DB分庫分表(2):全局主鍵生成策略
本文將主要介紹一些常見的全局主鍵生成策略,然后重點介紹flickr使用的一種非常優秀的全局主鍵生成方案。關于分庫分表(sharding)的拆分策略和實施細則,請參考該系列的前一篇文章:DB 分庫分表(1):拆分實施策略和示例演示
***部分:一些常見的主鍵生成策略
一旦數據庫被切分到多個物理結點上,我們將不能再依賴數據庫自身的主鍵生成機制。一方面,某個分區數據庫自生成的ID無法保證在全局上是唯一的;另一方面,應用程序在插入數據之前需要先獲得ID,以便進行SQL路由。目前幾種可行的主鍵生成策略有:
1. UUID:使用UUID作主鍵是最簡單的方案,但是缺點也是非常明顯的。由于UUID非常的長,除占用大量存儲空間外,最主要的問題是在索引上,在建立索引和基于索引進行查詢時都存在性能問題。
2. 結合數據庫維護一個Sequence表:此方案的思路也很簡單,在數據庫中建立一個Sequence表,表的結構類似于:
- CREATE TABLE `SEQUENCE` (
- `tablename` varchar(30) NOT NULL,
- `nextid` bigint(20) NOT NULL,
- PRIMARY KEY (`tablename`)
- ) ENGINE=InnoDB
每當需要為某個表的新紀錄生成ID時就從Sequence表中取出對應表的nextid,并將nextid的值加1后更新到數據庫中以備下次使用。此方案也較簡單,但缺點同樣明顯:由于所有插入任何都需要訪問該表,該表很容易成為系統性能瓶頸,同時它也存在單點問題,一旦該表數據庫失效,整個應用程序將無法工作。有人提出使用Master-Slave進行主從同步,但這也只能解決單點問題,并不能解決讀寫比為1:1的訪問壓力問題。
除此之外,還有一些方案,像對每個數據庫結點分區段劃分ID,以及網上的一些ID生成算法,因為缺少可操作性和實踐檢驗,本文并不推薦。實際上,接下來,我們要介紹的是Fickr使用的一種主鍵生成方案,這個方案是目前我所知道的***秀的一個方案,并且經受了實踐的檢驗,可以為大多數應用系統所借鑒。
第二部分:一種極為優秀的主鍵生成策略
flickr開發團隊在2010年撰文介紹了flickr使用的一種主鍵生成測策略,同時表示該方案在flickr上的實際運行效果也非常令人滿意,這個方案是我目前知道的***的方案,它與一般Sequence表方案有些類似,但卻很好地解決了性能瓶頸和單點問題,是一種非常可靠而高效的全局主鍵生成方案。
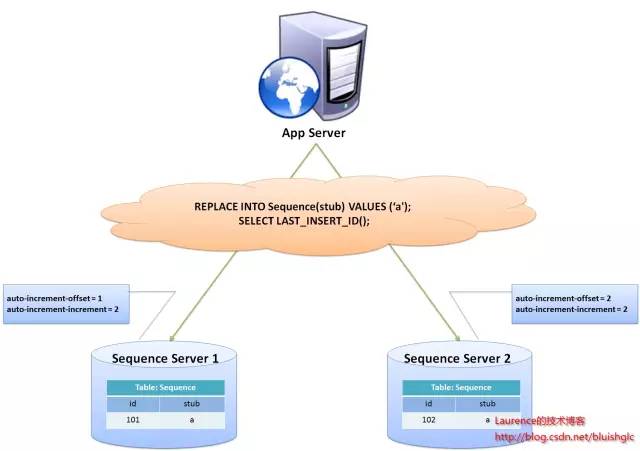
圖1. flickr采用的sharding主鍵生成方案示意圖
flickr這一方案的整體思想是:建立兩臺以上的數據庫ID生成服務器,每個服務器都有一張記錄各表當前ID的Sequence表,但是Sequence中ID增長的步長是服務器的數量,起始值依次錯開,這樣相當于把ID的生成散列到了每個服務器節點上。例如:如果我們設置兩臺數據庫ID生成服務器,那么就讓一臺的Sequence表的ID起始值為1,每次增長步長為2,另一臺的Sequence表的ID起始值為2,每次增長步長也為2,那么結果就是奇數的ID都將從***臺服務器上生成,偶數的ID都從第二臺服務器上生成,這樣就將生成ID的壓力均勻分散到兩臺服務器上,同時配合應用程序的控制,當一個服務器失效后,系統能自動切換到另一個服務器上獲取ID,從而保證了系統的容錯。
關于這個方案,有幾點細節這里再說明一下:
1. flickr的數據庫ID生成服務器是專用服務器,服務器上只有一個數據庫,數據庫中表都是用于生成Sequence的,這也是因為auto-increment-offset和auto-increment-increment這兩個數據庫變量是數據庫實例級別的變量。
2. flickr的方案中表格中的stub字段只是一個char(1) NOT NULL存根字段,并非表名,因此,一般來說,一個Sequence表只有一條紀錄,可以同時為多張表生成ID,如果需要表的ID是有連續的,需要為該表單獨建立Sequence表。
3. 方案使用了MySQL的LAST_INSERT_ID()函數,這也決定了Sequence表只能有一條記錄。
4. 使用REPLACE INTO插入數據,這是很討巧的作法,主要是希望利用mysql自身的機制生成ID,不僅是因為這樣簡單,更是因為我們需要ID按照我們設定的方式(初值和步長)來生成。
5. SELECT LAST_INSERT_ID()必須要于REPLACE INTO語句在同一個數據庫連接下才能得到剛剛插入的新ID,否則返回的值總是0
6. 該方案中Sequence表使用的是MyISAM引擎,以獲取更高的性能,注意:MyISAM引擎使用的是表級別的鎖,MyISAM對表的讀寫是串行的,因此不必擔心在并發時兩次讀取會得到同一個ID(另外,應該程序也不需要同步,每個請求的線程都會得到一個新的connection,不存在需要同步的共享資源)。經過實際對比測試,使用一樣的Sequence表進行ID生成,MyISAM引擎要比InnoDB表現高出很多!
7. 可使用純JDBC實現對Sequence表的操作,以便獲得更高的效率,實驗表明,即使只使用spring JDBC性能也不及純JDBC來得快!
實現該方案,應用程序同樣需要做一些處理,主要是兩方面的工作:
1. 自動均衡數據庫ID生成服務器的訪問
2. 確保在某個數據庫ID生成服務器失效的情況下,能將請求轉發到其他服務器上執行。