如何做到“恰好一次”地傳遞數十億條消息
在分布式領域中存在著三種類型的消息投遞語義,分別是:最多一次(at-most-once)、至少一次(at-least-once)和恰好一次(exactly-once)。本文作者介紹了一個利用Kafka和RocksDB來構建的“恰好一次”消息去重系統的實現原理。
對任何一個數據流水線的唯一要求就是不能丟失數據。數據通常可以被延遲或重新排序,但不能丟失。
為了滿足這一要求,大多數的分布式系統都能夠保證“至少一次”的投遞消息技術。實現“至少一次”的投遞技術通常就是:“重試、重試、再重試”。在你收到消費者的確認消息之前,你永遠不要認為消息已經投遞過去。
但“至少一次”的投遞并不是用戶想要的。用戶希望消息被投遞一次,并且僅有一次。
然而,實現“恰好一次”的投遞需要***的設計。每種投遞失敗的情況都必須認真考慮,并設計到架構中去,因此它不能在事后“掛到”現有的實現上去。即使這樣,“只有一次”的投遞消息幾乎是不可能的。
在過去的三個月里,我們構建了一個全新的去重系統,以便在面對各種故障時能讓系統盡可能實現“恰好一次”的投遞。
新系統能夠跟蹤舊系統100倍的消息數量,并且可靠性也得到了提高,而付出的代價卻只有一點點。下面我們就開始介紹這個新系統。
問題所在
Segment內部的大部分系統都是通過重試、消息重新投遞、鎖定和兩階段提交來優雅地處理故障。但是,有一個特例,那就是將數據直接發送到公共API的客戶端程序。
客戶端(特別是移動客戶端)經常會發生網絡問題,有時候發送了數據,卻沒有收到API的響應。
想象一下,某天你乘坐公共汽車,在iPhone上使用HotelTonight軟件預訂房間。該應用程序將數據上傳到了Segment的服務器上,但汽車突然進入了隧道并失去了網絡連接。你發送的某些數據在服務器上已經被處理,但客戶端卻無法收到服務器的響應消息。
在這種情況下,即使服務器在技術上已經收到了這些確切的消息,但客戶端也會進行重試并將相同的消息重新發送給Segment的API。
從我們服務器的統計數據來看,在四個星期的窗口時間內,大約有0.6%的消息似乎是我們已經收到過的重復消息。
這個錯誤率聽起來可能并不是很高。但是,對于一個能創造數十億美元效益的電子商務應用程序來說,0.6%的出入可能意味著盈利和數百萬美元損失之間的差別。
對消息進行去重
現在,我們認識到問題的癥結了,我們必須刪除發送到API的重復消息。但是,該怎么做呢?
最簡單的思路就是使用針對任何類型的去重系統的高級API。在Python中,我們可以將其表示為:
- def dedupe(stream):
- for message in stream:
- if has_seen(message.id):
- discard(message)
- else:
- publish_and_commit(message)
對于數據流中的每個消息,首先要把他的id(假設是唯一的)作為主鍵,檢查是否曾經見過這個特定的消息。如果以前見過這個消息,則丟棄它。如果沒有,則是新的,我們應重新發布這個消息并以原子的方式提交消息。
