超實(shí)用的Spark數(shù)據(jù)傾斜解決姿勢(shì),學(xué)起來(lái)!
本文將結(jié)合實(shí)例詳細(xì)闡明Spark數(shù)據(jù)傾斜(Data Skew)的幾種場(chǎng)景及對(duì)應(yīng)的解決方案,包括避免數(shù)據(jù)源傾斜、調(diào)整并行度、使用自定義Partitioner、使用Map側(cè)Join代替Reduce側(cè)Join、給傾斜Key加上隨機(jī)前綴等。
一、為何要處理數(shù)據(jù)傾斜
1、什么是數(shù)據(jù)傾斜
對(duì)Spark/Hadoop這樣的大數(shù)據(jù)系統(tǒng)來(lái)講,數(shù)據(jù)量大并不可怕,可怕的是數(shù)據(jù)傾斜。
那何謂數(shù)據(jù)傾斜?數(shù)據(jù)傾斜指的是并行處理的數(shù)據(jù)集中,某一部分(如Spark或Kafka的一個(gè)Partition)的數(shù)據(jù)顯著多于其它部分,從而使得該部分的處理速度成為整個(gè)數(shù)據(jù)集處理的瓶頸。
2、數(shù)據(jù)傾斜是如何造成的
在Spark中,同一個(gè)Stage的不同Partition可以并行處理,而具有依賴(lài)關(guān)系的不同Stage之間是串行處理的。假設(shè)某個(gè)Spark Job分為Stage 0和Stage 1兩個(gè)Stage,且Stage 1依賴(lài)于Stage 0,那Stage 0完全處理結(jié)束之前不會(huì)處理Stage 1。而Stage 0可能包含N個(gè)Task,這N個(gè)Task可以并行進(jìn)行。如果其中N-1個(gè)Task都在10秒內(nèi)完成,而另外一個(gè)Task卻耗時(shí)1分鐘,那該Stage的總時(shí)間至少為1分鐘。換句話說(shuō),一個(gè)Stage所耗費(fèi)的時(shí)間,主要由最慢的那個(gè)Task決定。
由于同一個(gè)Stage內(nèi)的所有Task執(zhí)行相同的計(jì)算,在排除不同計(jì)算節(jié)點(diǎn)計(jì)算能力差異的前提下,不同Task之間耗時(shí)的差異主要由該Task所處理的數(shù)據(jù)量決定。
Stage的數(shù)據(jù)來(lái)源主要分為如下兩類(lèi):
- 從數(shù)據(jù)源直接讀取,如讀取HDFS、Kafka
- 讀取上一個(gè)Stage的Shuffle數(shù)據(jù)
二、如何緩解/消除數(shù)據(jù)傾斜
1、盡量避免數(shù)據(jù)源的數(shù)據(jù)傾斜
以Spark Stream通過(guò)DirectStream方式讀取Kafka數(shù)據(jù)為例。由于Kafka的每一個(gè)Partition對(duì)應(yīng)Spark的一個(gè)Task(Partition),所以Kafka內(nèi)相關(guān)Topic的各Partition之間數(shù)據(jù)是否平衡,直接決定Spark處理該數(shù)據(jù)時(shí)是否會(huì)產(chǎn)生數(shù)據(jù)傾斜。
