崛起的GPU數據庫大揭秘:多數據流實時分析,如何做到快如閃電?
從應用上來講,GPU 數據庫帶來了三大方面的進步:加載速度、實時處理和寬表多條件查詢。它最大的革新點之一在于,提供了一種不依靠索引,并大幅提升速度的手段。 所以,要搞清楚 GPU 數據庫,先讓我們聊聊數據庫,尤其是數據存儲。
索引、分區和組合主鍵
傳統數據庫的存儲是在磁盤旋轉的碟片上。讀數據時碟片先旋轉到一定位置,磁頭再伸到相應的扇區,稱之為尋道,并讀取一個或多個數據塊(Block)。旋轉到位的時間和轉速有關,以 7200 轉 / 秒的磁盤為例,旋轉延遲為 4.16ms。普通臺式 PC 磁盤的尋道時間為 10ms, 數據傳輸時間可忽略不計,因此,光是從扇區上讀取數據,就需要 14 毫秒左右。這是什么概念呢? 大家后面可以看到,GPU 數據庫的響應時間常常也就幾十毫秒。
數據庫如何找到想要的記錄?最糟的辦法是掃描整個表,這就意味著要一個個的扇區地讀,直到讀到目標記錄。每讀一個扇區用 14 毫秒的話,就洗洗睡了吧。 每個記錄都有一個所屬的扇區和該記錄在該數據塊里的位置。不同的操作系統和數據庫對這兩個概念有不同的名稱,讓我們姑且稱為 PageID 和 SlotID。如果知道每條記錄的 PageID 和 SlotID,無論運氣好不好,讀取時間都是一個常數——直接到磁盤上的目標塊,整塊讀出,并按 SlotID 找到該記錄在本塊里的所在位置,讀出即可。這也稱為時間復雜度為 O(1)。
索引可以看作一張表,最重要的功能就是記錄每條記錄的 PageID 和 SlotID, 并通過一系列指針,讓人們盡可能快地找到或更新它們。
以數據庫最基本的查詢之一: SELECT...WHERE ID=123456 為例, 最有效的是哈希索引。它本質上是一個 Key-Value 表,Key 是 ID 的哈希值,對應該 Key-Value 表里的第幾行,Value 包括一個指針,指向存儲該條記錄的 PageID 和 SlotID。對于 ID=123456,先用哈希函數算出哈希值,比如是 9231,那么直接去索引表的第 9231 行即可找到 PageID 和 SlotID,讀出對應扇區的數據塊里的數據。因為索引通常放在內存里,因此訪問速度比一塊塊地從磁盤讀快得多。
真實的索引遠比這個復雜,并分為哈希、B 樹,B+ 樹等不同技術,來處理等值、范圍掃描、非等值查詢等。基本原理都類似,將掃描磁盤的多個扇區變為掃描一個多層次的地圖, 以便逐層找到目標記錄所在的 PageID 和 SlotID。
索引的最大壞處是多了一張或多張索引表。每增加一條記錄,不僅要將該記錄寫到磁盤里,而且要計算哈希值、編入索引表、并調整索引里受影響的指針位置等等。將一個寫操作變成了多個操作,更容易出錯甚至損壞,而且延長了寫入時間,大大降低了數據加載入庫的速度。因此,大家可以看到,基于磁盤的數據庫,無論是傳統關系型還是現代的分布式 Hadoop 數據庫,都會提供多種加載方式,其中一種一定是直接寫文件,而不寫索引,不考慮事務,以便加快加載。 在這點上,GPU 數據庫很不一樣,也是其最重要的優勢之一,后面再講。
用戶們不會那么乖,只按 ID 查,如果還需要按時間、店鋪 ID、產品 ID 之類查怎么辦?最簡單的辦法是建多個索引。用哪個字段查,就為哪個字段建索引。如果字段數少還行,但是如果有 10 個常用字段怎么辦? 這 10 個字段的組合就可能產生 1024 種索引,如果所有記錄都需要編入索引,數據量將膨脹到何種程度?
