關于機器學習的傻瓜式指南
成為2級新手
我第一次在工作中遇到實際的機器學習應用。我們要準備一個識別Zooplus商店中欺詐行為的應用。在經過幾個月嘗試了不同的解決方案之后:外部提供者,在代碼中額外的if語句,滅火腳本等諸如此類,我們最終得到機器學習是最適合該工作的結論。自此以后,我們試著說服周圍的人投資我們的教育并繼續機器學習之路,但是并沒有引人關注的成功。然而偶然的一個機會,我通過嘗試Amazon的機器學習功能邁出了我的第一步,因而我認為自己是一個2級新手。在本文中,我會嘗試向你 — 1級新手 — 展示如何邁出第一步,并切實地感受什么是機器學習。
什么是機器學習?
在互聯網上,也許有成百上千的機器學習的定義。但是,我是初級的傻瓜,我們希望得到一些簡單的東西——一些傻瓜式的東西!讓我們一起來解決這個問題吧。
術語中的“機器”可能指的是計算機。我們可以想到計算機,無人駕駛飛機和其他東西,但是他們是由計算機控制的,對么?所以,機器學習是關于“計算機學習”的。
學習實際上是指的什么呢?計算機并沒有大腦!沒有神經元的激活,沒有路徑的創建。它能做的所有只是存儲一些數據和進行一些操作。但是我們知道它是和數據有關的,而且是大數據(至少DZone是這么說明的)。所以我們有“關于大數據的計算機處理”。
那么,“處理”指的是什么呢?作為2級新手,我可以大概講解一下(不過我敢打賭,真正的從業人員會認為我說的話一點也不正派)。我所說的,就是利用1級新手和2級新手不想知道的高級算法進行統計分析。
我想,這樣就足以形成我們在這篇文章中給機器學習定下的最終定義:“電腦對大數據進行統計分析”。夠酷吧?
機器學習有什么用?
我懂,我懂。讀了這么多,你還是不曉得這一切關于機器學習的知識到底有什么用。作為2級新手,我要再次說一下,我有了一個學習機器學習的機會。
有兩種機器學習:監督與非監督。
監督學習
我非常希望給出監督孩子的類比,但是我并不能夠。是誰發明的這個名字?!
監督學習是當你為計算機提供你期望查找的信息時,-還記得我工作識別欺詐行為的例子嗎?那就是監督學習。-我告訴計算機:我希望知道這個客戶是否是一個欺詐者!而計算機器執行其高級魔法并給出答案:是的,主人!或者,不是,主人!他是一個笨蛋,但是普通的一個。通常,監督學習用于所謂的分類問題中。你為計算機提供大量的數據,而它進行分類:美國人是否會再次投票給 Mr. Trump ?這個人是否得了癌癥?你是否會繼續閱讀這篇長而有趣的文章?
非監督學習
非監督學習是你并不清楚你正在尋找什么時,你毫無思路,你告訴計算機:這里有一堆數據!找出一些有趣的內容來。而它會執行比監督學習中所用的更為高級的算法。
因為我們并不是毫無頭緒-我們確切地知道我們需要什么(而且我們對更為高級的算法并不感興趣),在接下來的部分我們會專注于監督ML。
Amazon ML簡介
在不久以前,對于你和我這樣的新手接觸機器學習非常困難。它是整天思考數字并且認為Scala與Python是好的編程語言的書呆子們的游戲。多虧了Amazon,精于銷售的這幫家伙開始賣他們自己的基礎設施,并且為我們提供了偉大的工具:Amazon機器學習。
創建數據源
我們擁有超過600個文本單詞,所以我們最好直接進入工作。打開你的Amazon Web控制面板并找到“機器學習”按鈕。點擊!你會看到一些為你提供教程之類內容的屏幕。忽略它!你不需要新手教程,因為你已經在新手教程的中間部分了。你應該看到如下內容:
所以,在大數據上執行計算統計分析的第一步將是提供真正的大數據。使用下面的鏈接下載文件并將其放入S3桶中:
https://s3.amazonaws.com/aml-sample-data/banking.csv
(是的,我們正在使用AWS文檔教程所提供的數據。只是這個教程相對更好!)
