人工智能、機器學(xué)習(xí)和認知計算入門指南
習(xí)和認知計算入門指南")
幾千年來,人們就已經(jīng)有了思考如何構(gòu)建智能機器的想法。從那時開始,人工智能 (AI) 經(jīng)歷了起起落落,這證明了它的成功以及還未實現(xiàn)的潛能。如今,隨時都能聽到應(yīng)用機器學(xué)習(xí)算法來解決新問題的新聞。從癌癥檢測和預(yù)測到圖像理解和總結(jié)以及自然語言處理,AI 正在增強人們的能力和改變我們的世界。
現(xiàn)代 AI 的歷史包含一部偉大的戲劇應(yīng)具有的所有要素。上世紀 50 年代,隨著對思維機器及阿蘭·圖靈和約翰·馮·諾依曼等著名人物的關(guān)注,AI 開始嶄露頭角。盡管隨后經(jīng)歷了數(shù)十年的繁榮與蕭條,并被寄予了難以實現(xiàn)的厚望,但 AI 和它的先驅(qū)們?nèi)匀灰恢痹谂η靶小H缃瘢珹I 展現(xiàn)出了它的真正潛力,專注于應(yīng)用并提供深度學(xué)習(xí)和認知計算等技術(shù)。
本文將探索 AI 的一些重要方面和它的子領(lǐng)域。我們首先會分析 AI 的時間線,然后深入介紹每種要素。
現(xiàn)代 AI 的時間線
從上世紀 50 年代開始,現(xiàn)代 AI 開始專注于所謂的強 AI,強 AI 指的是能普遍執(zhí)行人類所能執(zhí)行的任何智能任務(wù)的 AI。強 AI 的進展乏力,最終導(dǎo)致了所謂的弱 AI,或者將 AI 技術(shù)應(yīng)用于更小范圍的問題。直到上世紀 80 年代,AI 研究被拆分為這兩種范式。但在 1980 年左右,機器學(xué)習(xí)成為了一個突出的研究領(lǐng)域,它的目標是讓計算機能學(xué)習(xí)并構(gòu)建模型,以便能夠執(zhí)行一些活動,比如特定領(lǐng)域中的預(yù)測。
圖 1. 現(xiàn)代人工智能的時間線

點擊查看大圖深度學(xué)習(xí)于 2000 年左右出現(xiàn),建立在 AI 和機器學(xué)習(xí)的研究成果之上。計算機科學(xué)家通過新的拓撲結(jié)構(gòu)和學(xué)習(xí)方法,在許多層中使用神經(jīng)網(wǎng)絡(luò)。神經(jīng)網(wǎng)絡(luò)的這次演變成功解決了各種不同領(lǐng)域的復(fù)雜問題。
在過去 10 年中,認知計算興起,它的目標是構(gòu)建能學(xué)習(xí)并自然地與人交流的系統(tǒng)。IBM Watson 通過在 Jeopardy 比賽上成功擊敗世界級對手,證明了認知計算的能力。
在本教程中,我將探索每個領(lǐng)域,解釋一些促使認知計算取得成功的重要算法。
基礎(chǔ) AI
1950 年前的研究中提出了大腦由電脈沖網(wǎng)絡(luò)組成的理念,這些脈沖觸發(fā)并以某種方式精心組織形成思想和意識。阿蘭·圖靈表明任何計算都能以數(shù)字方式實現(xiàn),那時,距離實現(xiàn)構(gòu)建一臺能模仿人腦的機器的想法也就不遠了。