用戶行為分析的巨頭 Heap Analytics 就用這個辦法:將 Web 訪問事件的所有屬性記錄進一張大表,對常用字段分別建索引。其使用的 PostgreSQL 支持部分索引(partial Index),允許按 Where 條件篩選,僅將符合 Where 條件的記錄建入索引,以便大大地減小建索引的開銷和索引表的大小。據稱,他們需要維護幾百甚至上千個這樣的索引。 好在這張大 Fact 表是張稀疏表,每種屬性的數據都不多,大量空白值,因此通過 Where 條件篩選后的部分索引會大大縮小。
Hive、SQL-On-Hadoop 之類的產品還會增加其他手段,比如分區。在建表時增加一個“分區”字段,通常用基數低,而用戶經常查詢的字段,比如年月、店鋪 ID 或產品 ID。往數據庫里增加記錄時,同一分區的記錄盡量連續存放在磁盤的同一個或相鄰的數據塊、或分布式集群的同一個 Region/Partition/Bucket/Division 里 (不同的技術對這個概念的稱謂不同)。如果用戶經常用這些字段查詢,或者 Group By,那么只要先找到分區,一個讀操作就可以讀出同一個年月、店鋪 ID 或產品 ID 的大量記錄,大大節省旋轉、尋道或分布式存儲系統尋址的開銷。
對于索引問題,惠普等老牌數據庫公司還推出了 MDAM 等技術,將分區字段放在主鍵之前,拼成多個字段的組合主鍵,建入同一個 B 樹索引中,從而用一個索引達到兩個甚至更多索引的效果。 查詢時,先組合主鍵里的分區字段,對每個分區進行并行的范圍掃描(Range Scan)。可以想象,如果按性別分區,一下子可以縮小一半的搜索范圍。 有興趣的同學可以讀讀 HP Labs 大牛 Goetz Graefe 的有關論文,此人對惠普大型數據庫和 Microsoft SQL Server 都有神一般的影響。 這一機制在惠普的 Nonstop SQL/MX 和 Apache Trafodion 里仍能找到。
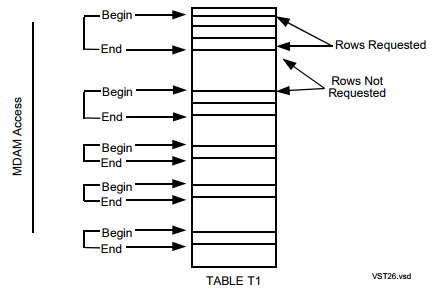
不過組合分區也有其他問題。如果存儲系統是鍵 - 值(Key-Value)的分布式系統,如 HBase,那么對于每對鍵 - 值都需要存 Key。如果 Key 是組合主鍵,包括多個字段,那么 Key 就會很長,大大增加存儲開銷。所以還需要進行編碼和壓縮,來減小空間開銷。代價是,在數據加載時,仍會有增加額外的編碼開銷。
GPU 和 SIMD