Kafka某一Topic內(nèi)消息在不同Partition之間的分布,主要由Producer端所使用的Partition實(shí)現(xiàn)類(lèi)決定。如果使用隨機(jī)Partitioner,則每條消息會(huì)隨機(jī)發(fā)送到一個(gè)Partition中,那么從概率上來(lái)講,各Partition間的數(shù)據(jù)會(huì)達(dá)到平衡。此時(shí)源Stage(直接讀取Kafka數(shù)據(jù)的Stage)不會(huì)產(chǎn)生數(shù)據(jù)傾斜。
但很多時(shí)候,業(yè)務(wù)場(chǎng)景可能會(huì)要求將具備同一特征的數(shù)據(jù)順序消費(fèi),此時(shí)就需要將具有相同特征的數(shù)據(jù)放于同一個(gè)Partition中。一個(gè)典型的場(chǎng)景是,需要將同一個(gè)用戶(hù)相關(guān)的PV信息置于同一個(gè)Partition中。此時(shí),如果產(chǎn)生了數(shù)據(jù)傾斜,則需要通過(guò)其它方式處理。
2、調(diào)整并行度分散同一個(gè)Task的不同Key
原理
Spark在做Shuffle時(shí),默認(rèn)使用HashPartitioner(非Hash Shuffle)對(duì)數(shù)據(jù)進(jìn)行分區(qū)。如果并行度設(shè)置得不合適,可能造成大量不相同的Key對(duì)應(yīng)的數(shù)據(jù)被分配到了同一個(gè)Task上,造成該Task所處理的數(shù)據(jù)遠(yuǎn)大于其它Task,從而造成數(shù)據(jù)傾斜。
如果調(diào)整Shuffle時(shí)的并行度,使得原本被分配到同一Task的不同Key發(fā)配到不同Task上處理,則可降低原Task所需處理的數(shù)據(jù)量,從而緩解數(shù)據(jù)傾斜問(wèn)題造成的短板效應(yīng)
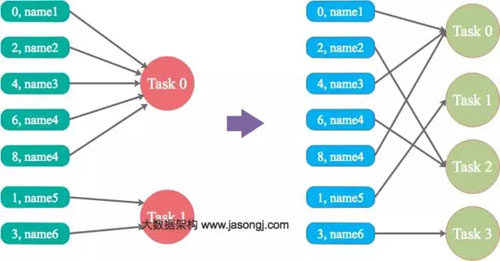
案例
現(xiàn)有一張測(cè)試表,名為student_external,內(nèi)有10.5億條數(shù)據(jù),每條數(shù)據(jù)有一個(gè)唯一的id值。現(xiàn)從中取出id取值為9億到10.5億的共1.5億條數(shù)據(jù),并通過(guò)一些處理,使得id為9億到9.4億間的所有數(shù)據(jù)對(duì)12取模后余數(shù)為8(即在Shuffle并行度為12時(shí)該數(shù)據(jù)集全部被HashPartition分配到第8個(gè)Task),其它數(shù)據(jù)集對(duì)其id除以100取整,從而使得id大于9.4億的數(shù)據(jù)在Shuffle時(shí)可被均勻分配到所有Task中,而id小于9.4億的數(shù)據(jù)全部分配到同一個(gè)Task中。
處理過(guò)程如下:
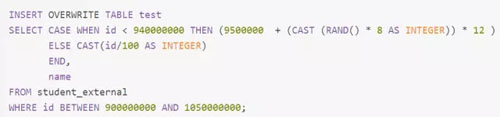
通過(guò)上述處理,一份可能造成后續(xù)數(shù)據(jù)傾斜的測(cè)試數(shù)據(jù)即以準(zhǔn)備好。接下來(lái),使用Spark讀取該測(cè)試數(shù)據(jù),并通過(guò)groupByKey(12)對(duì)id分組處理,且Shuffle并行度為12。代碼如下:

