向量化與HashTrick在文本挖掘中預處理中的體現
前言
在(文本挖掘的分詞原理)中,我們講到了文本挖掘的預處理的關鍵一步:“分詞”,而在做了分詞后,如果我們是做文本分類聚類,則后面關鍵的特征預處理步驟有向量化或向量化的特例Hash Trick,本文我們就對向量化和特例Hash Trick預處理方法做一個總結。
詞袋模型
在講向量化與Hash Trick之前,我們先說說詞袋模型(Bag of Words,簡稱BoW)。詞袋模型假設我們不考慮文本中詞與詞之間的上下文關系,僅僅只考慮所有詞的權重。而權重與詞在文本中出現的頻率有關。
詞袋模型首先會進行分詞,在分詞之后,通過統計每個詞在文本中出現的次數,我們就可以得到該文本基于詞的特征,如果將各個文本樣本的這些詞與對應的詞頻放在一起,就是我們常說的向量化。向量化完畢后一般也會使用TF-IDF進行特征的權重修正,再將特征進行標準化。 再進行一些其他的特征工程后,就可以將數據帶入機器學習算法進行分類聚類了。
詞袋模型的三部曲:
- 分詞(tokenizing);
- 統計修訂詞特征值(counting);
- 標準化(normalizing);
與詞袋模型非常類似的一個模型是詞集模型(Set of Words,簡稱SoW),和詞袋模型***的不同是它僅僅考慮詞是否在文本中出現,而不考慮詞頻。也就是一個詞在文本在文本中出現1次和多次特征處理是一樣的。在大多數時候,我們使用詞袋模型,后面的討論也是以詞袋模型為主。
當然,詞袋模型有很大的局限性,因為它僅僅考慮了詞頻,沒有考慮上下文的關系,因此會丟失一部分文本的語義。但是大多數時候,如果我們的目的是分類聚類,則詞袋模型表現的很好。
BoW之向量化
在詞袋模型的統計詞頻這一步,我們會得到該文本中所有詞的詞頻,有了詞頻,我們就可以用詞向量表示這個文本。這里我們舉一個例子,例子直接用scikit-learn的CountVectorizer類來完成,這個類可以幫我們完成文本的詞頻統計與向量化,代碼如下:
- from sklearn.feature_extraction.text import CountVectorizer
- corpus=["I come to China to travel",
- "This is a car polupar in China",
- "I love tea and Apple ",
- "The work is to write some papers in science"]
- print vectorizer.fit_transform(corpus)
我們看看對于上面4個文本的處理輸出如下:
- (0, 16)1
- (0, 3)1
- (0, 15)2
- (0, 4)1
- (1, 5)1
- (1, 9)1
- (1, 2)1
- (1, 6)1
- (1, 14)1
- (1, 3)1
- (2, 1)1
- (2, 0)1
- (2, 12)1
- (2, 7)1
- (3, 10)1
- (3, 8)1
- (3, 11)1
- (3, 18)1
- (3, 17)1
- (3, 13)1
- (3, 5)1
- (3, 6)1
- (3, 15)1
可以看出4個文本的詞頻已經統計出,在輸出中,左邊的括號中的***個數字是文本的序號,第2個數字是詞的序號,注意詞的序號是基于所有的文檔的。第三個數字就是我們的詞頻。
我們可以進一步看看每個文本的詞向量特征和各個特征代表的詞,代碼如下:
- print vectorizer.fit_transform(corpus).toarray()
- print vectorizer.get_feature_names()
輸出如下:
- [[0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 2 1 0 0]
- [0 0 1 1 0 1 1 0 0 1 0 0 0 0 1 0 0 0 0]
- [1 1 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0]
- [0 0 0 0 0 1 1 0 1 0 1 1 0 1 0 1 0 1 1]]
- [u'and', u'apple', u'car', u'china', u'come', u'in', u'is', u'love', u'papers', u'polupar', u'science', u'some', u'tea', u'the', u'this', u'to', u'travel', u'work', u'write']
