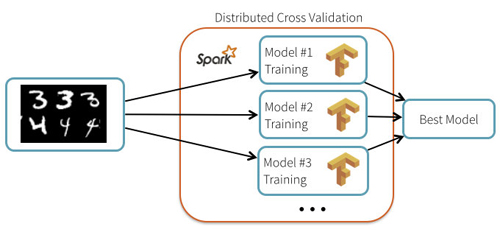
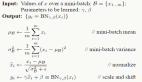用 Apache Spark 和 TensorFlow 進行深度學習
神經網絡在過去幾年中取得了驚人的進步,現在已成為圖像識別和自動翻譯領域***進的技術。TensorFlow是 Google 為數字計算和神經網絡發布的新框架。在這篇博文中,我們將演示如何使用 TensorFlow 和 Spark 一起來訓練和應用深度學習模型。
你可能會想:當大多數高性能深度學習實現只是單節點時,Apache Spark 在這里使用什么?為了回答這個問題,我們將通過兩個用例來解釋如何使用 Spark 和 TensorFlow 的集群機器來改進深度學習流程:
超參數調整:使用 Spark 找到神經網絡訓練的***超參數,使得訓練時間減少 10 倍并且錯誤率降低 34 %。
大規模部署模型:使用 Spark,在大量數據上應用訓練后神經網絡模型。
超參數調優
深度學習機器學習(ML)技術的一個例子是人工神經網絡。它們采取復雜的輸入,例如圖像或音頻記錄,然后對這些信號應用復雜的數學變換。該變換的輸出是數值向量,其更容易被其他 ML 算法運算。人工神經網絡通過模仿人腦視覺皮質中的神經元(以簡化形式)執行這種轉化。
正如人類學習解釋他們所看到的那樣,人工神經網絡需要被訓練來識別「有趣」的特定模式。例如,這些可以是簡單的圖案,例如,邊緣,圓形,但是它們可能要復雜。在這里,我們將使用由 NIST 組合的經典數據集,并訓練神經網絡來識別這些數字:

TensorFlow 庫自動化訓練各種形狀和大小的神經網絡算法的創建。然而,構建神經網絡的實際過程比僅在數據集上運行一些函數更復雜。通常會有許多非常重要的影響模型訓練效果的超參數(外行人術語中的配置參數)設置。選擇正確的參數會導致高性能,而不良參數會導致訓練時間長,性能不佳。在實踐中,機器學習從業者用不同的超參數多次重復運行相同的模型,以便找到***超參數集。這是一種稱為超參數優化的經典技術。
建立神經網絡時,有很多要慎重選擇的超參數。例如:
- 每層神經元數量:太少的神經元會降低網絡的表達力,但太多會大大增加運行時間并返回帶有噪聲的估計。
- 學習率:如果太高,神經網絡只會關注最近幾個樣本,忽視以前積累的所有經驗。如果太低,達到好狀態需要太長時間。
有趣的是,即使 TensorFlow 本身沒有分布,超參數調整過程也是「尷尬并行」,可以使用 Spark 進行分布。在這種情況下,我們可以使用 Spark 來 broadcast 諸如數據和模型描述之類的常見元素,然后在整個機器群集之間以容錯方式調度各個重復計算。
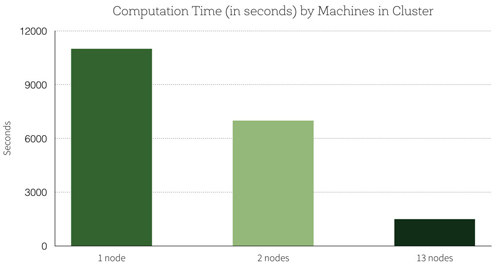