表和圖像很類似,對象都是很有規律的一個個格子。 處理起來也很類似:可以并行地對每個格子里的數值執行一組單向步驟的指令——即通過 SIMD(Single Instruction Multiple Data)用同一組指令處理多個數據單元。加上 GPU 有多核,因此可以并行大量線程。每個線程都有對應的核支撐,無需操作系統來回切換,將大大加快速度。對 NVidiaK80 這樣的 GPU 設備來講,硬件并行意味著可以用 4992 顆核來支持上萬個線程并行處理,這比操作系統 +CPU 的超線程快多了。GPU 上的內存也增加了不少,K80 有 24G 顯存,在 RDMA 等技術的支持下,可以通過 PCI-E 總線和網口實現 GPU 顯存之間的高速數據交換。 K80 顯存的 IO 總吞吐量也達到 480G/S。因此,將 GPU 用于并行計算和數據庫是水到渠成的事。用 GPU 進行幾千萬行的掃描通常僅需幾十毫秒。如果網絡速度夠快,幾十億行的掃描,返回幾億行結果,也僅需幾百毫秒。
GPU 數據庫
物聯網的迅猛發展,讓人們不得不調整數據平臺的設計思路和處理方式。2017 年 Gartner 發布的 Top strategic predictions for 2017 一文指出,到 2020 年,210 億只 IoT 設備對數據中心存儲需求增長將不超過 3%。 先入庫再處理的方式不適合高速、巨量的物聯網數據。
和銀行或商業交易記錄相比,這些物聯網數據的存儲價值不高,因為同樣的傳感器之間的個體差異很小,更接近于隨機過程,我們更關心在某個時間段內,發生某個事件的概率,因此需要確保相應統計模型的可靠,和等,而不那么關心 A 區的傳感器在二季度比去年同期多發了多少個警報,更無需考慮 A 區傳感器半年以來的購物和存貸記錄,是否適合我行 180 天期的金茉莉理財產品。
在數據加載的同時進行分析,顯得前所未有地重要。第一個坎就是要擺脫對索引的依賴。在多個數據流高速加載的情況下,無需寫索引表所換來的性能非常可觀。據 Kinetica 的創立者稱,2010 年美國陸軍情報和安全指揮中心(US Army Intelligence and Security Command) 希望處理 200 多個實時數據流,包括手機、無人機、社交網絡和 Web 訪問,每小時 2 千億條記錄,為分析師和開發者們提供接口,來結合時間和地理位置監控危險信號。 他們嘗試了 HBase、Cassandra 和 MongoDB, 但一直未能解決同樣的問題:能支持的查詢極為有限,索引越來越多,越來越復雜,并一直需要增加硬件。得到結果的速度越來越慢,開始是 1 個小時,隨著索引越來越復雜,逐漸需要 1 天,后來發展到一個星期。 用兩年時間,他們開發了基于 GPU 的系統——用 HBase 作為永久存儲,用 GPU 數據庫提供實時加載、實時查詢。多個實時流可以從多個 Head 節點,多線程加載,可處理每分鐘 14 億條。
該 GPU 數據庫以列式存儲,結合內存 + 顯存,無需優化,無需建索引。內置可視化層、地理空間層、流處理層,并有 Hadoop 和 Spark 等接口。常見的使用方法是從 Kafka、Storm、Nifi 上獲取數據,高速處理,并輸出到 BI 工具如 Tableau、Qlikview 里。