許多早期研究都重點關(guān)注過這個強 AI 方面,但這一時期也引入了一些基礎(chǔ)概念,如今的所有機器學(xué)習(xí)和深度學(xué)習(xí)都是在這些概念基礎(chǔ)上建立起來的。
圖 2. 1980 年前的人工智能方法的時間線
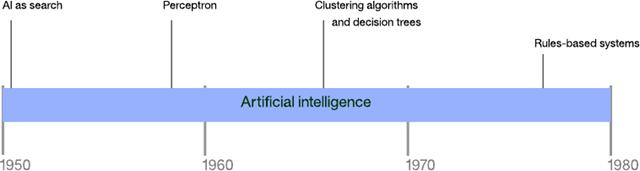
AI 即搜索
AI 中的許多問題都可以通過暴力搜索(比如深度或廣度優(yōu)先搜索)來解決。但是,考慮到普通問題的搜索空間,基本搜索很快就會招架不住。AI 即搜索的最早示例之一是一個下棋程序的開發(fā)。Arthur Samuel 在 IBM 701 Electronic Data Processing Machine 上構(gòu)建了第一個這樣的程序,對搜索樹執(zhí)行一種名為 α-β 剪枝技術(shù)(alpha-beta pruning)的優(yōu)化。他的程序還會記錄特定某步棋的回報,允許應(yīng)用程序?qū)W習(xí)每一場比賽(使它成為了第一個自主學(xué)習(xí)的程序)。為了提高程序的學(xué)習(xí)速度,Samuel 將它設(shè)計為能夠自己跟自己下棋,提高了它的下棋和學(xué)習(xí)能力。
盡管可以成功地應(yīng)用對許多簡單問題的搜索,但隨著選擇數(shù)量的增加,該方法很快就會行不通。以簡單的井字棋游戲為例。在游戲開始時,有 9 種可能的棋著。每步棋著會導(dǎo)致 8 種可能的對抗棋著,以此類推。井字棋完整的棋著樹(未進行旋轉(zhuǎn)優(yōu)化來刪除重復(fù)棋著)有 362,880 個節(jié)點。如果您將同樣的思維試驗推廣到象棋或圍棋,很快就會看到搜索的缺點。
感知器
感知器是一種用于單層神經(jīng)網(wǎng)絡(luò)的早期的監(jiān)督式學(xué)習(xí)算法。給定一個輸入特征矢量,感知器算法就能學(xué)習(xí)將輸入劃分到特定類別。通過使用訓(xùn)練集,可以更新線性分類的網(wǎng)絡(luò)的權(quán)值和閥值。感知器最初是針對 IBM 704 實現(xiàn)的,隨后被用在定制硬件上,用于圖像識別。
圖 3. 感知器和線性分類
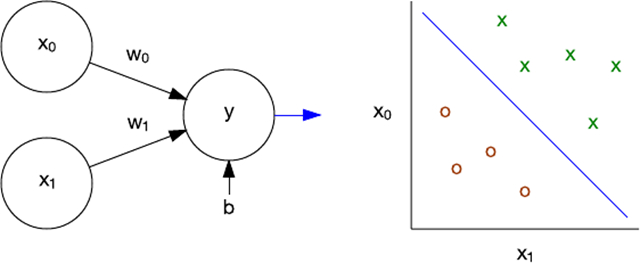
作為線性分類器,感知器能線性地分離問題。感知器的局限性的重要示例是,它無法學(xué)習(xí)一個異或 (XOR) 函數(shù)。多層感知器解決了這一問題,為更復(fù)雜的算法、網(wǎng)絡(luò)拓撲結(jié)構(gòu)和深度學(xué)習(xí)鋪平了道路。
集群算法
對于感知器,學(xué)習(xí)方法是監(jiān)督式的。用戶提供數(shù)據(jù)來訓(xùn)練網(wǎng)絡(luò),然后針對新數(shù)據(jù)來測試網(wǎng)絡(luò)。集群算法采用了一種不同的學(xué)習(xí)方法,叫做無監(jiān)督學(xué)習(xí)。在此模型中,算法基于數(shù)據(jù)的一個或多個屬性,將一組特征矢量組織到集群中。
圖 4. 二維特征空間中的集群
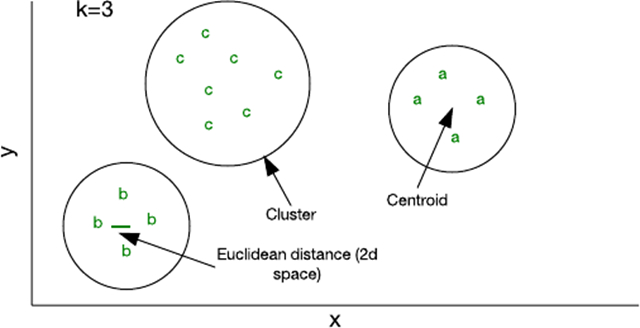