為了避免存儲所有的消息,我們會設置“去重窗口”這個參數,這個參數定義了在消息過期之前key存儲的時長。只要消息落在窗口時間之外,我們就認為它已過期失效。我們要保證在窗口時間內某個給定ID的消息只發送一次。
這個行為很容易描述,但有兩個方面需要特別注意:讀/寫性能和正確性。
我們希望系統能夠低延遲和低成本的對通過流水線的數十億個事件進行去重。更重要的是,我們要確保所有的事件都能夠被持久化,以便可以從崩潰中恢復出來,并且不會輸出重復的消息。
架構
為了實現這一點,我們創建了一個“兩階段”架構,它讀入Kafka的數據,并且在四個星期的時間窗口內對接收到的所有事件進行去重。
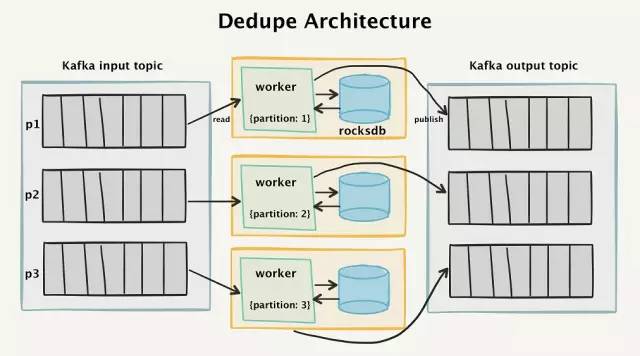
去重系統的高級架構圖
Kafka的拓撲結構
要了解其工作原理,首先看一下Kafka的流拓撲結構。所有傳入消息的API調用都將作為單獨的消息進行分離,并讀入到Kafka輸入主題(input topic)中。
首先,每個傳入的消息都有一個由客戶端生成的具有唯一性的messageId標記。在大多數情況下,這是一個UUIDv4(我們考慮切換到ksuids)。 如果客戶端不提供messageId,我們會在API層自動分配一個。
我們不使用矢量時鐘或序列號,因為我們希望能降低客戶端的復雜性。使用UUID可以讓任何人輕松地將數據發送到我們的API上來,因為幾乎所有的主要語言都支持它。
- {
- "messageId": "ajs-65707fcf61352427e8f1666f0e7f6090",
- "anonymousId": "e7bd0e18-57e9-4ef4-928a-4ccc0b189d18",
- "timestamp": "2017-06-26T14:38:23.264Z",
- "type": "page"
- }
為了能夠將消息持久化,并能夠重新發送,一個個的消息被保存到Kafka中。消息以messageId進行分區,這樣就可以保證具有相同messageId的消息能夠始終由同一個消費者處理。
這對于數據處理來說是一件很重要的事情。我們可以通過路由到正確的分區來查找鍵值,而不是在整個中央數據庫的數百億條消息中查找,這種方法極大地縮小了查找范圍。
去重“worker”(worker:工人。譯者注,這里表示的是某個進程。為防止引起歧義,下文將直接使用worker)是一個Go程序,它的功能是從Kafka輸入分區中讀入數據,檢查消息是否有重復,如果是新的消息,則發送到Kafka輸出主題中。
根據我們的經驗,worker和Kafka拓撲結構都非常容易掌握。我們無需使用一組遇到故障時需要切換到副本的龐大的Memcached實例。相反,我們只需使用零協同的嵌入式RocksDB數據庫,并以非常低的成本來獲得持久化存儲。
RocksDB的worker進程