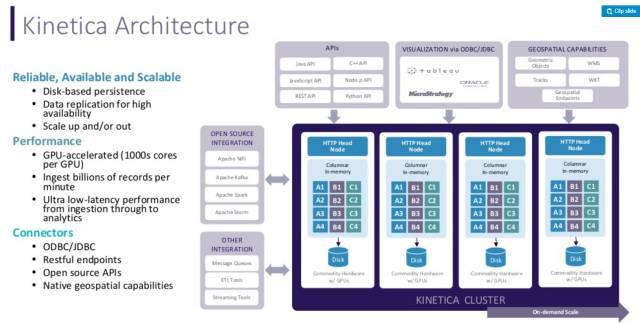
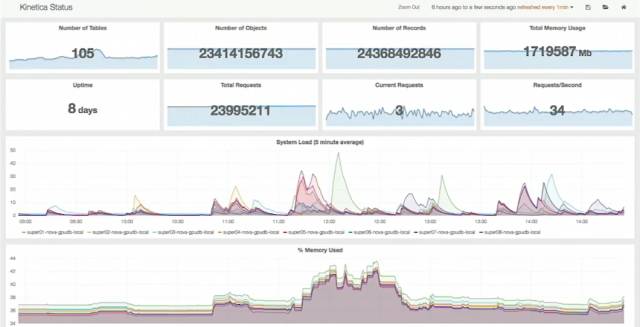
他們在 2017 年紐約舉行的 O'Reilly AI 大會里有個演示: 8 個 GPU 設備組成的集群,每臺服務器 256G 內存,整個集群有 244 億條記錄,共 1.7TB,其中包含 41 億條推特。
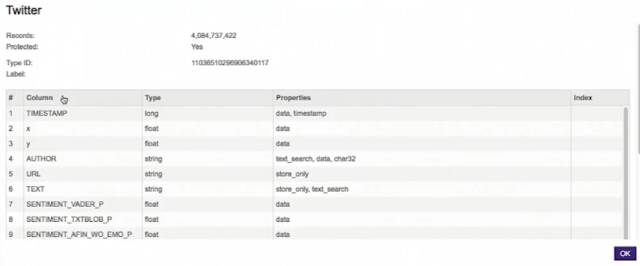
推特表的情況如下:
用戶可以在地圖上任意圈定區域,結合郵編、名稱等篩選、關聯,一秒以內可以從 41 億條里,返回 5.13 億條結果。
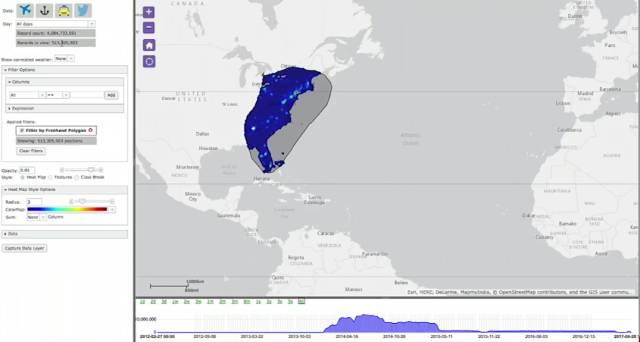
這種城市級的區域選擇,得到 4300 多萬條結果,需幾十毫秒。
同時,也可以復制區域形狀,拉到其他地區放大縮小范圍,用關鍵詞搜索文本內容,也可以在幾十毫秒得到幾百條結果。
用 SQL 對這張 40 多億條記錄的大表,跑下面這條聚合查詢,72 毫秒就出結果。
- SELECT count(*), sum(sentiment_vader_p),avg(sentiment_vader_p), min(sentiment_vader_p),stddev(sentiment_vader_p),var(sentiment_vader_p),sum(txtblob_p),avg(txtblob_p),stddev(txtblob_p)
- FROM MASTER.Twitter
對兩張 2000 萬條記錄的電影統計表關聯、排序和模糊匹配,響應時間是 53 毫秒。既然是排序,那么 limit 100 對響應時間的幫助應該不大。
- SELECT m.title, m.genres, avg(r.rating),count(r.rating)
- from movie m, rating r
- where r.movieID=m.movieID
- and (genres like'Action%' or genres like 'Thriller%')
- group by m.title, m.genres
- order by 4 desc
- limit 100
總的來說,分析型應用涉及到的大多數數據庫操作是讀。在生產時間,將數據加載到顯存和內存里,無需訪問磁盤,因此無需依靠索引來降低訪問扇區的開銷。通過每個 GPU 的幾千個核,并發上萬個線程并行掃描全表,尤其適合幾千萬到幾十億行的 JOIN、模糊匹配、Group By、全表掃描或聚合等等,比如七八千萬條的大表在非主鍵字段上 JOIN,性能提升很明顯。單機處理幾千萬行的數據也能在幾十毫秒內返回。這樣的低成本查詢,使用起來就比 Hadoop 和傳統關系型數據庫靈活、高效得多。人們不僅可以更自由地選擇任意字段分析,按任意組合,一次查詢的條件更多,而且能夠對高速加載的數據流實時處理——先處理、再落地。