可通過少量代碼實現(xiàn)的最簡單的算法之一稱為 k 均值。在此算法中,k 表示您可向其中分配樣本的集群數(shù)量。您可以使用一個隨機特征矢量初始化一個集群,然后將其他所有樣本添加到離它們最近的集群(前提是每個樣本表示一個特征矢量,而且使用了一種歐幾里德距離來標識 “距離”)。隨著您將樣本添加到集群中,它的質(zhì)心 — 即集群的中心 — 會被重新計算。然后該算法會再次檢查樣本,確保它們存在于最近的集群中,并在沒有樣本改變集群成員關(guān)系時停止運行。
盡管 k 均值的效率相對較高,但您必須提前指定 k。根據(jù)所用的數(shù)據(jù),其他方法可能更高效,比如分層或基于分布的集群方法 。
決策樹
與集群緊密相關(guān)的是決策樹。決策樹是一種預(yù)測模型,對可得出某個結(jié)論的觀察值進行預(yù)測。樹上的樹葉代表結(jié)論,而節(jié)點是觀察值分叉時所在的決策點。決策樹是利用決策樹學(xué)習(xí)算法來構(gòu)建的,它們根據(jù)屬性值測試將數(shù)據(jù)集拆分為子集(通過一個稱為遞歸分區(qū)的流程)。
考慮下圖中的示例。在這個數(shù)據(jù)集中,我可以根據(jù) 3 個因素來觀察某個人何時的生產(chǎn)力較高。使用決策樹學(xué)習(xí)算法時,我可以使用一個指標來識別屬性(比如信息增益)。在這個示例中,情緒是生產(chǎn)力的主要因素,所以我依據(jù) “good mood” 是 Yes 還是 No 來拆分數(shù)據(jù)集。No 分支很簡單:它始終導(dǎo)致生產(chǎn)力低下。但是,Yes 分支需要根據(jù)其他兩個屬性來再次拆分數(shù)據(jù)集。我給數(shù)據(jù)集涂上顏色,以演示何處的觀察值通向我的葉節(jié)點。
圖 5. 一個簡單的數(shù)據(jù)集和得到的決策樹
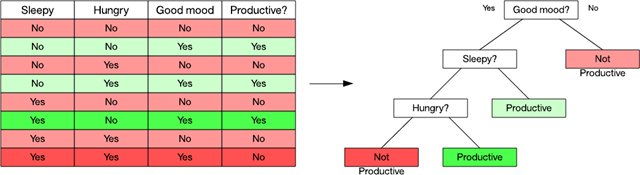
點擊查看大圖決策樹的一個有用方面是它們的內(nèi)在組織,您能輕松且圖形化地解釋您是如何分類一個數(shù)據(jù)項的。流行的決策樹學(xué)習(xí)算法包括 C4.5 和分類回歸樹。
基于規(guī)則的系統(tǒng)
第一個根據(jù)規(guī)則和推斷來構(gòu)建的系統(tǒng)稱為 Dendral,是 1965 年開發(fā)出來的,但直到上世紀 70 年代,這些所謂的 “專家系統(tǒng)” 才得到大力發(fā)展。基于規(guī)則的系統(tǒng)可以存儲知識和規(guī)則,并使用一個推理系統(tǒng)來得出結(jié)論。
基于規(guī)則的系統(tǒng)通常包含一個規(guī)則集、一個知識庫、一個推理引擎(使用前向或后向規(guī)則鏈),以及一個用戶界面。在下圖中,我使用一段信息(“蘇格拉底是一個凡人”)、一條規(guī)則(“凡人終有一死”)和一次關(guān)于誰會死的交互。
圖 6. 一個基于規(guī)則的系統(tǒng)
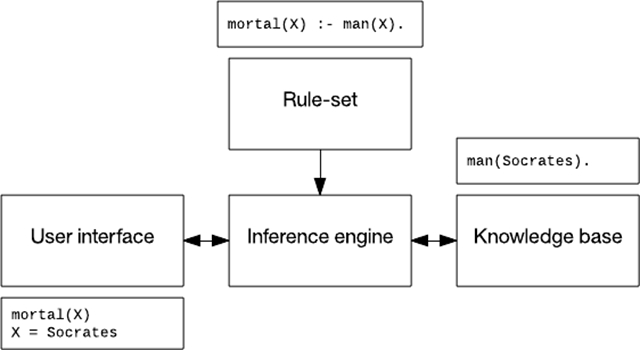