本次實(shí)驗(yàn)所使用集群節(jié)點(diǎn)數(shù)為4,每個(gè)節(jié)點(diǎn)可被Yarn使用的CPU核數(shù)為16,內(nèi)存為16GB。使用如下方式提交上述應(yīng)用,將啟動(dòng)4個(gè)Executor,每個(gè)Executor可使用核數(shù)為12(該配置并非生產(chǎn)環(huán)境下的***配置,僅用于本文實(shí)驗(yàn)),可用內(nèi)存為12GB。
- spark-submit --queue ambari --num-executors 4 --executor-cores 12 --executor-memory 12g --class com.jasongj.spark.driver.SparkDataSkew --master yarn --deploy-mode client SparkExample-with-dependencies-1.0.jar
GroupBy Stage的Task狀態(tài)如下圖所示,Task 8處理的記錄數(shù)為4500萬(wàn),遠(yuǎn)大于(9倍于)其它11個(gè)Task處理的500萬(wàn)記錄。而Task 8所耗費(fèi)的時(shí)間為38秒,遠(yuǎn)高于其它11個(gè)Task的平均時(shí)間(16秒)。整個(gè)Stage的時(shí)間也為38秒,該時(shí)間主要由最慢的Task 8決定。
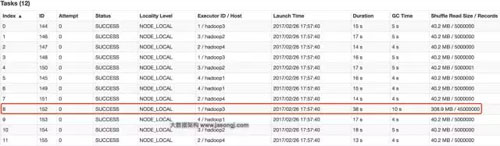
在這種情況下,可以通過(guò)調(diào)整Shuffle并行度,使得原來(lái)被分配到同一個(gè)Task(即該例中的Task 8)的不同Key分配到不同Task,從而降低Task 8所需處理的數(shù)據(jù)量,緩解數(shù)據(jù)傾斜。
通過(guò)groupByKey(48)將Shuffle并行度調(diào)整為48,重新提交到Spark。新的Job的GroupBy Stage所有Task狀態(tài)如下圖所示。
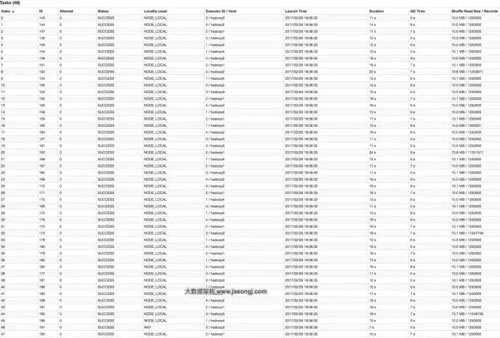
從上圖可知,記錄數(shù)最多的Task 20處理的記錄數(shù)約為1125萬(wàn),相比于并行度為12時(shí)Task 8的4500萬(wàn),降低了75%左右,而其耗時(shí)從原來(lái)Task 8的38秒降到了24秒。
在這種場(chǎng)景下,調(diào)整并行度,并不意味著一定要增加并行度,也可能是減小并行度。如果通過(guò)groupByKey(11)將Shuffle并行度調(diào)整為11,重新提交到Spark。新Job的GroupBy Stage的所有Task狀態(tài)如下圖所示。
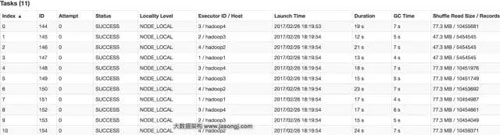
從上圖可見(jiàn),處理記錄數(shù)最多的Task 6所處理的記錄數(shù)約為1045萬(wàn),耗時(shí)為23秒。處理記錄數(shù)最少的Task 1處理的記錄數(shù)約為545萬(wàn),耗時(shí)12秒。
小結(jié)
適用場(chǎng)景:
大量不同的Key被分配到了相同的Task造成該Task數(shù)據(jù)量過(guò)大。
解決方案:
調(diào)整并行度。一般是增大并行度,但有時(shí)如本例減小并行度也可達(dá)到效果。
優(yōu)勢(shì):