每一個worker都會在本地EBS硬盤上存放了一個RocksDB數據庫。RocksDB是由Facebook開發的嵌入式鍵值存儲系統,它的性能非常高。
每當從輸入主題中過來的消息被消費時,消費者通過查詢RocksDB來確定我們之前是否見過該事件的messageId。
如果RocksDB中不存在該消息,我們就將其添加到RocksDB中,然后將消息發布到Kafka輸出主題。
如果消息已存在于RocksDB,則worker不會將其發布到輸出主題,而是更新輸入分區的偏移,確認已處理過該消息。
性能
為了讓我們的數據庫獲得高性能,我們必須對過來的每個事件滿足三種查詢模式:
- 檢測隨機key的存在性,這可能不存在于我們的數據庫中,但會在key空間中的任何地方找到。
- 高速寫入新的key
- 老化那些超出了“去重窗口”的舊的key
實際上,我們必須不斷地檢索整個數據庫,追加新的key,老化舊的key。在理想情況下,這些發生在同一數據模型中。
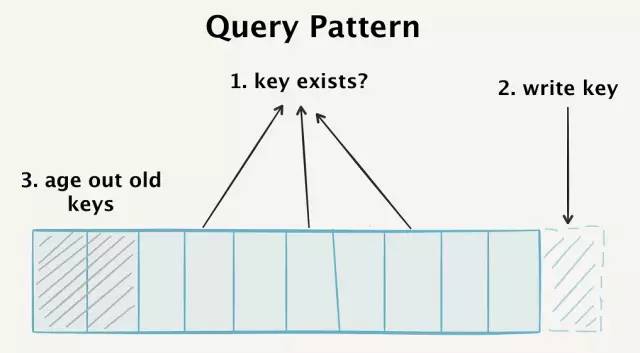
我們的數據庫必須滿足三種獨立的查詢模式
一般來說,這些性能大部分取決于我們數據庫的性能,所以應該了解一下RocksDB的內部機制來提高它的性能。
RocksDB是一個日志結構合并樹(log-structured-merge-tree, 簡稱LSM)數據庫,這意味著它會不斷地將新的key附加到磁盤上的預寫日志(write-ahead-log)中,并把排序過的key存放在內存中作為memtable的一部分。
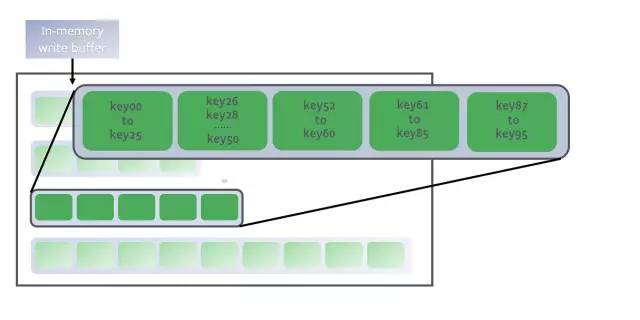
key存放在內存中作為memtable的一部分
寫入key是一個非常快速的過程。新的消息以追加的方式直接保存到磁盤上,并且數據條目在內存中進行排序,以提供快速的搜索和批量寫入。
每當寫入到memtable的條目達到一定數量時,這些條目就會被作為SSTable(排序的字符串表)持久化到磁盤上。由于字符串已經在內存中排過序了,所以可以將它們直接寫入磁盤。
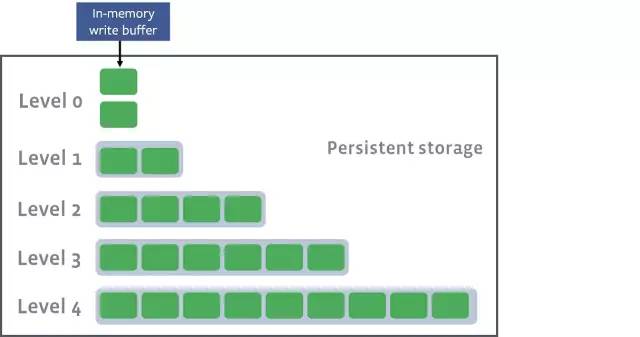
當前的memtable零級寫入磁盤
以下是在我們的生產日志中寫入的示例:
- [JOB 40] Syncing log #655020
- [default] [JOB 40] Flushing memtable with next log file: 655022
- [default] [JOB 40] Level-0 flush table #655023: started
- [default] [JOB 40] Level-0 flush table #655023: 15153564 bytes OK
- [JOB 40] Try to delete WAL files size 12238598, prev total WAL file size 24346413, number of live WAL files 3.
