













十年DBA老兵:重Java輕SQL乃性能大忌
《SQL性能優化與批判》是黃浩老師的系列新作,他將從過往在項目技術支持中碰到的諸多案例入手,細化到每一條問題 SQL 的內在病因,反思每一個案例的背后深思,抽絲剝繭,層層深入。
今天跟大家分享的是 WM_CONCAT 優化,這是一次憑借技術+經驗+運氣三重加成才得以解決的案例,are you ready?
案例
01.初來乍到,如臨深淵
公元 2015 年 7 月 20 日,天氣還是一如既往的炙熱,徐徐海風也吹不散身上的熱量。在經過近一個小時的班車加徒步,我正式開啟了在 H 公司 I 項目技術支持的***天。
因為信息安全的緣故,***次進入項目現場的外協人員需要辦理接待電子流。因為是非研發區域,倒也快捷,經過兩重關卡后,順利進入到項目現場。
媽呀,一個足球場般大小的辦公場地,一排排的辦公桌和電腦井然有序,但桌面上的辦公用品卻凌亂狼藉,而座位跟座位之間沒有任何的遮擋。
當時已經九點多,基本上座無虛席,雖然開著空調,仍然能感覺到一股由電腦散發出來的摻雜著鐵銹及灰塵味的熱氣,以及由此帶來的壓抑感。
在與現場同事簡短的寒暄后,我便立馬投入到工作——當然是交接工作。與同事的溝通中,我獲取了如下信息:
- 這位同事來這個項目不足兩周。
- 離職的原因是適應不了外包的工作方式。
- 項目組性能優化工作開展很困難,項目組在這方面的投入不夠,重視度也不夠。
綜合起來就是一個字:坑,而且是巨坑。原本擔心我主觀上的能力問題會影響到工作,沒想到客觀環境也是如此糟糕,我的心情跌倒了冰點。
明天是這位同事在項目組的 last day,所以交接工作必須在今天內完成。好在同事進項目不久,還沒有接觸到太多的工作內容,手頭上就一個在優化的 SQL。
因為這個 SQL 的優化已經持續了幾天時間,所以到目前顯得有些緊迫:該 SQL 的優化被安排在周六上線,因此必須要在周三前給出優化方案。
離周三只有不到 2 天的時間了,而目前的優化進度還停留在問題定位階段,還不確定問題處在哪里?換句話說,不是工作交接,而是從零開始。
我在同事的交接文檔中找到了問題 SQL,代碼如下:

02.戰戰兢兢,如履薄冰
沒有任何的注釋,代碼中的表呀,字段呀什么的,我一個也不認識,唯一親切的就是 select from where join group 這些被標綠的 SQL 關鍵字。
“這個 SQL 有什么性能癥狀?”
“跑起來很慢。”
“慢到什么程度?”
“大概需要半個多小時才能跑完。”
“數據量很大嗎?”
“可能吧,我還沒有執行過,只是聽開發人員這么說的。”
看來我不能從這位同事這里得到更多有價值的信息了。
按下 F5 查看執行計劃:

執行計劃中,表訪問方式基本上都是 index scan,而且也并無大成本的操作。奇怪了,問題處在哪里呢?我又回到 SQL 窗口,按下 F8,果然只見時間過,不見數據出來。
在長期與 SQL 相伴的日子里,我養成了一個習慣,喜歡在邊看著 Oracle 執行,一邊分析代碼,大有“我忙著分析,你也別閑著偷懶”的“小人嘴臉”。
這個 SQL 有兩個部分,***部分是用 with 封裝了一個結果集,第二部分是對***部分的結果集進行 group by 處理。根據過往經驗,我將 SQL 復制到了另一個 SQL 窗口,選中 with 子句單獨執行,秒出呀。
排除了子查詢的性能嫌疑,那么很顯然問題是出在第二部分的 SQL。第二部分 SQL 包含了 group by,難道是 group by 產生了性能問題。要知道,group by 等聚合操作的性能對數據量是極其敏感的。難道是 with 子查詢的數據量非常大?
我趕緊 count 了***部分 SQL 的結果集,顯示不到 20 萬數據。那就不應該呀,20 萬數據做 group by 也不至于慢成“蝸牛”呀。
繼續分析第二部分 SQL 代碼,在 select 子句中,驚現 wm_concat 函數。此時,我還是有些小激動的,因為在之前也遇到過由于 wm_concat 引發的性能問題。為了驗證判斷,我將 wm_concat 注釋掉,按F8 運行,果然飛快,不到 1s 就出結果。
至此,通過排除法,病因是找到了:由 wm_conca t引發了性能問題。
03.順藤摸瓜,順手牽羊
原因已經找到,那么對癥又該如何下藥呢?顯然,從 SQL 功能上,wm_concat 是必須的,我也嘗試過用 listagg 來替代 wm_concat,但是會因超過 4000 字符而報錯。
其實 wm_concat 函數之所以慢,就是因為以 task_name 為維度需要拼湊的數據量太大導致的。難道就無解了嗎?