基于規(guī)則的系統(tǒng)已應(yīng)用于語音識別,規(guī)劃和控制,以及疾病識別。上世紀 90 年代開發(fā)的一個監(jiān)視和診斷壩體穩(wěn)定性的系統(tǒng) Kaleidos 至今仍在運營。
機器學(xué)習(xí)
機器學(xué)習(xí)是 AI 和計算機科學(xué)的一個子領(lǐng)域,起源于統(tǒng)計學(xué)和數(shù)學(xué)優(yōu)化。機器學(xué)習(xí)涵蓋應(yīng)用于預(yù)測、分析和數(shù)據(jù)挖掘的監(jiān)督式和非監(jiān)督式學(xué)習(xí)技術(shù)。它并不僅限于深度學(xué)習(xí),在本節(jié)中,我將探討一些實現(xiàn)這種效率奇高的方法的算法。
圖 7. 機器學(xué)習(xí)方法的時間線
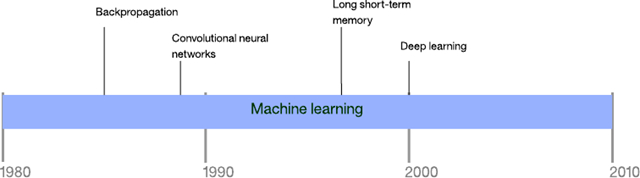
反向傳播算法(Backpropagation)
神經(jīng)網(wǎng)絡(luò)的真正威力在于它們的多層變形。訓(xùn)練單層感知器很簡單,但得到的網(wǎng)絡(luò)不是很強大。那么問題就變成了如何訓(xùn)練有多個層的網(wǎng)絡(luò)?這時就會用到反向傳播算法。
反向傳播是一種訓(xùn)練有許多層的神經(jīng)網(wǎng)絡(luò)的算法。它分兩個階段執(zhí)行。第一階段是通過一個神經(jīng)網(wǎng)絡(luò)將輸入傳播到最后一層(稱為前饋)。在第二階段,算法計算一個錯誤,然后將此錯誤從最后一層反向傳播(調(diào)節(jié)權(quán)值)到第一層。
圖 8. 反向傳播簡圖
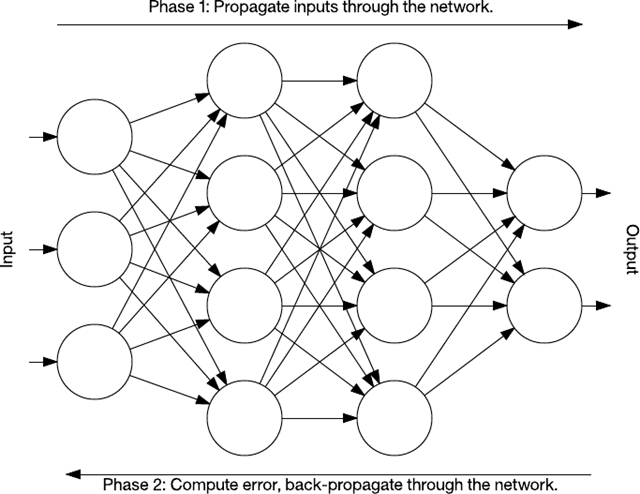
在訓(xùn)練期間,網(wǎng)絡(luò)的中間層自行進行組織,以便將輸入空間的各部分映射到輸出空間。通過監(jiān)督式學(xué)習(xí),反向傳播識別輸入-輸出映射中的錯誤,然后相應(yīng)地(以一定的學(xué)習(xí)速率)調(diào)整權(quán)值來更正此錯誤。反向傳播一直是神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)的一個重要方面。隨著計算資源消耗得更快和變得更廉價,反向傳播會繼續(xù)被應(yīng)用于更大更密集的網(wǎng)絡(luò)。
卷積神經(jīng)網(wǎng)絡(luò)(Convolutional neural networks)
卷積神經(jīng)網(wǎng)絡(luò) (CNN) 是受動物視覺皮質(zhì)啟發(fā)的多層神經(jīng)網(wǎng)絡(luò)。該架構(gòu)在各種應(yīng)用中都很有用,包括圖像處理。第一個 CNN 是 Yann LeCun 創(chuàng)建的,當(dāng)時,該架構(gòu)專注于手寫字符識別任務(wù),比如讀取郵政編碼。
