美麗聯合業務升級下的機器學習應用
通常機器學習在電商領域有三大應用,推薦、搜索、廣告,這次我們聊聊三個領域里都會涉及到的商品排序問題。從業務角度,一般是在一個召回的商品集合里,通過對商品排序,追求GMV或者點擊量***化。進一步講,就是基于一個目標,如何讓流量的利用效率***。很自然的,如果我們可以準確預估每個商品的GMV轉化率或者點擊率,就可以***化利用流量,從而收益***。
蘑菇街是一個年輕女性垂直電商平臺,主要從事服飾鞋包類目,2015年時全年GMV超過了百億,后與美麗說合并后公司更名為美麗聯合集團。2014年時入職蘑菇街,那時候蘑菇街剛剛開始嘗試機器學習,這3年中經歷了很多變化,打造爆款、追求效率、提升品質等等。雖然在過程中經常和業務方互相challenge,但我們的理念——技術服務于業務始終沒有變化過。模型本身的迭代需配合業務目標才能發揮出***的價值,因此選擇模型迭代的路線,必須全盤考慮業務的情況。
在開始前,先和大家討論一些方法論。在點擊率預估領域,常用的是有監督的模型,其中樣本、特征、模型是三個繞不開的問題。首先,如何構建樣本,涉及模型的目標函數是什么,即要優化什么。原則上,我們希望樣本構建越接近真實場景越好。比如點擊率模型常用用戶行為日志作為樣本,曝光過沒有點擊的日志是負樣本,有點擊的是正樣本,去構建樣本集,變成一個二分類。在另一個相似的領域——Learning to rank,樣本構建方法可以分為三類:pointwise、pairwise、listwise。簡單來講,前面提到的構建樣本方式屬于pointwise范疇,即每一條樣本構建時不考慮與其他樣本直接的關系。但真實的場景中,往往需要考慮其他樣本的影響,比如去百度搜一個關鍵字,會出來一系列的結果,用戶的決策會受整個排序結果影響。故pairwise做了一點改進,它的樣本都是由pair對組成,比如電商搜索下,商品a和商品b可以構建一個樣本,如果a比b好,樣本pair{a,b}是正樣本,否則是負樣本。
當然,這會帶來新問題,比如a>b,b>c,c>a,這個時候怎么辦?有興趣的同學可以參考From RankNet to LambdaRank to LambdaMART: An Overview。而listwise就更接近真實,但復雜性也隨之增加,工業界用的比較少,這里不做過多描述。理論上,樣本構建方式listwise>pairwise>pointwise,但實際應用中,不一定是這個順序。比如,你在pointwise的樣本集下,模型的fit情況不是很好,比如auc不高,這個時候上pairwise,意義不大,更應該從特征和模型入手。一開始就選擇pairwise或者listwise,并不是一種好的實踐方式。
其次是模型和特征,不同模型對應不同的特征構建方式,比如廣告的點擊率預估模型,通常就有兩種組合方式:采用大規模離散特征+logistic regression模型或中小規模特征+復雜模型。比如gbdt這樣的樹模型,就沒有必要再對很多特征做離散化和交叉組合,特征規模可以小下來。很難說這兩種方式哪種好,但這里有個效率問題。在工業界,機器學習工程師大部分的時間都是花在特征挖掘上,因此很多時候叫數據挖掘工程師更加合適,但這本身是一件困難且低效難以復用的工作。希望能更***干凈地解決這些問題,是我們從不停地從學術界借鑒更強大的模型,雖然大部分不達預期,卻不曾放棄的原因。
言歸正傳,下文大致是按時間先后順序組織而成。
導購到電商