我轉念一想,為什么要用 wm_concat 函數?應用程序在拿到這個字段后做什么用呢?在前端頁面顯示嗎?
這種顯示是沒有多大意義的,因為 wm_concat 的結果可能非常大,根本就顯示不了。既然顯示不完整,那么為什么又要從 DB 中獲取完整的內容呢?
帶著這些疑惑,我與 SQL 開發人員進行了溝通,原來,應用程序拿到這個 SQL 的數據后,并不是在前端頁面展現,而是在應用程序中繼續加工處理,在經過若干復雜的邏輯處理后,以另一種形式在頁面展現。
此時,多年的從業經驗告訴我:既然可以用 Java 來實現的業務邏輯,那么肯定也能在 DB 中通過 SQL 來實現,這樣就可以避開 wm_concat 函數。
于是我決心深入了解業務功能,希望能從業務方案上有所突破。這樣就形成了一個初步的工作計劃:了解整體業務功能及邏輯-->了解應用程序處理邏輯-->改寫 SQL 語句-->功能性測試-->性能輪回調整。
在大約兩個小時的一對一講解后,我基本上掌握了整體業務功能及邏輯、應用技術架構及處理邏輯。
這個其實是一個報表展現功能,是按區域、里程碑展現兩個相鄰里程碑之間的時間間隔,包括計劃間隔時間與實際間隔天數(平均)。
報表格式大致如下:
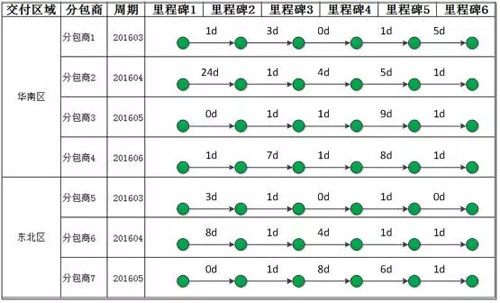
在 DB 中,里程碑的計劃與實際時間是存在二維表中,結構示意如下:
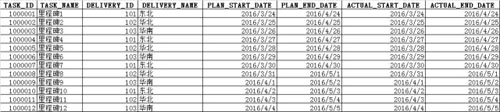
在這里,就存在一個行列轉換的問題,即將 TASK_NAME 從以行存儲轉換成以列展現。
為了實現這種結構轉換,當時的架構設計如下:
- 通過 SQL 從 DB 獲取每個里程碑、交付區域的 plan_start_time、plan_end_time、actural_start_time、actural_end_time 及 du 集合,即 SQL 中的 wm_concat 拼湊后的結果。
- Java 應用程序拿到這個結果后,循環結果集,并依次分解由 wm_concat 拼湊的內容:計算每一個里程碑內 DU 的平均時間間隔;判斷里程碑的前后置關系;計算前后置里程碑間的天數間隔;最終將計算結果展現在前端頁面。
04.水到渠成,一戰而定
從上述描述中,我們可以提煉出如下信息:
- WM_CONCAT 拼湊的內容只是過渡的,在 Java 中還需要依次分解。
- Java 處理的幾個步驟完全可以由 SQL 來實現。
這樣就可以省卻以下幾個“麻煩”:
- 省卻了大量數據從 DB 傳輸到 Java 服務器的成本開銷。
- 可以順理成章的拔掉 wm_concat 這根刺。
那么,如果用 SQL 來實現上述邏輯功能,存在兩個難點,其一是如何判斷里程碑(task_name)前后置關系,其二是計算前后置里程碑的時間差。
進一步分析后發現,里程碑(task_name)前后置關系可以通過 SQL 來獲取,而在時間間隔的計算上,可以通過 lead 窗口分析函數獲取后置時間,然后相減即可。
改造后的 SQL 如下:




將 SQL 在 DB 中運行,不到 3 秒就執行完成。
心得
01.心有余悸,學無止境
值得一提的是,這個 SQL 并非一蹴而就的,從***次改寫,到最終上線,經歷了好幾個版本,但整體結構并沒有變動,只是對某些特殊場景做了調整。
我來項目的***個 SQL 優化就這樣跌跌撞撞、歪打正著的完成了。由于時間緊迫,整個過程都是繃緊了神經。
現在回想起來,既是慶幸又是后怕,慶幸的是問題得到了及時解決;后怕的是,當時可謂是不知者無畏,完全是在不熟悉環境,不熟悉利害關系的情況下解決了問題。如果放在幾個月后,我想一定沒有當時的勇氣和決心來完成這件事情。
回過頭來看,這起由 wm_concat 引發的性能事件還是給了我們很多的啟發:
SQL 優化不是孤立的存在
SQL 優化并不是孤立的,也就是說并不是所有的 SQL 本身都存在優化的空間。當 SQL 本身無法優化的時候,或者優化的空間不足以滿足用戶需求時,就需要從全局需求突破。