同時,GPU 顯存和內存之間的交換帶寬很高,所以即使是 TB 級數據,或者有更新、數據注入時,可以用內存作為橋梁,實現磁盤—內存—顯存緩存的三級緩存來解決。
多維交叉可視化查詢
傳統的 BI 只能每次看一個視圖,比如先從銷售,再碰碰運氣加入庫存,但實際上有價值的結論需要多個視圖一起看,因此產生了多維度交互式可視化查詢,讓大家的嘗試更高效。
Tableau 無疑是這方面最成功的企業之一。這種做法的顛覆性意義在于,同一個儀表盤上同時展現多個視圖,反映不同的角度,比如銷售、庫存、客戶等等,點擊任何一個視圖都會對所有視圖添加同樣的篩選條件,展現所有角度的變化。
每次點擊實際上是對所有視圖加了 Where 條件。當數據超過 1 千萬條,用普通數據庫的響應時間就會很慢,不再是交互式。如果視圖超過 10 個,每次互動產生的查詢很多,數據庫壓力也會很大。Tableau 等 BI 工具的解決方法是將查詢結果緩存起來,和對大數據集先采樣再計算。但這種緩存的設計比較考究,也增加了更多步驟——要先查緩存,緩存里的記錄也可能未及時更新。而 GPU 數據庫的響應速度快,每個查詢的開銷低,所以即使不用緩存、不采樣,每次都發新的 Query,同樣可以達到實時的效果。
MapD 曾有一個很棒的 Demo,展示紐約市出租車的交互式分析,數據量超過 10 億條。利用 GPU 數據庫的性能,加上查詢結果在顯存里,能實現動畫式的交互:用戶可以在時間軸上拉一個窗口,并拉動該窗口,其他視圖隨之變化,請見下圖底部時間軸的淺藍色塊,從左到右移動效果。這就超越了指標計算,可以更好地洞察趨勢。也可以戳地址(https://www.mapd.com/blog/content/images/2017/04/taxi-ride-filters.gif)看動圖。
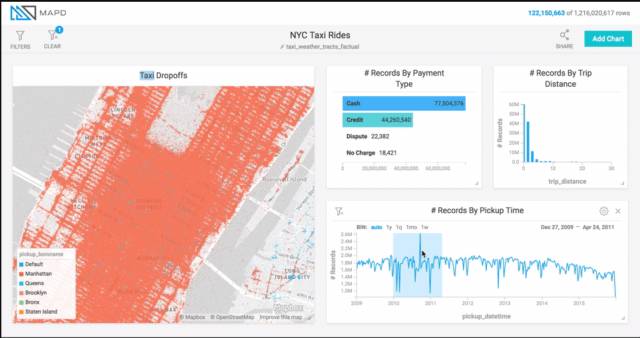
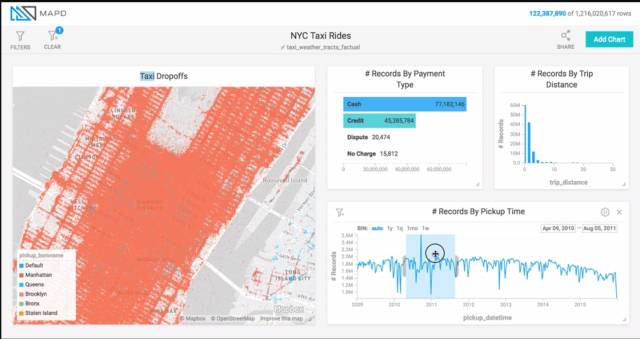
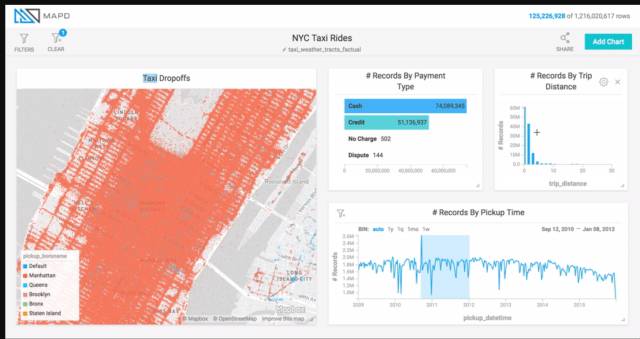
這種拉動窗口產生的查詢更密集,因此仍可以借助查詢緩存,利用之前的結果來加速響應,實現流暢的動畫效果。不過這種緩存更加簡單,比如將查詢結果按 Key-Value 的形式放入緩存,Key 是查詢語句,Value 是查詢結果。
舉個例子,如果用 X、Y 軸分別展示航班的到達延誤和滿座率,通過拉動時間窗口,可以看出不同航空公司的這兩個指標組成的點的移動。哪些公司的差距逐漸增大?哪些在減小?
小空間,大數據
大家都知道,GPU 數據庫的顯存小,那么有沒有處理 TB 級以上的例子呢?