每個SSTable是不可變的,一旦創建,永遠不會改變。這是什么寫入新的鍵這么快的原因。無需更新文件,無需寫入擴展。相反,在帶外壓縮階段,同一級別的多個SSTable可以合并成一個新的文件。
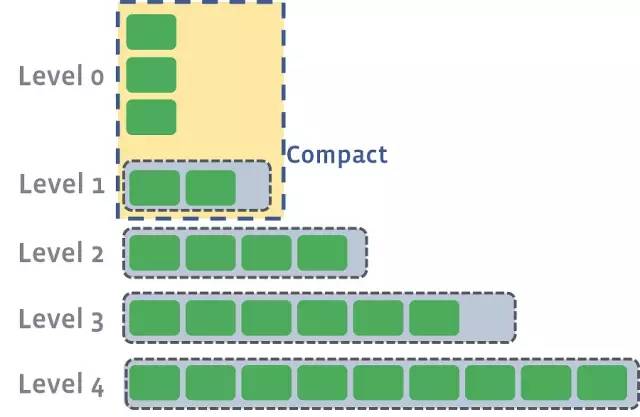
當在同一級別的SSTables壓縮時,它們的key會合并在一起,然后將新的文件升級到下一個更高的級別。
看一下我們生產的日志,可以看到這些壓縮作業的示例。在這種情況下,作業41正在壓縮4個0級文件,并將它們合并為單個較大的1級文件。
- /data/dedupe.db$ head -1000 LOG | grep "JOB 41"
- [JOB 41] Compacting 4@0 + 4@1 files to L1, score 1.00
- [default] [JOB 41] Generated table #655024: 1550991 keys, 69310820 bytes
- [default] [JOB 41] Generated table #655025: 1556181 keys, 69315779 bytes
- [default] [JOB 41] Generated table #655026: 797409 keys, 35651472 bytes
- [default] [JOB 41] Generated table #655027: 1612608 keys, 69391908 bytes
- [default] [JOB 41] Generated table #655028: 462217 keys, 19957191 bytes
- [default] [JOB 41] Compacted 4@0 + 4@1 files to L1 => 263627170 bytes
壓縮完成后,新合并的SSTables將成為最終的數據庫記錄集,舊的SSTables將被取消鏈接。
如果我們登錄到生產實例,我們可以看到正在更新的預寫日志以及正在寫入、讀取和合并的單個SSTable。
日志和最近占用I/O的SSTable
下面生產的SSTable統計數據中,可以看到一共有四個“級別”的文件,并且一個級別比一個級別的文件大。
- ** Compaction Stats [default] **
- Level Files Size(MB} Score Read(GB} Rn(GB} Rnp1(GB} Write(GB} Wnew(GB} Moved(GB} W-Amp Rd(MB/s} Wr(MB/s} Comp(sec} Comp(cnt} Avg(sec} KeyIn KeyDrop
- ----------------------------------------------------------------------------------------------------------------------------------------------------------
- L0 1/0 14.46 0.2 0.0 0.0 0.0 0.1 0.1 0.0 0.0 0.0 15.6 7 8 0.925 0 0
- L1 4/0 194.95 0.8 0.5 0.1 0.4 0.5 0.1 0.0 4.7 20.9 20.8 26 2 12.764 12M 40
- L2 48/0 2551.71 1.0 1.4 0.1 1.3 1.4 0.1 0.0 10.7 19.4 19.4 73 2 36.524 34M 14
- L3 351/0 21735.77 0.8 2.0 0.1 1.9 1.9 -0.0 0.0 14.3 18.1 16.9 112 2 56.138 52M 3378K
- Sum 404/0 24496.89 0.0 3.9 0.4 3.5 3.9 0.3 0.0 34.2 18.2 18.1 218 14 15.589 98M 3378K
- Int 0/0 0.00 0.0 3.9 0.4 3.5 3.9 0.3 0.0 34.2 18.2 18.1 218 14 15.589 98M 3378K
RocksDB保存了索引和存儲在SSTable的特定SSTables的布隆過濾器,并將這些加載到內存中。通過查詢這些過濾器和索引可以找到特定的key,然后將完整的SSTable作為LRU基礎的一部分加載到內存中。
在絕大多數情況下,我們就可以看到新的消息了,這使得我們的去重系統成為教科書中的布隆過濾器案例。
布隆過濾器會告訴我們某個鍵“可能在集合中”,或者“絕對在集合中”。要做到這一點,布隆過濾器保存了已經見過的任何元素的多種哈希函數的設置位。如果設置了散列函數的所有位,則過濾器將返回消息“可能在集合中”。

我們的集合包含{x,y,z},在布隆過濾器中查詢w,則布隆過濾器會返回“不在集合中”,因為其中有一位沒有設置。
如果返回“可能在集合中”,則RocksDB可以從SSTables中查詢到原始數據,以確定該項是否在該集合中實際存在。但在大多數情況下,我們不需查詢任何SSTables,因為過濾器將返回“絕對不在集合”的響應。