嘗試著按另一種方式得到結果:殊途同歸講的不就是這個道理嗎?正所謂山重水復疑無路,柳暗花明又一村,關鍵在于你是否愿意主動尋求和突破。
SQL 優化其實很樸素
SQL 優化并不需要多么高深的知識和高級的技術,SQL 優化也并不那么神秘,一點點技術,一點點經驗,再加上一點點運氣就足夠了。
一點點技術
這里說的技術是 SQL 技術。SQL 語言我認為是除匯編外所有語言中最神奇、最簡單、***藝術化的語言。
說簡單,就 select 查詢而言,就 select from where and or group order 等***的幾個關鍵字,拿 SQL 而言也就 select、update、delete、insert 四種功能。而且通俗易懂。
說神奇,因為就這些關鍵字,無需排列組合,便可以千變萬化。在當今的信息化大時代,無外乎就是增刪改查;大千世界,蕓蕓眾生,概莫能外。
就拿人類自身來說,其***哲學就是:生老病死,出生就是 insert,歲月催人老就是 update,眾里尋他千百度就是 select,榮登極樂就是 delete。
說藝術化,簡單而不簡約,這就是藝術,能以數個關鍵字撐起世間萬物的起起落落,這就是藝術。
這里說的掌握 SQL 技術,不僅僅是掌握這幾個關鍵字,用這幾個關鍵字變幻出種種結果,更是要掌握如何通過這幾個關鍵字來實現這種藝術化的效果。
一點點經驗
經驗這東西是美妙的,一旦你擁有了某個知識點的經驗,下次再遇到時,你會不費吹灰之力就能解決了。
比如這次的 wm_concat 函數,我相信,之前的同事沒有定位出問題所在,就是他沒有遇到過 wm_concat 這個函數。所以總結經驗是絕對正確的,雖然經驗并不一定有用得上的機會。
一點點運氣
所學的一點點知識和積累的一點點經驗恰好被用上了,這就是運氣。因此運氣也是辯證的,表面上是因為運氣解決了這個問題,實則不然,如果沒有那么一點點知識和經驗,也不會這么順利的解決。可見偶然中也有必然。
批判
7 月 25 日周末上線,周一一大早,開發兄弟像報喜一樣告訴我,優化效果明顯,用戶非常滿意。看著他稚嫩中略帶青澀的笑臉,我也長舒一口氣,畢竟這是我的***個優化案例。
“黃工,你是怎么知道可以這樣處理的?”
面對他的這個問題,我一時啞口,該如何回答呢?
“那你當初為什么要將 SQL 返回中間結果集,然后又在 Java 中做邏輯處理呢?”
“一方面,我們的架構規范就是這樣的,要求盡量在 Java 中完成邏輯處理,減少 DB 的負載;另一方面,我也寫不出這么復雜的 SQL,說實話,你給我的 SQL,我到現在還沒有看明白。”
原來如此,我就告訴他:
“在二維關系的系統里面,Java 能處理的二維數據,在 SQL 中都能實現”
“哦”
“對了,你是怎么選擇 wm_concat 這個函數的?”我知道這個函數很少用,也是 Oracle 公司未公開的內部函數。
“我是在網上查到的資料,看到這個函數可以實現功能,就拿來用了,沒想到會帶來這么大的性能問題。”
看得出來,他仍然保持了學生意氣,有些自責,他好像又想起了什么來,趕緊補充說“因為時間太緊迫了,現在是敏捷開發,每兩周一個版本,如果時間充裕的話,我想我也能通過查資料把這個 SQL 寫出來的。”
他說著有些激動,但事實上他是認真的,也真的做到了。在后來的開發過程中,他寫出了連我都寫不出來的復雜 SQL。
通過與他的對話,我大致可以勾畫出這個項目的一些基本元素:敏捷開發,雙周迭代,無開發型 DBA,重 Java 輕 SQL。
這些是國內大多數項目的通病,本來是見怪不怪,但是出現在世界 500 強,國內 IT 軟件天堂的大公司,還是讓我有些意外,更讓人感到后脊涼涼的。
敏捷開發要求快速交付,功能優先性能,急功近利;偌大的一個企業級平臺項目,居然沒有匹配一個專職的開發 DBA,SQL 的質量令人擔憂。
而重 Java 輕 SQL 在信息管理系統中是一個大忌,會暗藏很多性能風險,這些都是性能的催化劑。這意味著我接下來的道路勢必坎坷曲折、荊棘叢生。
