蘑菇街原來是做淘寶導購起家,在2013年轉型成電商平臺,剛開始的商品排序是運營和技術同學拍了一個公式,雖然很簡單,但也能解決大部分問題。作為一個初創的電商平臺,商家數量和質量都難以得到保障。當時公式有個買手優選的政策,即蘑菇街上主要售賣的商品都是經過公司的買手團隊人工審核,一定程度上保證了平臺的口碑,同時豎立平臺商品的標桿。但這個方式投入很重,為了讓這種模式得到***收益,必須讓商家主動學習這批買手優選商品的運營模型。另一方面,從技術角度講,系統迭代太快,導致數據鏈路不太可靠,且沒有分布式機器學習集群。我們做了簡化版的排序模型,將轉化、點擊、GMV表現好的一批商品作為正樣本,再選擇有一定曝光且表現不好的商品作為負樣本,做了一個爆款模型。該模型比公式排序的GMV要提升超過10%。
從結果上,這個模型還是很成功的,仔細分析下收益的來源:對比公式,主要是它更多相關的影響因子(即它的特征),而且在它的優化目標下學到了一個***的權重分配方案。而人工設計的公式很難包含太多因素,且是拍腦袋決定權重分配。由于這個模型的目標很簡單,學習商品成為爆款的可能性,因此做完常見CVR、CTR等統計特征,模型就達到了瓶頸。
做大做強,效率優先
到了2015年,平臺的DAU、GMV、商家商品數都在快速膨脹,原來的模型又暴露出新的業務問題。一是該模型對目標做了很大簡化,只考慮了top商品,對表現中等的商品區分度很小;二是模型本身沒有繼續優化的空間,auc超過了95%。這個時候,我們的數據鏈路和Spark集群已經準備好了。借鑒業界的經驗,開始嘗試轉化率模型。
我們的目標是追求GMV***化。因此最直接的是對GMV轉化率建模,曝光后有成交的為正樣本,否則為負樣本,再對正樣本按price重采樣,可以一定程度上模擬GMV轉化率。另一種方案,用戶的購買是有個決策路徑的,gmv = ctr * cvr * price,取log后可以變成log(gmv) = log(ctr) + log(cvr) + log(price),一般還會對這幾個目標加個權重因子。這樣,問題可以拆解成點擊率預估、轉化率預估,***再相加。從我們的實踐經驗看,第二種方案的效果優于***種,主要原因在于第二種方案將問題拆解成更小的問題后,降低了模型學習的難度,用戶購不購買商品的影響因素太多,***種方案對模型的要求要大于后面的。但第二種方案存在幾個目標之間需要融合,帶來了新的問題。可以嘗試對多個模型的結果,以GMV轉化率再做一次學習得到融合的方案,也可以根據業務需求,人工分配參數。
模型上我們嘗試過lr和lr+xgboost。lr的轉化率模型對比爆款模型轉化率有8%以上的提升,lr+xgboost對比lr gmv轉化率有5%以上的提升。但我們建議如果沒有嘗試過lr,還是先用lr去積累經驗。在lr模型中,我們把主要的精力放在了特征工程上。在電商領域,特征從類型上可以分為三大種類:商品、店鋪、用戶。又可以按其特點分為:
- 統計類:比如點擊率、轉化率、商品曝光、點擊、成交等,再對這些特征進行時間維度上的切割刻畫,可進一步增強特征的描述力度。
- 離散類:id類特征。比如商品id、店鋪id、用戶id、query類id、類目id等,很多公司會直接做onehot編碼,得到一個高維度的離散化稀疏特征。但這樣會對模型訓練、線上預測造成一定的工程壓力。另一種選擇是對其做編碼,用一種embedding的方式去做。
- 其他類:比如文本類特征,商品詳情頁標題、屬性詞等。
