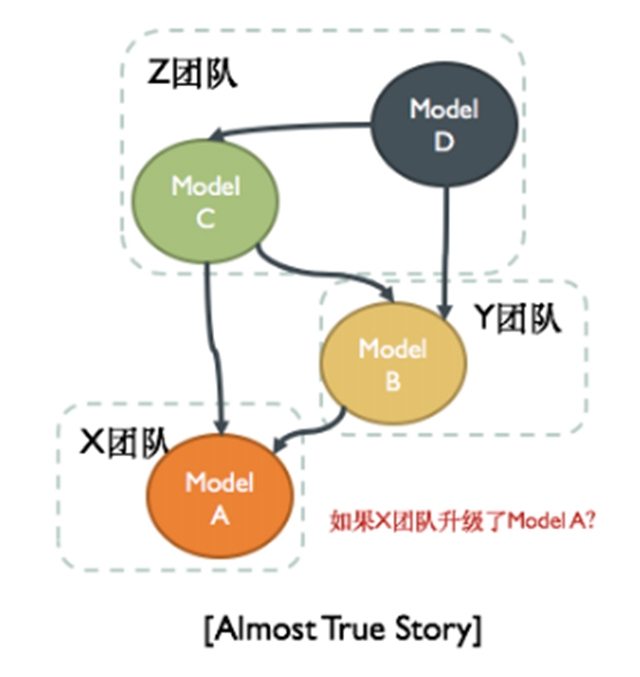
除了數據依賴和模型之間的依賴之外,更難被察覺的是隱性依賴,可能會有一些特征字段會被模型自己改變,比如推薦系統中“用戶點擊推薦文章的次數”這個特征會隨著推薦模型的升級而發生改變。
實際應用中要密切關注數據依賴,盡量避免產生模型之間的依賴,避免出現隱性依賴。
可理解性/可調試性陷阱
可理解性/可調試性最容易被大家忽略。在實際的業務應用中,經常為了追求效果可能會采用非常復雜的模型,然后這個模型可能很難理解,也很難調試。
對于一些業務,比如醫療應用、銀行審計等都會需要模型的可理解性。對于可理解性,一種常見的解決方法是說做模型轉換,比如說像周志華教授提出的Twice Learning方法,可以把一個非常復雜的應用模型,通過Twice Learning的方式轉換成一個性能相近的決策樹模型,而決策樹模型是一個比較容易理解的模型。還有一種做法就是對模型的預測結果給出解釋,比如***的工作LIME借用類似Twice Learning的思想,在局部區域內用可理解模型對復雜模型進行解釋。
可調試性對于實際應用是非常重要的,因為模型幾乎不可能100%正確,而為了追求業務效果,容易采用非常復雜的特征和模型,但是在復雜模型和特征情況下沒發生了bad case,或者想要提升模型性能,會很難分析,導致模型很難提升,不利于后續的發展,所以在實際的業務中需要選擇適合實際問題和團隊能力的特征、模型復雜度。
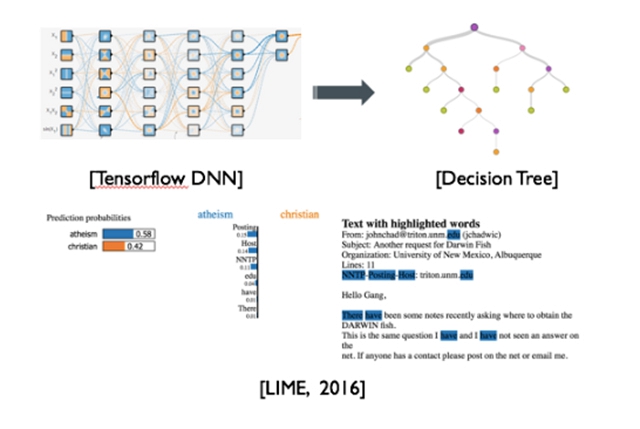
[Twice Learnig和LIME]
總結
機器學習利用數據改善系統性能,是一種數據驅動的實現人工智能的方式,已經被廣泛應用在各行各業。隨著實際業務數據量和數據維度的增長,計算能力的不斷提升,機器學習算法的持續優化,工業應用中的機器學習正在從早期的簡單模型宏觀特征轉變到現在的復雜模型微觀特征,這樣的轉變為機器學習訓練系統的設計與優化帶來了新的挑戰。
機器學習應用的核心系統包括數據收集、數據預處理、模型訓練和模型服務,每個系統對計算、存儲、通訊和一致性的要求都不一樣。對于模型訓練系統而言,由于摩爾定律失效,實際業務整體的數據量和數據維度持續不斷的增長,機器學習算法的No Free Lunch定理,實際建模過程中頻繁嘗試的需要,計算框架的No Free Lunch,實際的機器學習系統需要一個專門針對機器學習設計的兼顧開發效率和執行效率的分布式并行計算框架。這次分享首先對解決開發效率中的計算和編程模型的選擇,編程語言的選擇做了介紹,開發者需要根據自己實際的應用場景、開發成本和團隊能力等去做權衡和選擇。然后又舉例介紹了解決執行效率中涉及到的計算、存儲、通訊和容錯的設計和優化。持續Profiling,迭代消除瓶頸,均衡利用好各種計算資源,盡可能***化各類計算資源的利用率,從而提升整體執行效率。
機器學習被應用到實際的業務中會有很多容易被忽視的陷阱。這次分享對其中常見的各種類型的一致性陷阱、機器學習面對開放世界中的陷阱、機器學習系統中各種依賴的陷阱以及容易被忽視的模型可理解性和可調試性做了簡單的介紹,同時給出了一些可供參考的解決方案。在實際的機器學習應用中需要盡量避免踏入這些陷阱。