實(shí)現(xiàn)簡(jiǎn)單,可在需要Shuffle的操作算子上直接設(shè)置并行度或者使用spark.default.parallelism設(shè)置。如果是Spark SQL,還可通過(guò)SET spark.sql.shuffle.partitions=[num_tasks]設(shè)置并行度。可用最小的代價(jià)解決問(wèn)題。一般如果出現(xiàn)數(shù)據(jù)傾斜,都可以通過(guò)這種方法先試驗(yàn)幾次,如果問(wèn)題未解決,再?lài)L試其它方法。
劣勢(shì):
適用場(chǎng)景少,只能將分配到同一Task的不同Key分散開(kāi),但對(duì)于同一Key傾斜嚴(yán)重的情況該方法并不適用。并且該方法一般只能緩解數(shù)據(jù)傾斜,沒(méi)有徹底消除問(wèn)題。從實(shí)踐經(jīng)驗(yàn)來(lái)看,其效果一般。
3、自定義Partitioner
原理
使用自定義的Partitioner(默認(rèn)為HashPartitioner),將原本被分配到同一個(gè)Task的不同Key分配到不同Task。
案例
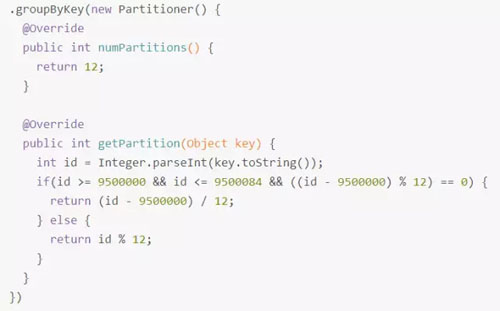
以上述數(shù)據(jù)集為例,繼續(xù)將并發(fā)度設(shè)置為12,但是在groupByKey算子上,使用自定義的Partitioner(實(shí)現(xiàn)如下):
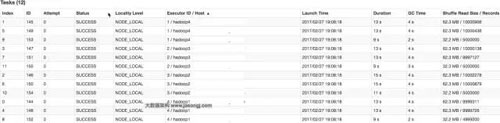
由下圖可見(jiàn),使用自定義Partition后,耗時(shí)最長(zhǎng)的Task 6處理約1000萬(wàn)條數(shù)據(jù),用時(shí)15秒。并且各Task所處理的數(shù)據(jù)集大小相當(dāng)。
小結(jié)
適用場(chǎng)景:
大量不同的Key被分配到了相同的Task,造成該Task數(shù)據(jù)量過(guò)大。
解決方案:
使用自定義的Partitioner實(shí)現(xiàn)類(lèi)代替默認(rèn)的HashPartitioner,盡量將所有不同的Key均勻分配到不同的Task中。
優(yōu)勢(shì):
不影響原有的并行度設(shè)計(jì)。如果改變并行度,后續(xù)Stage的并行度也會(huì)默認(rèn)改變,可能會(huì)影響后續(xù)Stage。
劣勢(shì):
適用場(chǎng)景有限,只能將不同Key分散開(kāi),對(duì)于同一Key對(duì)應(yīng)數(shù)據(jù)集非常大的場(chǎng)景不適用。效果與調(diào)整并行度類(lèi)似,只能緩解數(shù)據(jù)傾斜而不能完全消除數(shù)據(jù)傾斜。而且需要根據(jù)數(shù)據(jù)特點(diǎn)自定義專(zhuān)用的Partitioner,不夠靈活。
4、將Reduce side Join轉(zhuǎn)變?yōu)镸ap side Join
原理
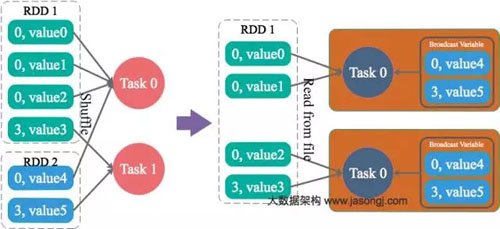
通過(guò)Spark的Broadcast機(jī)制,將Reduce側(cè)Join轉(zhuǎn)化為Map側(cè)Join,避免Shuffle從而完全消除Shuffle帶來(lái)的數(shù)據(jù)傾斜。
案例