你一旦完成,你可以返回機器學習屏幕并選擇 “Create new…” ,然后選擇 “Datasource”. 你應該可以看到如下內容:
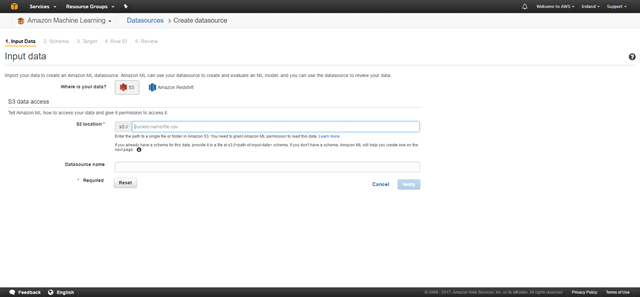
Insert the S3 location and choose a Datasource name. 名字無所謂。 (最終我們會將其刪除), 所以你可以為其指定任意名字。完成后點擊 “Verify” 并選擇 “Continue”.
你應該可以看到類似如下的屏幕內容:
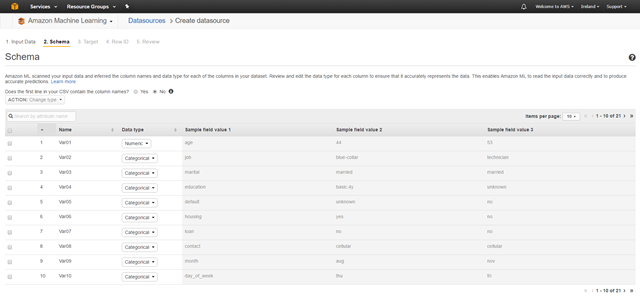
正如你看到的,Amazon通過將數據分割為不同的數據類型試圖使該數據更為合理。因為這是他們的新手教程數據,所有內容都應該更為平滑。你只需要對列名相關的問題點擊 “Yes” ,如果一切順利,最后一頁命名為 “y” 應該是 “Binary” 類型。如果正是這種情況,點擊 “Continue”;否則,我不知道 – 我只是一個2級新手。
在第三頁,Amazon最終會詢問我們真正希望得到什么樣的魔法結果。那正是 “Target” 。在如下的屏幕中選擇最后一列:
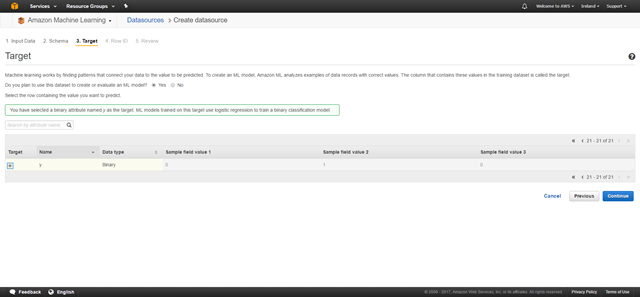
正如你看到的,Amazon將其識別為一個二分類問題,這意味著我們現在是監督者了!點擊 “Continue”。
我們的數據并不包含標識符,所以點擊 “Review” 并選擇 “Create Datasource”。他需要一段時間直到創建完成。一旦完成,你應該看到如下內容:
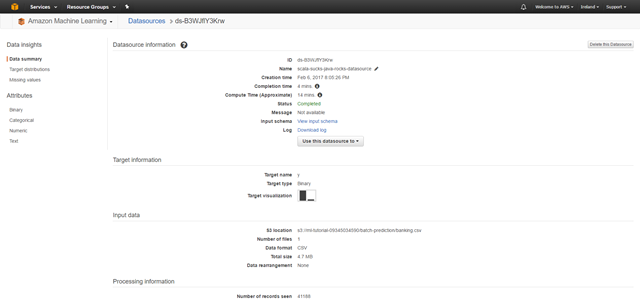
我們完成了數據源!在系統中我們擁有我們的大數據了!
有了上千的單詞,我們已為了最重要的部分做好了準備。我們將會創建實際的統計分析部分。ML模型是我們的超酷的機器學習解決方案的大腦。它是由Amazon基于我們的大數據與設置所創造的神奇生物,可以為所提供的數據預測列 “y” 的值。讓我們開始吧!