常見的特征處理手段有log、平滑、離散化、交叉。根據我們的實踐經驗,平滑非常重要,對一些統計類的特征,比如點擊率,天然是存在position bias。一個商品在曝光未充分之前,很難說是因為它本身就點擊率低還是因為沒有排到前面得到足夠的曝光導致。因此,通過對CTR平滑的方式來增強該指標的置信度,具體選擇貝葉斯平滑、拉普拉斯平滑或其他平滑手段都是可以的。這個平滑參數,大了模型退化成爆款模型,小了統計指標置信度不高,需根據當前數據分布去折中考慮。
我們借鑒了Facebook在gbdt+lr的經驗,用xgboost預訓練模型,將輸出的葉子節點當做特征輸入到lr模型中訓練。實踐中,需特別注意是選擇合理的歸一化方案避免訓練和預測階段數據分布的變化帶來模型的效果的不穩定。該方案容易出現過擬合的現象,建議樹的個數多一點,深度少一些。當然xgboost有很多針對過擬合的調參方案,這里不再復述。
在轉化率模型取得一定成果后,開始個性化的嘗試。個性化方案分為兩種:
- 標簽類個性化:購買力、風格、地域等。
- 行為粒度相似個性化(千人千面):推薦的思想,根據用戶的行為日志,構建商品序列,對這些序列中的商品找相識的商品去rerank。常見的方法有:
- 實時偏好
- 離線偏好
- 店鋪偏好
- etc
標簽類個性化具有可解釋高,業務合作點多等優點,而缺點是覆蓋率低,整體上指標提升不明顯。而行為粒度相識個性化優點是覆蓋率高,刻畫細致,上線后多次迭代,累計GMV提升10%。但其缺點是業務可解釋性差,業務方難以使用該技術去運營。
我們的個性化方案不是直接把特征放入模型,而是將排序分為初排和精排,在精排層做個性化。這樣精排可以只對topN個商品做個性化,qps有明顯提升。因此在架構上,如圖1,在傳統的搜索引擎上層加了一個精排,設計UPS系統做為用戶實時、離線特征存儲模型。
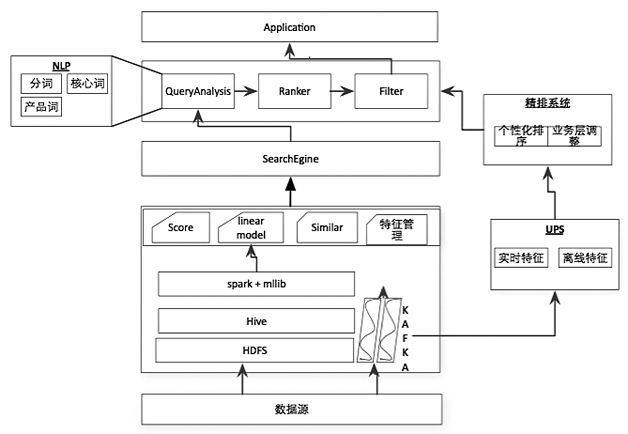
圖1 個性化排序系統架構
品質升級
隨著大環境消費升級的到來,公司將品質升級做為一個戰略方向。模型策略的目標是幫助業務方達成目標的同時,降低損失,減少流量的浪費。通過分人群引導的方案,建立流量端和品質商品端的聯系,達到在全局轉化率微跌的情況下,品質商品的流量提升40%。其整體的設計方案如圖2。
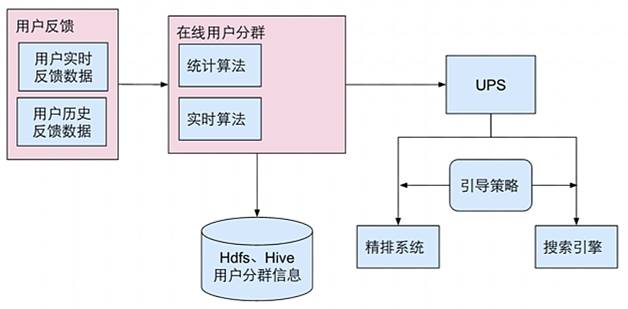
圖2 實時在線人群引導算法架構
將用戶的反饋分為實時和離線兩種,在Spark Stream上搭建在線分群模塊,***將用戶群的數據存儲在UPS中,在精排增加引導策略,實現對用戶在線實時分群引導,其數據流如圖3。
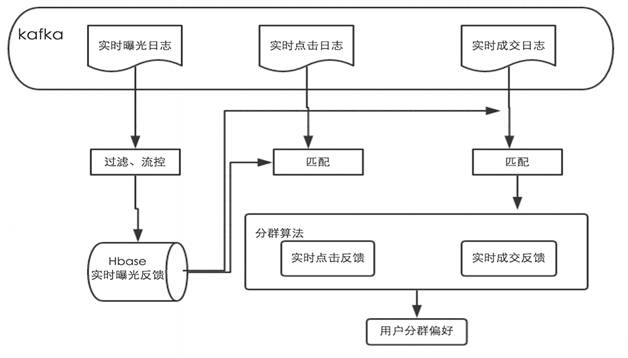
圖3 實時在線人群引導數據流
從效果看,引導和非引導次日回訪率隨時間逐步接近,流失率也在隨時間遞減,說明隨時間的推移,人群的分群會逐漸穩定。從全局占比看,大部分用戶都是可以引導的。
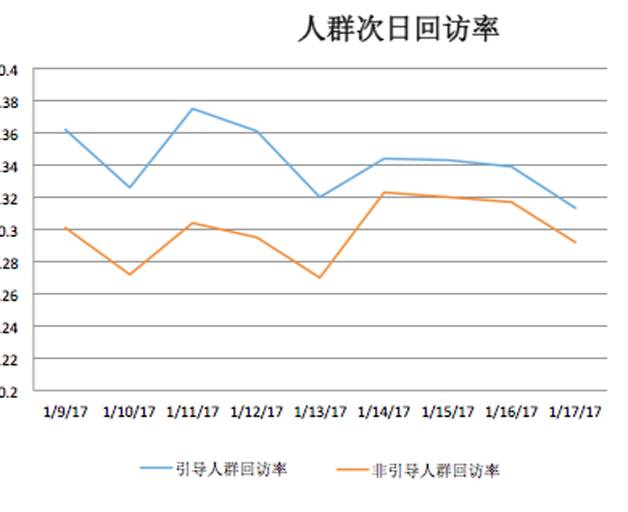
圖4 人群次日回訪率

圖5 次日引導用戶流失率
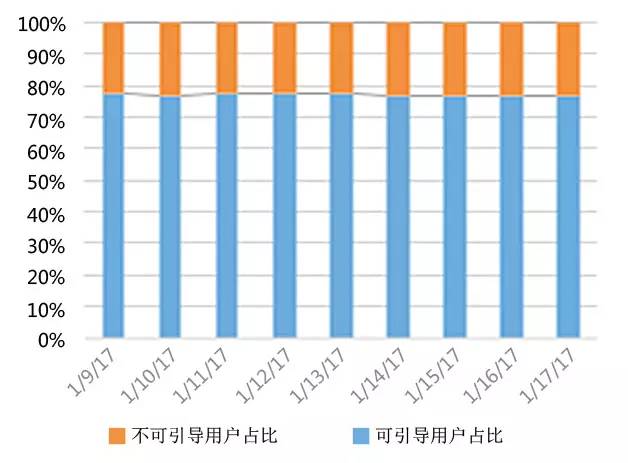
圖6 人群占比統計圖
未來
我們最近做了一些深度學習實驗,結合百度在CTR領域的DNN實踐,可以確認在電商領域應用深度學習的技術大有可為。另外,電商的業務場景天然具有導購的屬性,而這正好是可以與強化學習結合,阿里在這方面已經有不少嘗試。這兩塊后續也會是蘑菇街未來的方向。