除了 Kinetica 宣稱能處理 100TB 級的數據之外,Sqream 也比較擅長大數據量的 GPU 應用:其最初客戶來源于癌癥研究中心,需要處理基因排序,比如對比癌癥患者的缺陷基因序列和正常序列,需要大表之間 JOIN。每對序列有 200 多 GB,多對序列的比對就需要 TB 級的處理能力。用關系型數據庫對比 12 對序列需要 2 個月,Sqream 通過 GPU 比對幾百對序列,僅用了 2 小時。
他們的另一個場景和 Kinetica 最初的安全監控很相似,反映了 GPU 數據庫的另一個優勢。
5 個無人機加一個巡邏車進行邊境巡邏,每小時無人機總共傳輸 8TB 給巡邏車,巡邏車要及時發現異常以便及時準備扔石頭(好吧,后面這句是我編的,如有雷同,純屬巧合)。車里最多能放一兩臺服務器,GPU 數據庫當仁不讓。
同樣,無人機在人群集中的廣場、景點巡邏時,可以將視頻傳輸到坐在咖啡館里的便衣工作人員的筆記本上,由人臉識別等視頻軟件產生結構化或半結構化的數據,并由 GPU 數據庫實時處理,來識別可疑人物或異常移動的車輛。靈活轉移的工作地點和隱秘性,使得一臺帶 GPU 的筆記本比幾臺服務器更適合。
機器學習和深度分析
GPU 數據庫在機器學習和深度分析上的應用也越來越多。對于機器學習來講,在模型上跑機器學習算法,需要用多個數據集在多個模型上計算。越快算完,可驗證的模型就越多。 這方面的應用有很多文章,就不再贅述。
越來越多的廠家開始用 UDF 將人工智能、回歸、分類、預測等現成的代碼集成到 GPU 上運算,以充分利用 GPU 加速線性回歸、隨機森林、灰度提升樹(GBT)或蒙特卡羅仿真等。一般的實現方式是先將自己的 Java/Python/C/C++ 的函數和 library 向 GPU 數據庫注冊成 UDF 函數,然后在自己的 Python/Spark/Tensor Flow/Caffe 里訪問數據庫,比如通過 UDF 向 GPU 數據庫傳入一個表,在 GPU 上執行 UDF,返回數值結果或二進制的表結果。
GPU 數據庫的局限
GPU 數據庫擅長能夠被轉化成并行處理的任務,比如 Group By、JOIN、Aggregates、Hash。但不擅長某些難以并行的,比如排序,或者先排序再處理。
同時,由于顯存有限,在處理較大數據集時,需要內存、顯存之間的交換。數據準備、分塊、各個階段 IO 訪問和 Kernel 的同步協調等執行細節,對開發者的要求和代碼質量比較高。考慮到數據的實際物理分布、并行度、對 JOIN 優化等情況,還可能涉及到數據重分配,廣播等跨 GPU、跨節點的交換。雖然 NVidia 的 RDMA 通過支持 GPU 和網卡、GPU 同伴之間基于 PCI-E 總線的高速交換,能提高數據交換速度,但仍和開發水平關系很大。
一旦涉及到大量的寫操作,GPU 顯存小的劣勢更明顯,需要頻繁地和內存、磁盤之間交換。隨著計算的比例下降,IO 的比例上升,GPU 在計算上的優勢就被 IO 上的劣勢逐漸掩蓋。同時,分析型應用和顯存的有限,導致 GPU 數據庫常用列式存儲。因此對于一致性要求較高的場景,需慎用。它們一般提供最終一致性。讀寫并行時,如果有 20 個線程訪問,19 個讀、1 個寫,會讓所有讀都通過,無鎖、無事務,有可能帶來臟讀等問題。
在并發處理上,更多的是依靠高速計算能力,十幾毫秒的響應速度結合分布式、管道、隊列、消息系統等來提升并發性能。而如果十幾毫秒仍然不夠快, 從 GPU SIMD 的實施方式上來講,是獨占和單向的,有的指令要等所有核都計算完,數據同步后才能進入下個指令。 因此,如果某個核所需的數據沒準備好,有可能造成其他核空等。
實際上,GPU 數據庫這個稱謂,和其發展現狀來比,還有甚遠的距離。“數據庫”包括很多內容,性能僅僅是一個小部分。MySQL、PostgreSQL 等開源數據庫的成功遠遠不只是“性能”或“兼容”。窗口函數、CTE 等帶來的便捷、高可用、事務、ACID、元數據管理、冷熱數據分離、混合工作流等等都是大型數據庫集幾十年、數代的開發和應用逐漸積累的,基于 GPU 的數據產品還不能全面和商業數據庫媲美。
同時,站在數據湖的角度來看,GPU 能解決某些實時流處理、查詢和加工工作。而更多的報表、ETL、數據集市、關系型數據庫遷移、混合云等工作,還是需要基于 Hadoop 等分布式數據平臺,依靠全面的 ETL、索引、分區、冷熱數據分離、冷數據轉移、清理、合并、復制等。數據治理、元數據管理、安全和權限、彈性計算等方面,幾個 Hadoop 平臺廠家也有成熟、全面且可靠、好用的方案。
任重而道遠,且行且珍惜!