通過(guò)如下SQL創(chuàng)建一張具有傾斜Key且總記錄數(shù)為1.5億的大表test。

使用如下SQL創(chuàng)建一張數(shù)據(jù)分布均勻且總記錄數(shù)為50萬(wàn)的小表test_new。
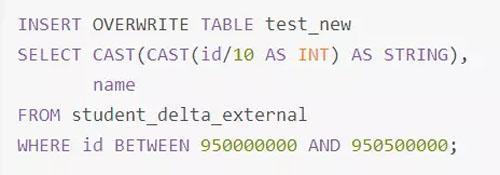
直接通過(guò)Spark Thrift Server提交如下SQL將表test與表test_new進(jìn)行Join并將Join結(jié)果存于表test_join中。

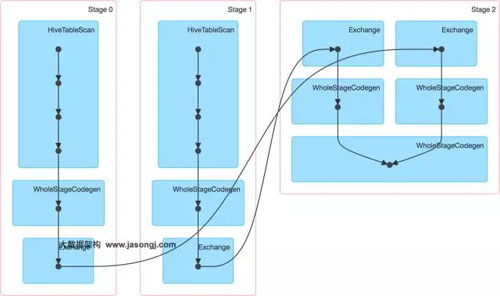
該SQL對(duì)應(yīng)的DAG如下圖所示。從該圖可見(jiàn),該執(zhí)行過(guò)程總共分為三個(gè)Stage,前兩個(gè)用于從Hive中讀取數(shù)據(jù),同時(shí)二者進(jìn)行Shuffle,通過(guò)***一個(gè)Stage進(jìn)行Join并將結(jié)果寫(xiě)入表test_join中。
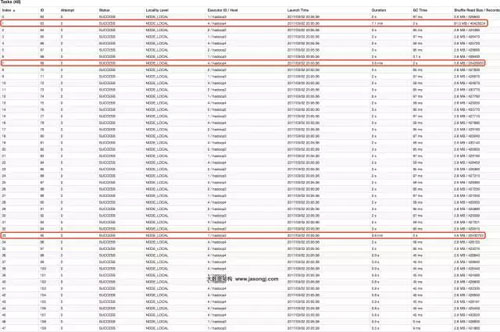
從下圖可見(jiàn),Join Stage各Task處理的數(shù)據(jù)傾斜嚴(yán)重,處理數(shù)據(jù)量***的Task耗時(shí)7.1分鐘,遠(yuǎn)高于其它無(wú)數(shù)據(jù)傾斜的Task約2秒的耗時(shí)。
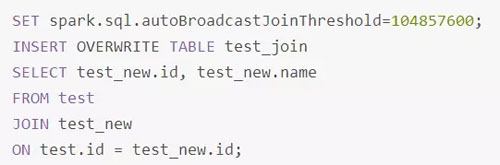
接下來(lái),嘗試通過(guò)Broadcast實(shí)現(xiàn)Map側(cè)Join。實(shí)現(xiàn)Map側(cè)Join的方法,并非直接通過(guò)CACHE TABLE test_new將小表test_new進(jìn)行cache。現(xiàn)通過(guò)如下SQL進(jìn)行Join。
通過(guò)如下DAG圖可見(jiàn),該操作仍分為三個(gè)Stage,且仍然有Shuffle存在,唯一不同的是,小表的讀取不再直接掃描Hive表,而是掃描內(nèi)存中緩存的表。
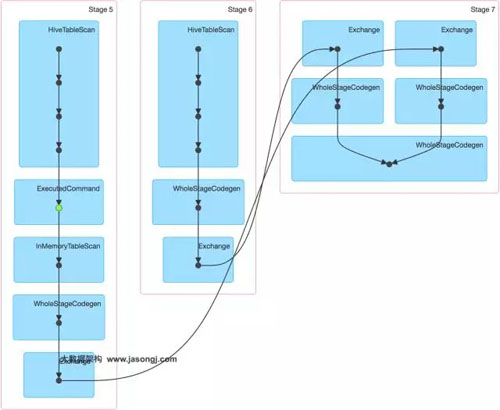
并且數(shù)據(jù)傾斜仍然存在。如下圖所示,最慢的Task耗時(shí)為7.1分鐘,遠(yuǎn)高于其它Task的約2秒。
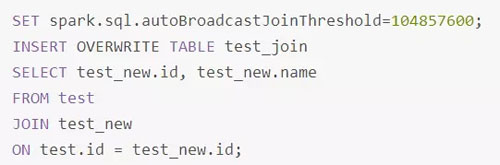
正確的使用Broadcast實(shí)現(xiàn)Map側(cè)Join的方式是,通過(guò)SET spark.sql.autoBroadcastJoinThreshold=104857600;將Broadcast的閾值設(shè)置得足夠大。
再次通過(guò)如下SQL進(jìn)行Join。
通過(guò)如下DAG圖可見(jiàn),該方案只包含一個(gè)Stage。
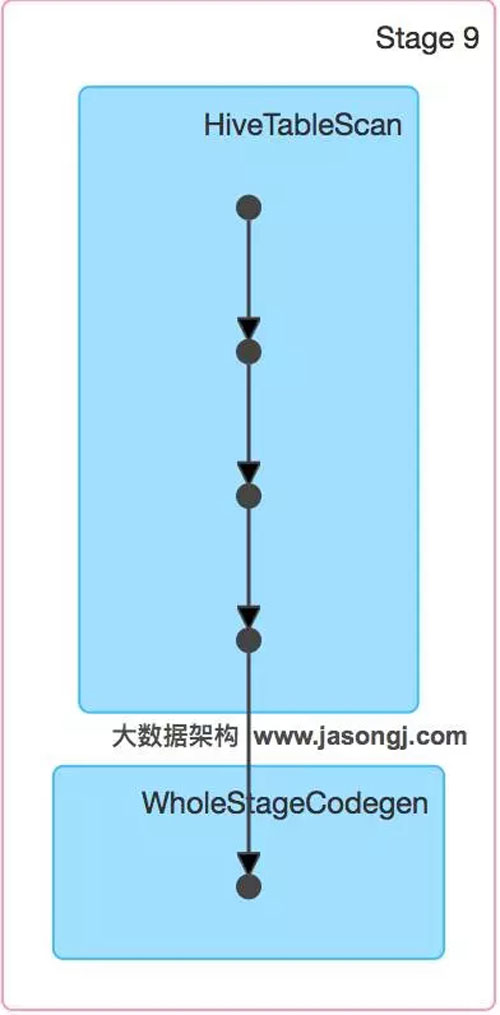
并且從下圖可見(jiàn),各Task耗時(shí)相當(dāng),無(wú)明顯數(shù)據(jù)傾斜現(xiàn)象。并且總耗時(shí)為1.5分鐘,遠(yuǎn)低于Reduce側(cè)Join的7.3分鐘。
小結(jié)
適用場(chǎng)景:
參與Join的一邊數(shù)據(jù)集足夠小,可被加載進(jìn)Driver并通過(guò)Broadcast方法廣播到各個(gè)Executor中。