使用Spark如何提高準確性?超級參數的默認設置精度為 99.2%。通過超參數調優,在測試集上***的結果是具有 99.47% 的精度,這減少 34% 的測試誤差。分配添加到集群的節點數呈線性關系的計算:使用 13 節點集群,我們能夠并行訓練 13 個模型,這相當于在一臺機器上一次訓練一個模型的 7 倍速度。以下是關于機器集群數量的計算時間(以秒為單位)的圖表:
更重要的是,我們深入了解訓練過程的各種訓練超參數的敏感性。例如,對于不同數量的神經元,我們繪制關于學習率的最終測試性能:
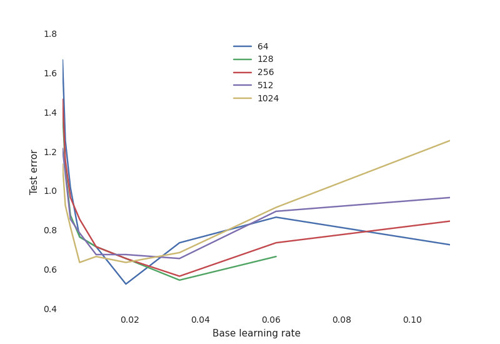
這顯示了神經網絡的典型權衡曲線:
- 學習率至關重要:如果太低,神經網絡不會學到任何東西(高測試錯誤率);如果太高,在某些配置中,訓練過程可能隨機振蕩甚至發散。
- 神經元的數量對于獲得良好的性能并不重要,并且具有許多神經元的網絡對于學習率更加敏感。這是奧卡姆的剃刀原理:對于大多數目標來說,更簡單的模型往往都是「夠好」的。如果你在缺少 1% 的測試錯誤率后有足夠的時間和資源,你可以投入大量資源進行訓練,并找到產生影響的適當的超參數。
通過使用稀疏的參數樣本,我們可以對最有希望的參數集進行歸零。
我該怎么用?
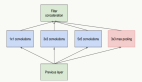
由于 TensorFlow 可以使用每個機器的所有核心,因此我們一次只能在每個機器運行一個任務,并將它們批處理以限制競爭。TensorFlow 庫可以作為常規 Python 庫安裝在 Spark 集群上,遵循 TensorFlow 網站上的說明。以下筆記本顯示如何安裝 TensorFlow,讓用戶重新運行此博客的實驗:
使用TensorFlow分布式處理圖像
使用TensorFlow測試圖像的分布處理
規模部署模型
TensorFlow 模型可以直接嵌入到管道中,以對數據集執行復雜的識別任務。例如,我們展示了如何從已經訓練的股票神經網絡模型中標注一組圖像。
該模型首先使用 Spark 的內置 broadcasting 機制分配給集群的機器:

然后將該模型加載到每個節點上并應用于圖像。這是每個節點上運行代碼的草圖:
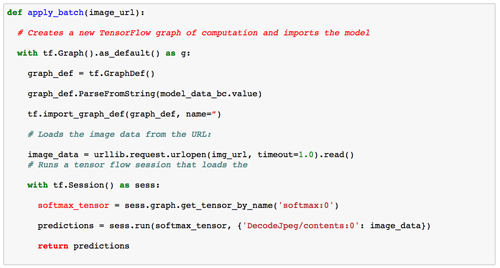
通過將圖像批量化在一起,可以使此代碼更有效率。
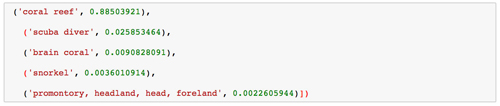
這是一個圖像的例子:
這里是根據神經網絡對這個圖像的解釋,這是非常準確的:
期待
針對手寫數字識別和圖像標識,我們已經展示了如何結合 Spark 和 TensorFlow 訓練和部署神經網絡。即使我們使用的神經網絡框架本身只適用于單節點,我們可以使用 Spark 來分配超參數調整過程和模型部署。這不僅減少了訓練時間,而且提高了準確度,使我們更好地了解了各種超參數的敏感性。
雖然此支持僅適用于 Python,但我們期待在 TensorFlow 和 Spark 框架的其余部分之間進行更深入的集成。