在我們查詢RocksDB時,我們會為所有要查詢的相關的messageId發出一個MultiGet。基于性能考慮,我們會批量地發布出去,以避免太多的并發鎖定操作。它還允許我們批量處理來自Kafka的數據,這是為了實現順序寫入,而不是隨機寫入。
以上回答了為什么讀/寫工作負載性能這么好的問題,但仍然存在如何老化數據這個問題。
刪除:按大小來限制,而不是按時間來限制
在我們的去重過程中,我們必須要確定是否要將我們的系統限制在嚴格的“去重窗口”內,或者是通過磁盤上的總數據庫大小來限制。
為了避免系統突然崩潰導致去重系統接收到所有客戶端的消息,我們決定按照大小來限制接收到消息數量,而不是按照設定的時間窗口來限制。這允許我們為每個RocksDB實例設置***的大小,以能夠處理突然的負載增加。但是其副作用是可能會將去重窗口降低到24小時以下。
我們會定期在RocksDB中老化舊的key,使其不會增長到***大小。為此,我們根據序列號保留key的第二個索引,以便我們可以先刪除最早接收到的key。
我們使用每個插入的key的序列號來刪除對象,而不是使用RocksDB TTL(這需要在打開數據庫的時候設置一個固定的TTL值)來刪除。
因為序列號是第二索引,所以我們可以快速地查詢,并將其標記為已刪除。下面是根據序列號進行刪除的示例代碼:
- func (d *DB) delete(n int) error {
- // open a connection to RocksDB
- ro := rocksdb.NewDefaultReadOptions()
- defer ro.Destroy()
- // find our offset to seek through for writing deletes
- hint, err := d.GetBytes(ro, []byte("seek_hint"))
- if err != nil {
- return err
- }
- it := d.NewIteratorCF(ro, d.seq)
- defer it.Close()
- // seek to the first key, this is a small
- // optimization to ensure we don't use `.SeekToFirst()`
- // since it has to skip through a lot of tombstones.
- if len(hint) > 0 {
- it.Seek(hint)
- } else {
- it.SeekToFirst()
- }
- seqs := make([][]byte, 0, n)
- keys := make([][]byte, 0, n)
- // look through our sequence numbers, counting up
- // append any data keys that we find to our set to be
- // deleted
- for it.Valid() && len(seqs) < n {
- k, v := it.Key(), it.Value()
- key := make([]byte, len(k.Data()))
- val := make([]byte, len(v.Data()))
- copy(key, k.Data())
- copy(val, v.Data())
- seqs = append(seqs, key)
- keys = append(keys, val)
- it.Next()
- k.Free()
- v.Free()
- }
- wb := rocksdb.NewWriteBatch()
- wo := rocksdb.NewDefaultWriteOptions()
- defer wb.Destroy()
- defer wo.Destroy()
- // preserve next sequence to be deleted.
- // this is an optimization so we can use `.Seek()`
- // instead of letting `.SeekToFirst()` skip through lots of tombstones.
- if len(seqs) > 0 {
- hint, err := strconv.ParseUint(string(seqs[len(seqs)-1]), 10, 64)
- if err != nil {
- return err
- }
- buf := []byte(strconv.FormatUint(hint+1, 10))
- wb.Put([]byte("seek_hint"), buf)
- }
- // we not only purge the keys, but the sequence numbers as well