解決方案:
在Java/Scala代碼中將小數(shù)據(jù)集數(shù)據(jù)拉取到Driver,然后通過(guò)Broadcast方案將小數(shù)據(jù)集的數(shù)據(jù)廣播到各Executor。或者在使用SQL前,將Broadcast的閾值調(diào)整得足夠多,從而使用Broadcast生效。進(jìn)而將Reduce側(cè)Join替換為Map側(cè)Join。
優(yōu)勢(shì):
避免了Shuffle,徹底消除了數(shù)據(jù)傾斜產(chǎn)生的條件,可極大提升性能。
劣勢(shì):
要求參與Join的一側(cè)數(shù)據(jù)集足夠小,并且主要適用于Join的場(chǎng)景,不適合聚合的場(chǎng)景,適用條件有限。
5、為skew的key增加隨機(jī)前/后綴
原理
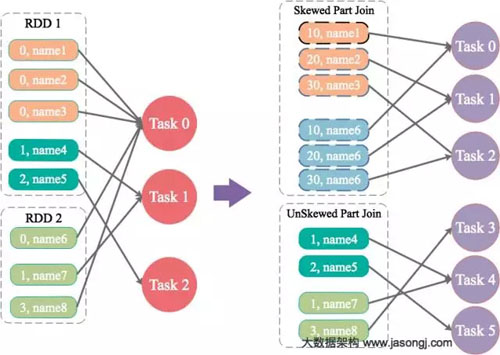
為數(shù)據(jù)量特別大的Key增加隨機(jī)前/后綴,使得原來(lái)Key相同的數(shù)據(jù)變?yōu)镵ey不相同的數(shù)據(jù),從而使傾斜的數(shù)據(jù)集分散到不同的Task中,徹底解決數(shù)據(jù)傾斜問(wèn)題。Join另一則的數(shù)據(jù)中,與傾斜Key對(duì)應(yīng)的部分?jǐn)?shù)據(jù),與隨機(jī)前綴集作笛卡爾乘積,從而保證無(wú)論數(shù)據(jù)傾斜側(cè)傾斜Key如何加前綴,都能與之正常Join。
案例
通過(guò)如下SQL,將id為9億到9.08億共800萬(wàn)條數(shù)據(jù)的id轉(zhuǎn)為9500048或者9500096,其它數(shù)據(jù)的id除以100取整。從而該數(shù)據(jù)集中,id為9500048和9500096的數(shù)據(jù)各400萬(wàn),其它id對(duì)應(yīng)的數(shù)據(jù)記錄數(shù)均為100條。這些數(shù)據(jù)存于名為test的表中。
對(duì)于另外一張小表test_new,取出50萬(wàn)條數(shù)據(jù),并將id(遞增且唯一)除以100取整,使得所有id都對(duì)應(yīng)100條數(shù)據(jù)。

通過(guò)如下代碼,讀取test表對(duì)應(yīng)的文件夾內(nèi)的數(shù)據(jù)并轉(zhuǎn)換為JavaPairRDD存于leftRDD中,同樣讀取test表對(duì)應(yīng)的數(shù)據(jù)存于rightRDD中。通過(guò)RDD的join算子對(duì)leftRDD與rightRDD進(jìn)行Join,并指定并行度為48。

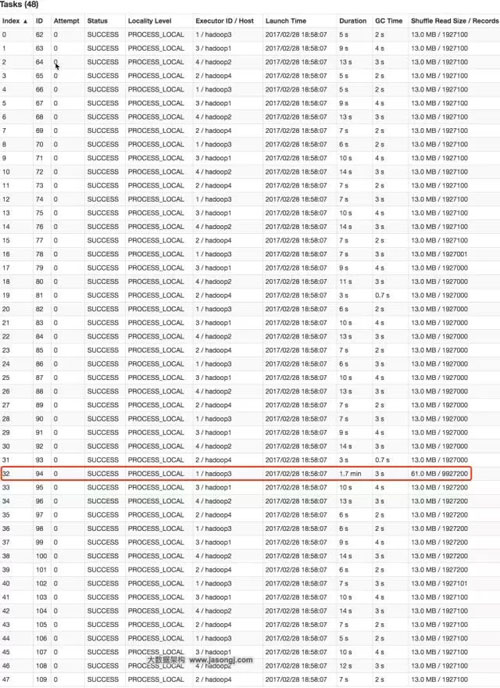
從下圖可看出,整個(gè)Join耗時(shí)1分54秒,其中Join Stage耗時(shí)1.7分鐘。

通過(guò)分析Join Stage的所有Task可知,在其它Task所處理記錄數(shù)為192.71萬(wàn)的同時(shí)Task 32的處理的記錄數(shù)為992.72萬(wàn),故它耗時(shí)為1.7分鐘,遠(yuǎn)高于其它Task的約10秒。這與上文準(zhǔn)備數(shù)據(jù)集時(shí),將id為9500048為9500096對(duì)應(yīng)的數(shù)據(jù)量設(shè)置非常大,其它id對(duì)應(yīng)的數(shù)據(jù)集非常均勻相符合。
