數(shù)據(jù)預處理——是臟活、累活,卻也價值無限
據(jù)預處理——是臟活、累活,卻也價值***")
當有大企業(yè)為數(shù)據(jù)進行爭論時,我們再一次感慨數(shù)據(jù)的價值。自從大數(shù)據(jù)一詞被提出之后,我們無時無刻不再提醒著自己,累積了越多的數(shù)據(jù),就越能手握金礦。在機器學習、深度神經(jīng)網(wǎng)絡開始走向大眾視野之后,我們更加自豪,仿佛分分鐘能從自己的數(shù)據(jù)中誕生個什么算法。
事實上,針對于機器學習應用范疇看來,絕大部分企業(yè)所謂的大數(shù)據(jù),都只是一大堆占據(jù)著儲存空間的垃圾。
因為,這些大數(shù)據(jù)都是未經(jīng)清洗、處理過的臟數(shù)據(jù),完全不足以用來訓練算法模型。
今天就來談談機器學習這一高級產業(yè)中的“苦力工種”——數(shù)據(jù)預處理。
拋開盲目崇拜,我們其實知道,機器學習對于數(shù)據(jù)的依賴非常之深,同時對數(shù)據(jù)的要求也很高。和數(shù)據(jù)庫中的數(shù)據(jù)不同,現(xiàn)實生活中我們采集到的數(shù)據(jù)往往存在大量人為造成的異常和缺失,非常不利于算法模型的訓練。
而對于數(shù)據(jù)的清洗、特征標注等等,往往占據(jù)了一個項目七成的時間。
在分析了項目的具體需求之后,***步就是數(shù)據(jù)的清洗。
數(shù)據(jù)清洗包含多種步驟,比如對異常值的處理、對缺失數(shù)據(jù)的處理和對重復數(shù)據(jù)的處理等等。
常用的辦法是將數(shù)據(jù)制成直方圖、點圖、箱型圖、Q-Q 圖等等,從其中可以直觀的發(fā)現(xiàn)需要清理的數(shù)據(jù)。
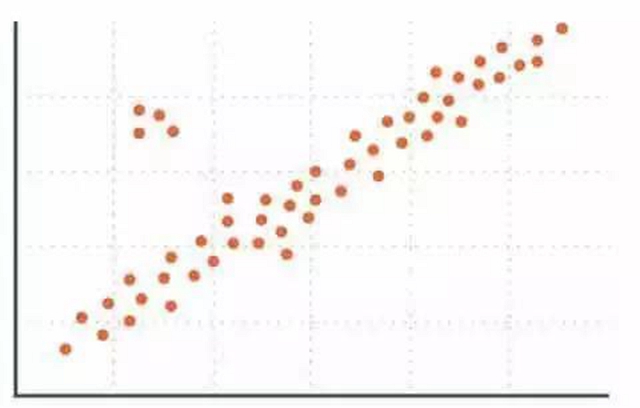
如圖所示,遠離群體的數(shù)據(jù)均為需要清理的數(shù)據(jù)。當然,清理也不一定是刪除,可以根據(jù)實際情況選擇用平均值替代甚至不處理等等。
在經(jīng)歷了痛苦的去異常、去缺失、去重復、降噪音之后,我們得到的僅僅是一份沒有明顯錯誤的原始數(shù)據(jù)。還要經(jīng)歷數(shù)據(jù)轉換、降維等等方式讓數(shù)據(jù)標準化,只保留我們所需要的維度。這樣一來才可以進一步降低噪音,去除無關特征帶來的巨大計算量。
以上的步驟可以運用于任何數(shù)據(jù)之上,像是在 NLP 中就要提取波形文件,去掉連接詞、分詞等等。至于在人臉識別中,則是將每個人的名字和對應的照片標注歸類,去掉混亂度較高的人。再提取圖片向量,一個人照片中向量的平均值既是他的特征。
總之,數(shù)據(jù)預處理工作的難度不大,但卻能折騰的人欲仙欲死。
這也是為什么 Apollo 這樣的平臺會為人工智能創(chuàng)業(yè)者提供數(shù)據(jù)庫,畢竟對于大多數(shù)中小企業(yè)來講,獲取數(shù)據(jù)雖然簡單,對于數(shù)據(jù)的預處理卻是幾乎不可能完成的任務。而以谷歌、百度等為代表的大企業(yè),擁有足夠的人力和算力,能夠將自己的數(shù)據(jù)妥善處理,甚至開放開來組建生態(tài)力量。
除去與巨頭共舞,另外的選擇就是購買第三方提供的數(shù)據(jù)庫,可***的問題就是數(shù)據(jù)的真實性和實用性。糟糕數(shù)據(jù)庫帶來的結果,往往是算法在數(shù)據(jù)庫內跑的風生水起,一落地應用就漏洞百出。而在資本的揠苗助長下,大多數(shù)人都忙著鼓吹自己的算法模型而忽略了數(shù)據(jù)源頭問題,最終就是將萬丈高樓建立在沙地之上。
面對這種情況,最苦惱的就是那些還算不上 BAT 級別,但又有了足夠規(guī)模的互聯(lián)網(wǎng)企業(yè):他們擁有了足夠多的數(shù)據(jù),不屑于拿所謂的算法作為融資噱頭,而是真的想通過機器學習提升自身業(yè)務。可面對復雜的數(shù)據(jù)預處理工作,他們需要付出極大的人力成本。要是說邀請第三方為其處理,恐怕又不放心自身數(shù)據(jù)的安全。
而這一切,不正是商機所在嗎?
在今年三月的谷歌云開發(fā)者大會上,谷歌就發(fā)布了一項新服務—— Google Cloud Dataprep。它可以自動檢索出數(shù)據(jù)中的異常值,用戶只要給出數(shù)據(jù)清理規(guī)則,整個過程中都不需要人工寫代碼來干預。所以,用戶既可以簡單的完成數(shù)據(jù)清理,又能很大程度上保證數(shù)據(jù)安全。
數(shù)據(jù)的預處理的確是機器學習中的“臟活累活”,但這不代表不能用技術的力量提高這部分工作的效率。相比遙遙無期的人工智能,有關數(shù)據(jù)預處理的需求已經(jīng)擺在了我們面前,并且每天都在擴大。而專注與數(shù)據(jù)預處理垂直領域的技術服務商卻***。
所以,與其在 NLP、自動駕駛的紅海中被巨頭碾壓,不如換個角度,從現(xiàn)在就開始想辦法服務那些渴望 AI 的企業(yè)。