LeNet CNN 架構(gòu)包含多層,這些層實現(xiàn)了特征提取,然后實現(xiàn)了分類。圖像被分成多個接受區(qū),注入可從輸入圖像中提取特征的卷積層。下一步是池化,它可以(通過下采樣)降低提取特征的維度,同時(通常通過最大池化)保留最重要的信息。然后該算法執(zhí)行另一個卷積和池化步驟,注入一個完全連通的多層感知器。此網(wǎng)絡(luò)的最終輸出層是一組節(jié)點,這些節(jié)點標識了圖像的特征(在本例中,每個節(jié)點對應(yīng)一個識別出的數(shù)字)。用戶可以通過反向傳播訓(xùn)練該網(wǎng)絡(luò)。
圖 9. LeNet 卷積神經(jīng)網(wǎng)絡(luò)架構(gòu)
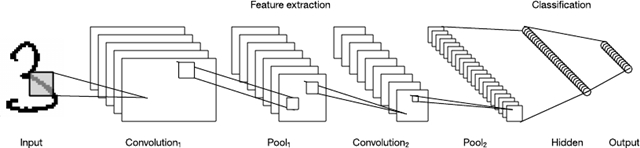
深層處理、卷積、池化和一個完全連通的分類層的使用,為神經(jīng)網(wǎng)絡(luò)的各種新應(yīng)用開啟了一扇門。除了圖像處理之外,CNN 還被成功應(yīng)用到許多視頻識別和自然語言處理的任務(wù)中。CNN 也已在 GPU 中獲得高效實現(xiàn),顯著提高了它們的性能。
長短期記憶
回想一下,在反向傳播的討論中曾提到過,該網(wǎng)絡(luò)是用前饋方式進行訓(xùn)練的。在這個架構(gòu)中,用戶將輸入注入網(wǎng)絡(luò)中,通過隱藏層將它們前向傳播到輸出層。但是,還有許多其他神經(jīng)網(wǎng)絡(luò)拓撲結(jié)構(gòu)。此處分析的拓撲結(jié)構(gòu)允許在節(jié)點之間建立連接,以便形成一個定向循環(huán)。這些網(wǎng)絡(luò)被稱為遞歸神經(jīng)網(wǎng)絡(luò),它們能反向饋送到前幾層或它們的層中的后續(xù)節(jié)點。該屬性使這些網(wǎng)絡(luò)成為處理時序數(shù)據(jù)的理想選擇。
1997 年,人們創(chuàng)建了一種名為長短期記憶 (LSTM) 的特殊回歸網(wǎng)絡(luò)。LSTM 由記憶細胞組成,網(wǎng)絡(luò)中的這些細胞會短期或長期記住一些值。
圖 10. 長短期記憶網(wǎng)絡(luò)和記憶細胞
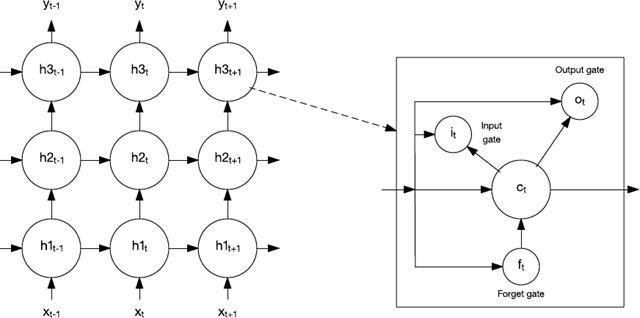
記憶細胞包含控制信息如何流進或流出細胞的閘門。輸入門控制新信息何時能流入記憶中。遺忘門控制一段現(xiàn)有信息保留的時長。最后,輸出門控制細胞中包含的信息何時用在來自該細胞的輸出中。記憶細胞還包含控制每個門的權(quán)值。訓(xùn)練算法通常沿時間反向傳播(反向傳播的一種變體),可以根據(jù)得到的錯誤來優(yōu)化這些權(quán)值。
LSTM 已被應(yīng)用于語音識別、手寫體識別、文本到語音合成、圖像字幕和其他各種任務(wù)。我很快會再介紹 LSTM。
深度學(xué)習(xí)
深度學(xué)習(xí)是一組相對較新的方法,它們正從根本上改變機器學(xué)習(xí)。深度學(xué)習(xí)本身不是一種算法,而是一系列通過無監(jiān)督學(xué)習(xí)來實現(xiàn)深度網(wǎng)絡(luò)的算法。這些網(wǎng)絡(luò)非常深,以至于(除了計算節(jié)點集群外)需要采用新計算方法(比如 GPU)來構(gòu)建它們。