現(xiàn)通過(guò)如下操作,實(shí)現(xiàn)傾斜Key的分散處理:
將leftRDD中傾斜的key(即9500048與9500096)對(duì)應(yīng)的數(shù)據(jù)單獨(dú)過(guò)濾出來(lái),且加上1到24的隨機(jī)前綴,并將前綴與原數(shù)據(jù)用逗號(hào)分隔(以方便之后去掉前綴)形成單獨(dú)的leftSkewRDD
將rightRDD中傾斜key對(duì)應(yīng)的數(shù)據(jù)抽取出來(lái),并通過(guò)flatMap操作將該數(shù)據(jù)集中每條數(shù)據(jù)均轉(zhuǎn)換為24條數(shù)據(jù)(每條分別加上1到24的隨機(jī)前綴),形成單獨(dú)的rightSkewRDD
將leftSkewRDD與rightSkewRDD進(jìn)行Join,并將并行度設(shè)置為48,且在Join過(guò)程中將隨機(jī)前綴去掉,得到傾斜數(shù)據(jù)集的Join結(jié)果skewedJoinRDD
將leftRDD中不包含傾斜Key的數(shù)據(jù)抽取出來(lái)作為單獨(dú)的leftUnSkewRDD
對(duì)leftUnSkewRDD與原始的rightRDD進(jìn)行Join,并行度也設(shè)置為48,得到Join結(jié)果unskewedJoinRDD
通過(guò)union算子將skewedJoinRDD與unskewedJoinRDD進(jìn)行合并,從而得到完整的Join結(jié)果集
具體實(shí)現(xiàn)代碼如下:

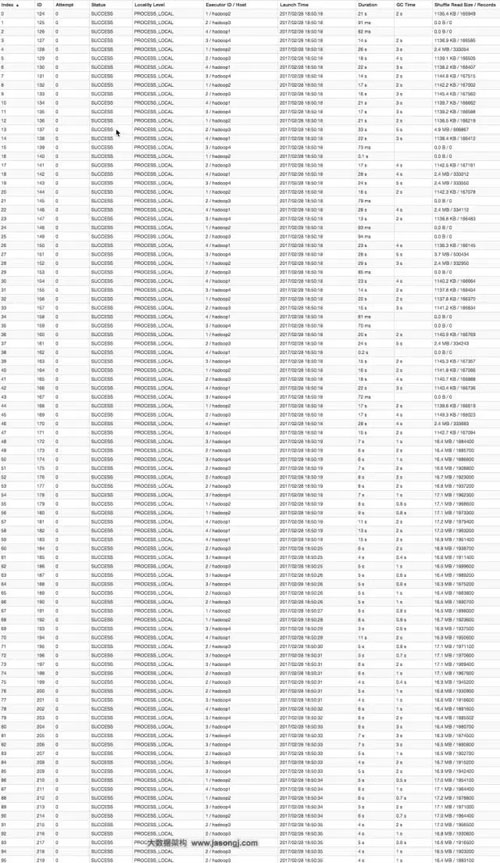
從下圖可看出,整個(gè)Join耗時(shí)58秒,其中Join Stage耗時(shí)33秒。

通過(guò)分析Join Stage的所有Task可知:
由于Join分傾斜數(shù)據(jù)集Join和非傾斜數(shù)據(jù)集Join,而各Join的并行度均為48,故總的并行度為96
由于提交任務(wù)時(shí),設(shè)置的Executor個(gè)數(shù)為4,每個(gè)Executor的core數(shù)為12,故可用Core數(shù)為48,所以前48個(gè)Task同時(shí)啟動(dòng)(其Launch時(shí)間相同),后48個(gè)Task的啟動(dòng)時(shí)間各不相同(等待前面的Task結(jié)束才開(kāi)始)
由于傾斜Key被加上隨機(jī)前綴,原本相同的Key變?yōu)椴煌腒ey,被分散到不同的Task處理,故在所有Task中,未發(fā)現(xiàn)所處理數(shù)據(jù)集明顯高于其它Task的情況
實(shí)際上,由于傾斜Key與非傾斜Key的操作完全獨(dú)立,可并行進(jìn)行。而本實(shí)驗(yàn)受限于可用總核數(shù)為48,可同時(shí)運(yùn)行的總Task數(shù)為48,故而該方案只是將總耗時(shí)減少一半(效率提升一倍)。如果資源充足,可并發(fā)執(zhí)行Task數(shù)增多,該方案的優(yōu)勢(shì)將更為明顯。在實(shí)際項(xiàng)目中,該方案往往可提升數(shù)倍至10倍的效率。