回到機器學習面板,再一次選擇 “Create new…” 然后選擇 “ML Model”。選擇我們新創建的數據源。我們應該看到類似如下的內容:
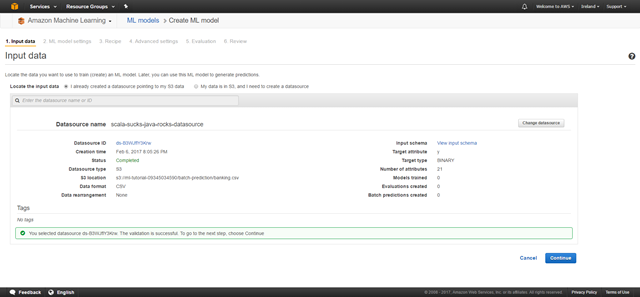
點擊 “Continue” 然后選擇 “Review” 與 “Create ML Model”. 我們并不希望修改任何高級設置。記住,我們僅是1級與2級的新手;我們僅是希望可以看到一切可以正常工作。
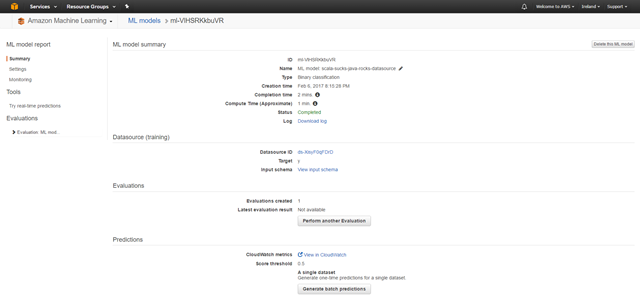
一段時間后按F5刷新,我們應該看到成功界面(如下所示)。我們的ML模型已成功創建!
創建預測
如果我們創建了我們解決方案的神奇大腦而不預測任何事情,那我們會感到遺憾。由ML模型成功界面的左邊選擇 “Try real-time predictions” 。 點擊 “Paste a record” 按鈕并粘貼如下內容:
32,services,divorced,basic.9y,no,unknown,yes,cellular,dec,mon,110,1,11,0,nonexistent,-1.8,94.465,-36.1,0.883,5228.1
該行與我們的大數據文件具有相同的格式,但是缺少最后一列 – “y” 。這正是我們的神奇ML模型將要預測的內容。如果已為驚奇做好準備,點擊 “Create prediction” 。
Yes, yes, yes! 它起作用了!它預測了!如果你正確地做了我告訴你的所有事情,你預測屏幕的右邊應是類似如下的內容:
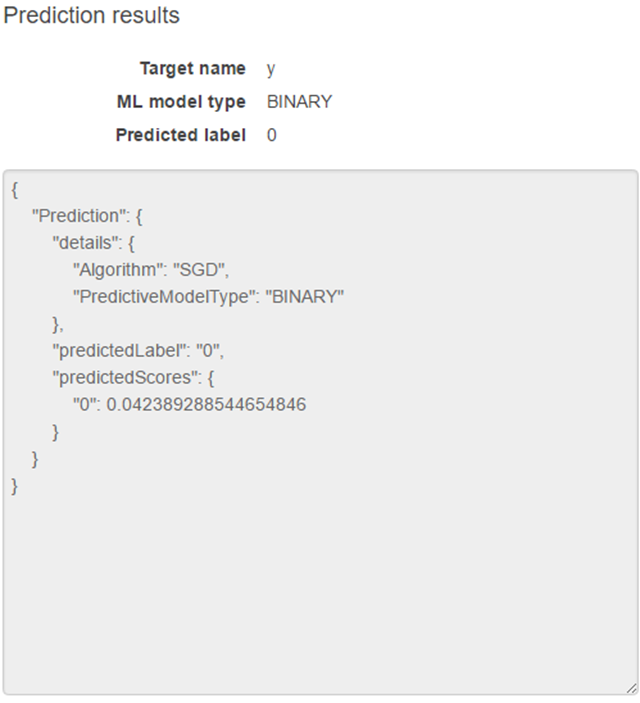
“Predicted label” 是我們預測的結果 – 驚人的 0!正是它!
清理
確保由S3桶中刪除數據,從而你不會為存儲支付費用。你可以由你的帳戶中刪除機器學習,這取決于你,因為它不會花費任何費用。
總結
我們由給出一個糟糕的機器學習定義開始。然后,我們學習監督機器學習與非監督機器學習之間的區別。最后,我們通過Amazon機器學習接口創建了一個簡單的預測。現在你也許想要知道的是:我們預測了什么?我們在那里放置的是什么數據?如果它沒有起作用該怎么辦?目前,這些無所謂。它僅是一個例子。現在重要的是,我的2級新手是你希望預測什么?你有什么可以利用的數據?以及為使其起作用你可以做什么?在下面我會為你提供一些資源,祝你在成長為3級的道路上好運!