本文目前為止探討了兩種深度學(xué)習(xí)算法:CNNs 和 LSTMs。這些算法的組合已用于實現(xiàn)多種非常智能的任務(wù)。如下圖所示,CNN 和 LSTM 已用于識別,以及使用自然語言描述照片或視頻。
圖 11. 組合使用卷積神經(jīng)網(wǎng)絡(luò)和長短期記憶網(wǎng)絡(luò)來描述圖片

點擊查看大圖深度學(xué)習(xí)算法也應(yīng)用于面部識別,能以 96% 的準確度識別肺結(jié)核,自動駕駛汽車,以及其他許多復(fù)雜的問題。
但是,盡管應(yīng)用深度學(xué)習(xí)算法取得了這些成果,但是仍有一些亟待我們解決的問題。最近,深度學(xué)習(xí)在皮膚癌檢測上的應(yīng)用發(fā)現(xiàn),該算法比獲得職業(yè)認證的皮膚科醫(yī)生更準確。但是,皮膚科醫(yī)生能列舉促使他們得出診斷結(jié)果的因素,而深度學(xué)習(xí)程序無法識別其在分類時使用了哪些因素。這就是所謂的深度學(xué)習(xí)黑盒問題。
另一種應(yīng)用稱為 Deep Patient,能根據(jù)患者的醫(yī)療記錄成功地預(yù)測疾病。事實證明,該應(yīng)用預(yù)測疾病的能力比醫(yī)生好得多 — 甚至是眾所周知難以預(yù)測的精神分裂癥。所以,盡管這些模型很有效,但沒有人能真正弄清楚龐大的神經(jīng)網(wǎng)絡(luò)行之有效的原因。
認知計算
AI 和機器學(xué)習(xí)都有許多生物靈感方面的示例。早期 AI 專注于構(gòu)建模仿人腦的機器的宏偉目標,而認知計算也致力于實現(xiàn)此目標。
認知計算是根據(jù)神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)來構(gòu)建的,正在應(yīng)用來自認知科學(xué)的知識來構(gòu)建模擬人類思維過程的系統(tǒng)。但是,認知計算沒有專注于單組技術(shù),而是涵蓋多個學(xué)科,包括機器學(xué)習(xí)、自然語言處理、視覺和人機交互。
IBM Watson 就是認知計算的一個示例,在 Jeopardy 上,IBM Watson 證實了它最先進的問答交互能力,但自那時起,IBM 已通過一系列 Web 服務(wù)擴展了該能力。這些服務(wù)公開的應(yīng)用編程接口可用于視覺識別、語音到文本和文本到語音轉(zhuǎn)換功能,語言理解和翻譯,以及對話引擎,以構(gòu)建強大的虛擬代理。
結(jié)束語
本文僅介紹了 AI 發(fā)展史以及最新的神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)方法的一小部分。盡管 AI 和機器學(xué)習(xí)的發(fā)展跌宕起伏,但深度學(xué)習(xí)和認知計算等新方法仍大大提高了這些學(xué)科的標準。有意識的機器可能仍無法實現(xiàn),但幫助改善人類生活的系統(tǒng)目前已存在。