小結(jié)
適用場(chǎng)景:
兩張表都比較大,無(wú)法使用Map則Join。其中一個(gè)RDD有少數(shù)幾個(gè)Key的數(shù)據(jù)量過(guò)大,另外一個(gè)RDD的Key分布較為均勻。
解決方案:
將有數(shù)據(jù)傾斜的RDD中傾斜Key對(duì)應(yīng)的數(shù)據(jù)集單獨(dú)抽取出來(lái)加上隨機(jī)前綴,另外一個(gè)RDD每條數(shù)據(jù)分別與隨機(jī)前綴結(jié)合形成新的RDD(相當(dāng)于將其數(shù)據(jù)增到到原來(lái)的N倍,N即為隨機(jī)前綴的總個(gè)數(shù)),然后將二者Join并去掉前綴。然后將不包含傾斜Key的剩余數(shù)據(jù)進(jìn)行Join。***將兩次Join的結(jié)果集通過(guò)union合并,即可得到全部Join結(jié)果。
優(yōu)勢(shì):
相對(duì)于Map則Join,更能適應(yīng)大數(shù)據(jù)集的Join。如果資源充足,傾斜部分?jǐn)?shù)據(jù)集與非傾斜部分?jǐn)?shù)據(jù)集可并行進(jìn)行,效率提升明顯。且只針對(duì)傾斜部分的數(shù)據(jù)做數(shù)據(jù)擴(kuò)展,增加的資源消耗有限。
劣勢(shì):
如果傾斜Key非常多,則另一側(cè)數(shù)據(jù)膨脹非常大,此方案不適用。而且此時(shí)對(duì)傾斜Key與非傾斜Key分開(kāi)處理,需要掃描數(shù)據(jù)集兩遍,增加了開(kāi)銷(xiāo)。
6、大表隨機(jī)添加N種隨機(jī)前綴,小表擴(kuò)大N倍
原理
如果出現(xiàn)數(shù)據(jù)傾斜的Key比較多,上一種方法將這些大量的傾斜Key分拆出來(lái),意義不大。此時(shí)更適合直接對(duì)存在數(shù)據(jù)傾斜的數(shù)據(jù)集全部加上隨機(jī)前綴,然后對(duì)另外一個(gè)不存在嚴(yán)重?cái)?shù)據(jù)傾斜的數(shù)據(jù)集整體與隨機(jī)前綴集作笛卡爾乘積(即將數(shù)據(jù)量擴(kuò)大N倍)。
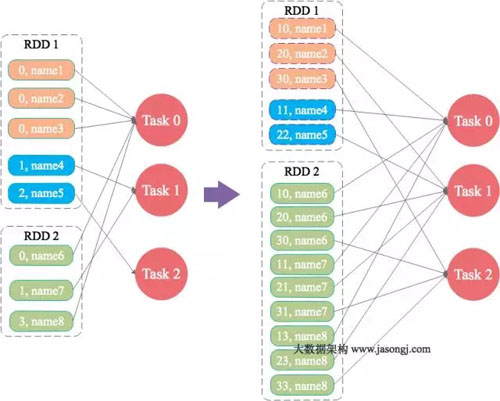
案例
這里給出示例代碼,讀者可參考上文中分拆出少數(shù)傾斜Key添加隨機(jī)前綴的方法,自行測(cè)試。

小結(jié)
適用場(chǎng)景:
一個(gè)數(shù)據(jù)集存在的傾斜Key比較多,另外一個(gè)數(shù)據(jù)集數(shù)據(jù)分布比較均勻。
優(yōu)勢(shì):
對(duì)大部分場(chǎng)景都適用,效果不錯(cuò)。
劣勢(shì):
需要將一個(gè)數(shù)據(jù)集整體擴(kuò)大N倍,會(huì)增加資源消耗。
三、總結(jié)
對(duì)于數(shù)據(jù)傾斜,并無(wú)一個(gè)統(tǒng)一的一勞永逸的方法。更多的時(shí)候,是結(jié)合數(shù)據(jù)特點(diǎn)(數(shù)據(jù)集大小,傾斜Key的多少等)綜合使用上文所述的多種方法。希望本文能對(duì)你有所幫助和啟發(fā)。