可以看到我們一共有19個詞,所以4個文本都是19維的特征向量。而每一維的向量依次對應了下面的19個詞。另外由于詞”I”在英文中是停用詞,不參加詞頻的統計。
由于大部分的文本都只會使用詞匯表中的很少一部分的詞,因此我們的詞向量中會有大量的0。也就是說詞向量是稀疏的。在實際應用中一般使用稀疏矩陣來存儲。將文本做了詞頻統計后,我們一般會通過TF-IDF進行詞特征值修訂。
向量化的方法很好用,也很直接,但是在有些場景下很難使用,比如分詞后的詞匯表非常大,達到100萬+,此時如果我們直接使用向量化的方法,將對應的樣本對應特征矩陣載入內存,有可能將內存撐爆,在這種情況下我們怎么辦呢?***反應是我們要進行特征的降維,說的沒錯!而Hash Trick就是非常常用的文本特征降維方法。
Hash Trick
在大規模的文本處理中,由于特征的維度對應分詞詞匯表的大小,所以維度可能非常恐怖,此時需要進行降維,不能直接用我們上一節的向量化方法。而最常用的文本降維方法是Hash Trick。說到Hash,一點也不神秘,學過數據結構的同學都知道。這里的Hash意義也類似。
在Hash Trick里,我們會定義一個特征Hash后對應的哈希表的大小,這個哈希表的維度會遠遠小于我們的詞匯表的特征維度,因此可以看成是降維。具體的方法是,對應任意一個特征名,我們會用Hash函數找到對應哈希表的位置,然后將該特征名對應的詞頻統計值累加到該哈希表位置。如果用數學語言表示,假如哈希函數h使第i個特征哈希到位置j,即h(i)=j,則第i個原始特征的詞頻數值ϕ(i)將累加到哈希后的第j個特征的詞頻數值ϕ¯上,即:
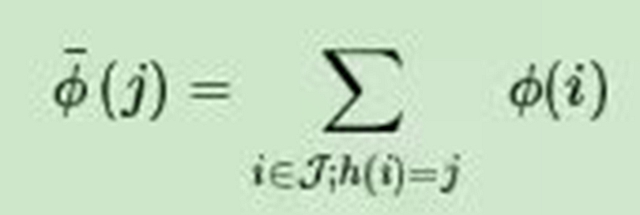
但是上面的方法有一個問題,有可能兩個原始特征的哈希后位置在一起導致詞頻累加特征值突然變大,為了解決這個問題,出現了hash Trick的變種signed hash trick,此時除了哈希函數h,我們多了一個哈希函數:
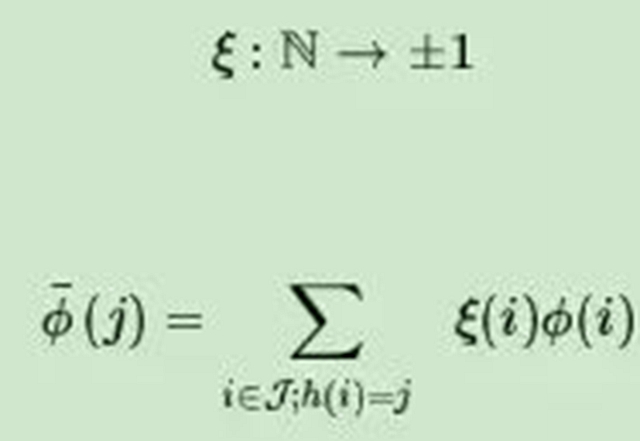
這樣做的好處是,哈希后的特征仍然是一個無偏的估計,不會導致某些哈希位置的值過大。
在scikit-learn的HashingVectorizer類中,實現了基于signed hash trick的算法,這里我們就用HashingVectorizer來實踐一下Hash Trick,為了簡單,我們使用上面的19維詞匯表,并哈希降維到6維。當然在實際應用中,19維的數據根本不需要Hash Trick,這里只是做一個演示,代碼如下:
- from sklearn.feature_extraction.text import HashingVectorizer
- vectorizer2=HashingVectorizer(n_features = 6,norm = None)print vectorizer2.fit_transform(corpus)
輸出如下:
- (0, 1)2.0
- (0, 2)-1.0
- (0, 4)1.0
- (0, 5)-1.0
- (1, 0)1.0
- (1, 1)1.0
- (1, 2)-1.0
- (1, 5)-1.0
- (2, 0)2.0
- (2, 5)-2.0
- (3, 0)0.0
- (3, 1)4.0
- (3, 2)-1.0
- (3, 3)1.0
- (3, 5)-1.0
和PCA類似,Hash Trick降維后的特征我們已經不知道它代表的特征名字和意義。此時我們不能像上一節向量化時候可以知道每一列的意義,所以Hash Trick的解釋性不強。
小結
在特征預處理的時候,我們什么時候用一般意義的向量化,什么時候用Hash Trick呢?標準也很簡單。
一般來說,只要詞匯表的特征不至于太大,大到內存不夠用,肯定是使用一般意義的向量化比較好。因為向量化的方法解釋性很強,我們知道每一維特征對應哪一個詞,進而我們還可以使用TF-IDF對各個詞特征的權重修改,進一步完善特征的表示。
而Hash Trick用大規模機器學習上,此時我們的詞匯量極大,使用向量化方法內存不夠用,而使用Hash Trick降維速度很快,降維后的特征仍然可以幫我們完成后續的分類和聚類工作。當然由于分布式計算框架的存在,其實一般我們不會出現內存不夠的情況。因此,實際工作中我使用的都是特征向量化。