- for i := range seqs {
- wb.DeleteCF(d.seq, seqs[i])
- wb.Delete(keys[i])
- }
- // finally, we persist the deletions to our database
- err = d.Write(wo, wb)
- if err != nil {
- return err
- }
- return it.Err()
- }
為了保證寫入速度,RocksDB不會立即返回并刪除一個鍵(記住,這些SSTable是不可變的!)。相反,RocksDB將添加一個“墓碑”,等到壓縮時再進行刪除。因此,我們可以通過順序寫入來快速地老化,避免因為刪除舊項而破壞內存數據。
確保正確性
我們已經討論了如何確保數十億條消息投遞的速度、規模和低成本的搜索。***一個部分將講述各種故障情況下我們如何確保數據的正確性。
EBS快照和附件
為了確保RocksDB實例不會因為錯誤的代碼推送或潛在的EBS停機而損壞,我們會定期保存每個硬盤驅動器的快照。雖然EBS已經在底層進行了復制,但是這一步可以防止數據庫受到某些底層機制的破壞。
如果我們想要啟用一個新實例,則可以先暫停消費者,將相關聯的EBS驅動器分開,然后重新附加到新的實例上去。只要我們保證分區ID相同,重新分配磁盤是一個輕松的過程,而且也能保證數據的正確性。
如果worker發生崩潰,我們依靠RocksDB內置的預寫日志來確保不會丟失消息。消息不會從輸入主題提交,除非RocksDB已經將消息持久化在日志中。
讀取輸出主題
你可能會注意到,本文直到這里都沒有提到“原子”步驟,以使我們能夠確保只投遞一次消息。我們的worker有可能在任何時候崩潰,不如:寫入RocksDB時、發布到輸出主題時,或確認輸入消息時。
我們需要一個原子的“提交”點,并覆蓋所有這些獨立系統的事務。對于輸入的數據,需要某個“事實來源”:輸出主題。
如果去重worker因為某些原因發生崩潰,或者遇到Kafka的某個錯誤,則系統在重新啟動時,會首先查閱這個“事實來源”,輸出主題,來判斷事件是否已經發布出去。
如果在輸出主題中找到消息,而不是RocksDB(反之亦然),則去重worker將進行必要的修復工作以保持數據庫和RocksDB之間的同步。實際上,我們使用輸出主題作為我們的預寫入日志和最終的事實來源,讓RocksDB進行檢查和校驗。
在生產環境中
我們的去重系統已經在生產運行了3個月,對其運行的結果我們感到非常滿意。我們有以下這些數據:
- 在RocksDB中,有1.5TB的key存儲在磁盤上
- 在老化舊的key之前,有一個四個星期的去重窗口
- RocksDB實例中存儲了大約600億個key
- 通過去重系統的消息達到2000億條
該系統快速、高效、容錯性強,也非常容易理解。
特別是我們的v2版本系統相比舊的去重系統有很多優點。
以前我們將所有的key存儲在Memcached中,并使用Memcached的原子CAS(check-and-set)操作來設置key。 Memcached起到了提交點和“原子”地發布key的作用。
雖然這個功能很好,但它需要有大量的內存來支撐所有的key。此外,我們必須能夠接受偶爾的Memcached故障,或者將用于高速內存故障切換的支出加倍。
Kafka/RocksDB的組合相比舊系統有如下幾個優勢:
- 數據存儲在磁盤上:在內存中保存所有的key或完整的索引,其代價是非常昂貴的。通過將更多的數據轉移到磁盤,并利用多種不同級別的文件和索引,能夠大幅削減成本。對于故障切換,我們能夠使用冷備(EBS),而不用運行其他的熱備實例。
- 分區:為了縮小key的搜索范圍,避免在內存中加載太多的索引,我們需要保證某個消息能夠路由到正確的worker。在Kafka中對上游進行分區可以對這些消息進行路由,從而更有效地緩存和查詢。
- 顯式地進行老化處理:在使用Memcached的時候,我們在每個key上設置一個TTL來標記是否超時,然后依靠Memcached進程來對超時的key進行處理。這使得我們在面對大量數據時,可能會耗盡內存,并且在丟棄大量超時消息時,Memcached的CPU使用率會飆升。而通過讓客戶端來處理key的刪除,使得我們可以通過縮短去重窗口來優雅地處理。
- 將Kafka作為事實來源:為了真正地避免對多個提交點進行消息去重,我們必須使用所有下游消費者都常見的事實來源。使用Kafka作為“事實來源”是最合適的。在大多數失敗的情況下(除了Kafka失敗之外),消息要么會被寫入Kafka,要么不會。使用Kafka可以確保按順序投遞消息,并在多臺計算機之間進行磁盤復制,而不需要在內存中保留大量的數據。
- 批量讀寫:通過Kafka和RocksDB的批量I/O調用,我們可以通過利用順序讀寫來獲得更好的性能。與之前在Memcached中使用的隨機訪問不同,我們能夠依靠磁盤的性能來達到更高的吞吐量,并只在內存中保留索引。
總的來說,我們對自己構建的去重系統非常滿意。使用Kafka和RocksDB作為流媒體應用的原語開始變得越來越普遍。我們很高興能繼續在這些原語之上構建新的分布式應用程序。